 لقد عثرت مؤخرًا على عدد قليل من القوائم الكبيرة لأسئلة المقابلة لشغل وظائف مطوري Java. تنقسم الأسئلة إلى مستويات مختلفة: المستوى المبتدئ والمتوسط والمستوى الأعلى. لا تنزعج: ليست كل الأسئلة سهلة، ولكن الأسئلة التي تحمل علامة النجمة نادرًا ما يتم طرحها. الأسئلة جيدة، وأود أن أحاول الإجابة على معظمها. من الواضح أن هذا لن يتناسب مع مقال واحد. بعد كل شيء، هناك الكثير من الأسئلة هناك. وهذا يعني أنه ستكون هناك سلسلة كاملة من المقالات تحتوي على إجابات لأسئلة المقابلة هذه. اسمحوا لي أن أؤكد على بعض النقاط على الفور: الإجابات ستكون قصيرة، لأن الإجابات المكتوبة بتفصيل كبير يمكن سحبها إلى مقال منفصل. أيضًا، في المقابلات، لا تكون هناك حاجة إلى إجابات مفصلة وضخمة للغاية، لأن الشخص الذي يجري المقابلة معك لديه ساعة واحدة فقط لإجراء مقابلة معك حول الموضوعات الأساسية (وكما تتذكر، هناك الكثير منها).
لقد عثرت مؤخرًا على عدد قليل من القوائم الكبيرة لأسئلة المقابلة لشغل وظائف مطوري Java. تنقسم الأسئلة إلى مستويات مختلفة: المستوى المبتدئ والمتوسط والمستوى الأعلى. لا تنزعج: ليست كل الأسئلة سهلة، ولكن الأسئلة التي تحمل علامة النجمة نادرًا ما يتم طرحها. الأسئلة جيدة، وأود أن أحاول الإجابة على معظمها. من الواضح أن هذا لن يتناسب مع مقال واحد. بعد كل شيء، هناك الكثير من الأسئلة هناك. وهذا يعني أنه ستكون هناك سلسلة كاملة من المقالات تحتوي على إجابات لأسئلة المقابلة هذه. اسمحوا لي أن أؤكد على بعض النقاط على الفور: الإجابات ستكون قصيرة، لأن الإجابات المكتوبة بتفصيل كبير يمكن سحبها إلى مقال منفصل. أيضًا، في المقابلات، لا تكون هناك حاجة إلى إجابات مفصلة وضخمة للغاية، لأن الشخص الذي يجري المقابلة معك لديه ساعة واحدة فقط لإجراء مقابلة معك حول الموضوعات الأساسية (وكما تتذكر، هناك الكثير منها).
سؤال وجواب لوظيفة مطور مبتدئ
اسئلة عامة
1. ما هي أنماط التصميم التي تعرفها؟ أخبرنا عن اثنين من أنماط التصميم التي استخدمتها في عملك.
هناك مجموعة كبيرة ومتنوعة من الأنماط. لأولئك منكم الذين يريدون التعرف بشكل كامل على أنماط التصميم، أوصي بقراءة كتاب "الرأس أولاً. أنماط التصميم". سيساعدك هذا على التعرف بسهولة على تفاصيل أنماط التصميم الأساسية. وفيما يتعلق بأنماط التصميم التي يمكن أن تذكرها في مقابلة العمل، يتبادر إلى ذهنك ما يلي:- Builder — قالب يستخدم بشكل متكرر، وهو بديل للنهج الكلاسيكي لإنشاء الكائنات؛
- الإستراتيجية – وهو النمط الذي يمثل في الأساس تعدد الأشكال. أي أن لدينا واجهة واحدة، لكن سلوك البرنامج يتغير اعتمادًا على تنفيذ الواجهة المحددة التي تم تمريرها إلى الوظيفة (يتم استخدام نمط الإستراتيجية الآن في كل مكان تقريبًا في تطبيقات Java).
- المصنع - يمكن العثور على هذا النمط في ApplicationContext (أو في BeanFactory)؛
- Singleton — جميع حبوب البن منفردة بشكل افتراضي؛
- الوكيل - في الأساس، كل شيء في Spring يستخدم هذا النمط بطريقة أو بأخرى، على سبيل المثال، AOP؛
- سلسلة المسؤولية – وهو النمط الذي يقوم عليه Spring Security؛
- القالب - يستخدم في Spring JDBC.

جافا كور

2. ما هي أنواع البيانات الموجودة في جافا؟
تحتوي Java على أنواع البيانات البدائية التالية:- بايت — أعداد صحيحة تتراوح من -128 إلى 127، وتشغل بايتًا واحدًا؛
- قصيرة - أعداد صحيحة تتراوح من -32768 إلى 32767، وتستهلك 2 بايت؛
- int - أعداد صحيحة تتراوح من -2147483648 إلى 2147483647، وتستهلك 4 بايت؛
- طويلة - الأعداد الصحيحة التي تتراوح من 9223372036854775808 إلى 9223372036854775807، تستهلك 8 بايت؛
- float - أرقام الفاصلة العائمة التي تتراوح من -3.4E+38 إلى 3.4E+38، وتستهلك 4 بايت؛
- مزدوج - أرقام الفاصلة العائمة تتراوح من -1.7E+308 إلى 1.7E+308، وتستهلك 8 بايت؛
- char - أحرف مفردة في UTF-16، تشغل 2 بايت؛
- القيم المنطقية الصحيحة/الخاطئة، تستهلك بايتًا واحدًا.
3. كيف يختلف الكائن عن أنواع البيانات البدائية؟
يتمثل الاختلاف الأول في مقدار الذاكرة المشغولة: فالبدائيات تشغل القليل جدًا لأنها تحتوي فقط على قيمتها الخاصة، ولكن الكائنات يمكن أن تحتوي على الكثير من القيم المختلفة - سواء كانت أولية أو مراجع لكائنات أخرى. والفرق الثاني هو أن Java هي لغة موجهة للكائنات، لذا فإن كل شيء في Java يعمل عبارة عن تفاعل بين الكائنات. البدائيون لا يتناسبون بشكل جيد هنا. في الواقع، هذا هو السبب في أن Java ليست لغة موجهة للكائنات بنسبة 100%. والفرق الثالث الذي يتبع الثاني هو أنه نظرًا لأن Java تركز على تفاعلات الكائنات، فهناك العديد من الآليات المختلفة لإدارة الكائنات. على سبيل المثال، المُنشئات، والأساليب، والاستثناءات (التي تعمل بشكل أساسي مع الكائنات)، وما إلى ذلك. وللسماح للأوليات بالعمل بطريقة ما في هذه البيئة الموجهة للكائنات، توصل منشئو Java إلى أغلفة للأنواع الأولية ( Integer ، Character ، Double ، Boolean ...)4. ما الفرق بين تمرير الوسيطات حسب المرجع والقيمة؟
تقوم الحقول الأولية بتخزين قيمتها: على سبيل المثال، إذا قمنا بتعيين int i = 9; ، ثم يقوم الحقل i بتخزين القيمة 9. عندما يكون لدينا مرجع إلى كائن، فهذا يعني أن لدينا حقل يحتوي على مرجع إلى الكائن. بمعنى آخر، لدينا حقل يخزن عنوان الكائن في الذاكرة.Cat cat = new Cat();5. ما هو JVM وJDK وJRE؟
يرمز JVM إلى Java Virtual Machine ، الذي يقوم بتشغيل Java bytecode الذي تم إنشاؤه مسبقًا بواسطة المترجم. JRE تعني بيئة تشغيل Java . إنها في الأساس بيئة لتشغيل تطبيقات Java. يتضمن JVM والمكتبات القياسية والمكونات الأخرى لتشغيل التطبيقات الصغيرة والتطبيقات المكتوبة بلغة برمجة Java. بمعنى آخر، JRE عبارة عن حزمة من كل ما هو مطلوب لتشغيل برنامج Java مترجم، ولكنها لا تتضمن الأدوات والأدوات المساعدة مثل المترجمين أو مصححات الأخطاء لتطوير التطبيقات. JDK تعني Java Development Kit ، وهي امتداد لـ JRE . أي أنها بيئة ليس فقط لتشغيل تطبيقات Java، ولكن أيضًا لتطويرها. يحتوي JDK على كل شيء في JRE، بالإضافة إلى العديد من الأدوات الإضافية - المترجمين ومصححي الأخطاء - اللازمة لإنشاء تطبيقات Java (بما في ذلك مستندات Java).
6. لماذا نستخدم JVM؟
كما هو مذكور أعلاه، فإن Java Virtual Machine هو جهاز افتراضي يقوم بتشغيل Java bytecode الذي تم إنشاؤه مسبقًا بواسطة المترجم. هذا يعني أن JVM لا يفهم كود مصدر Java. لذلك، أولاً، نقوم بتجميع ملفات جافا . الملفات المترجمة لها الامتداد .class وهي الآن في شكل كود بايت، وهو ما يفهمه JVM. يختلف JVM لكل نظام تشغيل. عندما يقوم JVM بتشغيل ملفات bytecode، فإنه يقوم بتكييفها مع نظام التشغيل الذي يعمل عليه. في الواقع، نظرًا لوجود JVMs مختلفة، فإن JDK (أو JRE) يختلف أيضًا باختلاف أنظمة التشغيل (يحتاج كل إصدار إلى JVM خاص به). دعونا نتذكر كيف يعمل التطوير في لغات البرمجة الأخرى. تكتب برنامجًا، ثم يتم تجميع الكود الخاص به في كود الجهاز لنظام تشغيل معين، ومن ثم يمكنك تشغيله. بمعنى آخر، تحتاج إلى كتابة إصدارات مختلفة من البرنامج لكل منصة. لكن معالجة Java المزدوجة للتعليمات البرمجية (تجميع التعليمات البرمجية المصدر في كود ثانوي، ثم معالجة الكود الثانوي بواسطة JVM) تتيح لك الاستمتاع بمزايا الحل عبر الأنظمة الأساسية. نقوم بإنشاء الكود مرة واحدة ثم تجميعه في كود بايت. ثم يمكننا نقله إلى أي نظام تشغيل، ويكون JVM الأصلي قادرًا على تشغيله. وهذه هي بالضبط ميزة الكتابة الأسطورية في Java مرة واحدة والتشغيل في أي مكان .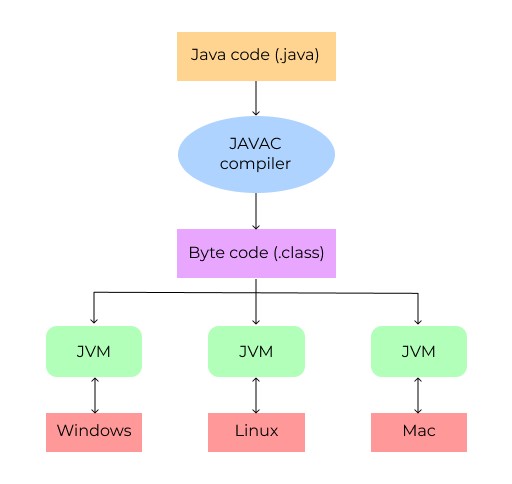
7. ما هو الرمز الثانوي؟
كما قلت أعلاه، يقوم المترجم بتحويل كود Java إلى رمز ثانوي متوسط (ننتقل من الملفات ذات الامتداد .java إلى الملفات ذات الامتداد .class). في العديد من النواحي، يشبه الرمز الثانوي رمز الآلة، باستثناء أن مجموعة التعليمات الخاصة به ليست لمعالج حقيقي، بل لمعالج افتراضي. ومع ذلك، يمكن أن يتضمن أقسامًا مصممة لمترجم JIT، الذي يعمل على تحسين تنفيذ الأوامر للمعالج الفعلي الذي يعمل عليه البرنامج. تجميع JIT، والذي يُطلق عليه أيضًا التجميع الفوري، هو تقنية تعمل على زيادة أداء برنامج الكود الثانوي عن طريق تجميع الكود الثانوي في كود الجهاز أو تنسيق آخر أثناء تشغيل البرنامج. كما كنت قد خمنت، يستخدم JVM مترجم JIT عندما يقوم بتشغيل الكود الثانوي. دعونا نلقي نظرة على بعض نماذج التعليمات البرمجية الثانوية: ليست قابلة للقراءة جدًا، أليس كذلك؟ والخبر السار هو أن هذه التعليمات ليست مخصصة لنا. إنها من أجل JVM.
ليست قابلة للقراءة جدًا، أليس كذلك؟ والخبر السار هو أن هذه التعليمات ليست مخصصة لنا. إنها من أجل JVM.
8. ما هي مميزات JavaBean؟
JavaBean هي فئة Java تتبع قواعد معينة . فيما يلي بعض القواعد لكتابة JavaBean :-
يجب أن يحتوي الفصل على مُنشئ فارغ (بدون وسيطة) مع معدل الوصول العام . يتيح هذا المنشئ إمكانية إنشاء كائن من الفئة دون أي مشاكل غير ضرورية (بحيث لا يكون هناك تلاعب غير ضروري بالوسائط).
-
يتم الوصول إلى الحقول الداخلية عبر أساليب الحصول على المثيلات وتعيينها ، والتي يجب أن يكون لها التنفيذ القياسي. على سبيل المثال، إذا كان لدينا حقل اسم ، فيجب أن يكون لدينا getName و setName ، وما إلى ذلك. وهذا يسمح للأدوات (الأطر) المختلفة بالحصول على محتوى الحبوب وتعيينها تلقائيًا دون أي صعوبة.
-
يجب أن يتجاوز الفصل أساليب يساوي () و hashCode () و toString () .
-
يجب أن يكون الفصل قابلاً للتسلسل. أي أنه يجب أن يحتوي على واجهة علامة قابلة للتسلسل أو تنفيذ واجهة قابلة للتحويل . وذلك حتى يمكن حفظ حالة الحبة وتخزينها واستعادتها بشكل موثوق.

9. ما هو خطأ OutOfMemoryError؟
OutOfMemoryError هو خطأ فادح في وقت التشغيل يتعلق بجهاز Java الظاهري (JVM). يحدث هذا الخطأ عندما يتعذر على JVM تخصيص كائن بسبب عدم وجود ذاكرة كافية له، ولا يستطيع جامع البيانات المهملة تخصيص المزيد من الذاكرة. بعض أنواع OutOfMemoryError :-
OutOfMemoryError: مساحة كومة Java - لا يمكن تخصيص الكائن في كومة Java بسبب عدم كفاية الذاكرة. يمكن أن يحدث هذا الخطأ بسبب تسرب الذاكرة أو بسبب حجم الكومة الافتراضي الذي يكون صغيرًا جدًا بالنسبة للتطبيق الحالي.
-
OutOfMemoryError: تم تجاوز حد الحمل الزائد لـ GC - نظرًا لأن بيانات التطبيق بالكاد تتناسب مع الكومة، فإن أداة تجميع البيانات المهملة تعمل طوال الوقت، مما يتسبب في تشغيل برنامج Java ببطء شديد. ونتيجة لذلك، تم تجاوز الحد الأقصى لمجمع البيانات المهملة وتعطل التطبيق بسبب هذا الخطأ.
-
OutOfMemoryError: حجم الصفيف المطلوب يتجاوز حد VM - يشير هذا إلى أن التطبيق حاول تخصيص ذاكرة لصفيف يتجاوز حجم الكومة. مرة أخرى، قد يعني هذا أنه تم تخصيص ذاكرة غير كافية بشكل افتراضي.
-
OutOfMemoryError: Metaspace - نفدت المساحة المخصصة للبيانات التعريفية في الكومة (بيانات التعريف هي تعليمات للفئات والأساليب).
-
OutOfMemoryError: طلب بايتات الحجم لسبب ما. نفدت مساحة المبادلة - حدث خطأ ما عند محاولة تخصيص الذاكرة من الكومة، ونتيجة لذلك، تفتقر الكومة إلى مساحة كافية.

10. ما هو تتبع المكدس؟ كيف يمكنني الحصول عليه؟
تتبع المكدس عبارة عن قائمة بالفئات والأساليب التي تم استدعاؤها حتى هذه النقطة في تنفيذ التطبيق. يمكنك الحصول على تتبع المكدس عند نقطة معينة في التطبيق عن طريق القيام بذلك:StackTraceElement[] stackTraceElements =Thread.currentThread().getStackTrace(); في Java، عندما يتحدث الأشخاص عن تتبع المكدس، فإنهم عادةً ما يقصدون تتبع المكدس المعروض على وحدة التحكم عند حدوث خطأ (أو استثناء). يمكنك الحصول على تتبع المكدس من استثناءات مثل هذا:
في Java، عندما يتحدث الأشخاص عن تتبع المكدس، فإنهم عادةً ما يقصدون تتبع المكدس المعروض على وحدة التحكم عند حدوث خطأ (أو استثناء). يمكنك الحصول على تتبع المكدس من استثناءات مثل هذا:
StackTraceElement[] stackTraceElements;
try{
...
} catch (Exception e) {
stackTraceElements = e.getStackTrace();
}try{
...
} catch (Exception e) {
e.printStackTrace();
} وبناءً على هذه الملاحظة، سنختتم مناقشتنا لهذا الموضوع اليوم.
وبناءً على هذه الملاحظة، سنختتم مناقشتنا لهذا الموضوع اليوم.
GO TO FULL VERSION