
ما هو التعبير العادي (regex)؟
في الواقع، التعبير العادي هو نمط للعثور على سلسلة في النص. في Java، يكون التمثيل الأصلي لهذا النمط دائمًا عبارة عن سلسلة، أي كائن من الفئةString. ومع ذلك، ليست أي سلسلة يمكن تجميعها في تعبير عادي - فقط السلاسل التي تتوافق مع قواعد إنشاء التعبيرات العادية. يتم تعريف بناء الجملة في مواصفات اللغة. تتم كتابة التعبيرات العادية باستخدام الحروف والأرقام، بالإضافة إلى الأحرف الأولية، وهي أحرف لها معنى خاص في بناء جملة التعبير العادي. على سبيل المثال:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;إنشاء التعبيرات العادية في جافا
يتضمن إنشاء تعبير عادي في Java خطوتين بسيطتين:- كتابتها كسلسلة تتوافق مع بناء جملة التعبير العادي؛
- تجميع السلسلة في تعبير عادي؛
Patternكائن. للقيام بذلك، نحتاج إلى استدعاء إحدى الطريقتين الثابتتين للفئة: compile. تأخذ الطريقة الأولى وسيطة واحدة - سلسلة حرفية تحتوي على التعبير العادي، بينما تأخذ الطريقة الثانية وسيطة إضافية تحدد إعدادات مطابقة النمط:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)flagsPattern
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.Patternالفصل هو منشئ للتعبيرات العادية. تحت الغطاء، compileتستدعي الطريقة Patternالمنشئ الخاص للفئة لإنشاء تمثيل مجمع. يتم تنفيذ آلية إنشاء الكائن بهذه الطريقة لإنشاء كائنات غير قابلة للتغيير. عند إنشاء تعبير عادي، يتم التحقق من تركيبه. إذا كانت السلسلة تحتوي على أخطاء، فسيتم PatternSyntaxExceptionإنشاء a.
بناء جملة التعبير العادي
يعتمد بناء جملة التعبير العادي على<([{\^-=$!|]})?*+.>الأحرف التي يمكن دمجها مع الحروف. اعتمادًا على دورهم، يمكن تقسيمهم إلى عدة مجموعات:
| حرف أولي | وصف |
|---|---|
| ^ | بداية السطر |
| $ | نهاية السطر |
| \ب | حدود الكلمة |
| \ب | حدود غير الكلمة |
| \أ | بداية الإدخال |
| \ز | نهاية المباراة السابقة |
| \ز | نهاية الإدخال |
| \ض | نهاية الإدخال |
| حرف أولي | وصف |
|---|---|
| \د | رقم |
| \د | غير رقم |
| \س | حرف المسافة البيضاء |
| \س | حرف غير مسافة بيضاء |
| \ث | حرف أبجدي رقمي أو الشرطة السفلية |
| \د | أي حرف باستثناء الحروف والأرقام والشرطة السفلية |
| . | أي شخصية |

| حرف أولي | وصف |
|---|---|
| \ ر | حرف علامة التبويب |
| \ن | حرف السطر الجديد |
| \ ص | إرجاع |
| \F | حرف تغذية الأسطر |
| \u0085 | حرف السطر التالي |
| \u2028 | فاصل الخط |
| \u2029 | فاصل الفقرة |
| حرف أولي | وصف |
|---|---|
| [اي بي سي] | أي من الأحرف المدرجة (أ، ب، أو ج) |
| [^ايه بي سي] | أي حرف غير تلك المذكورة (وليس أ، ب، أو ج) |
| [أ-ي-ي] | النطاقات المدمجة (الأحرف اللاتينية من a إلى z، غير حساسة لحالة الأحرف) |
| [إعلان[mp]] | اتحاد الأحرف (من a إلى d ومن m إلى p) |
| [أ&&[تعريف]] | تقاطع الأحرف (d، e، f) |
| [من الألف إلى الياء &&[^قبل الميلاد]] | طرح الأحرف (a، dz) |
| حرف أولي | وصف |
|---|---|
| ؟ | واحد أو لا شيء |
| * | صفر مرة أو أكثر |
| + | مرة واحدة أو أكثر |
| {ن} | ن مرات |
| {ن،} | ن أو أكثر من مرة |
| {ن،م} | على الأقل n مرات ولا يزيد عن m مرات |
محددات الكميات الجشعة
شيء واحد يجب أن تعرفه عن محددات الكمية هو أنها تأتي في ثلاثة أنواع مختلفة: الجشع، والتملك، والمتردد. يمكنك إنشاء مُحدِّد كمية عن طريق إضافة+حرف "" بعد مُحدِّد الكمية. أنت تجعله متردداً بإضافة " ?". على سبيل المثال:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
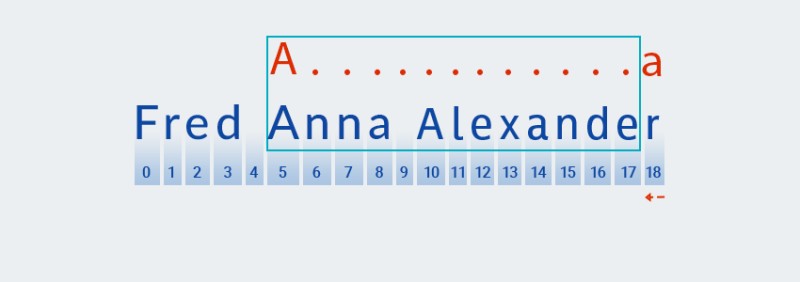
Anna AlexaA.+a"، يتم إجراء مطابقة النمط كما يلي:
-
الحرف الأول في النمط المحدد هو الحرف اللاتيني
A.Matcherومقارنتها بكل حرف في النص، بدءاً من الفهرس صفر. الحرفFموجود عند الفهرس صفر في النص، لذاMatcherيتكرر عبر الأحرف حتى يطابق النمط. في مثالنا، تم العثور على هذا الحرف في الفهرس 5.![التعبيرات العادية في جافا - 2]()
-
بمجرد العثور على تطابق مع الحرف الأول للنمط،
Matcherابحث عن تطابق مع الحرف الثاني. في حالتنا، هو.الحرف " "، الذي يرمز إلى أي حرف.![التعبيرات العادية في جافا - 3]()
الشخصية
nفي المركز السادس. إنها بالتأكيد مؤهلة لتكون مطابقة لـ "أي شخصية". -
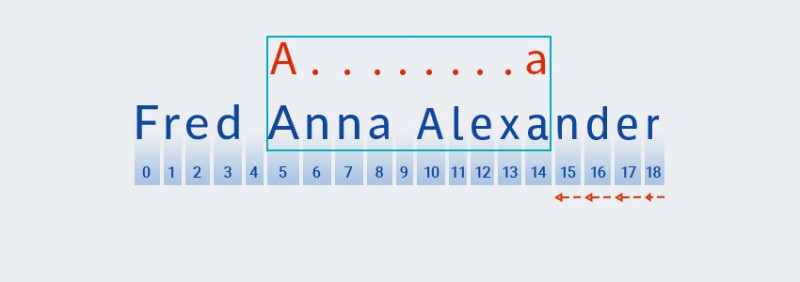
Matcherيستمر في التحقق من الحرف التالي للنمط. في نمطنا، يتم تضمينه في المحدد الكمي الذي ينطبق على الحرف السابق: ".+". نظرًا لأن عدد مرات تكرار "أي حرف" في نمطنا هو مرة واحدة أو أكثر، فإنناMatcherنقوم بشكل متكرر بأخذ الحرف التالي من السلسلة والتحقق منه مقابل النمط طالما أنه يطابق "أي حرف". في مثالنا — حتى نهاية السلسلة (من الفهرس 7 إلى الفهرس 18).![التعبيرات العادية في جافا - 4]()
في الأساس،
Matcherيلتهم الخيط حتى النهاية - وهذا هو بالضبط ما يُقصد بكلمة "الجشع". -
بعد أن يصل Matcher إلى نهاية النص وينتهي من التحقق من الجزء "
A.+" من النموذج، فإنه يبدأ في التحقق من بقية النموذج:a. لم يعد هناك أي نص للمضي قدمًا، لذا تتم عملية التحقق من خلال "التراجع"، بدءًا من الحرف الأخير:![التعبيرات العادية في جافا - 5]()
-
Matcher"يتذكر" عدد التكرارات في الجزء ".+" من النمط. عند هذه النقطة، فإنه يقلل عدد التكرارات بمقدار واحد ويتحقق من النمط الأكبر مقابل النص حتى يتم العثور على تطابق:![التعبيرات العادية في جافا - 6]()



محددات الكمية الملكية
محددات الكمية الملكية تشبه إلى حد كبير تلك الجشعة. الفرق هو أنه عندما يتم التقاط النص حتى نهاية السلسلة، لا توجد مطابقة للنمط أثناء "التراجع". وبعبارة أخرى، فإن المراحل الثلاث الأولى هي نفسها بالنسبة لمحددي الكمية الجشعين. بعد التقاط السلسلة بأكملها، يضيف المطابق بقية النموذج إلى ما يفكر فيه ويقارنه بالسلسلة الملتقطة. في مثالنا، باستخدام التعبير العادي "A.++a"، لم تجد الطريقة الرئيسية أي تطابق. 
محددات الكمية مترددة
-
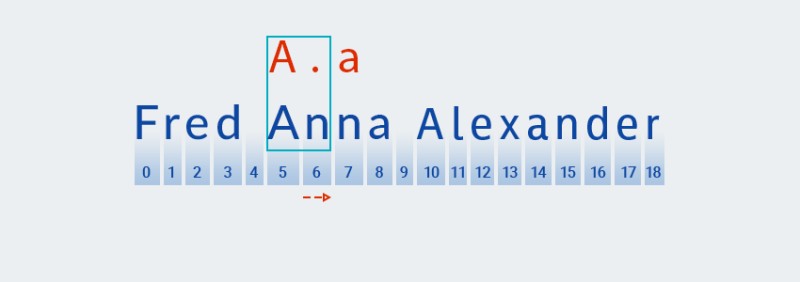
بالنسبة لهذه المحددات الكمية، كما هو الحال مع التنوع الجشع، يبحث الكود عن تطابق بناءً على الحرف الأول من النموذج:
![التعبيرات العادية في جافا - 8]()
-
ثم يبحث عن تطابق مع الحرف التالي للنمط (أي حرف):
![التعبيرات العادية في جافا - 9]()
-
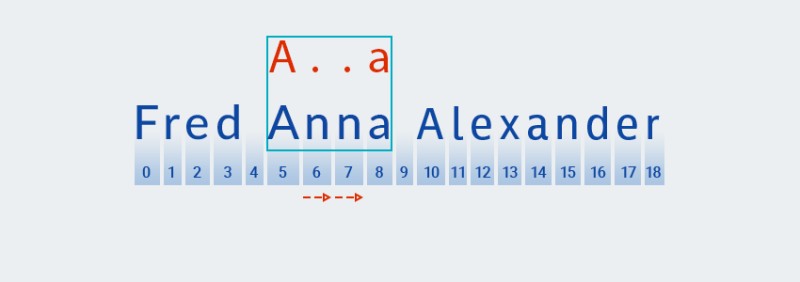
على عكس مطابقة الأنماط الجشعة، يتم البحث عن أقصر تطابق في مطابقة الأنماط المترددة. هذا يعني أنه بعد العثور على تطابق مع الحرف الثاني للنمط (النقطة، التي تتوافق مع الحرف الموجود في الموضع 6 في النص،
Matcherتتحقق مما إذا كان النص يطابق بقية النمط — الحرف "a"![التعبيرات العادية في جافا - 10]()
-
النص لا يتطابق مع النمط (أي أنه يحتوي على الحرف "
n" في الفهرس 7)، لذلكMatcherيتم إضافة المزيد من "أي حرف"، لأن محدد الكمية يشير إلى واحد أو أكثر. ثم يقوم مرة أخرى بمقارنة النمط بالنص الموجود في المواضع من 5 إلى 8:![التعبيرات العادية في جافا - 11]()


في حالتنا، تم العثور على تطابق، لكننا لم نصل إلى نهاية النص بعد. ولذلك، تتم إعادة تشغيل مطابقة النمط من الموضع 9، أي يتم البحث عن الحرف الأول للنمط باستخدام خوارزمية مشابهة ويتكرر هذا حتى نهاية النص.

mainتحصل الطريقة على النتيجة التالية عند استخدام النمط " A.+?a": Anna Alexa كما ترون من مثالنا، فإن الأنواع المختلفة من محددات الكمية تنتج نتائج مختلفة لنفس النمط. لذا ضع ذلك في الاعتبار واختر النوع المناسب بناءً على ما تبحث عنه.
الهروب من الأحرف في التعبيرات العادية
نظرًا لأن التعبير العادي في Java، أو بالأحرى تمثيله الأصلي، عبارة عن سلسلة حرفية، فإننا نحتاج إلى مراعاة قواعد Java المتعلقة بالسلسلة الحرفية. على وجه الخصوص، يتم تفسير حرف الخط المائل العكسي "\" في سلسلة حرفية في كود مصدر Java كحرف تحكم يخبر المترجم أن الحرف التالي خاص ويجب تفسيره بطريقة خاصة. على سبيل المثال:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"\الأحرف " " (على سبيل المثال للإشارة إلى الأحرف الأولية) يجب أن تكرر الخطوط المائلة العكسية للتأكد من أن مترجم Java bytecode لا يخطئ في تفسير السلسلة. على سبيل المثال:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"طرق فئة النمط
لدى الفصلPatternطرق أخرى للعمل مع التعبيرات العادية:
-
String pattern()- إرجاع تمثيل السلسلة الأصلية للتعبير العادي المستخدم لإنشاءPatternالكائن:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– يتيح لك التحقق من التعبير العادي الذي تم تمريره كـ regex مقابل النص الذي تم تمريره كـinput. عائدات:صحيح - إذا كان النص يطابق النمط؛
كاذبة - إذا لم يحدث ذلك؛على سبيل المثال:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()- يُرجع قيمةflagsمعلمة النمط التي تم تعيينها عند إنشاء النمط أو 0 إذا لم يتم تعيين المعلمة. على سبيل المثال:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)- تقسيم النص الذي تم تمريره إلىStringمصفوفة. تشير المعلمةlimitإلى الحد الأقصى لعدد التطابقات التي تم البحث عنها في النص:- إذا
limit > 0-limit-1يطابق؛ - إذا
limit < 0- جميع التطابقات في النص - إذا
limit = 0- جميع التطابقات في النص، فسيتم تجاهل السلاسل الفارغة في نهاية المصفوفة؛
على سبيل المثال:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }إخراج وحدة التحكم:
Fred Anna Alexa --------- Fred Anna Alexaأدناه سننظر في طريقة أخرى من طرق الفصل المستخدمة لإنشاء
Matcherكائن. - إذا
أساليب فئة المطابق
يتم إنشاء مثيلات الفئةMatcherلإجراء مطابقة الأنماط. Matcherهو "محرك البحث" للتعبيرات العادية. لإجراء بحث، نحتاج إلى إعطائه شيئين: نمط وفهرس بداية. لإنشاء Matcherكائن، Patternتوفر الفئة الطريقة التالية: рublic Matcher matcher(CharSequence input) تأخذ الطريقة تسلسل أحرف، والذي سيتم البحث فيه. هذا مثيل للفئة التي تنفذ الواجهة CharSequence. لا يمكنك تمرير ملف فحسب String، بل يمكنك أيضًا تمرير StringBufferملف StringBuilderأو Segmentأو CharBuffer. النمط هو كائن يتم استدعاء الطريقة Patternعليه . matcherمثال على إنشاء المطابق:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"
boolean find()عن المطابقة التالية في النص. يمكننا استخدام هذه الطريقة وبيان الحلقة لتحليل النص بأكمله كجزء من نموذج الحدث. بمعنى آخر، يمكننا إجراء العمليات اللازمة عند وقوع حدث ما، أي عندما نجد تطابقًا في النص. على سبيل المثال، يمكننا استخدام هذه الفئة int start()وطرقها int end()لتحديد موضع التطابق في النص. ويمكننا استخدام الطرق String replaceFirst(String replacement)و String replaceAll(String replacement)لاستبدال التطابقات بقيمة معلمة الاستبدال. على سبيل المثال:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna AlexareplaceFirstو replaceAllتنشئ كائنًا جديدًا String- سلسلة يتم فيها استبدال تطابقات النمط في النص الأصلي بالنص الذي تم تمريره إلى الطريقة كوسيطة. بالإضافة إلى ذلك، replaceFirstيستبدل الأسلوب المطابقة الأولى فقط، لكن replaceAllيستبدل الأسلوب كافة التطابقات في النص. يبقى النص الأصلي دون تغيير. تم إنشاء عمليات regex الأكثر شيوعًا للفئات و في الفصل Patternمباشرةً . هذه هي الأساليب مثل و و و . ولكن تحت غطاء محرك السيارة، تستخدم هذه الأساليب والفئات . لذا، إذا كنت تريد استبدال نص أو مقارنة سلاسل في برنامج ما دون كتابة أي تعليمات برمجية إضافية، فاستخدم أساليب الفصل . إذا كنت بحاجة إلى المزيد من الميزات المتقدمة، فتذكر الفئات . MatcherStringsplitmatchesreplaceFirstreplaceAllPatternMatcherStringPatternMatcher
خاتمة
في برنامج Java، يتم تعريف التعبير العادي بواسطة سلسلة تخضع لقواعد محددة لمطابقة الأنماط. عند تنفيذ التعليمات البرمجية، يقوم جهاز Java بتجميع هذه السلسلة في كائنPatternويستخدم Matcherكائنًا للعثور على التطابقات في النص. كما قلت في البداية، غالبًا ما يؤجل الناس التعبيرات العادية لوقت لاحق، معتبرين أنها موضوعًا صعبًا. ولكن إذا فهمت بناء الجملة الأساسي، والأحرف الأولية، والهروب من الأحرف، ودرست أمثلة للتعبيرات العادية، فستجد أنها أبسط بكثير مما تبدو للوهلة الأولى.
|
المزيد من القراءة: |
|---|
GO TO FULL VERSION