Java의 컬렉션이란 무엇입니까?
Java의 컬렉션은 모든 요소를 단일 단위로 그룹화하는 컨테이너로 표시됩니다. 예를 들어 메일 폴더(이메일 그룹), 전화번호부(이름과 전화번호 매핑) 등이 있습니다.프레임워크란 무엇입니까?
프레임워크는 제공된 다양한 클래스와 인터페이스를 사용하여 작업을 시작하는 기본 기반 또는 레이아웃입니다. 예를 들어 , Laravel은 애플리케이션의 기본 뼈대를 제공하는 가장 유명한 PHP 프레임워크 중 하나입니다.Java의 컬렉션 프레임워크란 무엇입니까?
모든 개체는 컬렉션을 조작하기 위한 다양한 방법을 나타내고 제공하는 아키텍처와 함께 단일 개체로 그룹화됩니다. 따라서 Java의 컬렉션 프레임워크는 데이터 및 메소드를 저장하고 정렬, 검색, 삭제 및 삽입 과 같은 기능을 사용하여 조작하기 위해 이미 구현된 다양한 데이터 구조를 제공합니다 . 예를 들어 , 임의의 회사가 선착순으로 고객 서비스를 개선하기 위한 시스템을 구현하려고 합니다. 이는 FIFO(선입선출) 구현이라고도 합니다. 이제 우리는 이 데이터 구조를 구현한 다음 이를 사용하여 목표를 달성해야 합니다. 컬렉션 프레임워크는 구현보다는 가져오기만 하면 되는 Queue 인터페이스를 제공하고 이를 사용하면 작업이 완료됩니다. 구현 : 다음 줄을 사용하여 모든 컬렉션을 가져올 수 있습니다.import java.util.*;import java.util.LinkedList;Java 컬렉션 프레임워크의 이점
다음과 같은 이점이 있습니다.- 이미 구현되었습니다(시간 절약).
- 성능 효율성(속도 및 품질).
- 새로운 API를 배우고 사용하는 노력이 줄어듭니다.
컬렉션 프레임워크의 계층 구조는 무엇입니까?
이제 컬렉션 계층 구조를 살펴보겠습니다. 하지만 먼저 이 프레임워크의 필수 구성 요소를 알아야 합니다.- 인터페이스
- 클래스(구현)
- 알고리즘
수집 프레임워크의 계층 구조
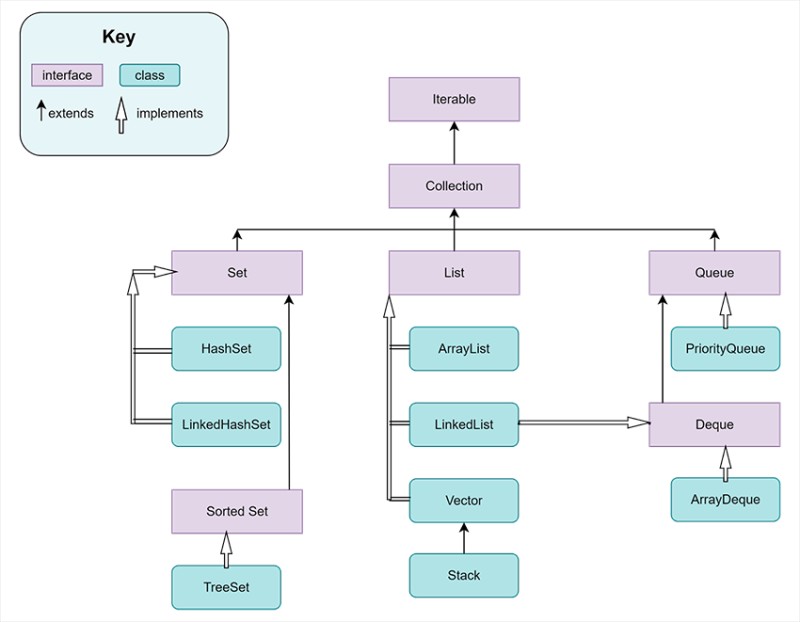 당신의 이해를 돕기 위해:
당신의 이해를 돕기 위해:
- Collection, Set, Queue 및 List는 모두 인터페이스입니다. Set, Queue 및 List는 Collection 인터페이스에 의해 확장 됩니다.
- PriorityQueue, HashSet, LinkedList 및 Stack은 모두 클래스이거나 이러한 인터페이스의 구현입니다.
- 클래스가 하나의 인터페이스만 구현하는 것이 필수는 아닙니다 . 예를 들어 LinkedList는 Deque 인터페이스도 구현합니다.
컬렉션 유형
Java 컬렉션 프레임워크에는 우리의 노력을 줄이기 위해 많은 유형의 컬렉션이 있습니다. 다음은 일부 컬렉션 목록입니다.- ArrayList 클래스
- 링크드리스트 클래스
- 목록 인터페이스
- 인터페이스 설정
- 대기열 인터페이스
- 지도 인터페이스
- PriorityQueue 클래스
- 해시맵 클래스
- 비교 가능한 인터페이스
- LinkedHashMap 클래스
- 트리맵 클래스
- 해시테이블
컬렉션 인터페이스
여기에서는 몇 가지 일반적인 컬렉션 인터페이스와 클래스에서 구현하는 몇 가지 메서드에 대해 설명합니다.수집 인터페이스
이는 구현에 필요한 모든 방법을 제공하므로 컬렉션 프레임워크의 기본 기반입니다. Map은 이를 구현하지 않는 유일한 데이터 구조이지만 나머지는 모두 해당 메소드를 구현합니다. 이 인터페이스에는 컬렉션의 크기, 개체가 컬렉션에 존재하는지 여부, 컬렉션에서 개체를 추가하거나 제거하는 방법을 알 수 있는 메서드가 있습니다.반복 가능한 인터페이스
모든 클래스에 의해 구현되는 Collection 인터페이스에 의해 확장되므로 Collections 프레임워크의 루트 인터페이스입니다. 특정 컬렉션을 반복할 반복자를 반환합니다.대기열 인터페이스
대기열은 요소를 보유하는 데 사용되지만 처리할 수는 없습니다. 기본 컬렉션 작업을 구현하면서 추가 삽입 및 추출 방법도 제공합니다.인터페이스 설정
세트는 고유한 요소를 보유하는 데 사용됩니다. 이는 중복된 요소를 포함하지 않으며 수학적 집합 추상화를 모델링하여 기계에서 실행되는 프로세스와 같은 집합을 나타냅니다.
목록 인터페이스
리스트는 중복된 요소를 보유할 수 있는 시퀀스라고도 하는 순서가 지정된 컬렉션입니다. 정수 인덱스 값을 사용하여 특정 지점에 요소를 삽입하고 특정 요소를 업데이트하거나 제거하기 위한 제어를 사용자에게 제공합니다. LinkedList 및 ArrayList는 List 인터페이스의 구현 클래스입니다.데크 인터페이스
Deque는 양쪽 끝에서 작업을 수행할 수 있음을 의미하는 이중 끝 큐를 나타냅니다. 양쪽 끝에서 요소를 삽입하고 제거할 수 있습니다. Deque 인터페이스는 대기열 인터페이스를 확장합니다. ArrayDeque와 LinkedList는 모두 Deque 인터페이스를 구현합니다. 양쪽 끝에서 인스턴스를 삽입, 삭제 및 검사하는 방법을 제공합니다.지도 인터페이스
맵 인터페이스도 컬렉션 프레임워크의 일부이지만 컬렉션 인터페이스를 확장하지는 않습니다. 키-값 쌍을 저장하는 데 사용됩니다. 주요 구현은 HashSet, TreeSet 및 LinkedHashSet과 특정 측면에서 유사한 HashMap, TreeMap 및 LinkesHashMap입니다. 항상 고유 키를 포함하지만 값이 중복될 수 있습니다. 키를 기준으로 항목을 추가, 삭제, 검색해야 할 때 유용합니다. put , get , Remove , size , empty 등과 같은 기본 메소드를 제공합니다 .이러한 인터페이스의 일반적인 방법
이제 우리는 Map 인터페이스를 제외하고 이 프레임워크에서 다양한 클래스를 구현하기 위해 제공되는 몇 가지 일반적인 메서드를 살펴보겠습니다.| 행동 양식 | 설명 |
|---|---|
| 공개 부울 추가(E e) | 컬렉션에 요소를 삽입하는 데 사용됩니다. |
| 공개 부울 제거(객체 요소) | 컬렉션에서 요소를 제거하는 데 사용됩니다. |
| 공개 정수 크기() | 컬렉션의 요소 수를 반환합니다. |
| 공개 부울 포함(객체 요소) | 요소를 검색하는 데 사용됩니다. |
| 공개 부울 isEmpty() | 컬렉션이 비어 있는지 확인합니다. |
| 공개 부울 같음(객체 요소) | 동등성을 확인합니다. |
컬렉션 클래스
우리가 알고 있듯이 프레임워크에는 내부의 많은 클래스에 의해 구현되는 다양한 인터페이스가 있습니다. 이제 일반적으로 사용되는 몇 가지 클래스를 살펴보겠습니다.링크드리스트
내부에 요소를 저장하기 위해 이중 연결 목록을 구현하는 가장 일반적으로 사용되는 데이터 구조입니다. 중복된 요소를 저장할 수 있습니다. Queue 인터페이스와 List 인터페이스에 의해 확장된 Dequeue 인터페이스를 구현합니다. 동기화되지 않았습니다. 이제 LinkedList를 사용하여 위에서 논의한 문제(FIFO 개념)를 해결하는 방법을 살펴보겠습니다. 문제는 고객이 도착하는 방식, 즉 선입선출 방식 으로 고객에게 서비스를 제공하는 것입니다 .예
import java.util.*;
public class LinkedListExample {
public static void main(String[] args) {
Queue<String> customerQueue = new LinkedList<String>();
//Adding customers to the Queue as they arrived
customerQueue.add("John");
customerQueue.add("Angelina");
customerQueue.add("Brooke");
customerQueue.add("Maxwell");
System.out.println("Customers in Queue:"+customerQueue);
//element() => returns head of the queue
//we will see our first customer and serve him
System.out.println("Head of the queue i.e first customer: "+customerQueue.element());
//remove () method =>removes first element(customer) from the queue i.e the customer is served so remove him to see next
System.out.println("Element removed from the queue: "+customerQueue.remove());
//poll () => removes and returns the head
System.out.println("Poll():Returned Head of the queue: "+customerQueue.poll());
//print the remaining customers in the Queue
System.out.println("Final Queue:"+customerQueue);
}
}산출
대기열의 고객:[John, Angelina, Brooke, Maxwell] 대기열의 헤드, 즉 첫 번째 고객: John 요소가 대기열에서 제거됨: John Poll():반환된 대기열의 헤드: Angelina 최종 대기열:[Brooke, Maxwell]
배열목록
이는 단순히 List 인터페이스를 구현합니다. 삽입 순서를 유지하고 동적 배열을 사용하여 다양한 데이터 유형의 요소를 저장합니다. 요소는 복제될 수 있습니다. 또한 비동기화되어 있으며 null 값을 저장할 수 있습니다. 이제 다양한 방법을 살펴보겠습니다. 삽입해야 하는 레코드나 요소 수를 모를 때 유용합니다. 얼마나 많은 책을 보관해야 하는지 알 수 없는 도서관의 예를 들어보겠습니다. 따라서 책이 있을 때마다 이를 ArrayList에 삽입해야 합니다.예
public class ArrayListExample {
public static void main(String args[]) {
// Creating the ArrayList
ArrayList<String> books = new ArrayList<String>();
// Adding a book to the list
books.add("Absalom, Absalom!");
// Adding a book in array list
books.add("A Time to Kill");
// Adding a book to the list
books.add("The House of Mirth");
// Adding a book to the list
books.add("East of Eden");
// Traversing the list through Iterator
Iterator<String> itr = books.iterator();
while (itr.hasNext()) {
System.out.println(itr.next());
}
}
}산출
압살롬, 압살롬! 에덴 동쪽에 있는 미르스의 집을 죽일 시간
해시세트
이는 Set 인터페이스를 구현하며 중복된 값을 포함하지 않습니다. 값을 저장하기 위한 해시 테이블을 구현합니다. 또한 null 값도 허용됩니다. 삽입 순서를 유지하지 않지만 add , Remove , size 및 contain 메소드 에 대해 일정한 시간 성능을 제공합니다 . 검색 작업에 가장 적합하며 동기화되지 않습니다.예
import java.util.*;
class HashSetExample{
public static void main(String args[]){
//creating HashSet and adding elements to it
HashSet<Integer> hashSet=new HashSet();
hashSet.add(1);
hashSet.add(5);
hashSet.add(4);
hashSet.add(3);
hashSet.add(2);
//getting an iterator for the collection
Iterator<Integer> i=hashSet.iterator();
//iterating over the value
while(i.hasNext()) {
System.out.println(i.next());
}
}
}산출
1 2 3 4 5
보시다시피 삽입 순서를 유지하지 않습니다.
ArrayDeque
Deque 인터페이스를 구현하여 양쪽 끝에서 작업이 가능하도록 합니다. null 값은 허용되지 않습니다. Stack, LinkedList로 구현하면 Stack, LinkedList보다 속도가 빠릅니다. ArrayDeque는 요구 사항에 따라 확장 및 축소되므로 크기 제한이 없습니다. 비동기화되어 있어 스레드로부터 안전하지 않습니다. 스레드로부터 안전한 상태를 유지하려면 일부 외부 논리를 구현해야 합니다.예
import java.util.*;
public class ArrayDequeExample {
public static void main(String[] args) {
//creating Deque and adding elements
Deque<String> deque = new ArrayDeque<String>();
//adding an element
deque.add("One");
//adding an element at the start
deque.addFirst("Two");
//adding an element at the end
deque.addLast("Three");
//traversing elements of the collection
for (String str : deque) {
System.out.println(str);
}
}
}산출
둘 하나 셋
해시맵
이는 해시 테이블이 지원하는 Map 인터페이스의 구현입니다. 키-값 쌍을 저장합니다. null 값은 허용되지 않습니다. 동기화되지 않았습니다. 삽입 순서를 보장하지 않습니다. get 및 put 과 같은 메서드에 대해 일정한 시간 성능을 제공합니다 . 성능은 초기 용량 과 부하율이라는 두 가지 요소에 따라 달라집니다 . 용량은 해시 테이블의 버킷 수이므로 초기 용량은 생성 시 할당된 버킷 수입니다. 로드 팩터는 용량이 증가하기 전에 해시 테이블이 채워질 수 있는 양을 측정한 것입니다. Rehash 방식은 용량을 늘리기 위해 사용되며 주로 버킷 수를 두 배로 늘립니다.예
import java.util.*;
public class HashMapExample{
public static void main(String args[]){
//creating a HashMap
HashMap<Integer,String> map=new HashMap<Integer,String>();
//putting elements into the map
map.put(1,"England");
map.put(2,"USA");
map.put(3,"China");
//get element at index 2
System.out.println("Value at index 2 is: "+map.get(2));
System.out.println("iterating map");
//iterating the map
for(Map.Entry m : map.entrySet()){
System.out.println(m.getKey()+" "+m.getValue());
}
}
}
산출
인덱스 2의 값은 다음과 같습니다. 중국 반복 지도 1 영국 2 미국 3 중국
알고리즘
컬렉션 프레임워크는 컬렉션에 적용할 다양한 작업에 대한 다양한 알고리즘을 제공합니다. 여기서는 이러한 알고리즘이 어떤 주요 작업을 다루는지 살펴보겠습니다. 여기에는 다음과 관련된 알고리즘이 포함되어 있습니다.- 정렬
- 수색
- 셔플링
- 일상적인 데이터 조작
- 구성
- 극단값 찾기
정렬
정렬 알고리즘은 순서 관계에 따라 목록을 다시 정렬합니다. 두 가지 형태의 관계가 제공됩니다.- 자연적인 순서
- 비교 정렬
자연적인 순서
자연 순서에서는 목록이 해당 요소에 따라 정렬됩니다.비교 정렬
이러한 순서 지정 형식에서는 비교기인 추가 매개변수가 목록과 함께 전달됩니다. 약간 최적화된 병합 정렬 알고리즘은 n log(n) 실행 시간을 보장하고 동일한 요소를 재정렬하지 않으므로 빠르고 안정적인 정렬에 사용됩니다. 정렬을 보여주기 위해 ArrayList의 동일한 예제를 사용할 것입니다.예
import java.util.*;
public class SortingExample{
public static void main(String args[]){
//Creating arraylist
ArrayList<String> books=new ArrayList<String>();
//Adding a book to the arraylist
books.add("A Time to Kill");
//Adding a book to the arraylist
books.add("Absalom, Absalom!");
//Adding a book to the arraylist
books.add("The House of Mirth");
//Adding a book to the arraylist
books.add("East of Eden");
//Traversing list through Iterator before sorting
Iterator itrBeforeSort=books.iterator();
while(itrBeforeSort.hasNext()){
System.out.println(itrBeforeSort.next());
}
//sorting the books
Collections.sort(books);
System.out.println("After sorting the books");
//Traversing list through Iterator after sorting
Iterator itr=books.iterator();
while(itr.hasNext()){
System.out.println(itr.next());
}
}
}산출
압살롬을 죽일 때다 압살롬아! 에덴동쪽 환희의 집 책을 정리한 후 압살롬을 죽일 때, 압살롬! 에덴의 동쪽 미르스의 집