Idag är vår uppgift att slutföra det andra projektet om Hibernate-ämnet. Dess kärna är att förstå strukturen i databasen, mappa entiteten till befintliga tabeller och lägga till minsta möjliga funktionalitet för att kontrollera att mappningen görs korrekt.
Nu mer i detalj:
- Ladda ner dumpfilen och distribuera den till din lokala dator. Som databas kommer vi att använda en testdatabas, som distribueras som ett exempel tillsammans med installationspaketet MySQL. Dumpningen behövs för att fixa tillståndet för databasen, eftersom vi inte kan garantera att den inte kommer att ändras under en dag, månad, år.
- Vi kommer inte att ha någon projektmall, så skapa projektet själv. Det borde vara ett maven-projekt med alla nödvändiga beroenden ( hibernate-core-jakarta , mysql-connector-java , p6spy ).
- Koppla in vår lokalt distribuerade databas som en datakälla i Idea. Efter det, på fliken Databas, placera markören på filmschemat och tryck på tangentkombinationen (
Alt+Ctrl+Shift+Ufungerar bara i Ultimate-versionen). Detta kommer att visa strukturen för hela filmschemat (med kolumnnamn, nycklar, etc.). Ser ut så här:![]()
Jag håller med, det är inte särskilt bekvämt att titta på. Stäng av visningen av rubriken för alla kolumner och kommentarer:
![]()
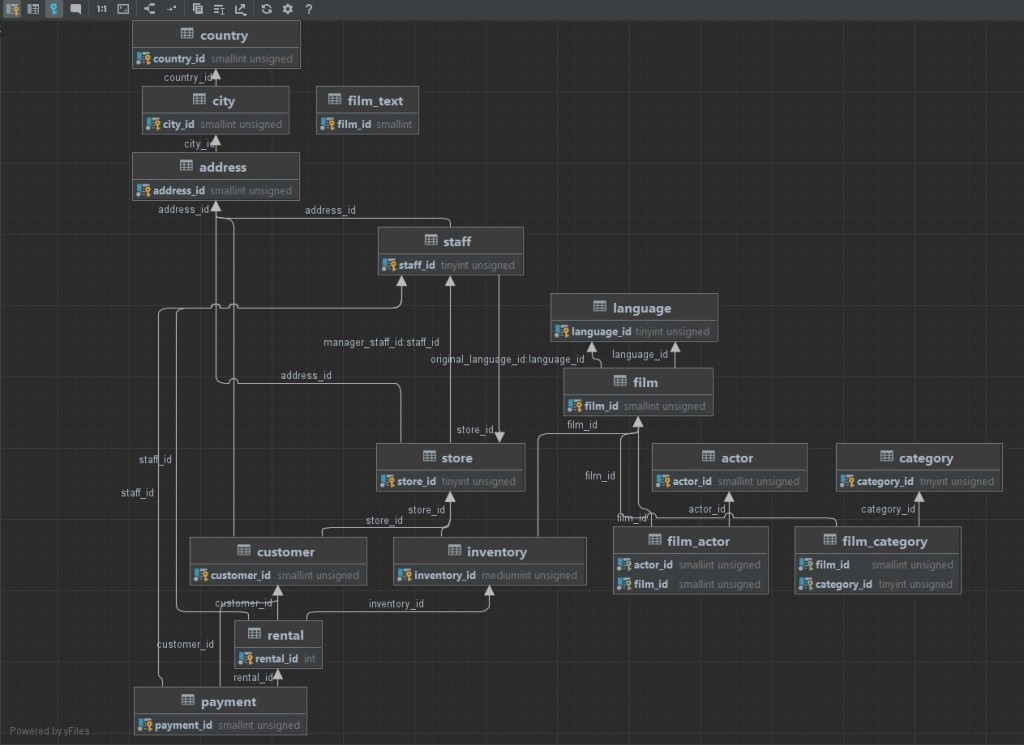
Som ett resultat får du ett databasschema som redan kan analyseras:
![]()
- Kretsen ser komplicerad ut, men allt är inte så illa. För att analysera strukturen i databasen måste du hitta var du ska börja. Det finns inget rätt svar, men jag skulle rekommendera att börja med en tabell
film. Låt oss ta några relationer som exempel:- Relationen mellan tabeller
filmochfilm_textär en explicit OneToOne- relation , eftersom tabellenfilm_texthar ett fältfilm_idsomINTErefererar till ett ID från en tabellfilm(ingen främmande nyckel). Men av namn och logik borde detta samband vara.film_textDessutom fungerar fältet i tabellenfilm_idsom en primärnyckel, vilket garanterar att en "film" inte motsvarar mer än en "filmtext". - Låt oss nu titta på tabeller
filmochcategory. Logiskt sett kan en film ha flera kategorier. Och en kategori, kanske olika filmer. Dessutom finns det en mellanliggande länktabell mellan dessa två tabellerfilm_category. Baserat på allt ovanstående är detta ett uttryckligt ManyToMany- förhållande . - Vi tittar på borden
filmochlanguage. Ur logisk synvinkel kan filmen ha en översättning till olika språk och olika filmer kan vara på samma språk. Det vill säga, ManyToMany föreslår sig själv . Men om vi tittar på innehållet i tabellenfilmkan vi se att varje rad i tabellen är en unik film. Och det finns bara ett language_id- fält i raden (det finns också original_language_id, men i alla poster är det null, så vi kan ignorera det). Det vill säga att en film bara kan ha ett språk. Och ett språk, kanske olika filmer. Kopplingen är ManyToOne (kopplingen är riktad från film till språk).
- Relationen mellan tabeller
- Nu är huvuduppgiften att skapa alla nödvändiga entitetsklasser och mappa dem till schematabellerna
movie. - Lägg till en metod som kan skapa en ny kund (kundtabell) med alla beroende fält. Glöm inte att göra metoden transaktionell (för att inte hamna i situationen att köparens adress är registrerad i databasen, men köparen själv är det inte).
- Lägg till en transaktionsmetod som beskriver händelsen "kunden gick och returnerade en tidigare hyrd film". Välj valfri köpare och uthyrningsevenemang. Filmens betyg behöver inte räknas om.
- Lägg till en transaktionsmetod som beskriver händelsen ”köparen gick till butiken (butiken) och hyrde (hyr) inventariet (inventariet) där. Samtidigt gjorde han en betalning (betalning) till säljaren (personalen). Film (genom inventering) välj efter eget gottfinnande. Den enda begränsningen är att filmen måste kunna hyras. Det vill säga, antingen ska det inte finnas några lagerposter i uthyrning alls, eller så ska kolumnen return_date i tabellen
rentalför den senaste uthyrningen av detta inventarium fyllas i. - Lägg till en transaktionsmetod som beskriver händelsen "en ny film spelades in och den blev tillgänglig för uthyrning." Film, språk, skådespelare, kategorier etc., välj efter eget gottfinnande.
- Tabellstrukturen kan inte ändras. Men du måste komma med förslag på förbättringar. Vi identifierade en problematisk plats i punkt 4 (avsaknad av främmande nyckel i tabellen
film_textifilm_idtabellfältetfilm). Se om det fortfarande finns sådana "misstag" i databasstrukturen. Om så är fallet, lägg till en readme-fil i roten av projektet och beskriv dessa misstag.



Projektanalys:
GO TO FULL VERSION