Wstęp
W prawie wszystkich programach istnieje potrzeba przechowywania zestawu dowolnych danych. Mogą to być ciągi i liczby, obiekty i tak dalej. Do tego celu idealnie nadają się tablice. Ale tablice mają pewne ograniczenia. Na przykład stały rozmiar, brak możliwości usunięcia elementów, wstawienia elementów w środku. Kolekcje zostały stworzone, aby obejść to i inne ograniczenia. Wszystkie typy kolekcji (a jest ich wiele, jak zobaczymy w dalszej części tego rozdziału) mają możliwość dynamicznej zmiany rozmiaru. Niektóre typy kolekcji mogą przechowywać uporządkowane elementy i automatycznie porządkować nowe elementy w miarę ich dodawania.
Podczas tego wykładu przyjrzymy się podstawowej hierarchii klas kolekcji Java Collections Framework . Istnieją również różne biblioteki alternatywne, które rozszerzają możliwości standardowej platformy Java Collections Framework . Najpopularniejszym z nich jest Guava (Google Collections Library).
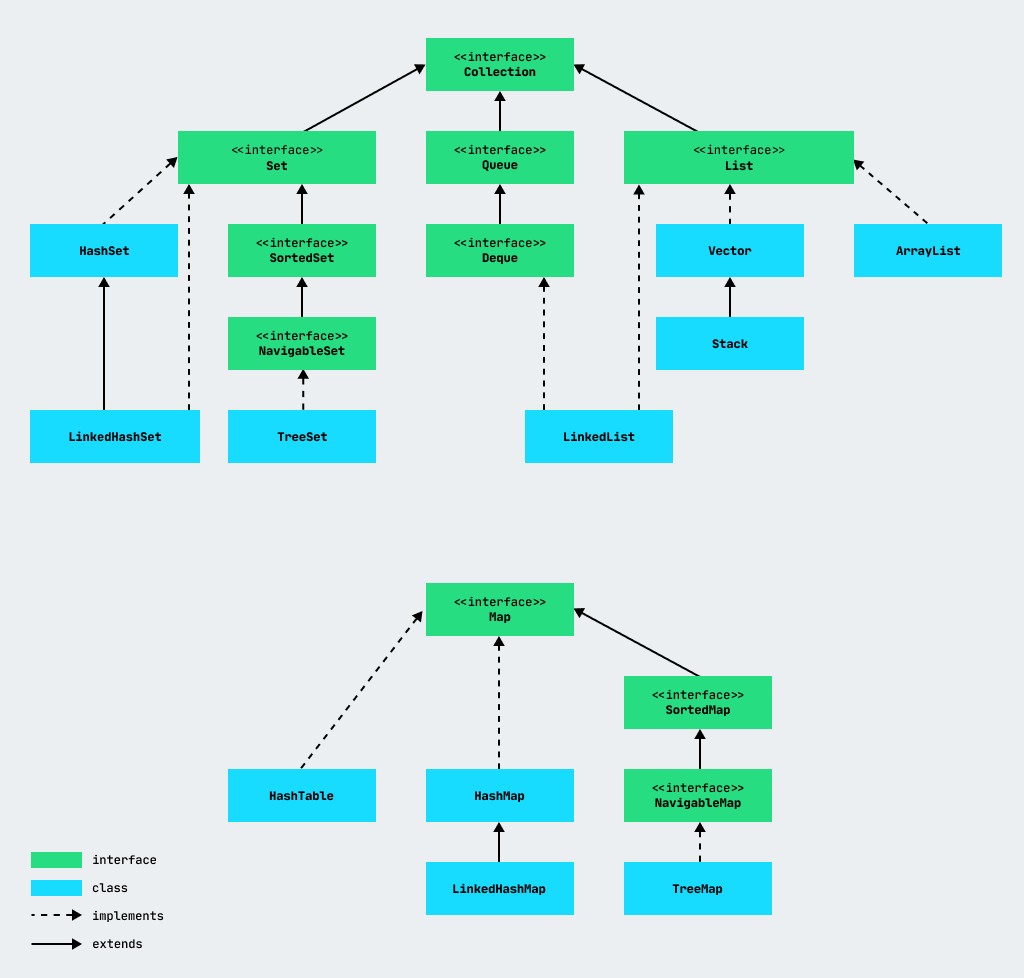

Główne interfejsy
Diagram pokazuje, że istnieją dwa główne interfejsy, z których implementowane są pozostałe klasy i interfejsy kolekcji.
Przyjrzyjmy się tym interfejsom:
-
Kolekcja to zwykła kolekcja zawierająca zestaw pojedynczych elementów (obiektów). Ta kolekcja ma główne metody pracy z elementami: wstawianie ( add , addAll ), usuwanie ( remove , removeAll , clear ), wyszukiwanie ( zawiera , zawieraAll ), sprawdzanie, czy kolekcja jest pusta ( isEmpty ) i rozmiar ( size ).
-
Mapa to kolekcja, której struktura to pary klucz-wartość. Co więcej, w ramach jednej Mapy każdy klucz jest unikalny: nie ma dwóch kluczy o identycznej wartości. Ponadto ta kolekcja jest czasami nazywana słownikiem . Mapa to osobny interfejs. Nie implementuje interfejsu Collection , ale jest częścią Java Collections Framework .
Podstawowe metody pracy z elementami mapy :
-
wstaw ( umieść , umieść wszystko )
-
pobieranie ( pobieranie , zestaw kluczy , wartości , zestaw wpisów )
-
usuwanie ( usuwać , usuwać )
-
szukaj ( zawieraKlucz , zawieraWartość )
-
sprawdzanie, czy kolekcja jest pusta ( isEmpty )
-
rozmiar _ _
Teraz porozmawiajmy więcej o każdym z nich.
Interfejs kolekcji
Interfejs Collection rozszerza interfejs Iterable , a ten interfejs ma pojedynczą metodę iterator() . Dla nas oznacza to, że każda kolekcja, która dziedziczy po Iterable , będzie mogła zwrócić iterator.
Iterator to specjalny obiekt, za pomocą którego można uzyskać dostęp do elementów dowolnej kolekcji, niezależnie od specyfiki jej implementacji.
Na rysunku widać, że 3 interfejsy są dziedziczone z interfejsu Collection : List , Queue i Set . Przyjrzyjmy się teraz pokrótce każdemu z nich.
Lista to uporządkowana kolekcja, która pozwala na duplikaty między wartościami. Możesz także znaleźć inne nazwy - sekwencja (sekwencja), lista. Cechą listy jest to, że elementy są ponumerowane i można uzyskać do nich dostęp za pomocą numeru (indeksu).
Kolejka - przetłumaczona z angielskiego jakokolejka. Poprawna wymowa: Kolejka - KYU. Kolejkaprzechowuje elementy w kolejności, w jakiej zostały dodane do kolejki .
Zestaw - w przeciwieństwie do listy, opisuje zbiór nieuporządkowany, w którym nie ma powtórzeń elementów. Zbiórodpowiada pojęciu w matematyce - m zbiór ( zbiór ).
Implementacje interfejsu Map
W interfejsie mapy możemy zobaczyć stosunek unikalnych kluczy do wartości.
interface Map<K, V>
gdzie K to typ kluczy, a V to typ przechowywanych wartości.
Według klucza możemy wyodrębnić dane z Map . Aby dodać element do mapy, musisz określić klucz i wartość.
Rozważ niektóre implementacje Map :
-
HashMap to implementacja mapy oparta na tablicach skrótów. Może przechowywać klucze i wartości dowolnego typu, w tym null . Kolejność elementów nie jest gwarantowana.
-
LinkedHashMap to struktura danych, która przechowuje dane jako połączoną listę elementów. Elementy są wymienione w kolejności, w jakiej zostały dodane.
-
TreeMap — Implementuje interfejs SortedMap (przez NavigableMap ). Elementy w takiej strukturze są przechowywane w postaci posortowanej (po dodaniu nowego elementu kolekcja jest sortowana automatycznie). TreeMap doskonale nadaje się do przechowywania dużych ilości posortowanych informacji w celu szybkiego wyszukiwania.
Starsze kolekcje
Z poprzednich wersji Javy pozostały przestarzałe kolekcje (w celu zachowania kompatybilności wstecznej), których nie zaleca się używać:
-
Wyliczanie jest analogiczne do interfejsu Iteratora ;
-
Vector - uporządkowana lista elementów, analogiczna do klasy ArrayList ;
-
Stack – struktura realizująca przechowywanie elementów na zasadzie stosu (np. stos książek), istnieją metody pchania ( push ) i pchania ( pop ) elementów;
-
Dictionary jest podobny do interfejsu Map , ale jest klasą abstrakcyjną;
-
Hashtable jest analogiczne do HashMap .
Możesz przeczytać więcej na temat Collections Framework w tym artykule .
GO TO FULL VERSION