Javaのコレクションとは何ですか?
Java のコレクションは、すべての要素を 1 つのユニットにグループ化するコンテナとして表されます。 たとえば、メール フォルダー (電子メールのグループ)、電話帳 (名前と電話番号のマッピング) などです。フレームワークとは何ですか?
フレームワークは、提供されているさまざまなクラスやインターフェイスを使用して作業を開始するための基本的な基盤またはレイアウトです。 たとえば、Laravel は、アプリケーションの基本的なスケルトンを提供する最も有名な PHP フレームワークの 1 つです。Java のコレクション フレームワークとは何ですか?
すべてのオブジェクトは、コレクションを操作するためのさまざまなメソッドを表現および提供するアーキテクチャとともに 1 つのオブジェクトにグループ化されます。そのため、Java のコレクション フレームワークは、データとメソッドを保存し、並べ替え、検索、削除、挿入などの機能でそれらを操作するために実装済みのさまざまなデータ構造を提供します。 たとえば、ランダムな企業向けに、先着順に基づいて顧客へのサービスを向上させるシステムを実装したいとします。これは、FIFO (先入れ先出し) 実装としても知られています。次に、このデータ構造を実装し、それを使用して目標を達成する必要があります。Collections フレームワークは Queue インターフェイスを提供します。これを実装するのではなくインポートするだけで済み、それを使用すれば完了です。 実装: 次の行を使用して、すべてのコレクションをインポートできます。import java.util.*;import java.util.LinkedList;Java のコレクション フレームワークの利点
以下のようなメリットがあります。- すでに実装されています(時間の節約)。
- パフォーマンス効率 (速度と品質)。
- 新しい API を学習して使用するための労力を軽減します。
コレクションフレームワークの階層は何ですか?
ここでコレクション階層を見てみましょう。その前に、このフレームワークの重要なコンポーネントを知る必要があります。- インターフェース
- クラス(実装)
- アルゴリズム
コレクションフレームワークの階層
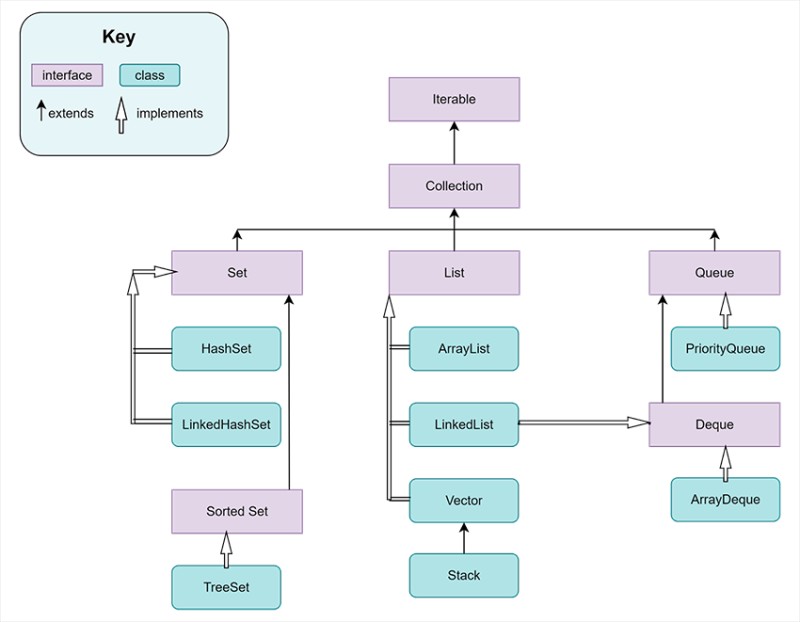 ご理解いただくために:
ご理解いただくために:
- Collection、Set、Queue、List はすべてインターフェイスです。Set、Queue、List はCollection インターフェイスによって拡張されています。
- PriorityQueue、HashSet、LinkedList、Stack はすべてクラス、またはこれらのインターフェイスの実装です。
- クラスが1 つのインターフェイスだけを実装する ことは必須ではありません。たとえば、LinkedList は Deque インターフェイスも実装します。
コレクションの種類
Java コレクション フレームワークには、労力を軽減するために多くの種類のコレクションが含まれています。以下はコレクションの一部のリストです。- ArrayList クラス
- リンクリストクラス
- リストインターフェイス
- インターフェースの設定
- キューインターフェース
- マップインターフェイス
- PriorityQueueクラス
- ハッシュマップクラス
- 同等のインターフェース
- LinkedHashMap クラス
- ツリーマップクラス
- ハッシュ表
コレクションインターフェイス
ここでは、いくつかの一般的なコレクション インターフェイスについて説明し、次にクラスによって実装されるいくつかのメソッドについて説明します。収集インターフェース
これは、実装に必要なすべてのメソッドを提供するコレクション フレームワークの基本基盤です。Map はそれを実装していない唯一のデータ構造ですが、残りはすべてそのメソッドを実装しています。このインターフェイスには、コレクションのサイズ、コレクション内にオブジェクトが存在するかどうかを確認し、コレクションにオブジェクトを追加または削除するためのメソッドがあります。反復可能なインターフェース
これは、すべてのクラスによって実装される Collection インターフェイスによって拡張されるため、Collections フレームワークのルート インターフェイスです。特定のコレクションを反復処理するためのイテレータを返します。キューインターフェース
キューは要素を保持するために使用されますが、要素を処理することはできません。基本的なコレクション操作を実装し、追加の挿入および抽出メソッドも提供します。
インターフェースの設定
Set は、一意の要素を保持するために使用されます。重複する要素は決して含まれず、数学的なセットの抽象化をモデル化して、マシン上で実行されているプロセスなどのセットを表現します。リストインターフェイス
リストは、重複した要素を保持できる順序付けされたコレクションであり、シーケンスとも呼ばれます。これにより、整数のインデックス値を使用して特定の要素を更新または削除したり、特定のポイントに要素を挿入したりするための制御がユーザーに提供されます。LinkedList と ArrayList は、List インターフェイスの実装クラスです。デキューインターフェイス
Deque は double-ended queue の略で、両端で操作を実行できることを意味します。両端から要素を挿入および削除できます。Deque インターフェイスはキュー インターフェイスを拡張します。ArrayDeque と LinkedList は両方とも Deque インターフェイスを実装します。これは、両端からインスタンスを挿入、削除、および検査するためのメソッドを提供します。マップインターフェイス
Map インターフェイスも Collections フレームワークの一部ですが、Collection インターフェイスを拡張するものではありません。キーと値のペアを保存するために使用されます。その主な実装は、HashMap、TreeMap、および LinkesHashMap であり、特定の点では HashSet、TreeSet、および LinkedHashSet に似ています。常に一意のキーが含まれていますが、値は重複する可能性があります。これは、キーに基づいて項目を追加、削除、または検索する必要がある場合に便利です。これは、 put、get、Remove、size、emptyなど の基本的なメソッドを提供します。これらのインターフェースの共通メソッド
次に、Map インターフェイスを除く、このフレームワーク内のさまざまなクラスの実装のために提供されるいくつかの一般的なメソッドを見ていきます。| メソッド | 説明 |
|---|---|
| public boolean add(E e) | コレクションに要素を挿入するために使用されます |
| public boolean delete(オブジェクト要素) | コレクションから要素を削除するために使用されます |
| public int size() | コレクション内の要素の数を返します。 |
| public boolean contains(Object 要素) | 要素の検索に使用されます |
| パブリックブール値 isEmpty() | コレクションが空かどうかを確認します |
| public booleanequals(オブジェクト要素) | 等しいかどうかをチェックします |
コレクションクラス
ご存知のとおり、フレームワークには、内部の多くのクラスによって実装されるさまざまなインターフェイスがあります。次に、一般的に使用されるクラスをいくつか見てみましょう。リンクリスト
これは、要素を内部に格納するために二重リンク リストを実装する、最も一般的に使用されるデータ構造です。重複した要素を保存できます。これは、Queue インターフェイスと List インターフェイスによって拡張された Dequeue インターフェイスを実装します。同期されていません。ここで、LinkedList を使用して、上で説明した問題 (FIFO の概念) を解決する方法を見てみましょう。問題は、顧客が到着した順、つまり先入れ先出しでサービスを提供することです。例
import java.util.*;
public class LinkedListExample {
public static void main(String[] args) {
Queue<String> customerQueue = new LinkedList<String>();
//Adding customers to the Queue as they arrived
customerQueue.add("John");
customerQueue.add("Angelina");
customerQueue.add("Brooke");
customerQueue.add("Maxwell");
System.out.println("Customers in Queue:"+customerQueue);
//element() => returns head of the queue
//we will see our first customer and serve him
System.out.println("Head of the queue i.e first customer: "+customerQueue.element());
//remove () method =>removes first element(customer) from the queue i.e the customer is served so remove him to see next
System.out.println("Element removed from the queue: "+customerQueue.remove());
//poll () => removes and returns the head
System.out.println("Poll():Returned Head of the queue: "+customerQueue.poll());
//print the remaining customers in the Queue
System.out.println("Final Queue:"+customerQueue);
}
}出力
キュー内の顧客:[John、Angelina、Brooke、Maxwell] キューの先頭、つまり最初の顧客: John キューから削除された要素: John Poll():Returned キューの先頭: Angelina 最終キュー:[Brooke、Maxwell]
配列リスト
これは単に List インターフェイスを実装するだけです。挿入順序を維持し、動的配列を使用してさまざまなデータ型の要素を格納します。要素は複製できます。また、非同期であり、NULL 値を格納できます。次に、そのさまざまなメソッドを見てみましょう... これらは、挿入する必要があるレコードまたは要素の数がわからない場合に便利です。何冊の本を保管しなければならないかわからない図書館の例を考えてみましょう。したがって、本があるときは必ず、それを ArrayList に挿入する必要があります。例
public class ArrayListExample {
public static void main(String args[]) {
// Creating the ArrayList
ArrayList<String> books = new ArrayList<String>();
// Adding a book to the list
books.add("Absalom, Absalom!");
// Adding a book in array list
books.add("A Time to Kill");
// Adding a book to the list
books.add("The House of Mirth");
// Adding a book to the list
books.add("East of Eden");
// Traversing the list through Iterator
Iterator<String> itr = books.iterator();
while (itr.hasNext()) {
System.out.println(itr.next());
}
}
}出力
アブサロム、アブサロム!エデンの東の歓喜の家
ハッシュセット
Set インターフェイスを実装しており、重複する値が含まれることはありません。値を保存するためのハッシュ テーブルを実装します。Null 値も許可されます。挿入順序は決して維持されませんが、 add、replace、size、およびcontainsメソッドに対して一定時間のパフォーマンスを提供します。検索操作に最適ですが、同期されません。例
import java.util.*;
class HashSetExample{
public static void main(String args[]){
//creating HashSet and adding elements to it
HashSet<Integer> hashSet=new HashSet();
hashSet.add(1);
hashSet.add(5);
hashSet.add(4);
hashSet.add(3);
hashSet.add(2);
//getting an iterator for the collection
Iterator<Integer> i=hashSet.iterator();
//iterating over the value
while(i.hasNext()) {
System.out.println(i.next());
}
}
}出力
1 2 3 4 5
ご覧のとおり、挿入順序は維持されません。
ArrayDeque
Deque インターフェイスを実装しているため、両端からの操作が可能です。Null 値は許可されません。Stack および LinkedList として実装すると、Stack および LinkedList よりも高速になります。ArrayDeque には、要件に応じて拡大または縮小できるため、サイズ制限はありません。非同期であるため、スレッドセーフではありません。スレッドセーフを維持するには、いくつかの外部ロジックを実装する必要があります。例
import java.util.*;
public class ArrayDequeExample {
public static void main(String[] args) {
//creating Deque and adding elements
Deque<String> deque = new ArrayDeque<String>();
//adding an element
deque.add("One");
//adding an element at the start
deque.addFirst("Two");
//adding an element at the end
deque.addLast("Three");
//traversing elements of the collection
for (String str : deque) {
System.out.println(str);
}
}
}出力
ツー・ワン・スリー
ハッシュマップ
これは、ハッシュ テーブルに基づいた Map インターフェイスの実装です。キーと値のペアが保存されます。Null 値は許可されません。同期されていません。掲載順序を保証するものではありません。getやputなどのメソッドに一定時間のパフォーマンスを提供します。そのパフォーマンスは、初期容量と負荷率という2 つの要素によって決まります。容量はハッシュ テーブル内のバケットの数であるため、初期容量は作成時に割り当てられたバケットの数になります。負荷率は、容量が増加する前にハッシュ テーブルにどれだけのデータを取り込むことができるかを示す尺度です。リハッシュ方式は容量を増やすために使用され、主にバケットの数を 2 倍にします。例
import java.util.*;
public class HashMapExample{
public static void main(String args[]){
//creating a HashMap
HashMap<Integer,String> map=new HashMap<Integer,String>();
//putting elements into the map
map.put(1,"England");
map.put(2,"USA");
map.put(3,"China");
//get element at index 2
System.out.println("Value at index 2 is: "+map.get(2));
System.out.println("iterating map");
//iterating the map
for(Map.Entry m : map.entrySet()){
System.out.println(m.getKey()+" "+m.getValue());
}
}
}
出力
インデックス 2 の値は次のとおりです: 中国反復マップ 1 イングランド 2 米国 3 中国
アルゴリズム
コレクション フレームワークは、コレクションに適用するさまざまな操作のためのさまざまなアルゴリズムを提供します。ここでは、これらのアルゴリズムでどの主要な操作がカバーされているかを見ていきます。以下に関連するアルゴリズムが含まれています。- 仕分け
- 検索中
- シャッフリング
- 日常的なデータ操作
- 構成
- 極値を見つける
仕分け
ソートアルゴリズムは、順序関係に従ってリストを並べ替えます。2 つの形式の関係が提供されます。- 自然な順序付け
- 比較注文
自然な順序付け
自然順序付けでは、リストはその要素に従ってソートされます。比較注文
この形式の順序付けでは、コンパレータである追加パラメータがリストとともに渡されます。ソートには、わずかに最適化されたマージ ソート アルゴリズムが使用されます。これは、n log(n) の実行時間を保証し、等しい要素を並べ替えないため、高速かつ安定しています。ArrayList の同じ例を使用して並べ替えを示します。例
import java.util.*;
public class SortingExample{
public static void main(String args[]){
//Creating arraylist
ArrayList<String> books=new ArrayList<String>();
//Adding a book to the arraylist
books.add("A Time to Kill");
//Adding a book to the arraylist
books.add("Absalom, Absalom!");
//Adding a book to the arraylist
books.add("The House of Mirth");
//Adding a book to the arraylist
books.add("East of Eden");
//Traversing list through Iterator before sorting
Iterator itrBeforeSort=books.iterator();
while(itrBeforeSort.hasNext()){
System.out.println(itrBeforeSort.next());
}
//sorting the books
Collections.sort(books);
System.out.println("After sorting the books");
//Traversing list through Iterator after sorting
Iterator itr=books.iterator();
while(itr.hasNext()){
System.out.println(itr.next());
}
}
}出力
アブサロムを殺す時が来た、アブサロム!エデンの東の歓喜の家 本を整理した後 アブサロムを殺す時が来た、アブサロム!エデンの東 歓喜の家
GO TO FULL VERSION