
מהו ביטוי רגולרי (רגקס)?
למעשה, ביטוי רגולרי הוא דפוס למציאת מחרוזת בטקסט. ב-Java, הייצוג המקורי של דפוס זה הוא תמיד מחרוזת, כלומר אובייקט של המחלקהString. עם זאת, זה לא כל מחרוזת שניתן להרכיב לביטוי רגולרי - רק מחרוזות התואמות לכללים ליצירת ביטויים רגולריים. התחביר מוגדר במפרט השפה. ביטויים רגולריים נכתבים באמצעות אותיות ומספרים, וכן מטא-תווים, שהם תווים בעלי משמעות מיוחדת בתחביר הביטוי הרגיל. לדוגמה:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;יצירת ביטויים רגולריים ב-Java
יצירת ביטוי רגולרי ב-Java כרוכה בשני שלבים פשוטים:- כתוב אותו כמחרוזת התואמת לתחביר ביטוי רגולרי;
- קומפיל את המחרוזת לביטוי רגולרי;
Pattern. לשם כך, עלינו לקרוא לאחת משתי השיטות הסטטיות של המחלקה: compile. השיטה הראשונה לוקחת ארגומנט אחד - מחרוזת מילולית המכילה את הביטוי הרגולרי, בעוד שהשנייה לוקחת ארגומנט נוסף שקובע את הגדרות התאמת הדפוסים:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)flagsהפרמטר מוגדרת במחלקה Patternוזמינה לנו כמשתני מחלקה סטטיים. לדוגמה:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.Patternהמחלקה היא בנאי לביטויים רגולריים. מתחת למכסה המנוע, compileהשיטה קוראת Patternלבנאי הפרטי של המחלקה ליצור ייצוג הידור. מנגנון יצירת אובייקט זה מיושם כך על מנת ליצור אובייקטים בלתי ניתנים לשינוי. כאשר נוצר ביטוי רגולרי, התחביר שלו נבדק. אם המחרוזת מכילה שגיאות, PatternSyntaxExceptionנוצרת a.
תחביר ביטוי רגולרי
תחביר ביטוי רגולרי מסתמך על<([{\^-=$!|]})?*+.>התווים, אותם ניתן לשלב עם אותיות. בהתאם לתפקידם, ניתן לחלק אותם למספר קבוצות:
| מטא-תווים | תיאור |
|---|---|
| ^ | תחילת שורה |
| $ | סוף שורה |
| \ב | גבול מילים |
| \B | גבול לא מילים |
| \א | תחילת הקלט |
| \G | סוף המשחק הקודם |
| \Z | סוף הקלט |
| \z | סוף הקלט |
| מטא-תווים | תיאור |
|---|---|
| \ד | סִפְרָה |
| \D | לא ספרתי |
| \s | תו רווח לבן |
| \S | תו ללא רווח לבן |
| \w | תו אלפאנומרי או קו תחתון |
| \W | כל תו מלבד אותיות, מספרים וקווים תחתונים |
| . | כל דמות |

| מטא-תווים | תיאור |
|---|---|
| \t | תו הכרטיסייה |
| \n | דמות חדשה |
| \r | החזרת מרכבה |
| \f | דמות פיד שורה |
| \u0085 | תו השורה הבאה |
| \u2028 | מפריד שורות |
| \u2029 | מפריד פסקאות |
| מטא-תווים | תיאור |
|---|---|
| [א ב ג] | כל אחד מהתווים הרשומים (a, b, או c) |
| [^abc] | כל תו מלבד אלו הרשומים (לא a, b או c) |
| [a-zA-Z] | טווחים ממוזגים (תווים לטיניים מא' עד ת', לא תלוי רישיות) |
| [מודעה[mp]] | איחוד תווים (מ-a עד d ומ-m עד p) |
| [az&&[def]] | חיתוך של תווים (ד, ה, ו) |
| [az&&[^bc]] | חיסור של תווים (a, dz) |
| מטא-תווים | תיאור |
|---|---|
| ? | אחד או אף אחד |
| * | אפס או יותר פעמים |
| + | פעם אחת או יותר |
| {נ} | n פעמים |
| {נ,} | n פעמים או יותר |
| {נ,מ} | לפחות n פעמים ולא יותר מ-m פעמים |
מכמים חמדנים
דבר אחד שכדאי לדעת על מכמתים הוא שהם מגיעים בשלושה סוגים שונים: חמדנים, רכושניים וסרבנים. אתה הופך מכמת לרכושני על ידי הוספת+תו " " אחרי המכמת. אתה עושה את זה מסויג על ידי הוספת " ?". לדוגמה:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna AlexaA.+a", התאמת דפוסים מתבצעת באופן הבא:
-
התו הראשון בתבנית שצוינה היא האות הלטינית
A.Matcherמשווה אותו עם כל תו בטקסט, החל מאינדקס אפס. התוFנמצא באינדקס אפס בטקסט שלנו, כךMatcherשהוא חוזר על התווים עד שהוא תואם לתבנית. בדוגמה שלנו, תו זה נמצא באינדקס 5.![ביטויים רגולריים ב-Java - 2]()
-
ברגע שנמצא התאמה עם הדמות הראשונה של התבנית,
Matcherמחפש התאמה עם הדמות השנייה שלה. במקרה שלנו,.הדמות " " היא המייצגת כל תו.![ביטויים רגולריים ב-Java - 3]()
הדמות
nנמצאת במיקום השישי. זה בהחלט מתאים כהתאמה ל"כל דמות". -
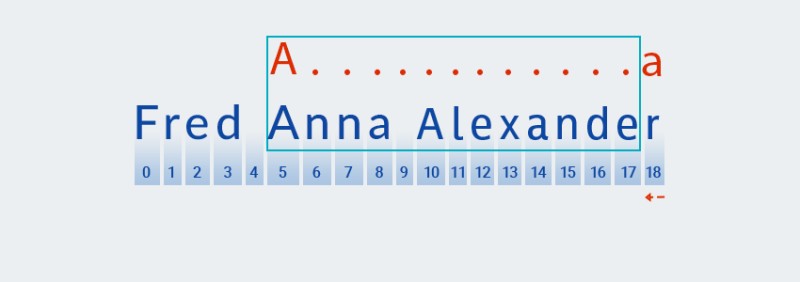
Matcherממשיך לבדוק את התו הבא של התבנית. בתבנית שלנו, הוא נכלל בכימת החל על התו הקודם: ".+". מכיוון שמספר החזרות של "כל תו" בתבנית שלנו הוא פעם אחת או יותר,Matcherלוקח שוב ושוב את התו הבא מהמחרוזת ובודק אותו מול התבנית כל עוד הוא מתאים ל"כל תו". בדוגמה שלנו - עד סוף המחרוזת (ממדד 7 לאינדקס 18).![ביטויים רגולריים ב-Java - 4]()
בעצם,
Matcherזולל את המיתר עד הסוף - זה בדיוק הכוונה ב"חמדן". -
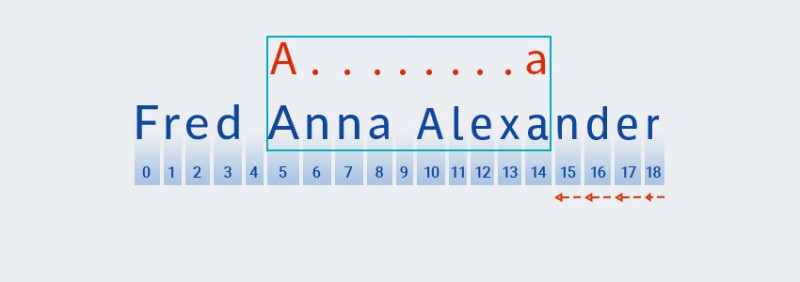
לאחר ש-Matcher מגיע לסוף הטקסט ומסיים את הסימון עבור
A.+החלק " " של התבנית, הוא מתחיל לבדוק את שאר התבנית:a. אין עוד טקסט קדימה, אז הבדיקה ממשיכה ב"התנתקות", החל מהתו האחרונה:![ביטויים רגולריים ב-Java - 5]()
-
Matcher"זוכר" את מספר החזרות בחלק ".+" של התבנית. בשלב זה, הוא מקטין את מספר החזרות באחת ובודק את הדפוס הגדול יותר מול הטקסט עד שנמצא התאמה:![ביטויים רגולריים ב-Java - 6]()



מכמתים רכושניים
מכמתים רכושניים דומים מאוד לחמדנים. ההבדל הוא שכאשר טקסט נקלט עד סוף המחרוזת, אין התאמת דפוסים בזמן "התנתקות". במילים אחרות, שלושת השלבים הראשונים זהים לאלה של מכמים חמדנים. לאחר לכידת המחרוזת כולה, המתאם מוסיף את שאר הדפוס למה שהוא שוקל ומשווה אותו למחרוזת שנלכדה. בדוגמה שלנו, באמצעות הביטוי הרגולרי "A.++a", השיטה הראשית לא מוצאת התאמה. 
מכמתים סרבנים
-
עבור מכמים אלה, כמו במגוון החמדן, הקוד מחפש התאמה על סמך התו הראשון של התבנית:
![ביטויים רגולריים ב-Java - 8]()
-
ואז הוא מחפש התאמה לדמות הבאה של התבנית (כל תו):
![ביטויים רגולריים ב-Java - 9]()
-
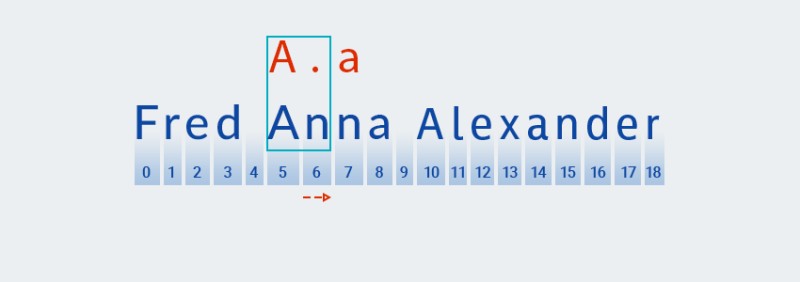
שלא כמו התאמת דפוסים חמדנית, ההתאמה הקצרה ביותר מחפשת בהתאמת דפוסים לא רצונית. המשמעות היא שלאחר מציאת התאמה עם התו השני של התבנית (נקודה, התואמת לתו במיקום 6 בטקסט,
Matcherבודקת אם הטקסט תואם לשאר התבנית - התו "a"![ביטויים רגולריים ב-Java - 10]()
-
הטקסט אינו תואם לתבנית (כלומר הוא מכיל את התו "
n" באינדקס 7), אזMatcherמוסיף עוד אחד "כל תו", מכיוון שהכמת מציין אחד או יותר. ואז זה שוב משווה את התבנית עם הטקסט במיקומים 5 עד 8:![ביטויים רגולריים ב-Java - 11]()


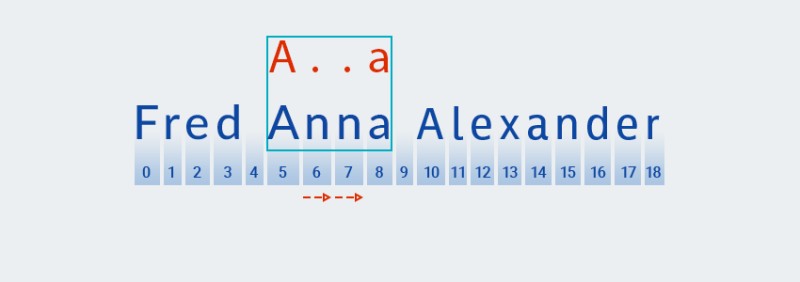
במקרה שלנו נמצא התאמה, אבל עדיין לא הגענו לסוף הטקסט. לכן, התאמת התבנית מתחילה מחדש ממיקום 9, כלומר מחפשים את התו הראשון של התבנית באמצעות אלגוריתם דומה וזה חוזר על עצמו עד סוף הטקסט.

mainהשיטה משיגה את התוצאה הבאה בעת שימוש בתבנית " A.+?a": Anna Alexa כפי שניתן לראות מהדוגמה שלנו, סוגים שונים של מכמתים מייצרים תוצאות שונות עבור אותה תבנית. אז זכור זאת ובחר את המגוון המתאים בהתאם למה שאתה מחפש.
תווים בורחים בביטויים רגולריים
מכיוון שביטוי רגולרי ב-Java, או ליתר דיוק, הייצוג המקורי שלו, הוא מילולי מחרוזת, עלינו לתת דין וחשבון לכללי ג'אווה לגבי מילולי מחרוזת. בפרט, התו האחורי "\" במילולי מחרוזת בקוד המקור של Java מתפרש כתו בקרה שאומר למהדר שהתו הבא הוא מיוחד ויש לפרש אותו בצורה מיוחדת. לדוגמה:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"\בתווים " " (כלומר כדי לציין תווים מטא) חייבים לחזור על ההלוכסים האחוריים כדי להבטיח שהמהדר של Java bytecode לא יפרש את המחרוזת בצורה לא נכונה. לדוגמה:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"שיטות של כיתת Pattern
לכיתהPatternיש שיטות נוספות לעבודה עם ביטויים רגולריים:
-
String pattern()‒ מחזירה את ייצוג המחרוזת המקורי של הביטוי הרגולרי ששימשה ליצירתPatternהאובייקט:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)- מאפשר לך לבדוק את הביטוי הרגולרי המועבר כ-regex מול הטקסט שהועבר כ-input. החזרות:true - אם הטקסט מתאים לתבנית;
שקר - אם לא;לדוגמה:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()‒ מחזירה את הערך של ערכת הפרמטרים של התבניתflagsכאשר התבנית נוצרה או 0 אם הפרמטר לא הוגדר. לדוגמה:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)- מפצל את הטקסט המועבר למערךString. הפרמטרlimitמציין את המספר המרבי של התאמות שחיפשו בטקסט:- אם
limit > 0‒limit-1תואם; - אם
limit < 0‒ כל תואמים בטקסט - אם
limit = 0‒ כל ההתאמות בטקסט, מחרוזות ריקות בסוף המערך נמחקות;
לדוגמה:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }פלט מסוף:
Fred Anna Alexa --------- Fred Anna Alexaלהלן נשקול עוד אחת מהשיטות של המחלקה המשמשות ליצירת אובייקט
Matcher. - אם
שיטות של כיתת Matcher
מופעים שלMatcherהמחלקה נוצרים כדי לבצע התאמת דפוסים. Matcherהוא "מנוע החיפוש" לביטויים רגולריים. כדי לבצע חיפוש, עלינו לתת לו שני דברים: דפוס ואינדקס התחלתי. כדי ליצור Matcherאובייקט, Patternהמחלקה מספקת את השיטה הבאה: рublic Matcher matcher(CharSequence input) השיטה לוקחת רצף תווים, אשר יבוצע חיפוש. זהו מופע של מחלקה המיישמת את CharSequenceהממשק. אתה יכול לעבור לא רק String, אלא גם StringBuffer, StringBuilder, Segmentאו CharBuffer. התבנית היא Patternאובייקט שעליו matcherנקראת השיטה. דוגמה ליצירת תואם:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"
boolean find()מחפשת את ההתאמה הבאה בטקסט. אנו יכולים להשתמש בשיטה זו ובמשפט לולאה כדי לנתח טקסט שלם כחלק ממודל אירועים. במילים אחרות, אנו יכולים לבצע פעולות נחוצות כאשר מתרחש אירוע, כלומר כאשר אנו מוצאים התאמה בטקסט. לדוגמה, אנו יכולים להשתמש במחלקה זו int start()ובשיטות int end()כדי לקבוע את מיקומה של התאמה בטקסט. ונוכל להשתמש בשיטות String replaceFirst(String replacement)ו String replaceAll(String replacement)כדי להחליף התאמות בערך של פרמטר ההחלפה. לדוגמה:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna AlexareplaceFirstויוצרות אובייקט replaceAllחדש String- מחרוזת שבה התאמות דפוס בטקסט המקורי מוחלפות בטקסט המועבר למתודה כארגומנט. בנוסף, replaceFirstהשיטה מחליפה רק את ההתאמה הראשונה, אך replaceAllהשיטה מחליפה את כל ההתאמות בטקסט. הטקסט המקורי נשאר ללא שינוי. פעולות ה- Regex השכיחות ביותר של Patternהמחלקות Matcherמובנות ישירות לתוך Stringהמחלקה. אלו הן שיטות כגון split, matches, replaceFirstו replaceAll. אבל מתחת למכסה המנוע, שיטות אלה משתמשות במחלקות Patternו Matcher. אז אם אתה רוצה להחליף טקסט או להשוות מחרוזות בתוכנה מבלי לכתוב קוד נוסף, השתמש בשיטות של המחלקה String. אם אתה צריך תכונות מתקדמות יותר, זכור את השיעורים Patternו Matcher.
סיכום
בתוכנת Java, ביטוי רגולרי מוגדר על ידי מחרוזת המצייתת לכללי התאמת דפוסים ספציפיים. בעת ביצוע קוד, מכונת Java מרכיבה מחרוזת זו לאובייקטPatternומשתמשת Matcherבאובייקט כדי למצוא התאמות בטקסט. כפי שאמרתי בהתחלה, לעתים קרובות אנשים דוחים ביטויים קבועים למועד מאוחר יותר, ורואים בהם נושא קשה. אבל אם אתה מבין את התחביר הבסיסי, המטא-תווים והבריחה של התווים, ותלמד דוגמאות של ביטויים רגולריים, אז תגלה שהם הרבה יותר פשוטים ממה שהם נראים במבט ראשון.
|
קריאה נוספת: |
|---|
GO TO FULL VERSION