ఈ కథనంలో, మీరు జావా కోసం అత్యంత ప్రజాదరణ పొందిన ఎంటర్ప్రైజ్ ఫ్రేమ్వర్క్లలో ఒకదానితో సుపరిచితులు అవుతారు మరియు మీ మొదటి హైబర్నేట్ అప్లికేషన్ను రూపొందించండి. హైబర్నేట్ గురించి ఎప్పుడూ వినలేదా? లేదా మీరు దాని గురించి విన్నారా, కానీ ఉపయోగించలేదా? లేదా మీరు దానిని ఉపయోగించడానికి ప్రయత్నించారు, కానీ విఫలమయ్యారా? మూడు సందర్భాలలో - కట్ క్రిందకు స్వాగతం :) హలో, అందరికీ! ఈ కథనంలో, నేను హైబర్నేట్ ఫ్రేమ్వర్క్ యొక్క ప్రధాన లక్షణాల గురించి మాట్లాడతాను మరియు మీ మొదటి చిన్న అప్లికేషన్ను వ్రాయడంలో మీకు సహాయం చేస్తాను. దీని కోసం, మాకు అవసరం:
IntelliJ IDEA అల్టిమేట్ ఎడిషన్
దీన్ని అధికారిక వెబ్సైట్ నుండి డౌన్లోడ్ చేసుకోండి మరియు 30-రోజుల ట్రయల్ వెర్షన్ను సక్రియం చేయండి.
PostgreSQL - అత్యంత ప్రజాదరణ పొందిన ఆధునిక డేటాబేస్ నిర్వహణ వ్యవస్థలలో ఒకటి (DBMS)
మావెన్ (ఇప్పటికే IDEA వరకు వైర్ చేయబడింది)
కొంచెం ఓపిక.
ఒకవేళ, నేను అప్లికేషన్ కోడ్ని GitHub (codegym బ్రాంచ్)లో పోస్ట్ చేసాను. కథనం ప్రాథమికంగా మునుపెన్నడూ ఈ సాంకేతికతతో పని చేయని వారి కోసం ఉద్దేశించబడింది, కాబట్టి నేను కోడ్ మొత్తాన్ని తగ్గించాను. ప్రారంభిద్దాం!
హైబర్నేట్ అంటే ఏమిటి?
ఇది అత్యంత ప్రజాదరణ పొందిన ఆబ్జెక్ట్-రిలేషనల్ మ్యాపింగ్ (ORM) అమలులలో ఒకటి. ఆబ్జెక్ట్-రిలేషనల్ మ్యాపింగ్ సాఫ్ట్వేర్ వస్తువులు మరియు డేటాబేస్ రికార్డుల మధ్య సంబంధాన్ని నిర్వచిస్తుంది. వాస్తవానికి, హైబర్నేట్ చాలా విస్తృత కార్యాచరణను కలిగి ఉంది, అయితే మేము సరళమైన ఫంక్షన్లపై దృష్టి పెడతాము. మా లక్ష్యం CRUD (సృష్టించండి, చదవండి, నవీకరించండి, తొలగించండి) అనువర్తనాన్ని సృష్టించడం:
వినియోగదారులను (యూజర్) సృష్టించండి, డేటాబేస్లో ID ద్వారా వారి కోసం శోధించండి, డేటాబేస్లో వారి డేటాను నవీకరించండి మరియు వాటిని డేటాబేస్ నుండి తొలగించండి.
వినియోగదారులకు కారు వస్తువులను (ఆటో) కేటాయించండి. డేటాబేస్ నుండి కార్లను సృష్టించండి, నవీకరించండి, కనుగొనండి మరియు తొలగించండి.
అదనంగా, అప్లికేషన్ స్వయంచాలకంగా డేటాబేస్ నుండి "యజమాని లేని" కార్లను తీసివేయాలి. మరో మాటలో చెప్పాలంటే, వినియోగదారుని తొలగించినప్పుడు, ఆ వినియోగదారుకు చెందిన అన్ని కార్లు కూడా డేటాబేస్ నుండి తొలగించబడాలి.
మా ప్రాజెక్ట్ ఇలా నిర్మించబడుతుంది: మీరు చూడగలిగినట్లుగా, సంక్లిష్టంగా ఏమీ లేదు. 6 తరగతులు + కాన్ఫిగరేషన్లతో 1 ఫైల్. ముందుగా, IntelliJ IDEAలో కొత్త మావెన్ ప్రాజెక్ట్ను సృష్టించండి. ఫైల్ -> కొత్త ప్రాజెక్ట్. ప్రతిపాదిత ప్రాజెక్ట్ రకాల నుండి మావెన్ని ఎంచుకుని, తదుపరి దశకు వెళ్లండి. Apache Maven అనేది POM ఫైల్లలో వాటి నిర్మాణం యొక్క వివరణ ఆధారంగా స్వయంచాలకంగా ప్రాజెక్ట్లను నిర్మించడానికి ఒక ఫ్రేమ్వర్క్. మీ ప్రాజెక్ట్ యొక్క మొత్తం నిర్మాణం pom.xmlలో వివరించబడుతుంది, మీ ప్రాజెక్ట్ యొక్క రూట్లో IDEA స్వయంగా సృష్టించే ఫైల్. ప్రాజెక్ట్ సెట్టింగ్లలో, మీరు కింది మావెన్ సెట్టింగ్లను పేర్కొనాలి: groupId మరియు artifactId. ప్రాజెక్ట్లలో, groupId అనేది సాధారణంగా కంపెనీ లేదా వ్యాపార యూనిట్ యొక్క వివరణ. కంపెనీ లేదా వెబ్సైట్ డొమైన్ పేరు ఇక్కడకు వెళ్లవచ్చు. ప్రతిగా, ఆర్టిఫాక్ట్ ఐడి అనేది ప్రాజెక్ట్ పేరు. groupdId కోసం, మీరు నమోదు చేయవచ్చు com.yourNickname.codegym. ఇది అప్లికేషన్పై ఎలాంటి ప్రభావం చూపదు. ArtifactId కోసం, మీకు నచ్చిన ఏదైనా ప్రాజెక్ట్ పేరుని ఎంచుకోండి. సంస్కరణను మార్చకుండా ఉంచవచ్చు. చివరి స్క్రీన్లో, గతంలో నమోదు చేసిన డేటాను నిర్ధారించండి.కాబట్టి, మేము ప్రాజెక్ట్ను సృష్టించాము. ఇప్పుడు చేయవలసిందల్లా కొంత కోడ్ వ్రాసి దానిని పని చేయడమే :) మొదటి విషయాలు: మేము డేటాబేస్తో పనిచేసే అప్లికేషన్ను సృష్టించాలనుకుంటే, మేము ఖచ్చితంగా డేటాబేస్ లేకుండా చేయలేము! PostgreSQLని ఇక్కడ నుండి డౌన్లోడ్ చేసుకోండి (నేను వెర్షన్ 9ని ఉపయోగిస్తున్నాను). PostgreSQLకి డిఫాల్ట్ యూజర్ 'postgres' ఉంది - మీరు ఇన్స్టాల్ చేసినప్పుడు దాని కోసం పాస్వర్డ్ను ఆలోచించాలి. పాస్వర్డ్ను మర్చిపోవద్దు. మాకు ఇది తర్వాత కావాలి! (సాధారణంగా, అప్లికేషన్లలో డిఫాల్ట్ డేటాబేస్ని ఉపయోగించడం చెడ్డ పద్ధతి, అయితే మీ స్వంత డేటాబేస్ని సృష్టించడం ద్వారా అల్సర్ల సంఖ్యను తగ్గించడానికి మేము దీన్ని చేస్తాము). మీరు కమాండ్ లైన్ మరియు SQL ప్రశ్నలతో స్నేహితులు కాకపోతే, శుభవార్త ఉంది. IntelliJ IDEA డేటాబేస్తో పని చేయడానికి పూర్తిగా అనుకూలమైన వినియోగదారు ఇంటర్ఫేస్ను అందిస్తుంది. (IDEA యొక్క కుడి పేన్, డేటాబేస్ ట్యాబ్లో ఉంది). కనెక్షన్ని సృష్టించడానికి, "+" క్లిక్ చేసి, మా డేటా మూలాన్ని (PostgeSQL) ఎంచుకోండి. వినియోగదారు మరియు డేటాబేస్ (రెండింటికి "postgres") కోసం ఫీల్డ్లను పూరించండి మరియు PostgreSQL యొక్క ఇన్స్టాలేషన్ సమయంలో సెట్ చేయబడిన పాస్వర్డ్ను నమోదు చేయండి. అవసరమైతే, పోస్ట్గ్రెస్ డ్రైవర్ను డౌన్లోడ్ చేయండి. మీరు దీన్ని ఒకే పేజీలో చేయవచ్చు. డేటాబేస్ కనెక్షన్ స్థాపించబడిందని ధృవీకరించడానికి "టెస్ట్ కనెక్షన్" క్లిక్ చేయండి. మీరు "విజయవంతం"ని చూసినట్లయితే, కొనసాగండి. ఇప్పుడు మనం అవసరమైన పట్టికలను సృష్టిస్తాము. మొత్తం ఇద్దరు ఉంటారు: వినియోగదారులు మరియు ఆటోలు. వినియోగదారుల పట్టిక కోసం పారామితులు: id ప్రాథమిక కీ అని గమనించండి. SQLలో ప్రాథమిక కీ ఏమిటో మీకు తెలియకపోతే, దాన్ని Google చేయండి. ఇది ముఖ్యమైనది. ఆటోస్ టేబుల్ కోసం సెట్టింగ్లు: ఆటోస్ టేబుల్ కోసం, మీరు విదేశీ కీని కాన్ఫిగర్ చేయాలి. ఇది మా పట్టికలను లింక్ చేయడానికి ఉపయోగపడుతుంది. మీరు దాని గురించి మరింత చదవాలని నేను సిఫార్సు చేస్తున్నాను. సరళంగా చెప్పాలంటే, ఇది బాహ్య పట్టికను సూచిస్తుంది, మా విషయంలో, వినియోగదారులు. id = 1 ఉన్న వినియోగదారుకు కారు చెందినట్లయితే, ఆటోల యొక్క user_id ఫీల్డ్ 1కి సమానంగా ఉంటుంది. ఈ విధంగా మేము మా అప్లికేషన్లో వినియోగదారులను వారి కార్లతో అనుబంధిస్తాము. మా ఆటోల పట్టికలో, user_id ఫీల్డ్ విదేశీ కీ వలె పని చేస్తుంది. ఇది వినియోగదారుల పట్టిక యొక్క id ఫీల్డ్ను సూచిస్తుంది. కాబట్టి, మేము రెండు పట్టికలతో డేటాబేస్ను సృష్టించాము. జావా కోడ్ నుండి దీన్ని ఎలా నిర్వహించాలో అర్థం చేసుకోవడం మిగిలి ఉంది. మేము pom.xml ఫైల్తో ప్రారంభిస్తాము, దీనిలో మనం అవసరమైన లైబ్రరీలను చేర్చాలి (మావెన్లో వాటిని డిపెండెన్సీలు అంటారు). అన్ని లైబ్రరీలు సెంట్రల్ మావెన్ రిపోజిటరీలో నిల్వ చేయబడతాయి. మీరు ప్రాజెక్ట్లో ఉపయోగించడానికి pom.xmlలో పేర్కొన్న లైబ్రరీలు అందుబాటులో ఉన్నాయి. మీ pom.xml ఇలా ఉండాలి: మీరు చూడగలిగినట్లుగా సంక్లిష్టంగా ఏమీ లేదు. మేము కేవలం 2 డిపెండెన్సీలను మాత్రమే జోడించాము — PostgreSQL మరియు Hibernateని ఉపయోగించడం కోసం. ఇప్పుడు జావా కోడ్కి వెళ్దాం. ప్రాజెక్ట్లో అవసరమైన అన్ని ప్యాకేజీలు మరియు తరగతులను సృష్టించండి. ప్రారంభించడానికి, మాకు డేటా మోడల్ అవసరం: Userమరియు Autoతరగతులు.
package models;
import javax.persistence.*;
import java.util.ArrayList;
import java.util.List;
@Entity
@Table (name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
@Column(name = "name")
private String name;
// You can omit the Column attribute if the name property matches the column name in the table
private int age;
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Auto> autos;
public User() {
}
public User(String name, int age) {
this.name = name;
this.age = age;
autos = new ArrayList<>();
}
public void addAuto(Auto auto) {
auto.setUser(this);
autos.add(auto);
}
public void removeAuto(Auto auto) {
autos.remove(auto);
}
public int getId() {
return id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public List<Auto> getAutos() {
return autos;
}
public void setAutos(List<Auto> autos) {
this.autos = autos;
}
@Override
public String toString() {
return "models.User{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}
package models;
import javax.persistence.*;
@Entity
@Table(name = "autos")
public class Auto {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
@Column (name = "model")
private String model;
// You can omit the Column attribute if the name property matches the column name in the table
private String color;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
public Auto() {
}
public Auto(String model, String color) {
this.model = model;
this.color = color;
}
public int getId() {
return id;
}
public String getModel() {
return model;
}
public void setModel(String model) {
this.model = model;
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
@Override
public String toString() {
return color + " " + model;
}
}
మీరు చూడగలిగినట్లుగా, తరగతులు అస్పష్టమైన ఉల్లేఖనాల సమూహంతో ఉన్నాయి. వాటిని త్రవ్వడం ప్రారంభిద్దాం. మాకు, ప్రధాన ఉల్లేఖన @Entity. దీని గురించి వికీపీడియాలో చదవండి మరియు హృదయపూర్వకంగా తెలుసుకోండి. ఇది పునాది యొక్క పునాది. ఈ ఉల్లేఖనం మీ జావా క్లాస్ యొక్క వస్తువులను డేటాబేస్కు మ్యాప్ చేయడానికి అనుమతిస్తుంది. తరగతి ఎంటిటీగా ఉండాలంటే, అది క్రింది అవసరాలను తీర్చాలి:
ఇది తప్పనిసరిగా ఖాళీ కన్స్ట్రక్టర్ ( publicలేదా protected) ని కలిగి ఉండాలి
ఇది గూడు, ఇంటర్ఫేస్ లేదా ఒకenum
ఇది ఫీల్డ్లు/గుణాలు ఉండకూడదు finalమరియు కలిగి ఉండకూడదుfinal
దీనికి కనీసం ఒక @Id ఫీల్డ్ ఉండాలి.
మీ ఎంటిటీ క్లాస్లను తనిఖీ చేయండి: అవి మిమ్మల్ని మీరు పాదాలకు కాల్చుకోవడానికి బాగా ప్రాచుర్యం పొందిన ప్రదేశాలు. ఏదైనా మర్చిపోవడం చాలా సులభం. అంతేకాకుండా, ఒక ఎంటిటీ కింది వాటిని చేయగలదు:
ఇది ఖాళీ కాని కన్స్ట్రక్టర్లను కలిగి ఉంటుంది
ఇది వారసత్వంగా మరియు వారసత్వంగా పొందవచ్చు
ఇది ఇతర పద్ధతులను కలిగి ఉంటుంది మరియు ఇంటర్ఫేస్లను అమలు చేస్తుంది.
మీరు చూడగలిగినట్లుగా, Userతరగతి వినియోగదారుల పట్టికకు చాలా పోలి ఉంటుంది. ఇది కలిగి ఉంది id, nameమరియుageపొలాలు. వాటి పైన ఉన్న ఉల్లేఖనాలకు ప్రత్యేక వివరణ అవసరం లేదు: ఫీల్డ్ ఈ తరగతికి చెందిన వస్తువుల ఐడెంటిఫైయర్ అని @Id సూచిస్తుంది. తరగతి పైన ఉన్న @టేబుల్ ఉల్లేఖన వస్తువులు వ్రాయబడిన పట్టిక పేరును సూచిస్తుంది. వయస్సు ఫీల్డ్ పైన ఉన్న వ్యాఖ్యను గమనించండి: తరగతిలోని ఫీల్డ్ పేరు మరియు టేబుల్ పేరు ఒకేలా ఉంటే, మీరు @కాలమ్ ఉల్లేఖనాన్ని వదిలివేయవచ్చు మరియు అది పని చేస్తుంది. జంట కలుపులలో సూచించబడిన భాగం కొరకు ("వ్యూహం = GenerationType.IDENTITY"): IDలను రూపొందించడానికి అనేక వ్యూహాలు ఉన్నాయి. మీరు వాటిని Google చేయవచ్చు, కానీ మా అప్లికేషన్ కోసం, ఇబ్బంది పడవలసిన అవసరం లేదు. ప్రధాన విషయం ఏమిటంటే, మన వస్తువులకు ఐడి విలువ స్వయంచాలకంగా ఉత్పత్తి అవుతుంది. దీని ప్రకారం, id కోసం సెట్టర్ లేదు మరియు మేము దానిని కన్స్ట్రక్టర్లో కూడా సెట్ చేయము. అయితే,Userతరగతి ప్రత్యేకంగా నిలుస్తుంది. ఇందులో కార్ల జాబితా ఉంది! @OneToMany ఉల్లేఖన జాబితా పైన వేలాడుతోంది. దీని అర్థం అనేక కార్లు వినియోగదారు తరగతి యొక్క ఒకే వస్తువుకు అనుగుణంగా ఉంటాయి. "mappedBy" మూలకం తరగతి యొక్క వినియోగదారు ఫీల్డ్ను సూచిస్తుంది Auto. అందువలన, కార్లు మరియు వినియోగదారులు సంబంధించినవి. ఆర్ఫన్ రిమూవల్ ఎలిమెంట్ అనేది ఇకపై సంబంధం లేని ఎంటిటీలకు రిమూవ్ ఆపరేషన్ని వర్తింపజేయాలా వద్దా అని సూచిస్తుంది. మేము డేటాబేస్ నుండి వినియోగదారుని తొలగిస్తే, దానితో అనుబంధించబడిన అన్ని కార్లు కూడా తొలగించబడతాయి. క్రమంగా, లోAutoతరగతి, మీరు @ManyToOne ఉల్లేఖన (ఒక వినియోగదారు అనేక ఆటోలకు అనుగుణంగా ఉండవచ్చు) మరియు @JoinColumn ఉల్లేఖనతో వినియోగదారు ఫీల్డ్ను చూస్తారు. ఇది ఆటోస్ టేబుల్లోని ఏ కాలమ్ వినియోగదారుల పట్టికను సూచించడానికి ఉపయోగించబడుతుందో సూచిస్తుంది (అంటే మనం ఇంతకు ముందు మాట్లాడిన విదేశీ కీ). డేటా మోడల్ని సృష్టించిన తర్వాత, డేటాబేస్లోని డేటాతో ఆపరేషన్లను నిర్వహించడానికి మా ప్రోగ్రామ్కు నేర్పించే సమయం ఇది. HibernateSessionFactoryUtil యుటిలిటీ క్లాస్తో ప్రారంభిద్దాం. దీనికి ఒకే ఒక పని ఉంది — డేటాబేస్తో పని చేయడానికి మా అప్లికేషన్ కోసం సెషన్ ఫ్యాక్టరీని సృష్టించడం (ఫ్యాక్టరీ డిజైన్ నమూనాకు హలో చెప్పండి!). ఇంకేమి చేయాలో దానికి తెలియదు.
ఈ క్లాస్లో, మేము కొత్త కాన్ఫిగరేషన్ ఆబ్జెక్ట్ని సృష్టిస్తాము మరియు దానిని ఎంటిటీలుగా పరిగణించాల్సిన తరగతులను పాస్ చేస్తాము: Userమరియు Auto. పద్ధతికి శ్రద్ధ వహించండి configuration.getProperties(). ఏ ఇతర ఆస్తులు ఉన్నాయి? ఎక్కడ నుండి వారు వచ్చారు? గుణాలు అనేవి ప్రత్యేక hibernate.cfg.xml ఫైల్లో సూచించబడిన హైబర్నేట్ సెట్టింగ్లు. Hibernate.cfg.xml ఇక్కడ చదవబడింది: new Configuration().configure(); మీరు చూస్తున్నట్లుగా, దాని గురించి ప్రత్యేకంగా ఏమీ లేదు: ఇది డేటాబేస్కు కనెక్ట్ చేయడానికి పారామితులను అలాగే show_sql పరామితిని కలిగి ఉంటుంది. హైబర్నేట్ ద్వారా అమలు చేయబడిన అన్ని sql ప్రశ్నలు కన్సోల్లో ప్రదర్శించబడేలా ఇది అవసరం. ఈ విధంగా మీరు హైబర్నేట్ ఏ క్షణంలో ఏమి చేస్తుందో ఖచ్చితంగా చూస్తారు, ఏదైనా "మేజిక్" భావాన్ని తొలగిస్తుంది. తదుపరి మనకు అవసరంUserDAOతరగతి. ఇంటర్ఫేస్ల ద్వారా ప్రోగ్రామ్ చేయడం ఉత్తమ అభ్యాసం — ప్రత్యేక UserDAOఇంటర్ఫేస్ మరియు UserDAOImplఅమలును సృష్టించడం, కానీ కోడ్ మొత్తాన్ని తగ్గించడానికి నేను దీన్ని దాటవేస్తాను. నిజమైన ప్రాజెక్ట్లలో ఇలా చేయవద్దు! DAO (డేటా యాక్సెస్ ఆబ్జెక్ట్) డిజైన్ నమూనా అత్యంత సాధారణమైనది. ఆలోచన చాలా సులభం - డేటాను యాక్సెస్ చేయడానికి మాత్రమే బాధ్యత వహించే అప్లికేషన్ లేయర్ను సృష్టించండి, మరేమీ లేదు. డేటాబేస్ నుండి డేటాను పొందండి, డేటాను నవీకరించండి, డేటాను తొలగించండి - అంతే. DAO గురించి మరింత అధ్యయనం చేయండి. మీరు మీ పనిలో నిరంతరం డేటా యాక్సెస్ ఆబ్జెక్ట్లను ఉపయోగిస్తారు. మా UserDaoతరగతి ఏమి చేయగలదు? సరే, అన్ని DAOల వలె, ఇది డేటాతో మాత్రమే పని చేయగలదు. id ద్వారా వినియోగదారుని కనుగొనండి, దాని డేటాను అప్డేట్ చేయండి, దాన్ని తొలగించండి, డేటాబేస్ నుండి వినియోగదారులందరి జాబితాను పొందండి లేదా డేటాబేస్లో కొత్త వినియోగదారుని సేవ్ చేయండి — ఇది దాని పూర్తి కార్యాచరణ.
UserDaoయొక్క పద్ధతులు ఒకదానికొకటి సమానంగా ఉంటాయి. వాటిలో చాలా వరకు, మేము మా సెషన్ ఫ్యాక్టరీని ఉపయోగించి సెషన్ ఆబ్జెక్ట్ (డేటాబేస్ కనెక్షన్ సెషన్)ని పొందుతాము, ఈ సెషన్లో ఒకే లావాదేవీని సృష్టించండి, అవసరమైన డేటా మానిప్యులేషన్లను చేస్తాము, లావాదేవీ ఫలితాన్ని డేటాబేస్లో సేవ్ చేస్తాము, ఆపై సెషన్ను మూసివేస్తాము . పద్ధతులు, మీరు చూడగలిగినట్లుగా, చాలా సులభం. DAO అనేది మా అప్లికేషన్ యొక్క "హృదయం". అయినప్పటికీ, మేము నేరుగా DAOని సృష్టించము మరియు దాని పద్ధతులను మా main()పద్ధతిలో పిలుస్తాము. అన్ని లాజిక్లు తరగతికి తరలించబడతాయి UserService.
package services;
import dao.UserDao;
import models.Auto;
import models.User;
import java.util.List;
public class UserService {
private UserDao usersDao = new UserDao();
public UserService() {
}
public User findUser(int id) {
return usersDao.findById(id);
}
public void saveUser(User user) {
usersDao.save(user);
}
public void deleteUser(User user) {
usersDao.delete(user);
}
public void updateUser(User user) {
usersDao.update(user);
}
public List<User> findAllUsers() {
return usersDao.findAll();
}
public Auto findAutoById(int id) {
return usersDao.findAutoById(id);
}
}
సేవ అనేది వ్యాపార లాజిక్ని అమలు చేయడానికి బాధ్యత వహించే అప్లికేషన్ డేటా లేయర్. మీ ప్రోగ్రామ్ ఒక విధమైన వ్యాపార తర్కాన్ని అమలు చేయవలసి వస్తే, అది సేవల ద్వారా చేస్తుంది. ఒక సేవ UserDaoదాని పద్ధతులలో DAO పద్ధతులను కలిగి ఉంటుంది మరియు కాల్ చేస్తుంది. మేము ఇక్కడ ఫంక్షన్లను నకిలీ చేస్తున్నట్లు అనిపించవచ్చు (ఎందుకు కేవలం DAO ఆబ్జెక్ట్ నుండి పద్ధతులను కాల్ చేయకూడదు?), కానీ చాలా వస్తువులు మరియు సంక్లిష్ట తర్కంతో, అప్లికేషన్ను పొరలుగా వేయడం వలన భారీ ప్రయోజనాలు లభిస్తాయి (అలా చేయడం మంచి అభ్యాసం - భవిష్యత్తులో దీన్ని గుర్తుంచుకోండి మరియు "అప్లికేషన్ లేయర్లు" గురించి చదవండి). మా సేవలో సాధారణ తర్కం ఉంది, కానీ వాస్తవ-ప్రపంచ ప్రాజెక్ట్లలో సేవా పద్ధతులు ఒకటి కంటే ఎక్కువ లైన్ కోడ్లను కలిగి ఉంటాయి :) ఇప్పుడు మీరు అప్లికేషన్ను అమలు చేయడానికి కావలసినవన్నీ మా వద్ద ఉన్నాయి! పద్ధతిలో main(), వినియోగదారుని మరియు దాని కారుని సృష్టించి, ఒకదానితో ఒకటి అనుబంధించండి మరియు వాటిని డేటాబేస్లో సేవ్ చేద్దాం.
import models.Auto;
import models.User;
import services.UserService;
import java.sql.SQLException;
public class Main {
public static void main(String[] args) throws SQLException {
UserService userService = new UserService();
User user = new User ("Jenny", 26);
userService.saveUser(user);
Auto ferrari = new Auto("Ferrari", "red");
ferrari.setUser(user);
user.addAuto(ferrari);
Auto ford = new Auto("Ford", "black");
ford.setUser(user);
user.addAuto(ford);
userService.updateUser(user);
}
}
మీరు చూడగలిగినట్లుగా, వినియోగదారుల పట్టిక దాని స్వంత రికార్డును కలిగి ఉంది మరియు ఆటోల పట్టిక దాని స్వంత రికార్డును కలిగి ఉంది. మన వినియోగదారు పేరు మార్చడానికి ప్రయత్నిద్దాం. వినియోగదారుల పట్టికను క్లియర్ చేసి, కోడ్ని అమలు చేయండి
import models.Auto;
import models.User;
import services.UserService;
import java.sql.SQLException;
public class Main {
public static void main(String[] args) throws SQLException {
UserService userService = new UserService();
User user = new User ("Jenny", 26);
userService.saveUser(user);
Auto ferrari = new Auto("Ferrari", "red");
user.addAuto(ferrari);
Auto ford = new Auto("Ford", "black");
ford.setUser(user);
user.addAuto(ford);
userService.updateUser(user);
user.setName ("Benny");
userService.updateUser(user);
}
}
ఇది పనిచేస్తుంది! మీరు వినియోగదారుని తొలగిస్తే ఏమి చేయాలి? వినియోగదారుల పట్టికను క్లియర్ చేయండి (ఆటోలు స్వయంగా క్లియర్ చేస్తాయి) మరియు కోడ్ను అమలు చేయండి
import models.Auto;
import models.User;
import services.UserService;
import java.sql.SQLException;
public class Main {
public static void main(String[] args) throws SQLException {
UserService userService = new UserService();
User user = new User ("Jenny", 26);
userService.saveUser(user);
Auto ferrari = new Auto("Ferrari", "red");
user.addAuto(ferrari);
Auto ford = new Auto("Ford", "black");
ford.setUser(user);
user.addAuto(ford);
userService.updateUser(user);
user.setName ("Benny");
userService.updateUser(user);
userService.deleteUser(user);
}
}
మరియు మా పట్టికలు పూర్తిగా ఖాళీగా ఉన్నాయి (కన్సోల్పై శ్రద్ధ వహించండి - హైబర్నేట్ చేసిన అన్ని అభ్యర్థనలు అక్కడ ప్రదర్శించబడతాయి). మీరు అప్లికేషన్తో ఆడుకోవచ్చు మరియు దాని అన్ని ఫంక్షన్లను ప్రయత్నించవచ్చు. ఉదాహరణకు, కార్లతో వినియోగదారుని సృష్టించండి, దానిని డేటాబేస్లో సేవ్ చేయండి, వినియోగదారుకు కేటాయించిన ఐడిని చూడండి మరియు ఈ ఐడిని దీనిలో ఉపయోగించడానికి ప్రయత్నించండిmain()డేటాబేస్ నుండి వినియోగదారుని పొందడం మరియు కన్సోల్లో దాని కార్ల జాబితాను ప్రదర్శించడం. వాస్తవానికి, మేము హైబర్నేట్ యొక్క కార్యాచరణలో కొంత భాగాన్ని మాత్రమే చూశాము. దీని సామర్థ్యాలు చాలా విస్తృతమైనవి మరియు ఇది జావా అభివృద్ధికి చాలా కాలంగా ప్రామాణిక పరిశ్రమ సాధనంగా ఉంది. మీరు దానిని వివరంగా అధ్యయనం చేయాలనుకుంటే, నేను "జావా పెర్సిస్టెన్స్ API మరియు హైబర్నేట్" పుస్తకాన్ని సిఫార్సు చేయగలను. నేను మునుపటి వ్యాసంలో సమీక్షించాను. ఈ వ్యాసం పాఠకులకు ఉపయోగకరంగా ఉందని నేను ఆశిస్తున్నాను. మీకు ఏవైనా ప్రశ్నలు ఉంటే, వాటిని వ్యాఖ్యలలో అడగండి. నేను సమాధానం చెప్పడానికి సంతోషిస్తాను :) అలాగే, "ఇష్టం" పోస్ట్ చేయడం ద్వారా పోటీలో రచయితకు మద్దతు ఇవ్వడం మర్చిపోవద్దు. లేదా ఇంకా మంచిది — "లవ్ ఇట్" :) మీ చదువులో అదృష్టం!
 హలో, అందరికీ! ఈ కథనంలో, నేను హైబర్నేట్ ఫ్రేమ్వర్క్ యొక్క ప్రధాన లక్షణాల గురించి మాట్లాడతాను మరియు మీ మొదటి చిన్న అప్లికేషన్ను వ్రాయడంలో మీకు సహాయం చేస్తాను. దీని కోసం, మాకు అవసరం:
హలో, అందరికీ! ఈ కథనంలో, నేను హైబర్నేట్ ఫ్రేమ్వర్క్ యొక్క ప్రధాన లక్షణాల గురించి మాట్లాడతాను మరియు మీ మొదటి చిన్న అప్లికేషన్ను వ్రాయడంలో మీకు సహాయం చేస్తాను. దీని కోసం, మాకు అవసరం:
 మీరు చూడగలిగినట్లుగా, సంక్లిష్టంగా ఏమీ లేదు. 6 తరగతులు + కాన్ఫిగరేషన్లతో 1 ఫైల్. ముందుగా, IntelliJ IDEAలో కొత్త మావెన్ ప్రాజెక్ట్ను సృష్టించండి. ఫైల్ -> కొత్త ప్రాజెక్ట్. ప్రతిపాదిత ప్రాజెక్ట్ రకాల నుండి మావెన్ని ఎంచుకుని, తదుపరి దశకు వెళ్లండి.
మీరు చూడగలిగినట్లుగా, సంక్లిష్టంగా ఏమీ లేదు. 6 తరగతులు + కాన్ఫిగరేషన్లతో 1 ఫైల్. ముందుగా, IntelliJ IDEAలో కొత్త మావెన్ ప్రాజెక్ట్ను సృష్టించండి. ఫైల్ -> కొత్త ప్రాజెక్ట్. ప్రతిపాదిత ప్రాజెక్ట్ రకాల నుండి మావెన్ని ఎంచుకుని, తదుపరి దశకు వెళ్లండి.  Apache Maven అనేది POM ఫైల్లలో వాటి నిర్మాణం యొక్క వివరణ ఆధారంగా స్వయంచాలకంగా ప్రాజెక్ట్లను నిర్మించడానికి ఒక ఫ్రేమ్వర్క్. మీ ప్రాజెక్ట్ యొక్క మొత్తం నిర్మాణం pom.xmlలో వివరించబడుతుంది, మీ ప్రాజెక్ట్ యొక్క రూట్లో IDEA స్వయంగా సృష్టించే ఫైల్. ప్రాజెక్ట్ సెట్టింగ్లలో, మీరు కింది మావెన్ సెట్టింగ్లను పేర్కొనాలి: groupId మరియు artifactId. ప్రాజెక్ట్లలో, groupId అనేది సాధారణంగా కంపెనీ లేదా వ్యాపార యూనిట్ యొక్క వివరణ. కంపెనీ లేదా వెబ్సైట్ డొమైన్ పేరు ఇక్కడకు వెళ్లవచ్చు. ప్రతిగా, ఆర్టిఫాక్ట్ ఐడి అనేది ప్రాజెక్ట్ పేరు. groupdId కోసం, మీరు నమోదు చేయవచ్చు
Apache Maven అనేది POM ఫైల్లలో వాటి నిర్మాణం యొక్క వివరణ ఆధారంగా స్వయంచాలకంగా ప్రాజెక్ట్లను నిర్మించడానికి ఒక ఫ్రేమ్వర్క్. మీ ప్రాజెక్ట్ యొక్క మొత్తం నిర్మాణం pom.xmlలో వివరించబడుతుంది, మీ ప్రాజెక్ట్ యొక్క రూట్లో IDEA స్వయంగా సృష్టించే ఫైల్. ప్రాజెక్ట్ సెట్టింగ్లలో, మీరు కింది మావెన్ సెట్టింగ్లను పేర్కొనాలి: groupId మరియు artifactId. ప్రాజెక్ట్లలో, groupId అనేది సాధారణంగా కంపెనీ లేదా వ్యాపార యూనిట్ యొక్క వివరణ. కంపెనీ లేదా వెబ్సైట్ డొమైన్ పేరు ఇక్కడకు వెళ్లవచ్చు. ప్రతిగా, ఆర్టిఫాక్ట్ ఐడి అనేది ప్రాజెక్ట్ పేరు. groupdId కోసం, మీరు నమోదు చేయవచ్చు 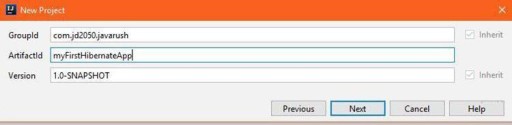 చివరి స్క్రీన్లో, గతంలో నమోదు చేసిన డేటాను నిర్ధారించండి.
చివరి స్క్రీన్లో, గతంలో నమోదు చేసిన డేటాను నిర్ధారించండి. కాబట్టి, మేము ప్రాజెక్ట్ను సృష్టించాము. ఇప్పుడు చేయవలసిందల్లా కొంత కోడ్ వ్రాసి దానిని పని చేయడమే :) మొదటి విషయాలు: మేము డేటాబేస్తో పనిచేసే అప్లికేషన్ను సృష్టించాలనుకుంటే, మేము ఖచ్చితంగా డేటాబేస్ లేకుండా చేయలేము! PostgreSQLని ఇక్కడ నుండి డౌన్లోడ్ చేసుకోండి (నేను వెర్షన్ 9ని ఉపయోగిస్తున్నాను). PostgreSQLకి డిఫాల్ట్ యూజర్ 'postgres' ఉంది - మీరు ఇన్స్టాల్ చేసినప్పుడు దాని కోసం పాస్వర్డ్ను ఆలోచించాలి. పాస్వర్డ్ను మర్చిపోవద్దు. మాకు ఇది తర్వాత కావాలి! (సాధారణంగా, అప్లికేషన్లలో డిఫాల్ట్ డేటాబేస్ని ఉపయోగించడం చెడ్డ పద్ధతి, అయితే మీ స్వంత డేటాబేస్ని సృష్టించడం ద్వారా అల్సర్ల సంఖ్యను తగ్గించడానికి మేము దీన్ని చేస్తాము). మీరు కమాండ్ లైన్ మరియు SQL ప్రశ్నలతో స్నేహితులు కాకపోతే, శుభవార్త ఉంది. IntelliJ IDEA డేటాబేస్తో పని చేయడానికి పూర్తిగా అనుకూలమైన వినియోగదారు ఇంటర్ఫేస్ను అందిస్తుంది.
కాబట్టి, మేము ప్రాజెక్ట్ను సృష్టించాము. ఇప్పుడు చేయవలసిందల్లా కొంత కోడ్ వ్రాసి దానిని పని చేయడమే :) మొదటి విషయాలు: మేము డేటాబేస్తో పనిచేసే అప్లికేషన్ను సృష్టించాలనుకుంటే, మేము ఖచ్చితంగా డేటాబేస్ లేకుండా చేయలేము! PostgreSQLని ఇక్కడ నుండి డౌన్లోడ్ చేసుకోండి (నేను వెర్షన్ 9ని ఉపయోగిస్తున్నాను). PostgreSQLకి డిఫాల్ట్ యూజర్ 'postgres' ఉంది - మీరు ఇన్స్టాల్ చేసినప్పుడు దాని కోసం పాస్వర్డ్ను ఆలోచించాలి. పాస్వర్డ్ను మర్చిపోవద్దు. మాకు ఇది తర్వాత కావాలి! (సాధారణంగా, అప్లికేషన్లలో డిఫాల్ట్ డేటాబేస్ని ఉపయోగించడం చెడ్డ పద్ధతి, అయితే మీ స్వంత డేటాబేస్ని సృష్టించడం ద్వారా అల్సర్ల సంఖ్యను తగ్గించడానికి మేము దీన్ని చేస్తాము). మీరు కమాండ్ లైన్ మరియు SQL ప్రశ్నలతో స్నేహితులు కాకపోతే, శుభవార్త ఉంది. IntelliJ IDEA డేటాబేస్తో పని చేయడానికి పూర్తిగా అనుకూలమైన వినియోగదారు ఇంటర్ఫేస్ను అందిస్తుంది.  (IDEA యొక్క కుడి పేన్, డేటాబేస్ ట్యాబ్లో ఉంది). కనెక్షన్ని సృష్టించడానికి, "+" క్లిక్ చేసి, మా డేటా మూలాన్ని (PostgeSQL) ఎంచుకోండి. వినియోగదారు మరియు డేటాబేస్ (రెండింటికి "postgres") కోసం ఫీల్డ్లను పూరించండి మరియు PostgreSQL యొక్క ఇన్స్టాలేషన్ సమయంలో సెట్ చేయబడిన పాస్వర్డ్ను నమోదు చేయండి. అవసరమైతే, పోస్ట్గ్రెస్ డ్రైవర్ను డౌన్లోడ్ చేయండి. మీరు దీన్ని ఒకే పేజీలో చేయవచ్చు. డేటాబేస్ కనెక్షన్ స్థాపించబడిందని ధృవీకరించడానికి "టెస్ట్ కనెక్షన్" క్లిక్ చేయండి. మీరు "విజయవంతం"ని చూసినట్లయితే, కొనసాగండి. ఇప్పుడు మనం అవసరమైన పట్టికలను సృష్టిస్తాము. మొత్తం ఇద్దరు ఉంటారు: వినియోగదారులు మరియు ఆటోలు. వినియోగదారుల పట్టిక కోసం పారామితులు:
(IDEA యొక్క కుడి పేన్, డేటాబేస్ ట్యాబ్లో ఉంది). కనెక్షన్ని సృష్టించడానికి, "+" క్లిక్ చేసి, మా డేటా మూలాన్ని (PostgeSQL) ఎంచుకోండి. వినియోగదారు మరియు డేటాబేస్ (రెండింటికి "postgres") కోసం ఫీల్డ్లను పూరించండి మరియు PostgreSQL యొక్క ఇన్స్టాలేషన్ సమయంలో సెట్ చేయబడిన పాస్వర్డ్ను నమోదు చేయండి. అవసరమైతే, పోస్ట్గ్రెస్ డ్రైవర్ను డౌన్లోడ్ చేయండి. మీరు దీన్ని ఒకే పేజీలో చేయవచ్చు. డేటాబేస్ కనెక్షన్ స్థాపించబడిందని ధృవీకరించడానికి "టెస్ట్ కనెక్షన్" క్లిక్ చేయండి. మీరు "విజయవంతం"ని చూసినట్లయితే, కొనసాగండి. ఇప్పుడు మనం అవసరమైన పట్టికలను సృష్టిస్తాము. మొత్తం ఇద్దరు ఉంటారు: వినియోగదారులు మరియు ఆటోలు. వినియోగదారుల పట్టిక కోసం పారామితులు:  id ప్రాథమిక కీ అని గమనించండి. SQLలో ప్రాథమిక కీ ఏమిటో మీకు తెలియకపోతే, దాన్ని Google చేయండి. ఇది ముఖ్యమైనది. ఆటోస్ టేబుల్ కోసం సెట్టింగ్లు:
id ప్రాథమిక కీ అని గమనించండి. SQLలో ప్రాథమిక కీ ఏమిటో మీకు తెలియకపోతే, దాన్ని Google చేయండి. ఇది ముఖ్యమైనది. ఆటోస్ టేబుల్ కోసం సెట్టింగ్లు:  ఆటోస్ టేబుల్ కోసం, మీరు విదేశీ కీని కాన్ఫిగర్ చేయాలి. ఇది మా పట్టికలను లింక్ చేయడానికి ఉపయోగపడుతుంది. మీరు దాని గురించి మరింత చదవాలని నేను సిఫార్సు చేస్తున్నాను. సరళంగా చెప్పాలంటే, ఇది బాహ్య పట్టికను సూచిస్తుంది, మా విషయంలో, వినియోగదారులు. id = 1 ఉన్న వినియోగదారుకు కారు చెందినట్లయితే, ఆటోల యొక్క user_id ఫీల్డ్ 1కి సమానంగా ఉంటుంది. ఈ విధంగా మేము మా అప్లికేషన్లో వినియోగదారులను వారి కార్లతో అనుబంధిస్తాము. మా ఆటోల పట్టికలో, user_id ఫీల్డ్ విదేశీ కీ వలె పని చేస్తుంది. ఇది వినియోగదారుల పట్టిక యొక్క id ఫీల్డ్ను సూచిస్తుంది.
ఆటోస్ టేబుల్ కోసం, మీరు విదేశీ కీని కాన్ఫిగర్ చేయాలి. ఇది మా పట్టికలను లింక్ చేయడానికి ఉపయోగపడుతుంది. మీరు దాని గురించి మరింత చదవాలని నేను సిఫార్సు చేస్తున్నాను. సరళంగా చెప్పాలంటే, ఇది బాహ్య పట్టికను సూచిస్తుంది, మా విషయంలో, వినియోగదారులు. id = 1 ఉన్న వినియోగదారుకు కారు చెందినట్లయితే, ఆటోల యొక్క user_id ఫీల్డ్ 1కి సమానంగా ఉంటుంది. ఈ విధంగా మేము మా అప్లికేషన్లో వినియోగదారులను వారి కార్లతో అనుబంధిస్తాము. మా ఆటోల పట్టికలో, user_id ఫీల్డ్ విదేశీ కీ వలె పని చేస్తుంది. ఇది వినియోగదారుల పట్టిక యొక్క id ఫీల్డ్ను సూచిస్తుంది.  కాబట్టి, మేము రెండు పట్టికలతో డేటాబేస్ను సృష్టించాము. జావా కోడ్ నుండి దీన్ని ఎలా నిర్వహించాలో అర్థం చేసుకోవడం మిగిలి ఉంది. మేము pom.xml ఫైల్తో ప్రారంభిస్తాము, దీనిలో మనం అవసరమైన లైబ్రరీలను చేర్చాలి (మావెన్లో వాటిని డిపెండెన్సీలు అంటారు). అన్ని లైబ్రరీలు సెంట్రల్ మావెన్ రిపోజిటరీలో నిల్వ చేయబడతాయి. మీరు ప్రాజెక్ట్లో ఉపయోగించడానికి pom.xmlలో పేర్కొన్న లైబ్రరీలు అందుబాటులో ఉన్నాయి. మీ pom.xml ఇలా ఉండాలి:
కాబట్టి, మేము రెండు పట్టికలతో డేటాబేస్ను సృష్టించాము. జావా కోడ్ నుండి దీన్ని ఎలా నిర్వహించాలో అర్థం చేసుకోవడం మిగిలి ఉంది. మేము pom.xml ఫైల్తో ప్రారంభిస్తాము, దీనిలో మనం అవసరమైన లైబ్రరీలను చేర్చాలి (మావెన్లో వాటిని డిపెండెన్సీలు అంటారు). అన్ని లైబ్రరీలు సెంట్రల్ మావెన్ రిపోజిటరీలో నిల్వ చేయబడతాయి. మీరు ప్రాజెక్ట్లో ఉపయోగించడానికి pom.xmlలో పేర్కొన్న లైబ్రరీలు అందుబాటులో ఉన్నాయి. మీ pom.xml ఇలా ఉండాలి:  మీరు చూడగలిగినట్లుగా సంక్లిష్టంగా ఏమీ లేదు. మేము కేవలం 2 డిపెండెన్సీలను మాత్రమే జోడించాము — PostgreSQL మరియు Hibernateని ఉపయోగించడం కోసం. ఇప్పుడు జావా కోడ్కి వెళ్దాం. ప్రాజెక్ట్లో అవసరమైన అన్ని ప్యాకేజీలు మరియు తరగతులను సృష్టించండి. ప్రారంభించడానికి, మాకు డేటా మోడల్ అవసరం:
మీరు చూడగలిగినట్లుగా సంక్లిష్టంగా ఏమీ లేదు. మేము కేవలం 2 డిపెండెన్సీలను మాత్రమే జోడించాము — PostgreSQL మరియు Hibernateని ఉపయోగించడం కోసం. ఇప్పుడు జావా కోడ్కి వెళ్దాం. ప్రాజెక్ట్లో అవసరమైన అన్ని ప్యాకేజీలు మరియు తరగతులను సృష్టించండి. ప్రారంభించడానికి, మాకు డేటా మోడల్ అవసరం: 
 @OneToMany ఉల్లేఖన జాబితా పైన వేలాడుతోంది. దీని అర్థం అనేక కార్లు వినియోగదారు తరగతి యొక్క ఒకే వస్తువుకు అనుగుణంగా ఉంటాయి. "mappedBy" మూలకం తరగతి యొక్క వినియోగదారు ఫీల్డ్ను సూచిస్తుంది
@OneToMany ఉల్లేఖన జాబితా పైన వేలాడుతోంది. దీని అర్థం అనేక కార్లు వినియోగదారు తరగతి యొక్క ఒకే వస్తువుకు అనుగుణంగా ఉంటాయి. "mappedBy" మూలకం తరగతి యొక్క వినియోగదారు ఫీల్డ్ను సూచిస్తుంది  Hibernate.cfg.xml ఇక్కడ చదవబడింది:
Hibernate.cfg.xml ఇక్కడ చదవబడింది: 

 మన వినియోగదారు పేరు మార్చడానికి ప్రయత్నిద్దాం. వినియోగదారుల పట్టికను క్లియర్ చేసి, కోడ్ని అమలు చేయండి
మన వినియోగదారు పేరు మార్చడానికి ప్రయత్నిద్దాం. వినియోగదారుల పట్టికను క్లియర్ చేసి, కోడ్ని అమలు చేయండి
 మీరు వినియోగదారుని తొలగిస్తే ఏమి చేయాలి? వినియోగదారుల పట్టికను క్లియర్ చేయండి (ఆటోలు స్వయంగా క్లియర్ చేస్తాయి) మరియు కోడ్ను అమలు చేయండి
మీరు వినియోగదారుని తొలగిస్తే ఏమి చేయాలి? వినియోగదారుల పట్టికను క్లియర్ చేయండి (ఆటోలు స్వయంగా క్లియర్ చేస్తాయి) మరియు కోడ్ను అమలు చేయండి
GO TO FULL VERSION