Találjuk ki az újWorkStealingPool metódust, amely ExecutorService- t készít nekünk.

Ez a szálkészlet különleges. Viselkedése a munka "ellopásának" gondolatán alapul.
A feladatok sorba vannak állítva, és elosztják a processzorok között. De ha egy processzor foglalt, akkor egy másik ingyenes processzor ellophat tőle egy feladatot és végrehajthatja azt. Ezt a formátumot a Java-ban vezették be, hogy csökkentsék a konfliktusokat a többszálú alkalmazásokban. A fork/join keretre épül .
elágazás/csatlakozás
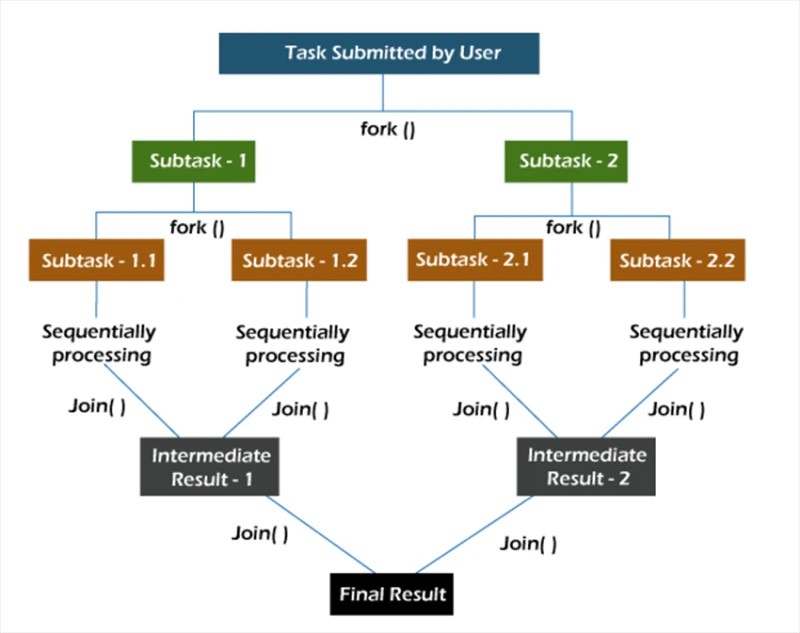
A fork/join keretrendszerben a feladatok rekurzív módon, azaz részfeladatokra bontásra kerülnek. Ezután a részfeladatokat egyenként hajtják végre, és a részfeladatok eredményeit kombinálják az eredeti feladat eredményévé.
A fork metódus aszinkron módon indít egy feladatot egy bizonyos szálon, az összekapcsolási módszer pedig lehetővé teszi, hogy megvárja a feladat befejezését.
newWorkStealingPool
Az újWorkStealingPool metódusnak két megvalósítása van:
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}Már az elején megjegyezzük, hogy a motorháztető alatt nem hívjuk meg a ThreadPoolExecutor konstruktort. Itt a ForkJoinPool entitással dolgozunk . A ThreadPoolExecutorhoz hasonlóan ez is az AbstractExecutorService megvalósítása .
2 módszer közül választhatunk. Az elsőben mi magunk jelezzük, hogy milyen szintű párhuzamosságot szeretnénk látni. Ha nem adjuk meg ezt az értéket, akkor a készletünk párhuzamossága megegyezik a Java virtuális gép számára elérhető processzormagok számával.

Még ki kell deríteni, hogyan működik a gyakorlatban:
Collection<Callable<Void>> tasks = new ArrayList<>();
ExecutorService executorService = Executors.newWorkStealingPool(10);
for (int i = 0; i < 10; i++) {
int taskNumber = i;
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
return null;
};
tasks.add(callable);
}
executorService.invokeAll(tasks);10 feladatot hozunk létre, amelyek saját teljesítési állapotukat jelenítik meg. Ezt követően az invokeAll metódussal elindítjuk az összes feladatot .
Eredmények 10 feladat végrehajtása során a készlet 10 szálán:
Feldolgozott felhasználói kérelem #4 a ForkJoinPool-1-worker-5 szálon.
Feldolgozott felhasználói kérelem #7 a ForkJoinPool-1-worker-8 szálon.
Feldolgozott felhasználói kérelem #1 a ForkJoinPool-on- 1-worker-2 szál
Feldolgozott felhasználói kérelem #2 a ForkJoinPool-1-worker-3 szálon
Feldolgozott felhasználói kérelem #3 a ForkJoinPool-1-worker-4 szálon
Feldolgozott felhasználói kérelem #6 a ForkJoinPool-1-worker-7 szálon
Feldolgozott felhasználó 0. kérés a ForkJoinPool-1-worker-1 szálon
Feldolgozott felhasználói kérelem #5 a ForkJoinPool-1-worker-6 szálon.
Feldolgozott felhasználói kérelem #8 a ForkJoinPool-1-worker-9 szálon
Azt látjuk, hogy a sor létrehozása után a szálak feladatokat vesznek fel végrehajtásra. Azt is ellenőrizheti, hogy 20 feladat hogyan lesz elosztva egy 10 szálból álló készletben.
Feldolgozott felhasználói kérelem #7 a ForkJoinPool-1-worker-8 szálon.
Feldolgozott felhasználói kérelem #2 a ForkJoinPool-1-worker-3 szálon.
Feldolgozott felhasználói kérelem #4 a ForkJoinPool-on- 1-worker-5 szál
Feldolgozott felhasználói kérelem #1 a ForkJoinPool-1-worker-2 szálon
Feldolgozott felhasználói kérelem #5 a ForkJoinPool-1-worker-6 szálon
Feldolgozott felhasználói kérelem #8 a ForkJoinPool-1-worker-9 szálon
Feldolgozott felhasználó 9. kérés a ForkJoinPool-1-worker-10 szálon
Feldolgozott felhasználói kérelem #0 a ForkJoinPool-1-worker-1 szálon.
Feldolgozott felhasználói kérelem #6 a ForkJoinPool-1-worker-7 szálon.
Feldolgozott felhasználói kérelem #10 a ForkJoinPool-1- szálon munkás-9 szál
Feldolgozott felhasználói kérelem #12 a ForkJoinPool-1-worker-1 szálon
Feldolgozott felhasználói kérelem #13 a ForkJoinPool-1-worker-8 szálon.
Feldolgozott felhasználói kérelem #11 a ForkJoinPool-1-worker-6 szálon
Feldolgozott felhasználói kérelem #15 a ForkJoinPool-on- 1-worker-8 szál
Feldolgozott felhasználói kérelem #14 ForkJoinPool-1-worker-1 szálon
Feldolgozott felhasználói kérelem #17 ForkJoinPool-1-worker-6 szálon
Feldolgozott felhasználói kérelem #16 ForkJoinPool-1-worker-7 szálon
Feldolgozott felhasználó 19. kérés a ForkJoinPool-1-worker-6 szálon
Feldolgozott felhasználói kérelem #18 a ForkJoinPool-1-worker-1 szálon
A kimenetből láthatjuk, hogy egyes szálak több feladatot is teljesítenek ( ForkJoinPool-1-worker-6 befejezte 4 feladatot), míg mások csak egyet ( ForkJoinPool-1-worker-2 ). Ha 1 másodperces késleltetést adunk a hívási módszer megvalósításához , a kép megváltozik.
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
return null;
};A kísérlet kedvéért futtassuk le ugyanazt a kódot egy másik gépen. A kapott kimenet:
Feldolgozott felhasználói kérelem #7 a ForkJoinPool-1-worker-31 szálon.
Feldolgozott felhasználói kérelem #4 a ForkJoinPool-1-worker-27 szálon.
Feldolgozott felhasználói kérelem #5 a ForkJoinPool-on- 1-worker-13 szál
Feldolgozott felhasználói kérelem #0 a ForkJoinPool-1-worker-19 szálon
Feldolgozott felhasználói kérelem #8 a ForkJoinPool-1-worker-3 szálon
Feldolgozott felhasználói kérelem #9 a ForkJoinPool-1-worker-21 szálon
Feldolgozott felhasználó 6. kérés a ForkJoinPool-1-worker-17 szálon
Feldolgozott felhasználói kérelem #3 a ForkJoinPool-1-worker-9 szálon. Feldolgozott felhasználói kérelem #
1 a ForkJoinPool-1-worker-5 szálon.
munkás-23 szál
Feldolgozott felhasználói kérelem #15 a ForkJoinPool-1-worker-19 szálon
Feldolgozott felhasználói kérelem #14 a ForkJoinPool-1-worker-27 szálon.
Feldolgozott felhasználói kérelem #11 a ForkJoinPool-1-worker-3 szálon.
Feldolgozott felhasználói kérelem #13 a ForkJoinPool-on 1-worker-13 szál
Feldolgozott felhasználói kérelem #10 a ForkJoinPool-1-worker-31 szálon
Feldolgozott felhasználói kérelem #18 a ForkJoinPool-1-worker-5 szálon
Feldolgozott felhasználói kérelem #16 a ForkJoinPool-1-worker-9 szálon
Feldolgozott felhasználó 17. kérés a ForkJoinPool-1-worker-21 szálon
Feldolgozott felhasználói kérelem #19 a ForkJoinPool-1-worker-17 szálon
Ebben a kimenetben figyelemre méltó, hogy "kértük" a szálakat a poolban. Ráadásul a munkásszálak nevei nem egyről tízre emelkednek, hanem néha tíznél magasabbak. Az egyedi neveket tekintve azt látjuk, hogy valóban tíz munkás van (3, 5, 9, 13, 17, 19, 21, 23, 27 és 31). Itt teljesen jogos a kérdés, hogy miért történt ez? Ha nem érti, mi történik, használja a hibakeresőt.
Ezt fogjuk tenni. Öntsük avégrehajtóSzolgáltatásobjektum egy ForkJoinPoolhoz :final ForkJoinPool forkJoinPool = (ForkJoinPool) executorService;Az InvokeAll metódus meghívása után a Kifejezés kiértékelése művelettel vizsgáljuk meg ezt az objektumot . Ehhez az invokeAll metódus után adjunk hozzá bármilyen utasítást, például egy üres kimenetet, és állítsunk be egy töréspontot.

Láthatjuk, hogy a készlet 10 szálból áll, de a dolgozói szálak tömbjének mérete 32. Furcsa, de rendben van. Ássuk tovább. A medence létrehozásakor próbáljuk meg a párhuzamossági szintet 32-nél többre, mondjuk 40-re állítani.
ExecutorService executorService = Executors.newWorkStealingPool(40);A hibakeresőben nézzük meg aforkJoinPool objektum ismét.

Most a munkaszálak tömbjének mérete 128. Feltételezhetjük, hogy ez a JVM egyik belső optimalizálása. Próbáljuk meg megtalálni a JDK kódjában (openjdk-14):

Ahogy gyanítottuk: a feldolgozószálak tömbjének méretét a párhuzamossági érték bitenkénti manipulációival számítjuk ki. Nem kell megpróbálnunk kitalálni, mi is történik itt pontosan. Elég csak azt tudni, hogy létezik ilyen optimalizálás.
Példánk másik érdekessége az invokeAll metódus használata . Érdemes megjegyezni, hogy az invokeAll metódus visszaadhat egy eredményt, vagy inkább egy eredménylistát (esetünkben egy List<Future<Vid>>) , ahol az egyes feladatok eredményét megtaláljuk.
var results = executorService.invokeAll(tasks);
for (Future<Void> result : results) {
// Process the task's result
}Ez a speciális szolgáltatás- és szálkészlet előre látható, vagy legalábbis implicit párhuzamossági szinttel rendelkező feladatokban használható.