우리를 위해 ExecutorService를 준비하는 newWorkStealingPool 메서드를 알아봅시다 .

이 스레드 풀은 특별합니다. 그것의 행동은 "도둑질" 작업의 아이디어를 기반으로 합니다.
작업은 대기하고 프로세서 간에 분산됩니다. 그러나 프로세서가 사용 중이면 다른 무료 프로세서가 작업을 훔쳐 실행할 수 있습니다. 이 형식은 다중 스레드 응용 프로그램에서 충돌을 줄이기 위해 Java에서 도입되었습니다. 포크/조인 프레임워크를 기반으로 합니다 .
포크/조인
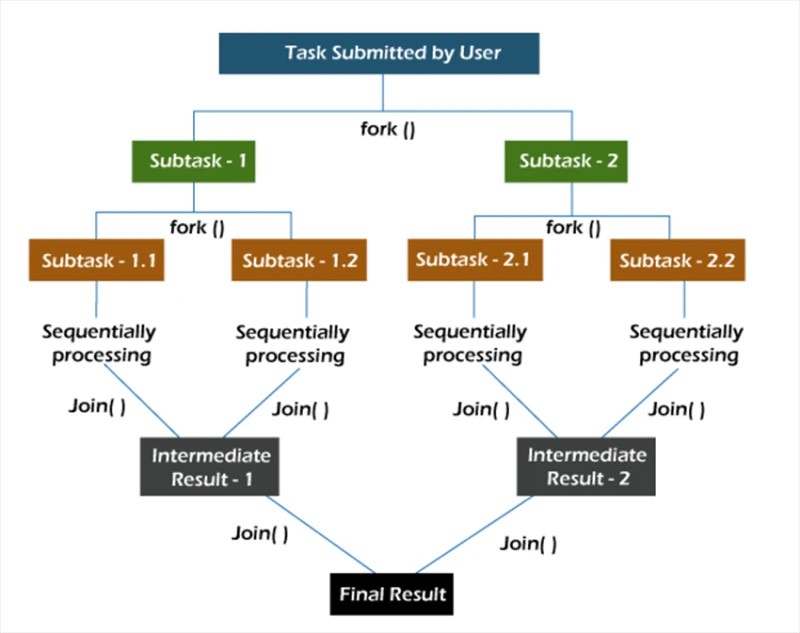
포크/조인 프레임워크 에서 작업은 재귀적으로 분해됩니다. 즉, 하위 작업으로 나뉩니다. 그런 다음 하위 작업이 개별적으로 실행되고 하위 작업의 결과가 결합되어 원래 작업의 결과를 형성합니다.
fork 메서드는 일부 스레드에서 비동기적으로 작업을 시작하고 join 메서드를 사용 하면 이 작업이 완료될 때까지 기다릴 수 있습니다.
newWorkStealingPool
newWorkStealingPool 메소드 에는 두 가지 구현이 있습니다.
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}처음부터 내부적으로는 ThreadPoolExecutor 생성자를 호출하지 않는다는 점에 유의하십시오. 여기서 우리는 ForkJoinPool 엔터티로 작업하고 있습니다. ThreadPoolExecutor 와 마찬가지로 AbstractExecutorService 의 구현입니다 .
우리는 선택할 수 있는 2가지 방법이 있습니다. 첫 번째에서 우리는 우리가 보고 싶은 병렬 처리 수준을 나타냅니다. 이 값을 지정하지 않으면 풀의 병렬 처리는 JVM(Java Virtual Machine)에서 사용할 수 있는 프로세서 코어의 수와 같습니다.

실제로 어떻게 작동하는지 파악해야 합니다.
Collection<Callable<Void>> tasks = new ArrayList<>();
ExecutorService executorService = Executors.newWorkStealingPool(10);
for (int i = 0; i < 10; i++) {
int taskNumber = i;
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
return null;
};
tasks.add(callable);
}
executorService.invokeAll(tasks);자체 완료 상태를 표시하는 10개의 작업을 생성합니다. 그런 다음 invokeAll 메서드를 사용하여 모든 작업을 시작합니다.
풀의 10개 스레드에서 10개의 작업을 실행할 때의 결과:
ForkJoinPool-1-worker-5 스레드에서
처리된 사용자 요청 #4 ForkJoinPool-1-worker-8 스레드에서 처리된 사용자 요청 #7
ForkJoinPool-에서 처리된 사용자 요청 #1 1-worker-2 스레드
ForkJoinPool-1-worker-3 스레드에서 처리된 사용자 요청 #2
ForkJoinPool-1-worker-4 스레드에서
처리된 사용자 요청 #3 ForkJoinPool-1-worker-7 스레드에서 처리된 사용자 요청 #6
처리된 사용자 ForkJoinPool-1-worker-1 스레드에서 요청 #0
ForkJoinPool-1-worker-6 스레드에서 처리된 사용자 요청 #5 ForkJoinPool-
1-worker-9 스레드에서 처리된 사용자 요청 #8
대기열이 형성된 후 스레드가 실행을 위해 작업을 수행하는 것을 볼 수 있습니다. 또한 10개의 스레드 풀에서 20개의 작업이 어떻게 분산되는지 확인할 수 있습니다.
요청 #3 ForkJoinPool-1-worker-8 스레드에서
처리된 사용자 요청 #7 ForkJoinPool-1-worker-3 스레드에서 처리된 사용자 요청 #2
ForkJoinPool-에서 처리된 사용자 요청 #4 1-worker-5 스레드
ForkJoinPool-1-worker-2 스레드에서 처리된 사용자 요청 #1
ForkJoinPool-1-worker-6 스레드에서
처리된 사용자 요청 #5 ForkJoinPool-1-worker-9 스레드에서 처리된 사용자 요청 #8
처리된 사용자 ForkJoinPool-1-worker-10 스레드에서 요청 #9
ForkJoinPool-1-worker-1 스레드에서 처리된 사용자 요청 #0
ForkJoinPool-1-worker-7 스레드에서 처리된 사용자 요청 #6
ForkJoinPool-1-에서 처리된 사용자 요청 #10 작업자-9 스레드
ForkJoinPool-1-worker-1 스레드에서 처리된 사용자 요청 #12
ForkJoinPool-1-worker-8 스레드에서
처리된 사용자 요청 #13 ForkJoinPool-1-worker-6 스레드에서 처리된 사용자 요청 #11
ForkJoinPool-에서 처리된 사용자 요청 #15 1-worker-8 스레드
ForkJoinPool-1-worker-1 스레드에서 처리된 사용자 요청 #14
ForkJoinPool-1-worker-6 스레드에서
처리된 사용자 요청 #17 ForkJoinPool-1-worker-7 스레드에서 처리된 사용자 요청 #16
처리된 사용자 ForkJoinPool-1-worker-6 스레드의 요청 #19
ForkJoinPool-1-worker-1 스레드의 처리된 사용자 요청 #18
출력에서 일부 스레드는 여러 작업( ForkJoinPool-1-worker-6 완료 4 작업 완료)을 관리하는 반면 일부 스레드는 하나만 완료( ForkJoinPool-1-worker-2 )하는 것을 볼 수 있습니다. call 메서드 구현에 1초 지연이 추가되면 그림이 바뀝니다.
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
return null;
};실험을 위해 다른 컴퓨터에서 동일한 코드를 실행해 보겠습니다. 결과 출력:
ForkJoinPool-1-worker-31 스레드에서
처리된 사용자 요청 #7 ForkJoinPool-1-worker-27 스레드에서 처리된 사용자 요청 #4
ForkJoinPool-에서 처리된 사용자 요청 #5 1-worker-13 스레드
ForkJoinPool-1-worker-19 스레드에서 처리된 사용자 요청 #0
ForkJoinPool-1-worker-3 스레드에서
처리된 사용자 요청 #8 ForkJoinPool-1-worker-21 스레드에서 처리된 사용자 요청 #9
처리된 사용자 ForkJoinPool-1-worker-17 스레드에서 요청 #6
ForkJoinPool-1-worker-9 스레드에서 처리된 사용자 요청 #3
ForkJoinPool-1-worker-5 스레드에서 처리된 사용자 요청 #1
ForkJoinPool-1-에서 처리된 사용자 요청 #12 작업자-23 스레드
ForkJoinPool-1-worker-19 스레드에서 처리된 사용자 요청 #15
ForkJoinPool-1-worker-27 스레드에서
처리된 사용자 요청 #14 ForkJoinPool-1-worker-3 스레드에서 처리된 사용자 요청 #11
ForkJoinPool-에서 처리된 사용자 요청 #13 1-worker-13 스레드
ForkJoinPool-1-worker-31 스레드에서 처리된 사용자 요청 #10
ForkJoinPool-1-worker-5 스레드에서
처리된 사용자 요청 #18 ForkJoinPool-1-worker-9 스레드에서 처리된 사용자 요청 #16
처리된 사용자 ForkJoinPool-1-worker-21 스레드의 요청 #17
ForkJoinPool-1-worker-17 스레드의 처리된 사용자 요청 #19
이 출력에서 풀의 스레드를 "요청"한 것이 주목할 만합니다. 또한 작업자 스레드의 이름은 1에서 10까지가 아니라 때때로 10보다 높습니다. 고유한 이름을 보면 실제로 10명의 일꾼이 있음을 알 수 있습니다(3, 5, 9, 13, 17, 19, 21, 23, 27 및 31). 왜 이런 일이 일어 났는지 묻는 것이 합리적입니까? 진행 상황을 이해하지 못할 때마다 디버거를 사용하십시오.
이것이 우리가 할 일입니다. 캐스팅하자집행자 서비스ForkJoinPool 에 대한 객체 :final ForkJoinPool forkJoinPool = (ForkJoinPool) executorService;invokeAll 메서드 를 호출한 후 Evaluate Expression 작업을 사용하여 이 개체를 검사합니다 . 이렇게 하려면 invokeAll 메서드 뒤에 빈 sout과 같은 문을 추가하고 중단점을 설정합니다.

풀에 10개의 스레드가 있지만 작업자 스레드 배열의 크기는 32개임을 알 수 있습니다. 이상하지만 괜찮습니다. 계속 파자. 풀을 생성할 때 병렬 처리 수준을 32 이상, 예를 들어 40으로 설정해 봅시다.
ExecutorService executorService = Executors.newWorkStealingPool(40);디버거에서 살펴보겠습니다.다시 forkJoinPool 객체.

이제 작업자 스레드 배열의 크기는 128입니다. 이것이 JVM의 내부 최적화 중 하나라고 가정할 수 있습니다. JDK(openjdk-14)의 코드에서 찾아봅시다.

예상한 대로 작업자 스레드 배열의 크기는 병렬도 값에 대해 비트 단위 조작을 수행하여 계산됩니다. 여기서 정확히 무슨 일이 일어나고 있는지 알아내려고 노력할 필요가 없습니다. 그러한 최적화가 존재한다는 사실을 아는 것만으로도 충분합니다.
우리 예제의 또 다른 흥미로운 측면은 invokeAll 메서드 의 사용입니다 . invokeAll 메서드가 결과를 반환하거나 각 작업의 결과를 찾을 수 있는 결과 목록(이 경우 List <Future<Void>>)을 반환할 수 있다는 점은 주목할 가치가 있습니다 .
var results = executorService.invokeAll(tasks);
for (Future<Void> result : results) {
// Process the task's result
}이 특별한 종류의 서비스 및 스레드 풀은 예측 가능하거나 최소한 암시적인 수준의 동시성을 가진 작업에서 사용할 수 있습니다.