1.1 ¿Qué es fragmentación?
Si busca persistentemente en Google, resulta que hay un borde bastante borroso entre la llamada partición y la llamada fragmentación. Cada cual llama como quiere, como quiere. Algunas personas distinguen entre partición horizontal y fragmentación. Otros dicen que la fragmentación es un cierto tipo de partición horizontal.
No encontré un solo estándar terminológico que fuera aprobado por los padres fundadores y certificado por ISO. La convicción interior personal es algo así: dividir en promedio es "cortar la base en pedazos" de una manera arbitraria.
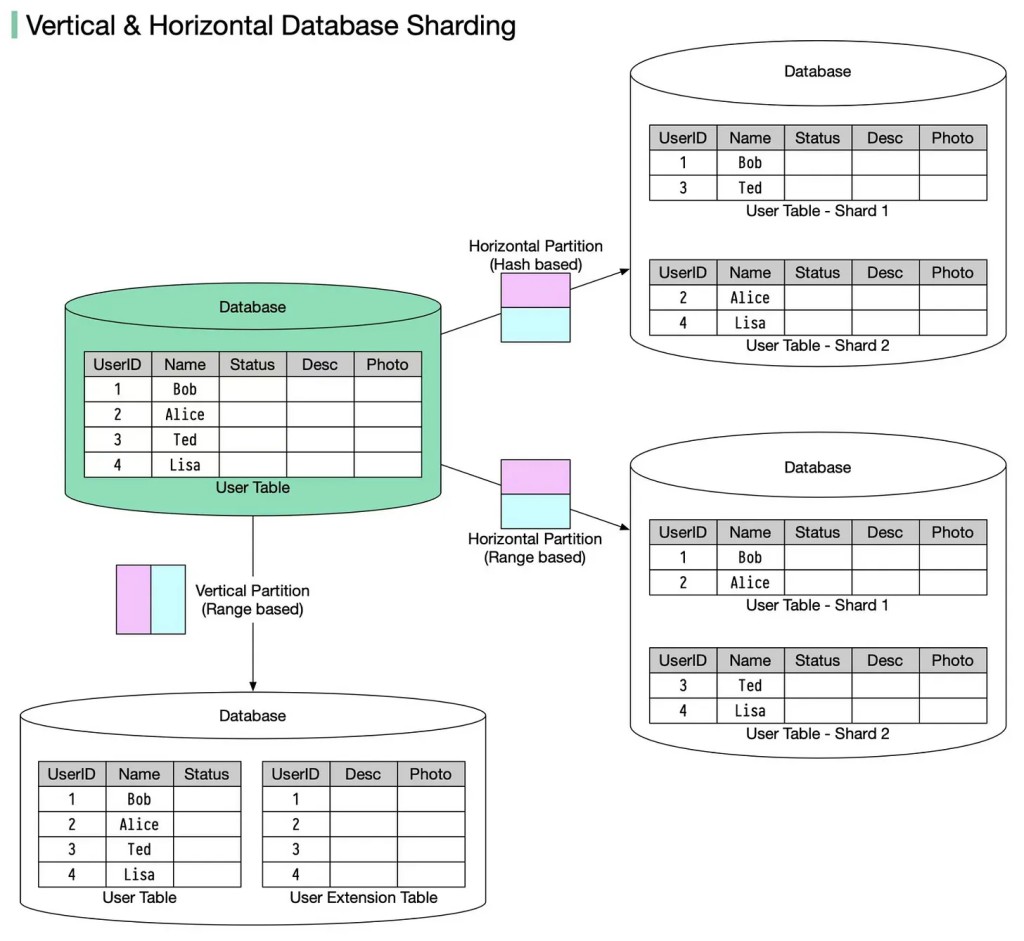
- Partición vertical - por columna. Por ejemplo, hay una tabla gigante con un par de miles de millones de registros en 60 columnas. En lugar de mantener una tabla gigante de este tipo, mantenemos al menos 60 tablas gigantes de 2 mil millones de registros cada una, y esto no es una base de columna, sino una partición vertical (como ejemplo de terminología).
- Particionamiento horizontal : cortamos línea por línea, tal vez dentro del servidor.
El momento incómodo aquí es la sutil diferencia entre la partición horizontal y la fragmentación. Puedo ser cortado en pedazos, pero no puedo decirte con certeza qué es. Existe la sensación de que la fragmentación y la partición horizontal son casi lo mismo.
La fragmentación es, en general, cuando una tabla grande en términos de bases de datos o una pro-colección de documentos, objetos, si no tiene una base de datos, pero un almacén de documentos, se corta exactamente por objetos. Es decir, de 2 mil millones de objetos, se seleccionan piezas sin importar el tamaño. Los objetos dentro de cada objeto no se cortan en pedazos, no los colocamos en columnas separadas, es decir, los colocamos en lotes en diferentes lugares.
Existen sutiles diferencias terminológicas. Por ejemplo, en términos relativos, los desarrolladores de Postgres pueden decir que la partición horizontal es cuando todas las tablas en las que se divide la tabla principal se encuentran en el mismo esquema, y cuando están en diferentes máquinas, esto ya es fragmentación.
En un sentido general, sin estar atado a la terminología de una base de datos específica y un sistema de administración de datos específico, existe la sensación de que fragmentar es solo dividir línea por línea, documento por documento, etc., eso es todo.

Subrayo típico. En el sentido de que estamos haciendo todo esto no solo para cortar 2 mil millones de documentos en 20 tablas, cada una de las cuales sería más manejable, sino para distribuirlo entre muchos núcleos, muchos discos o muchos servidores físicos o virtuales diferentes.
1.2 Divide lo indivisible
Se entiende que hacemos esto para que cada fragmento, cada dato, se replique muchas veces. Pero realmente, no.
INSERT INTO docs00
SELECT * FROM documents WHERE (id%16)=0
...
INSERT INTO docs15
SELECT * FROM documents WHERE (id%16)=15
De hecho, si realiza una división de datos de este tipo, y a partir de una tabla SQL gigante en MySQL en su computadora portátil valiente, generará 16 tablas pequeñas, sin ir más allá de una sola computadora portátil, ni un solo esquema, ni una sola base de datos, etc. . etcétera. - eso es todo, ya tienes sharding.
Esto da como resultado lo siguiente:
- El ancho de banda aumenta.
- La latencia no cambia, es decir, cada uno, por así decirlo, trabajador o consumidor en este caso, obtiene lo suyo. Se atienden diferentes solicitudes aproximadamente al mismo tiempo.
- O ambos, y otro, y también alta disponibilidad (replicación).
¿Por qué ancho de banda? A veces podemos tener tales volúmenes de datos que no encajan - no está claro dónde, pero no encajan - en 1 {kernel | disco | servidor | ...}. Simplemente no hay suficientes recursos, eso es todo. Para trabajar con este gran conjunto de datos, debe cortarlo.
¿Por qué latencia? En un núcleo, escanear una tabla de 2 mil millones de filas es 20 veces más lento que escanear 20 tablas en 20 núcleos, haciéndolo en paralelo. Los datos se procesan con demasiada lentitud en un solo recurso.
¿Por qué alta disponibilidad? O cortamos los datos para hacer ambas cosas al mismo tiempo y, al mismo tiempo, varias copias de cada fragmento: la replicación garantiza una alta disponibilidad.
1.3 Un ejemplo sencillo "cómo hacerlo a mano"
La fragmentación condicional se puede eliminar utilizando la tabla de prueba test.documents para 32 documentos y generando 16 tablas de prueba a partir de esta tabla, aproximadamente 2 documentos cada test.docs00, 01, 02, ..., 15.
INSERT INTO docs00
SELECT * FROM documents WHERE (id%16)=0
...
INSERT INTO docs15
SELECT * FROM documents WHERE (id%16)=15
¿Por qué? Porque a priori no sabemos cómo se distribuyen los id, si del 1 al 32 inclusive, habrá exactamente 2 documentos cada uno, de lo contrario no.
Lo hacemos aquí por qué. Después de haber hecho 16 tablas, podemos "tomar" 16 de lo que necesitamos. Independientemente de lo que golpeemos, podemos paralelizar estos recursos. Por ejemplo, si no hay suficiente espacio en disco, tendría sentido descomponer estas tablas en discos separados.
Todo esto, por desgracia, no es gratis. Sospecho que en el caso del estándar SQL canónico (hace mucho tiempo que no releo el estándar SQL, tal vez hace mucho tiempo que no se actualiza), no existe una sintaxis estandarizada oficial para decirle a cualquier servidor SQL : "Estimado servidor SQL, hazme 32 fragmentos y divídelos en 4 discos. Pero en implementaciones individuales, a menudo hay una sintaxis específica para hacer básicamente lo mismo. PostgreSQL tiene mecanismos para particionar, MySQL tiene MariaDB, Oracle probablemente hizo todo esto hace mucho tiempo.
Sin embargo, si lo hacemos a mano, sin soporte de base de datos y en el marco del estándar, entonces pagamos condicionalmente con la complejidad del acceso a los datos . Donde había un simple SELECCIONAR * DESDE documentos DONDE id=123, ahora 16 x SELECCIONAR * DESDE docsXX. Y es bueno si tratamos de obtener el registro por clave. Mucho más interesante si estuviéramos tratando de obtener una gama temprana de registros. Ahora (si, enfatizo, somos, por así decirlo, tontos y permanecemos dentro del marco del estándar), los resultados de estos 16 SELECT * FROM deberán combinarse en la aplicación.
¿Qué cambio de rendimiento puede esperar?
- Intuitivamente - lineal.
- Teóricamente - sublineal, porque la ley de Amdahl.
- Prácticamente, tal vez casi linealmente, tal vez no.
De hecho, la respuesta correcta es desconocida. Con una aplicación inteligente de la técnica de fragmentación, puede lograr una degradación superlineal significativa en el rendimiento de su aplicación, e incluso el DBA se ejecutará con un atizador al rojo vivo.
Veamos cómo se puede lograr esto. Está claro que simplemente establecer la configuración en fragmentos de PostgreSQL = 16, y luego despegar solo, no es interesante. Pensemos en cómo podemos asegurarnos de reducir la velocidad de fragmentación 16 veces por 32; esto es interesante desde el punto de vista de cómo no hacer esto.
Nuestros intentos de acelerar o ralentizar siempre se toparán con los clásicos: la vieja y buena ley de Amdahl, que dice que no existe una paralelización perfecta de ninguna solicitud, siempre hay alguna parte consistente.
1.4 Ley de Amdahl
Siempre hay una parte serializada.
Siempre hay una parte de la ejecución de la consulta que está en paralelo, y siempre hay una parte que no está en paralelo. Aunque te parezca una consulta perfectamente paralela, al menos la colección de la fila de resultados que vas a enviar al cliente a partir de las filas recibidas de cada fragmento siempre está ahí, y siempre es secuencial.
Siempre hay alguna parte consistente. Puede ser pequeño, completamente invisible en el contexto general, puede ser gigantesco y, en consecuencia, afectar fuertemente la paralelización, pero siempre existe.
Además, su influencia está cambiando y puede crecer significativamente, por ejemplo, si recortamos nuestra mesa -aumentemos las apuestas- de 64 registros a 16 tablas de 4 registros, esta parte cambiará. Por supuesto, a juzgar por cantidades de datos tan gigantescas, estamos trabajando en un teléfono móvil y un procesador 86 de 2 MHz, y no tenemos suficientes archivos que se puedan mantener abiertos al mismo tiempo. Aparentemente, con tales entradas, abrimos un archivo a la vez.
- Era Total = Serie + Paralelo . Donde, por ejemplo, paralelo es todo el trabajo dentro de la base de datos y serial envía el resultado al cliente.
- Se convirtió en Total2 = Serie + Paralelo/N + Xserial . Por ejemplo, cuando el pedido general POR, Xserial>0.
Con este ejemplo simple, estoy tratando de mostrar que aparece algún Xserial. Además del hecho de que siempre hay una parte serializada y del hecho de que estamos tratando de trabajar con datos en paralelo, hay una parte adicional para proporcionar este corte de datos. En términos generales, es posible que necesitemos:
- encuentre estas 16 tablas en el diccionario interno de la base de datos;
- abrir archivos;
- asignar memoria;
- desasignar memoria;
- combinar resultados;
- sincronizar entre núcleos.
Todavía aparecen algunos efectos fuera de sincronización. Pueden ser insignificantes y ocupar una milmillonésima parte del tiempo total, pero siempre son distintos de cero y siempre están ahí. Con su ayuda, podemos perder drásticamente el rendimiento después de la fragmentación.

Esta es una imagen estándar sobre la ley de Amdahl. Lo importante aquí es que las líneas, que idealmente deberían ser rectas y crecer linealmente, se conviertan en una asíntota. Pero como el gráfico de Internet es ilegible, hice, en mi opinión, tablas más visuales con números.
Digamos que tenemos una parte serializada del procesamiento de solicitudes que solo toma el 5 %: serial = 0.05 = 1/20 .
Intuitivamente, parecería que con una parte serializada que toma solo 1/20 del procesamiento de la solicitud, si paralelizamos el procesamiento de la solicitud para 20 núcleos, se volverá alrededor de 20, en el peor de los casos 18, veces más rápido.
De hecho, las matemáticas son una cosa sin corazón :
pared = 0.05 + 0.95/num_cores, aceleración = 1 / (0.05 + 0.95/num_cores)
Resulta que si calculas cuidadosamente, con una parte serializada del 5 %, la aceleración será de 10 veces (10,3), que es un 51 % en comparación con el ideal teórico.
| 8 núcleos | = 5,9 | = 74% |
| 10 núcleos | = 6,9 | = 69% |
| 20 núcleos | = 10,3 | = 51% |
| 40 núcleos | = 13,6 | = 34% |
| 128 núcleos | = 17,4 | = 14% |
Después de haber usado 20 núcleos (20 discos, si lo desea) para la tarea en la que solía trabajar, nunca obtendremos una aceleración de más de 20 veces, ni siquiera teóricamente, pero en la práctica, mucho menos. Además, con un aumento en el número de paralelos, la ineficiencia aumenta considerablemente.
Cuando solo queda el 1% del trabajo serializado y el 99% está paralelizado, los valores de aceleración mejoran un poco:
| 8 núcleos | = 7,5 | = 93% |
| 16 núcleos | = 13,9 | = 87% |
| 32 núcleos | = 24,4 | = 76% |
| 64 núcleos | = 39,3 | = 61% |
Para una consulta perfectamente termonuclear, que naturalmente toma horas en completarse, y el trabajo preparatorio y el ensamblaje del resultado toman muy poco tiempo (serie = 0.001), ya veremos una buena eficiencia:
| 8 núcleos | = 7,94 | = 99% |
| 16 núcleos | = 15,76 | = 99% |
| 32 núcleos | = 31,04 | = 97% |
| 64 núcleos | = 60,20 | = 94% |
Tenga en cuenta que nunca veremos el 100% . En casos especialmente buenos, puede ver, por ejemplo, el 99,999 %, pero no exactamente el 100 %.
GO TO FULL VERSION