讓我們弄清楚newWorkStealingPool方法,它為我們準備了一個ExecutorService 。

這個線程池很特別。它的行為是基於“竊取”工作的想法。
任務在處理器之間排隊和分配。但是如果一個處理器很忙,那麼另一個空閒的處理器可以從它那裡竊取一個任務並執行它。這種格式是在 Java 中引入的,目的是減少多線程應用程序中的衝突。它建立在fork/join框架之上。
分叉/加入
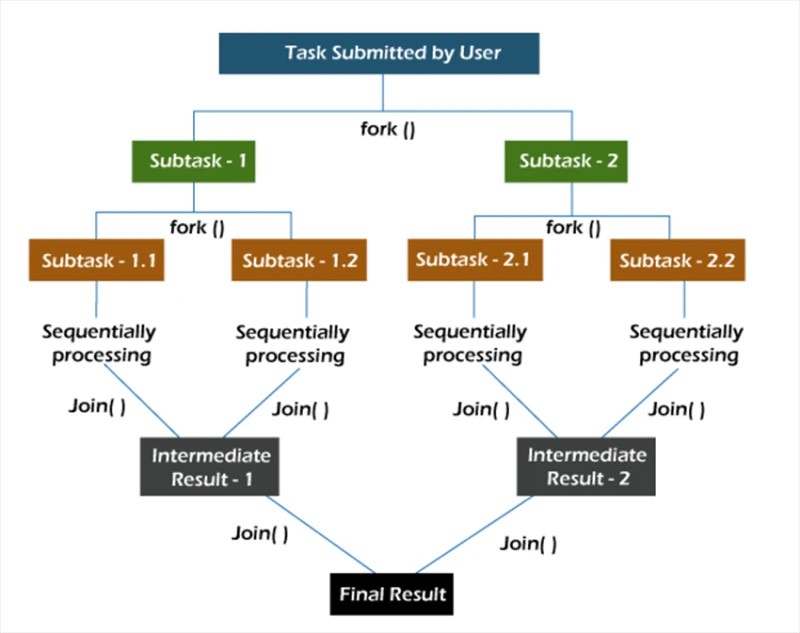
在fork/join框架中,任務被遞歸分解,即分解為子任務。然後將子任務單獨執行,將子任務的結果組合起來形成原任務的結果。
fork方法在某個線程上異步啟動任務,而join方法讓您等待該任務完成。
newWorkStealingPool
newWorkStealingPool方法有兩個實現:
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}從一開始,我們就注意到在幕後我們並沒有調用ThreadPoolExecutor構造函數。在這裡,我們正在使用ForkJoinPool實體。與ThreadPoolExecutor一樣,它是AbstractExecutorService的實現。
我們有 2 種方法可供選擇。首先,我們自己指出我們希望看到的並行性級別。如果我們不指定這個值,那麼我們的池的並行度將等於 Java 虛擬機可用的處理器核心數。
仍然需要弄清楚它在實踐中是如何工作的:

Collection<Callable<Void>> tasks = new ArrayList<>();
ExecutorService executorService = Executors.newWorkStealingPool(10);
for (int i = 0; i < 10; i++) {
int taskNumber = i;
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
return null;
};
tasks.add(callable);
}
executorService.invokeAll(tasks);我們創建了 10 個任務來顯示它們自己的完成狀態。之後,我們使用invokeAll方法啟動所有任務。
在池中的 10 個線程上執行 10 個任務時的結果:
在 ForkJoinPool-1-worker-5 線程
上處理的用戶請求 #4 在 ForkJoinPool-1-worker-8 線程上處理的用戶請求 #7 在
ForkJoinPool- 上處理的用戶請求 #1 1-worker-2 線程
在 ForkJoinPool-1-worker-3 線程上處理的用戶請求 #2
在 ForkJoinPool-1-worker-4 線程上處理的用戶請求 #3 在
ForkJoinPool-1-worker-7 線程上處理的用戶請求 #6
處理的用戶ForkJoinPool-1-worker-1 線程上的請求 #0 在
ForkJoinPool-1-worker-6 線程上處理的用戶請求 #5 在
ForkJoinPool-1-worker-9 線程上處理的用戶請求 #8
我們看到隊列形成後,線程就拿任務去執行。您還可以檢查 20 個任務將如何分配到 10 個線程的池中。
在 ForkJoinPool-1-worker-8 線程上
處理的用戶請求 #7 在 ForkJoinPool-1-worker-3 線程上處理的用戶請求 #2 在
ForkJoinPool- 上處理的用戶請求 #4 1-worker-5 線程
在 ForkJoinPool-1-worker-2 線程上處理的用戶請求 #1
在 ForkJoinPool-1-worker-6 線程上
處理的用戶請求 #5 在 ForkJoinPool-1-worker-9 線程上處理的用戶請求 #8
處理的用戶ForkJoinPool-1-worker-10 線程上的請求 #9
ForkJoinPool-1-worker-1 線程上已處理的用戶請求 #0
ForkJoinPool-1-worker-7 線程上已處理的用戶請求 #6
ForkJoinPool-1-上已處理的用戶請求 #10 worker-9 線程
在 ForkJoinPool-1-worker-1 線程上處理的用戶請求 #12
在 ForkJoinPool-1-worker-8 線程上處理的用戶請求 #13
在 ForkJoinPool-1-worker-6 線程上處理的用戶請求 #11 在
ForkJoinPool- 上處理的用戶請求 #15 1-worker-8 線程
在 ForkJoinPool-1-worker-1 線程上處理的用戶請求 #14
在 ForkJoinPool-1-worker-6 線程上處理的用戶請求 #17 在
ForkJoinPool-1-worker-7 線程上處理的用戶請求 #16
處理的用戶ForkJoinPool-1-worker-6 線程上的請求 #19
已處理的 ForkJoinPool-1-worker-1 線程上的用戶請求 #18
從輸出中,我們可以看到一些線程設法完成了幾個任務(ForkJoinPool-1-worker-6完成了 4 個任務),而一些線程只完成了一個(ForkJoinPool-1-worker-2)。如果在調用方法的實現中加入 1 秒的延遲,情況就會發生變化。
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
return null;
};為了進行實驗,讓我們在另一台機器上運行相同的代碼。結果輸出:
在 ForkJoinPool-1-worker-31 線程上處理的用戶請求 #7
在 ForkJoinPool-1-worker-27 線程上處理的用戶請求 #4 在
ForkJoinPool- 上處理的用戶請求 #5 1-worker-13 線程
在 ForkJoinPool-1-worker-19 線程上處理的用戶請求 #0
在 ForkJoinPool-1-worker-3 線程上處理的用戶請求 #8 在
ForkJoinPool-1-worker-21 線程上處理的用戶請求 #9
處理的用戶ForkJoinPool-1-worker-17 線程上的請求 #6 在
ForkJoinPool-1-worker-9 線程
上處理的用戶請求 #3 在 ForkJoinPool-1-worker-5 線程上處理的用戶請求 #1
在 ForkJoinPool-1- 上處理的用戶請求 #12 worker-23線程
在 ForkJoinPool-1-worker-19 線程上處理的用戶請求 #15
在 ForkJoinPool-1-worker-27 線程上處理的用戶請求 #14 在 ForkJoinPool
-1-worker-3 線程上處理的用戶請求 #11 在
ForkJoinPool- 上處理的用戶請求 #13 1-worker-13 線程
在 ForkJoinPool-1-worker-31 線程上處理的用戶請求 #10
在 ForkJoinPool-1-worker-5 線程上
處理的用戶請求 #18 在 ForkJoinPool-1-worker-9 線程上處理的用戶請求 #16
處理的用戶ForkJoinPool-1-worker-21 線程上的請求 #17
已處理的 ForkJoinPool-1-worker-17 線程上的用戶請求 #19
在此輸出中,值得注意的是我們“請求”池中的線程。而且,工作線程的名稱不是從一到十,而是有時大於十。查看唯一名稱,我們看到確實有十個工人(3、5、9、13、17、19、21、23、27 和 31)。在這裡問為什麼會這樣是很合理的?每當您不明白髮生了什麼時,請使用調試器。
這就是我們要做的。讓我們投執行服務反對ForkJoinPool:final ForkJoinPool forkJoinPool = (ForkJoinPool) executorService;在調用invokeAll方法後,我們將使用 Evaluate Expression 操作來檢查此對象。為此,在invokeAll方法之後,添加任何語句,例如空 sout,並在其上設置斷點。

我們可以看到池中有 10 個線程,但是工作線程數組的大小是 32。很奇怪,但是還好。讓我們繼續挖掘。創建池時,讓我們嘗試將並行度設置為 32 以上,比如 40。
ExecutorService executorService = Executors.newWorkStealingPool(40);在調試器中,讓我們看看再次 forkJoinPool 對象。

現在工作線程數組的大小是 128。我們可以假設這是 JVM 的內部優化之一。讓我們嘗試在JDK(openjdk-14)的代碼中找到它:

正如我們所懷疑的那樣:工作線程數組的大小是通過對並行度值執行按位操作來計算的。我們不需要試圖弄清楚這裡到底發生了什麼。只知道存在這樣的優化就足夠了。
我們示例的另一個有趣方面是invokeAll方法的使用。值得注意的是,invokeAll方法可以返回一個結果,或者更確切地說是一個結果列表(在我們的例子中,一個List<Future<Void>>),我們可以在其中找到每個任務的結果。
var results = executorService.invokeAll(tasks);
for (Future<Void> result : results) {
// Process the task's result
}這種特殊類型的服務和線程池可用於具有可預測或至少隱式並發級別的任務。