1. A karakterláncok összehasonlítása
Ez mind jó és jó. De láthatja, hogy a s1és s2karakterláncok valójában ugyanazok, vagyis ugyanazt a szöveget tartalmazzák. A karakterláncok összehasonlításakor hogyan mondod meg a programnak, hogy ne az Stringobjektumok címét, hanem a tartalmát nézze?
Ebben segít nekünk a Java Stringosztályának a equalsmódszere. A hívás így néz ki:
string1.equals(string2)Ez a metódus akkor tér vissza true, ha a karakterláncok megegyeznek, és falseha nem azonosak.
Példa:
| Kód | jegyzet |
|---|---|
|
|

További példák:
| Kód | Magyarázat |
|---|---|
|
false |
|
true |
|
true |
|
true |
2. Kis- és nagybetűk közötti karakterlánc-összehasonlítás
Az utolsó példában azt látta, hogy az összehasonlítás eredménye . Valójában a húrok nem egyenlőek. De..."Hello".equals("HELLO")false
Nyilvánvaló, hogy a húrok nem egyenlőek. Ennek ellenére a tartalmuk ugyanazokat a betűket tartalmazza, és csak a betűk kis- és nagybetűi szerint tér el. Van-e mód összehasonlítani őket, és figyelmen kívül hagyni a betűk nagybetűjét? Vagyis így hoz ?"Hello".equals("HELLO")true
És a válasz erre a kérdésre igen. Java nyelven a Stringtípusnak van egy másik speciális metódusa is: equalsIgnoreCase. A hívás így néz ki:
string1.equalsIgnoreCase(string2)A metódus neve nagyjából azt jelenti, hogy összehasonlítjuk, de figyelmen kívül hagyjuk a kis- és nagybetűket . A metódus nevében szereplő betűk két függőleges vonalat tartalmaznak: az első egy kisbetű L, a második pedig egy nagybetű i. Ne hagyd, hogy ez összezavarjon.
Példa:
| Kód | jegyzet |
|---|---|
|
|
3. Példa karakterlánc-összehasonlításra
Mondjunk csak egy egyszerű példát: tegyük fel, hogy be kell írnia két sort a billentyűzetről, és meg kell határoznia, hogy ugyanazok-e. Így fog kinézni a kód:
Scanner console = new Scanner(System.in);
String a = console.nextLine();
String b = console.nextLine();
String result = a.equals(b) ? "Same" : "Different";
System.out.println(result);4. Érdekes árnyalat a húr-összehasonlításhoz
Van egy fontos árnyalat, amellyel tisztában kell lennie.
Ha a Java fordító több azonos karakterláncot talál a kódban (konkrétan a kódban), akkor a memória megtakarítása érdekében csak egyetlen objektumot hoz létre számukra.
String text = "This is a very important message";
String message = "This is a very important message";És íme, mit fog tartalmazni a memória ennek eredményeként:
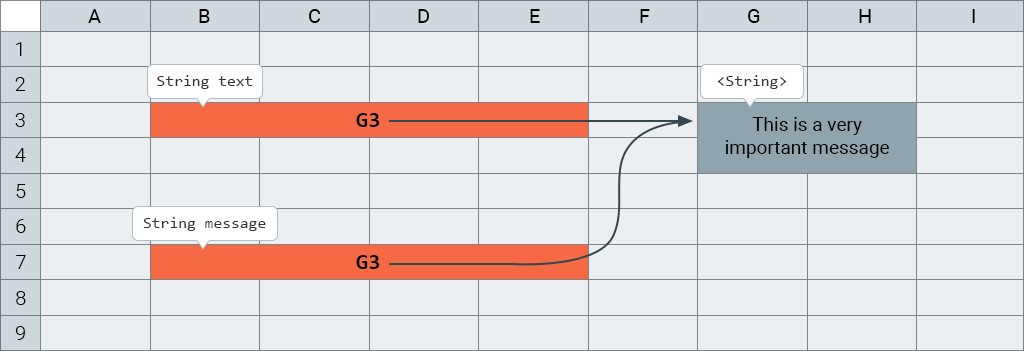
És ha itt összehasonlítod text == message, akkor megkapod true. Szóval ezen ne csodálkozz.
Ha valamilyen oknál fogva nagyon szüksége van arra, hogy a hivatkozások eltérőek legyenek, akkor ezt írhatja:
String text = "This is a very important message";
String message = new String ("This is a very important message");Vagy ez:
String text = "This is a very important message";
String message = new String (text);Mindkét esetben a textés messageváltozók különböző objektumokra mutatnak, amelyek ugyanazt a szöveget tartalmazzák.
GO TO FULL VERSION