1. Zadania programisty
Bardzo często początkujący programiści wyobrażają sobie istotę pracy programisty zupełnie inaczej niż doświadczeni programiści .
Od początkującego często można usłyszeć „Program działa, czego jeszcze potrzebujesz?”. Doświadczony programista wie, że "działa poprawnie" - to tylko jedno z wymagań stawianych programowi , i to nawet nie najważniejsze !
Czytelność kodu
Najważniejsze jest to, aby kod programu był zrozumiały dla innych programistów . To jest ważniejsze niż poprawnie działający program. O wiele ważniejsze.
Jeśli masz program, który nie działa poprawnie, możesz go naprawić, a jeśli masz program, który nie rozumie kodu, nie możesz nic z tym zrobić.
Wystarczy wziąć dowolny skompilowany program, na przykład notatnik (notatnik) i zmienić jego kolor tła na czerwony. Masz działający program, ale nie masz jasnego kodu programu: nie można wprowadzać zmian w takim programie.
Podręcznikowym przykładem jest sytuacja, w której Microsoft usunął grę Pinball z systemu Windows, ponieważ nie mógł przenieść jej do architektury 64-bitowej. Mieli nawet jego kod źródłowy. Po prostu nie mogli zrozumieć, jak działa napisany kod.

Rozliczanie dla wszystkich przypadków użycia
Drugim najważniejszym wymogiem wobec programu jest uwzględnienie wszystkich scenariuszy jego pracy. Często sprawy są trochę bardziej skomplikowane, niż się wydaje.
Jak początkujący programista widzi wysyłanie SMS-ów w swoim programie:
Jak widzi to profesjonalny programista:
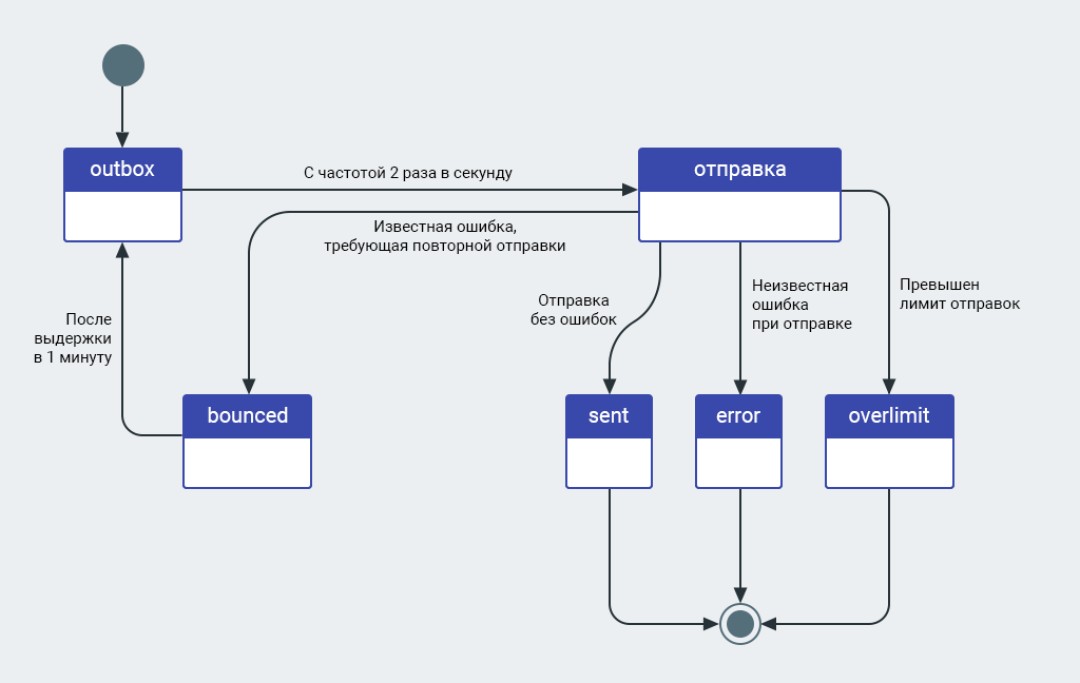
A „robienie tego dobrze” to zwykle tylko jeden z wielu scenariuszy. I dlatego wielu nowicjuszy narzeka na walidator zadań w CodeGym: jeden skrypt na 10 działa, a początkujący programista myśli, że to wystarczy.
2. Sytuacje awaryjne

Podczas działania dowolnego programu mogą wystąpić nietypowe sytuacje.
Na przykład decydujesz się zapisać plik, ale na dysku nie ma miejsca. Lub program próbuje zapisać dane w pamięci, ale brakuje jej pamięci. Lub pobierasz zdjęcie z Internetu, a połączenie zostało utracone podczas procesu pobierania.
Programista (autor programu) musi a) przewidzieć każdą sytuację awaryjną , b) zdecydować, jak dokładnie program ma działać w tej sytuacji , c) zaprogramować rozwiązanie jak najbardziej zbliżone do pożądanego.
Dlatego przez długi czas programy miały bardzo proste zachowanie: jeśli w programie wystąpił błąd, program był zamykany. I to było całkiem dobre podejście.
Powiedzmy, że chcesz zapisać dokument na dysku, a podczas procesu zapisywania okazuje się, że na dysku jest za mało miejsca. Które zachowanie programu najbardziej Ci się podoba:
- Program zamknięty
- Program kontynuował pracę, ale nie zapisał pliku.
Początkującemu programiście może się wydawać, że druga opcja jest lepsza, ponieważ program działa. Ale tak naprawdę nie jest.
Wyobraź sobie, że od 3 godzin piszesz dokument w Wordzie, chociaż już w drugiej minucie pracy stało się jasne, że program nie może zapisać dokumentu na dysku. Co jest lepsze - stracić dwie minuty pracy czy trzy godziny?
Jeśli program nie może zrobić tego, co powinien, lepiej go zamknąć, niż dalej udawać, że wszystko jest w porządku. Najlepszą rzeczą, jaką program może zrobić w przypadku awarii, której nie jest w stanie samodzielnie naprawić, jest natychmiastowe powiadomienie użytkownika o problemie.
3. Historia występowania wyjątków
Sytuacje odbiegające od normy zdarzają się nie tylko programom, ale także wewnątrz programu – metodom. Na przykład:
- Metoda chce zapisać plik na dysku, ale nie ma miejsca.
- Metoda chce wywołać funkcję na zmiennej, a zmienna == null.
- W metodzie wystąpiło dzielenie przez 0.
W takim przypadku metoda wywołująca mogłaby ewentualnie poprawić sytuację (wykonać alternatywny scenariusz), gdyby wiedziała, jaki problem wystąpił podczas działania wywoływanej metody.
Jeśli próbujemy zapisać plik na dysku, a plik już istnieje, możemy po prostu poprosić użytkownika o potwierdzenie nadpisania pliku. Jeśli na dysku nie ma miejsca, możesz wyświetlić użytkownikowi powiadomienie i poprosić o wybranie innego dysku. A jeśli programowi zabraknie pamięci, ulegnie awarii.
Dawno, dawno temu programiści zastanawiali się nad tym problemem i wymyślili następujące rozwiązanie: wszystkie metody/funkcje powinny w wyniku swojej pracy zwracać kod błędu. Jeśli funkcja działała idealnie, zwracała 0 , jeśli nie, zwracała kod błędu (nie zero).
Przy takim podejściu do błędów programista po wywołaniu niemal każdej funkcji musiał dodać sprawdzenie, czy funkcja nie zakończyła się błędem. Kod programu znacznie się powiększył i stał się podobny do tego:
| Kod bez obsługi błędów | Kod z obsługą błędów |
|---|---|
|
|
Ponadto bardzo często funkcja, która „zobaczyła”, że wystąpił błąd, nie wiedziała, co z nim zrobić: błąd powinien był zostać zwrócony funkcji wywołującej, a ta zwróciła go wywołującemu i tak dalej.
W dużych programach łańcuch dziesiątek wywołań funkcji jest normą: czasami można nawet znaleźć głębokość wywołań setek funkcji. A teraz musisz przenieść kod błędu z samego dołu na samą górę. A jeśli gdzieś po drodze jakaś funkcja nie przetworzy kodu wyjścia, błąd zostanie utracony.
Kolejną wadą tego podejścia jest to, że jeśli funkcje zwróciły kod błędu, nie mogły już zwrócić wartości swojej pracy. Wynik obliczeń musiałem przekazać przez parametry referencyjne. To sprawiło, że kod był jeszcze bardziej uciążliwy i jeszcze bardziej zwiększył liczbę błędów.