1. Przyczyny ucieczki postaci
Dawno, dawno temu dowiedziałeś się, że aby napisać ciąg znaków w kodzie, musisz ująć te znaki w podwójny cudzysłów: otrzymujesz literał łańcuchowy .
Ale co, jeśli potrzebujemy, aby cudzysłowy znalazły się wewnątrz literału łańcuchowego? Ciąg zawierający cudzysłowy - co może być prostszego.
Powiedzmy, że chcemy wyświetlić tekst Фильм "Друзья" номинирован на "Оскар". Jak to zrobić?
| Kod | Notatki |
|---|---|
|
Ta opcja nie zadziała! |
Chodzi o to, że według kompilatora napisany jest tutaj zupełnie inny kod:
| Kod | Notatki |
|---|---|
|
Ta opcja nie zadziała! |
Gdy kompilator napotka podwójne cudzysłowy w kodzie, uzna je za początek literału łańcuchowego. Następne podwójne cudzysłowy to koniec literału łańcuchowego.
Jak więc umieścić podwójne cudzysłowy w literale?
2. Uciekające postacie
Jest na to sposób, dali mu nawet nazwę – postać uciekająca . Po prostu wpisujesz cudzysłowy w wierszu tekstu i dodajesz znak przed cudzysłowami \( ukośnik odwrotny lub ukośnik odwrotny lub ukośnik odwrotny ).
Oto jak wyglądałby poprawnie napisany literał łańcuchowy:
| Kod | Notatki |
|---|---|
|
To będzie działać! |
Kompilator zrozumie wszystko poprawnie i nie uzna cudzysłowów po odwrotnym ukośniku za zwykłe cudzysłowy.
Ponadto, jeśli wydrukujesz ten ciąg na ekranie, cudzysłowy z odwrotnymi ukośnikami zostaną poprawnie przetworzone, a tekst bez odwrotnego ukośnika zostanie wyświetlony na ekranie:Фильм "Друзья" номинирован на "Оскар"

Kolejny ważny punkt. Cudzysłowy poprzedzone odwrotnym ukośnikiem to jeden znak: po prostu używamy tej trudnej notacji, aby nie uniemożliwić kompilatorowi rozpoznawania literałów łańcuchowych w kodzie. Możesz przypisać cudzysłowy do zmiennej char:
| Kod | Notatki |
|---|---|
|
\"to jeden znak, a nie dwa |
|
jest to również możliwe: podwójny cudzysłów wewnątrz pojedynczych cudzysłowów |
3. Częste sytuacje podczas ucieczki postaci

Oprócz podwójnych cudzysłowów istnieje wiele innych znaków, które są traktowane inaczej przez kompilator. Na przykład przerwa w linii.
Jak dodać podział linii do literału? Istnieje również specjalna kombinacja do tego:
\nJeśli chcesz dodać koniec wiersza do literału łańcuchowego, wystarczy dodać kilka znaków - \n.
Przykład:
| Kod | Wyjście na wyświetlaczu |
|---|---|
|
|
W sumie jest 8 takich specjalnych kombinacji: są one również nazywane sekwencjami ucieczki , oto one:
| Kod | Opis |
|---|---|
\t |
Wstaw znak tabulacji |
\b |
Wstaw znak powrotu jeden znak |
\n |
Wstaw znak nowej linii |
\r |
Wstaw powrót karetki |
\f |
Wstaw symbol kanału strony |
\' |
Wstaw pojedynczy cytat |
\" |
Wstaw podwójny cudzysłów |
\\ |
Wstaw ukośnik odwrotny |
Spotkałeś dwóch z nich, ale co oznacza pozostałych 6?
Znak tabulacji -\t
Ten znak w tekście jest równoznaczny z naciśnięciem klawisza na klawiaturze Tabpodczas pisania. Przesuwa następujący po nim tekst, aby go wyrównać.
Przykład:
| Kod | Wyjście na wyświetlaczu |
|---|---|
|
|
Cofnij się o jedną postać -\b
Ten znak w tekście jest równoznaczny z naciśnięciem klawisza na klawiaturze Backspacepodczas pisania. Usuwa ostatni wydrukowany znak przed nim:
| Kod | Wyjście na wyświetlaczu |
|---|---|
|
|
Znak powrotu karetki -\r
Ten znak przesuwa kursor na początek bieżącego wiersza bez zmiany tekstu. Następny tekst wyjściowy nadpisze istniejący.
Przykład:
| Kod | Wyjście na wyświetlaczu |
|---|---|
|
|
Symbol kanału strony -\f
Symbol ten zawędrował do nas z czasów pierwszych drukarek igłowych. Jeśli taki znak został wydrukowany, powodowało to, że drukarka po prostu przewijała bieżący arkusz bez drukowania tekstu, aż zaczął się nowy.
Teraz nazwalibyśmy to podziałem strony lub nową stroną .
Ukośnik wsteczny -\\
Cóż, tutaj wszystko jest proste. Jeśli użyjemy odwrotnego ukośnika (ukośnika odwrotnego) w tekście do zmiany znaczenia znaków, to w jaki sposób zapiszemy sam ukośnik w ciągu tekstowym?
To proste: aby dodać znak ukośnika odwrotnego do tekstu , musisz napisać go dwa razy z rzędu.
Przykład:
| Kod | Wyjście na wyświetlaczu |
|---|---|
|
Kompilator będzie narzekał na nieznane znaki ucieczki. |
|
Zgadza się! |
4. Kodowanie Unicode
Jak już wiesz, każdemu znakowi wyświetlanemu na ekranie odpowiada określony kod numeryczny. Standaryzowany zestaw takich kodów nazywa się kodowaniem .
Dawno, dawno temu, kiedy komputery dopiero powstawały, do zakodowania wszystkich znaków wystarczyło siedem bitów (mniej niż jeden bajt) - pierwsze kodowanie zawierało tylko 128 znaków. To kodowanie nazwano ASCII .
ASCII (American Standard Code for Information Interchange) to amerykańska standardowa tabela kodowania znaków drukowalnych i niektórych kodów specjalnych.
Składał się z 33 niedrukowalnych znaków kontrolnych (wpływających na przetwarzanie tekstu i spacji) oraz 95 znaków drukowalnych, w tym cyfr, małych i wielkich liter alfabetu łacińskiego oraz pewnej liczby znaków interpunkcyjnych.
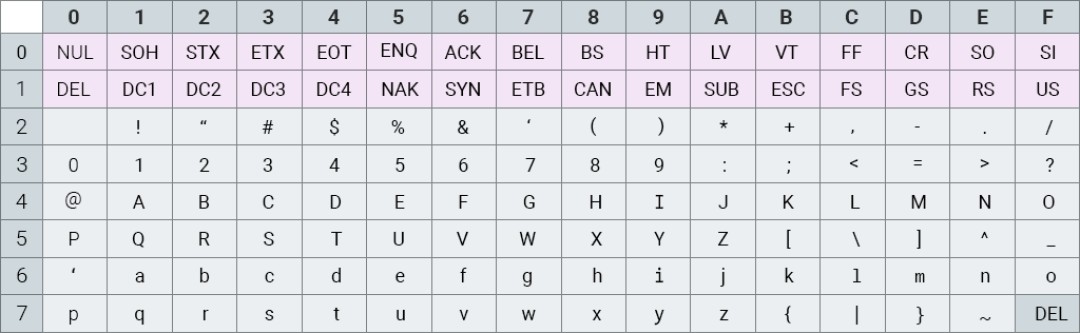
Wzrost popularności komputerów doprowadził do tego, że każdy kraj zaczął wydawać własne kodowanie. Zwykle za podstawę przyjmowano ASCII, a rzadko używane znaki zastępowano znakami alfabetów narodowych.
Z czasem pojawił się pomysł: stworzyć jedno kodowanie, w którym zmieściłyby się wszystkie znaki ze wszystkich światowych kodowań.

W 1993 roku stworzono kodowanie Unicode , a język Java był pierwszym językiem programowania, który używał go jako standardu przechowywania tekstu. Teraz Unicode jest standardem dla całej branży IT.
I chociaż sam Unicode jest standardem, ma kilka form reprezentacji (format transformacji Unicode, UTF): UTF-8, UTF-16 i UTF-32 itd.
Java wykorzystuje zaawansowaną formę kodowania Unicode - UTF-16: każdy znak, w którym został zakodowany w 16 bitach (2 bajtach). Może pomieścić do 65 536 znaków!
W tym kodowaniu można znaleźć prawie wszystkie znaki wszystkich alfabetów świata. Ale oczywiście nikt nie zna tego na pamięć: nie możesz wiedzieć wszystkiego, ale możesz wszystko wygooglować.
Aby napisać znak Unicode zgodnie z jego kodem w kodzie programu, musisz napisać \u+ cyfry kodu szesnastkowego . Na przykład\u00A9
| Kod | Wyjście na wyświetlaczu |
|---|---|
|
|
5. Unicode: punkt kodu
640 kilobajtów wystarczy dla każdego! Albo nie. (Cytat przypisywany Billowi Gatesowi)
Życie to trudna rzecz, a kodowanie UTF-16 w końcu zaczęło brakować. Okazało się, że w Azji jest dużo języków i mają dużo hieroglifów. A wszystkich hieroglifów po prostu nie da się zmieścić w 2 bajtach.
I co robić? Użyj więcej bajtów !
Ale typ char zajmuje tylko 2 bajty, a zmiana go na 4 nie jest taka łatwa: na świecie są miliardy wierszy kodu Java, które nie będą działać poprawnie, jeśli typ char nagle zmieni się na 4 bajty w maszynie Java. Więc nie możesz zmienić typu znaku!
Istnieje inne podejście. Przypomnij sobie, jak zmienialiśmy znaki za pomocą przedrostka ukośnika. Zasadniczo zakodowaliśmy jeden znak z wieloma znakami.
Programiści Javy postanowili zastosować to samo podejście.
Niektóre znaki, które wizualnie wyglądają jak pojedynczy znak, są zakodowane jako dwie charw ciągu:
| Kod | Wyjście na wyświetlaczu |
|---|---|
|
|
Teraz Twój program Java może nawet drukować emotikony na konsoli 😎
GO TO FULL VERSION