"Ciao, Amico!"
"CIAO!"
"Oggi ti parlerò dei sistemi di controllo della versione."
"Come probabilmente già saprai, i programmi sono spesso molto grandi e richiedono molto tempo per essere scritti. A volte decine di persone possono passare anni a scrivere un programma."
"I progetti con milioni di righe di codice sono una realtà."
"Ehi."
"È tutto molto complicato. Le persone spesso interferiscono tra loro e spesso modificano lo stesso codice, e così via."
"Per mettere ordine in questo pasticcio, i programmatori hanno iniziato a utilizzare i sistemi di controllo della versione per il loro codice."
" Un sistema di controllo della versione è un programma costituito da un client e un server.
"Il programma memorizza i dati (il codice scritto dai programmatori) su un server e i programmatori li aggiungono o li modificano utilizzando i client."
"La principale differenza tra un sistema di controllo della versione e i programmi che consentono semplicemente di lavorare in modo collaborativo sui documenti è che memorizza tutte le versioni precedenti di tutti i documenti (file di codice)."

"Puoi darmi maggiori dettagli. Come funziona?"
"Immagina di essere un programmatore e di voler apportare piccole modifiche al codice sorgente di un programma archiviato in un repository sul server."
"Ecco cosa devi fare:"
"1) Accedi al server."
"2) Copia l'ultima versione di tutti i file sul tuo computer usando il comando Checkout."
"3) Apportare modifiche ai file richiesti."
"4) Esegui il programma in locale per assicurarti che venga compilato ed eseguito."
"5) Invia le tue 'modifiche' al server usando il comando Commit."
"In genere ha senso."
"Ma c'è di più. Immagina di arrivare al lavoro la mattina, ma è già ora di pranzo in India. Quindi i tuoi colleghi indiani hanno già apportato modifiche e le hanno salvate nel tuo repository sul server."
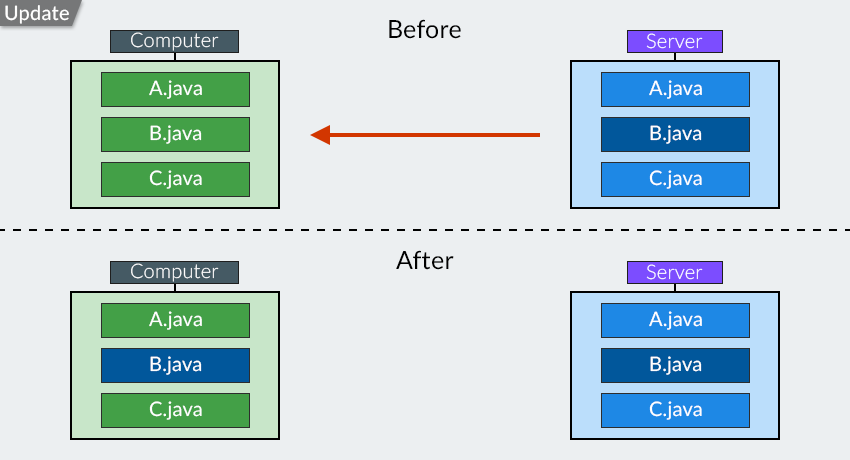
"Devi lavorare con l'ultima versione del codice. Quindi esegui il comando Aggiorna ."
"In che modo è diverso da Checkout ?"
" Checkout è progettato per copiare tutti i file del repository, ma Update aggiorna solo i file che sono stati aggiornati sul server dall'ultima volta che hai eseguito un comando Checkout / Update ."
"Questo è più o meno come funziona:"
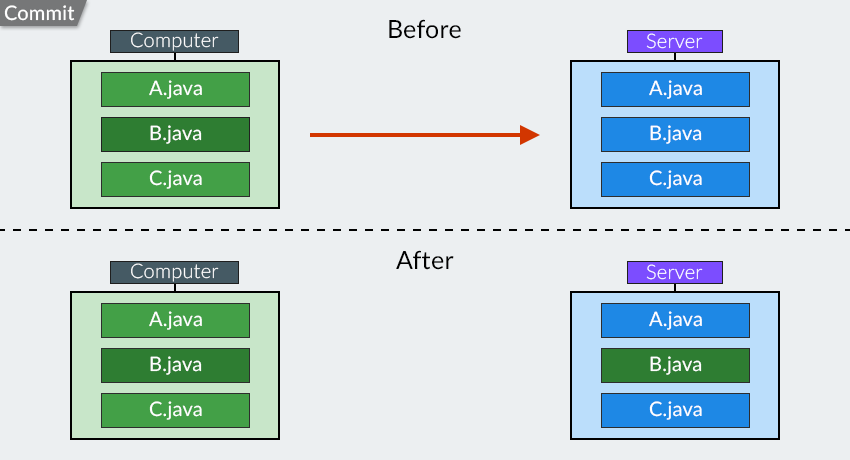
Pagamento :

"Ora, supponiamo di aver modificato il file B e di volerlo caricare sul server. Per fare ciò, dobbiamo utilizzare il comando Commit ."
"Ed ecco come funziona il comando Aggiorna :"
"Che interessante! Ci sono altri comandi?"
"Sì, ce ne sono parecchi. Ma variano a seconda del programma di controllo della versione che scegli. Quindi, sto solo cercando di spiegare i principi generali."
"Esiste anche un'operazione chiamata unione: l'unione di due documenti. Supponiamo che due programmatori modifichino lo stesso file contemporaneamente. Allora il programma sul server non consentirà il commit di entrambe le modifiche. o i suoi cambiamenti."
"Allora cosa fa l'altra persona?"
"Lui o lei sarà invitato a eseguire un'operazione di aggiornamento per acquisire le ultime modifiche dal server. A proposito, questo - fare un aggiornamento prima di impegnarsi - è una buona pratica."
"Quindi, durante l'operazione di aggiornamento, il programma client tenterà di unire le modifiche locali con le modifiche ricevute dal server."
"Se i programmatori hanno modificato diverse parti del file, il programma di controllo della versione sarà probabilmente in grado di unirle correttamente. Se le modifiche si trovano nello stesso punto, il programma di controllo della versione segnalerà un conflitto di unione e chiederà all'utente di unire le modifiche."
"Ad esempio, questo accade spesso quando entrambi i programmatori aggiungono qualcosa alla fine di un file."
"Capisco. Nel complesso, sembra ragionevole."
"E c'è un'altra cosa: i rami."
"Immagina che due programmatori di un team abbiano il compito di riscrivere lo stesso modulo. O ancora meglio, di riscriverlo da zero. Fino a quando questo modulo non sarà completato, il programma non sarà in grado di funzionare e potrebbe anche non essere compilato."
"Allora cosa dovrebbero fare?"
"Vanno avanti aggiungendo rami al repository. In parole povere, questo significa che il repository viene diviso in due parti. Non per file o directory, ma per versioni."
"Immagina che l'elettricità non sia mai stata scoperta e che i robot non siano mai stati inventati. Allora le tre guerre di liberazione non sarebbero mai accadute e tutta la storia umana avrebbe seguito un percorso completamente diverso. "
"Questo percorso è un ramo alternativo della storia".
"Oppure puoi semplicemente provare a immaginare un ramo semplicemente come una copia del repository. In altre parole, a un certo punto, abbiamo creato un clone del repository sul server, in modo che, oltre al repository principale (spesso chiamato trunk ), abbiamo un altro ramo ."
"Beh, questo mi sembra più comprensibile.
"Perché non potevi semplicemente dire che abbiamo copiato il repository?"
"Questa non è una semplice copia."
"Questi rami non solo possono essere separati dal tronco, ma anche fusi in esso."
"In altre parole, è possibile eseguire del lavoro in un ramo e poi, quando è finito, è possibile aggiungere il ramo del repository al trunk del repository?"
"Sì."
"E cosa succederà ai file?"
"I file verranno uniti."
"Beh, suona bene. Spero che sia altrettanto bello in azione."
"E poi un po'. Ok, facciamo una pausa."
"Ci sono un sacco di informazioni utili qui "
GO TO FULL VERSION