5.1 Distribución de datos
Consideremos cómo se distribuyen los datos según la clave entre los nodos del clúster. Cassandra le permite establecer una estrategia de distribución de datos. La primera estrategia de este tipo distribuye los datos según el valor de la clave md5: un particionador aleatorio. El segundo tiene en cuenta la representación de bits de la clave en sí: el marcado ordinal (particionador ordenado por bytes).
La primera estrategia, en su mayor parte, brinda más ventajas, ya que no necesita preocuparse por la distribución uniforme de datos entre servidores y tales problemas. La segunda estrategia se usa en casos excepcionales, por ejemplo, si se necesitan consultas de intervalo (escaneo de rango). Es importante señalar que la elección de esta estrategia se realiza antes de la creación del clúster y, de hecho, no se puede cambiar sin una recarga completa de los datos.
Cassandra utiliza una técnica conocida como hashing consistente para distribuir datos. Este enfoque le permite distribuir datos entre nodos y asegurarse de que cuando se agrega y elimina un nuevo nodo, la cantidad de datos transferidos es pequeña. Para hacer esto, a cada nodo se le asigna una etiqueta (token), que divide el conjunto de todos los valores clave md5 en partes. Dado que RandomPartitioner se usa en la mayoría de los casos, considerémoslo.
Como dije, RandomPartitioner calcula un md5 de 128 bits para cada clave. Para determinar en qué nodos se almacenarán los datos, simplemente revisa todas las etiquetas de los nodos de menor a mayor, y cuando el valor de la etiqueta sea mayor que el valor de la clave md5, entonces este nodo, junto con un número de nodos subsiguientes (en el orden de las etiquetas) se selecciona para el almacenamiento. El número total de nodos seleccionados debe ser igual al factor de replicación. El nivel de replicación se establece para cada espacio de claves y le permite ajustar la redundancia de datos (redundancia de datos).


Antes de que se pueda agregar un nodo al clúster, se le debe asignar una etiqueta. El porcentaje de claves que cubren el espacio entre esta etiqueta y la siguiente determina la cantidad de datos que se almacenarán en el nodo. El conjunto completo de etiquetas para un grupo se denomina anillo.
Aquí hay una ilustración que usa la utilidad nodetool incorporada para mostrar un anillo de clúster de 6 nodos con etiquetas espaciadas uniformemente.

5.2 Coherencia de datos al escribir
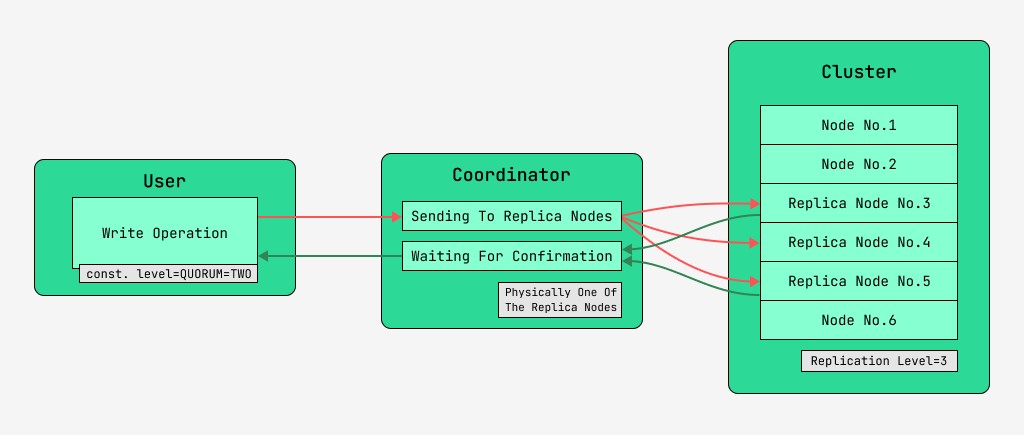
Los nodos del clúster de Cassandra son equivalentes y los clientes pueden conectarse a cualquiera de ellos, tanto para escribir como para leer. Las solicitudes pasan por la etapa de coordinación, durante la cual, habiendo descubierto con la ayuda de la clave y el marcado en qué nodos deben ubicarse los datos, el servidor envía solicitudes a estos nodos. Al nodo que realiza la coordinación lo llamaremos coordinador , ya los nodos que se seleccionan para guardar el registro con la clave dada, los nodos réplica . Físicamente, uno de los nodos de réplica puede ser el coordinador; depende solo de la clave, el marcado y las etiquetas.
Para cada solicitud, tanto de lectura como de escritura, es posible establecer el nivel de consistencia de los datos.
Para una escritura, este nivel afectará la cantidad de nodos de réplica que esperarán la confirmación de la finalización exitosa de la operación (datos escritos) antes de devolver el control al usuario. Para un registro, existen estos niveles de consistencia:
- UNO : el coordinador envía solicitudes a todos los nodos de réplica, pero después de esperar la confirmación del primer nodo, devuelve el control al usuario;
- DOS : lo mismo, pero el coordinador espera la confirmación de los dos primeros nodos antes de devolver el control;
- TRES : similar, pero el coordinador espera la confirmación de los primeros tres nodos antes de devolver el control;
- QUORUM : se recopila un quórum: el coordinador está esperando la confirmación del registro de más de la mitad de los nodos de réplica, es decir, la ronda (N / 2) + 1, donde N es el nivel de replicación;
- LOCAL_QUORUM : el coordinador está esperando la confirmación de más de la mitad de los nodos de réplica en el mismo centro de datos donde se encuentra el coordinador (potencialmente diferente para cada solicitud). Le permite deshacerse de los retrasos asociados con el envío de datos a otros centros de datos. Los problemas de trabajar con muchos centros de datos se consideran en este artículo de pasada;
- EACH_QUORUM : el coordinador está esperando la confirmación de más de la mitad de los nodos de réplica en cada centro de datos, de forma independiente;
- TODOS : el coordinador espera la confirmación de todos los nodos de réplica;
- CUALQUIERA : permite escribir datos, incluso si todos los nodos de réplica no responden. El coordinador espera la primera respuesta de uno de los nodos de réplica o que los datos se almacenen mediante un traspaso sugerido al coordinador.
5.3 Coherencia de datos al leer
Para las lecturas, el nivel de consistencia afectará la cantidad de nodos de réplica de los que se leerán. Para la lectura, existen estos niveles de consistencia:
- UNO : el coordinador envía solicitudes al nodo de réplica más cercano. El resto de las réplicas también se leen para reparación de lectura con la probabilidad especificada en la configuración de cassandra;
- DOS es lo mismo, pero el coordinador envía solicitudes a los dos nodos más cercanos. Se elige el valor con la marca de tiempo más grande;
- TRES - similar a la opción anterior, pero con tres nodos;
- QUORUM : se recopila un quórum, es decir, el coordinador envía solicitudes a más de la mitad de los nodos de réplica, es decir, ronda (N / 2) + 1, donde N es el nivel de replicación;
- LOCAL_QUORUM : se recopila un quórum en el centro de datos en el que se lleva a cabo la coordinación y se devuelven los datos con la última marca de tiempo;
- EACH_QUORUM - El coordinador devuelve datos después de la reunión del quórum en cada uno de los centros de datos;
- TODO : el coordinador devuelve datos después de leer de todos los nodos de réplica.

Por lo tanto, es posible ajustar los tiempos de retardo de las operaciones de lectura y escritura y ajustar la consistencia (tune coherencia), así como la disponibilidad (availability) de cada tipo de operación. De hecho, la disponibilidad está directamente relacionada con el nivel de consistencia de las lecturas y escrituras, ya que determina cuántos nodos de réplica pueden dejar de funcionar y aún así confirmarse.
Si la cantidad de nodos de los que proviene el reconocimiento de escritura, más la cantidad de nodos de los que se realiza la lectura, es mayor que el nivel de replicación, entonces tenemos la garantía de que el nuevo valor siempre se leerá después de la escritura, y esto se llama consistencia fuerte (strong-consistencia). En ausencia de una consistencia sólida, existe la posibilidad de que una operación de lectura devuelva datos obsoletos.
En cualquier caso, el valor eventualmente se propagará entre las réplicas, pero solo después de que finalice la espera de coordinación. Esta propagación se llama consistencia eventual. Si no todos los nodos de réplica están disponibles en el momento de la escritura, tarde o temprano entrarán en juego las herramientas de recuperación, como las lecturas correctivas y la reparación de nodos anti-entropía. Más sobre esto más adelante.
Por lo tanto, con un nivel de consistencia de lectura y escritura QUORUM, siempre se mantendrá una fuerte consistencia, y esto será un equilibrio entre la latencia de lectura y escritura. Con TODAS las escrituras y UNA lectura habrá una gran consistencia y las lecturas serán más rápidas y estarán más disponibles, es decir, la cantidad de nodos fallidos en los que aún se completará una lectura puede ser mayor que con QUORUM.
Para las operaciones de escritura, se requerirán todos los nodos trabajadores de réplica. Al escribir UNO, leyendo TODOS, también habrá una consistencia estricta, y las operaciones de escritura serán más rápidas y la disponibilidad de escritura será grande, porque será suficiente para confirmar solo que la operación de escritura tuvo lugar en al menos uno de los servidores, mientras que la lectura es más lenta y requiere todos los nodos de réplica. Si una aplicación no tiene un requisito de coherencia estricta, es posible acelerar las operaciones de lectura y escritura, así como mejorar la disponibilidad estableciendo niveles de coherencia más bajos.
GO TO FULL VERSION