"안녕, 아미고!"
"이제 또 다른 흥미로운 주제인 인코딩을 할 시간입니다."
"어디선가 이미 각 문자에 코드(숫자)가 있다는 말을 들었을 것입니다. 그래서 char 유형이 기호와 숫자를 모두 나타낼 수 있습니다."
"예를 들어 영어 알파벳 'A'의 코드는 65, 'B'는 66, 'C'는 67 등입니다. 대문자, 소문자, 키릴 문자, 중국어에 대한 고유 코드가 있습니다. 문자(예, 매우 많은 코드), 숫자 및 다양한 기호. 요컨대 문자라고 부르는 거의 모든 것에 대한 코드가 있습니다."
"그래서, 모든 문자와 문자는 어떤 숫자에 해당합니까?"
"정확히."
"문자는 숫자로 변환될 수 있고 숫자는 문자로 변환될 수 있습니다. Java는 일반적으로 이들 사이의 차이점을 보지 못합니다."
char c = 'A'; //The code (number) for 'A' is 65
c++; //Now c contains the number 66, which is the code for 'B'"흥미로운."
"그래서 인코딩은 일련의 기호와 그에 상응하는 코드 집합입니다. 그러나 단지 하나의 인코딩이 발명된 것이 아니라 꽤 많이 있습니다. 나중에야 공통 범용 인코딩인 유니코드가 발명되었습니다."

"그러나 아무리 많은 보편적 표준이 발명되더라도 아무도 서둘러 이전 표준을 포기하지 않습니다. 그러면 모든 것이 이 만화에서와 같이 발생합니다."
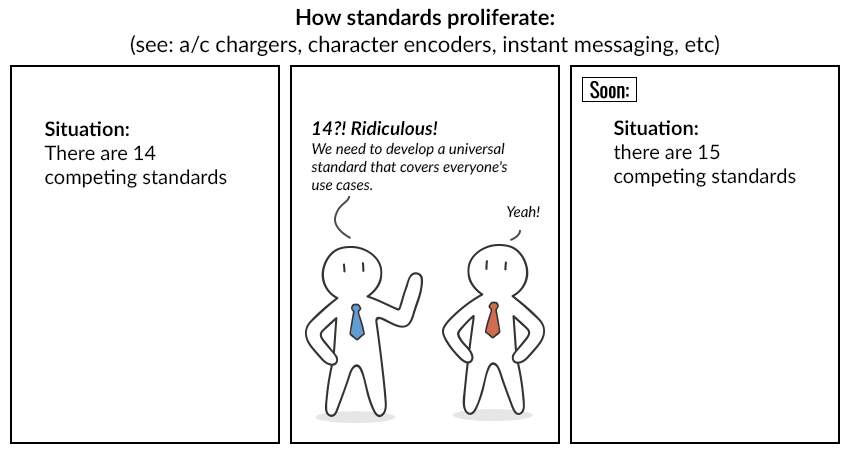
"Vincent와 Nick이 그들만의 인코딩을 만들기로 결정했다고 상상해보세요."
"빈센트의 인코딩은 다음과 같습니다."
"그리고 여기 Nick의 인코딩이 있습니다."
"심지어 같은 문자를 사용하지만 문자에 대한 코드가 다릅니다."
"문자열 'ABC-123'이 Vincent의 인코딩을 사용하여 파일에 기록되면 다음 바이트 세트를 얻습니다."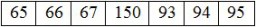
"그리고 이제 Nick의 인코딩을 사용하는 다른 프로그램이 파일을 읽으려고 합니다."
"다음과 같이 표시됩니다. «345-IJK»."
"그리고 최악의 상황은 일반적으로 인코딩이 파일의 어디에도 저장되지 않기 때문에 개발자가 추측해야 한다는 것입니다."
"글쎄, 그들은 어떻게 추측합니까?"
"그건 다른 주제입니다. 하지만 인코딩 작업 방법을 설명하고 싶습니다. 이미 알고 있듯이 Java의 문자 크기는 2바이트입니다. 그리고 Java 문자열은 유니코드 형식을 사용합니다."
"그러나 Java는 문자열을 알고 있는 모든 인코딩의 바이트 집합으로 변환할 수 있습니다. String 클래스에는 이를 위한 특수 메서드가 있습니다. Java에는 특정 인코딩을 설명하는 특수 Charset 클래스도 있습니다."
1) Java가 지원하는 모든 인코딩 목록을 어떻게 얻습니까?
"이를 위해 availableCharsets라는 특별한 정적 메서드가 있습니다. "이 메서드는 쌍 세트(인코딩 이름, 인코딩을 설명하는 개체)를 반환합니다."
SortedMap<String,Charset> charsets = Charset.availableCharsets();"각 인코딩에는 고유한 이름이 있습니다. UTF-8, UTF-16, Windows-1251, KOI8-R,…
2) 현재 활성 인코딩(유니코드)을 어떻게 얻습니까?
" 이를 위한 defaultCharset 이라는 특별한 방법이 있습니다 .
Charset currentCharset = Charset.defaultCharset();3) 문자열을 특정 인코딩으로 어떻게 변환합니까?
"Java에서는 Java가 알고 있는 모든 인코딩에서 문자열을 바이트 배열로 변환할 수 있습니다."
| 방법 | 예 |
|---|---|
|
|
|
|
|
|
4) 파일의 인코딩이 무엇인지 알고 있는 경우 파일에서 읽은 바이트 배열을 문자열로 변환하려면 어떻게 해야 합니까?
"훨씬 더 쉽습니다. String 클래스에는 특별한 생성자가 있습니다."
| 방법 | 예 |
|---|---|
|
|
|
|
|
|
5) 한 인코딩에서 다른 인코딩으로 바이트 배열을 어떻게 변환합니까?
"많은 방법이 있습니다. 다음은 가장 간단한 방법 중 하나입니다."
Charset koi8 = Charset.forName("KOI8-R");
Charset windows1251 = Charset.forName("Windows-1251");
byte[] buffer = new byte[1000];
inputStream.read(buffer);
String s = new String(buffer, koi8);
buffer = s.getBytes(windows1251);
outputStream.write(buffer);"그게 내가 생각한거야. 재미있는 수업 고마워, 리시."