Zajmijmy się następującą metodą, która przygotowuje dla nas ExecutorService - newWorkStealingPool .

Ta pula wątków jest szczególna - koncepcja jej działania opiera się na „kradzieży” pracy.
Zadania są ustawiane w kolejce i rozdzielane między procesory. Ale jeśli procesor jest zajęty, inny wolny procesor może ukraść mu zadanie i wykonać je. Ten format został wprowadzony w Javie w celu zmniejszenia kontrowersji w aplikacjach wielowątkowych. Opiera się na frameworku fork/join .
widelec / połączenie
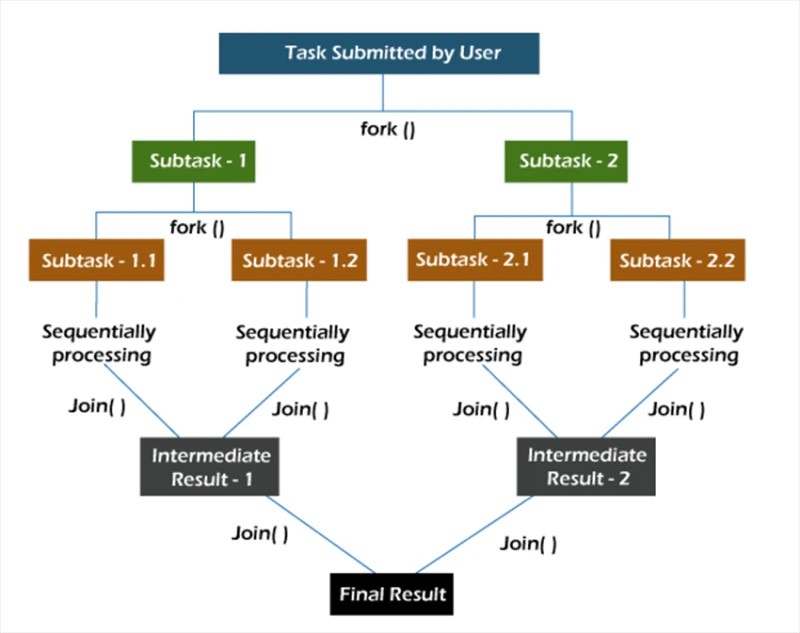
W ramach fork/join zadania są dekomponowane rekurencyjnie, czyli dzielone na podzadania. Następnie zadania są wykonywane indywidualnie, a wyniki podzadań są łączone, tworząc wyniki zadania głównego.
Metoda fork uruchamia zadanie asynchronicznie w jakimś wątku, a metoda join pozwala czekać na zakończenie pracy nad tym zadaniem.
nowośćPraca KradzieżPula
Metoda newWorkStealingPool ma dwie implementacje:
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}Od razu zauważamy, że pod maską nie wywołujemy konstruktora na ThreadPoolExecutor , tutaj pracujemy z jednostką ForkJoinPool . To, podobnie jak ThreadPoolExecutor , jest implementacją AbstractExecutorService .
Do wyboru mamy 2 metody. Różnią się tym, że w pierwszym przypadku sami wskazujemy, jaki poziom równoległości chcemy zobaczyć. Jeśli nie określimy tej wartości, to w naszej puli zobaczymy poziom równoległości równy liczbie rdzeni procesora dostępnych dla wirtualnej maszyny Javy w danym momencie.

Pozostaje dowiedzieć się, jak to naprawdę działa:
Collection<Callable<Void>> tasks = new ArrayList<>();
ExecutorService executorService = Executors.newWorkStealingPool(10);
for (int i = 0; i < 10; i++) {
int taskNumber = i;
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
return null;
};
tasks.add(callable);
}
executorService.invokeAll(tasks);Tworzymy 10 zadań, w których wyświetlamy status ich wykonania. Następnie uruchamiamy wszystkie zadania metodą invokeAll .
Wyniki przy wykonywaniu 10 zadań na 10 wątkach w puli:
Żądanie przetworzonego użytkownika nr 4 w wątku ForkJoinPool-1-pracownik-5
Żądanie przetworzonego użytkownika nr 7 w wątku ForkJoinPool-1-worker-8 Żądanie
przetworzonego użytkownika nr 1 w wątku ForkJoinPool -1-pracownik-2
Przetworzone żądanie od użytkownika nr 2 w wątku ForkJoinPool-1-pracownik-3
Przetworzone żądanie od użytkownika nr 3 w wątku ForkJoinPool-1-pracownik-4
Przetworzone żądanie od użytkownika nr 6 w wątku ForkJoinPool-1 -worker-7
Przetworzone żądanie użytkownika nr 0 w wątku ForkJoinPool-1-pracownik-1
Przetworzone żądanie użytkownika nr 5 w wątku ForkJoinPool-1-pracownik-6
Przetworzone żądanie użytkownika nr 8 w wątku ForkJoinPool-1-pracownik-9
Widzimy, że po utworzeniu kolejki wątki przyjęły zadania do wykonania. Możesz też sprawdzić jak będzie się zachowywał rozkład pomiędzy wątkami z puli dla 20 zadań na 10 wątków.
Żądanie przetworzonego użytkownika nr 7 w wątku ForkJoinPool-1-pracownik-8 Żądanie
przetworzonego użytkownika nr 2 w wątku ForkJoinPool-1-worker-3 Żądanie
przetworzonego użytkownika nr 4 w wątku ForkJoinPool -1-pracownik-5
Przetworzone żądanie od użytkownika nr 1 w wątku ForkJoinPool-1-pracownik-2
Przetworzone żądanie od użytkownika nr 5 w wątku ForkJoinPool-1-pracownik-6
Przetworzone żądanie od użytkownika nr 8 w wątku ForkJoinPool-1 -worker-9
Przetworzone żądanie użytkownika #9 w wątku ForkJoinPool-1-worker-10
Przetworzone żądanie użytkownika #0 w wątku ForkJoinPool-1-worker-1
Przetworzone żądanie użytkownika #6 w wątku ForkJoinPool-1-worker-7
Żądanie użytkownika nr 10 przetworzone w wątku ForkJoinPool-1-worker-9
Żądanie użytkownika nr 12 przetworzone w wątku ForkJoinPool-1-pracownik-1
Żądanie użytkownika nr 13 przetworzone w wątku ForkJoinPool-1-worker-8 Żądanie
użytkownika nr 11 przetworzone w wątku ForkJoinPool -1-pracownik-6
Przetworzone żądanie od użytkownika nr 15 w strumieniu ForkJoinPool-1-pracownik-8
Przetworzone żądanie od użytkownika nr 14 w strumieniu ForkJoinPool-1-pracownik-1
Przetworzone żądanie od użytkownika nr 17 w strumieniu ForkJoinPool-1 -worker-6
Przetworzone żądanie użytkownika nr 16 w wątku ForkJoinPool-1-pracownik-7
Przetworzone żądanie użytkownika nr 19 w wątku ForkJoinPool-1-pracownik-6
Przetworzone żądanie użytkownika nr 18 w wątku ForkJoinPool-1-pracownik-1
Z danych wyjściowych widać, że niektóre wątki mają czas na wykonanie kilku zadań ( ForkJoinPool-1-worker-6 wykonały 4 zadania), a niektóre tylko jedno ( ForkJoinPool-1-worker-2 ). Jeśli do implementacji metody wywołania zostanie dodane opóźnienie 1 sekundy , obraz ulegnie zmianie.
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
return null;
};Na potrzeby eksperymentu uruchommy ten sam kod na innej maszynie. Wynikowy wynik:
Żądanie przetworzonego użytkownika nr 7 na ForkJoinPool-1-worker-31
Żądanie przetworzonego użytkownika nr 4 na ForkJoinPool-1-worker-27
Żądanie przetworzonego użytkownika nr 5 na wątku ForkJoinPool -1- pracownik-13
Przetworzone żądanie od użytkownika nr 0 w strumieniu ForkJoinPool-1-pracownik-19
Przetworzone żądanie od użytkownika nr 8 w strumieniu ForkJoinPool-1-pracownik-3
Przetworzone żądanie od użytkownika nr 9 w strumieniu ForkJoinPool-1-pracownik- 21
Przetworzone żądanie użytkownika nr 6 w wątku ForkJoinPool-1-worker-17
Przetworzone żądanie użytkownika nr 3 w wątku ForkJoinPool-1-pracownik-9
Przetworzone żądanie użytkownika nr 1 w wątku ForkJoinPool-1-pracownik-5
Przetworzone żądanie od użytkownika #12 w wątku ForkJoinPool-1-worker-23
Przetworzone żądanie od użytkownika #15 w wątku ForkJoinPool-1-worker-19
Przetworzone żądanie od użytkownika #14 w wątku ForkJoinPool-1-worker-27
Przetworzone żądanie od użytkownika #11 w wątku ForkJoinPool -1-worker-3
Przetworzone żądanie od użytkownika #13 w ForkJoinPool-1-worker-13
Przetworzone żądanie od użytkownika #10 w ForkJoinPool-1-worker-31
Przetworzone żądanie od użytkownika #18 w ForkJoinPool -1-pracownik-5
Przetworzone żądanie użytkownika nr 16 w wątku ForkJoinPool-1-pracownik-9
Przetworzone żądanie użytkownika nr 17 w wątku ForkJoinPool-1-pracownik-21
Przetworzone żądanie użytkownika nr 19 w wątku ForkJoinPool-1-pracownik-17 nitka
Z ciekawego w tym wyjściu możemy zauważyć, że „uporządkowaliśmy” wątki w puli. A nazwiska robotników nie idą od jednego do dziesięciu włącznie, ale więcej. Jeśli spojrzysz na unikalne nazwy, to naprawdę jest dziesięciu pracowników (3, 5, 9, 13, 17, 19, 21, 23, 27 i 31). Powstaje uzasadnione pytanie: dlaczego tak się stało? W każdej niejasnej sytuacji użyj debugowania.
Oto, co zrobimy. Weźmy przedmiotUsługa wykonawcydo typu ForkJoinPool :final ForkJoinPool forkJoinPool = (ForkJoinPool) executorService;Przyjrzymy się temu obiektowi po wywołaniu metody invokeAll w trybie Evaluate Expression. Aby to zrobić, po metodzie invokeAll dodaj dowolne polecenie, na przykład puste sout i ustaw na nim punkt przerwania.

Widzimy, że w puli jest 10 wątków, ale tablica wątków (robotników) ma wymiar 32. Dziwne, ale dobra, kopmy dalej. Podczas tworzenia puli spróbujmy ustawić parametr równoległości na więcej niż 32, na przykład 40.
ExecutorService executorService = Executors.newWorkStealingPool(40);Podczas debugowania spójrzmy ponownie na obiektwidelec Dołącz do puli.

Teraz rozmiar tablicy pracowników wynosi 128. Możemy założyć, że jest to wewnętrzna optymalizacja JVM. Spróbujmy znaleźć to w kodzie JDK (openjdk-14):

Tak, rzeczywiście: rozmiar tablicy pracowników jest obliczany na podstawie wartości równoległości i bitowych manipulacji nią. Nie trzeba próbować dowiedzieć się, co dokładnie się tutaj dzieje. Wystarczy znać sam fakt istnienia takiej optymalizacji.
Inną cechą naszego przykładu jest użycie metody invokeAll . Warto zauważyć, że metoda invokeAll może zwrócić nam wynik, a raczej listę wyników (w naszym przypadku List<Future<Void>>) , gdzie możemy uzyskać wynik każdego z zadań.
var results = executorService.invokeAll(tasks);
for (Future<Void> result : results) {
// Process the task's result
}Ten specjalny rodzaj puli usług i wątków może być używany w zadaniach, w których poziom współbieżności jest przewidywany lub nieprzewidziany, ale dorozumiany.