"हाय, अमीगो!"
"अब यह एक और दिलचस्प विषय के लिए समय है: एनकोडिंग।"
"शायद आपने पहले ही कहीं सुना होगा कि प्रत्येक वर्ण का एक कोड (संख्या) होता है। इसीलिए char प्रकार प्रतीकों और संख्याओं दोनों का प्रतिनिधित्व कर सकता है।"
"उदाहरण के लिए, अंग्रेजी वर्णमाला में 'ए' अक्षर के लिए कोड 65 है। 'बी' 66 है, 'सी' 67 है, और इसी तरह। अपरकेस अक्षरों, लोअरकेस अक्षरों, सिरिलिक अक्षरों, चीनी के लिए अद्वितीय कोड हैं। अक्षर (हाँ, बहुत सारे और बहुत सारे कोड), संख्याएँ, और विभिन्न प्रतीक। संक्षेप में, व्यावहारिक रूप से हर उस चीज़ के लिए एक कोड होता है जिसे आप एक चरित्र कहते हैं।
"तो, हर अक्षर और वर्ण किसी न किसी संख्या से मेल खाता है?"
"एकदम सही।"
"एक वर्ण को एक संख्या में और एक संख्या को एक वर्ण में बदला जा सकता है। जावा आमतौर पर उनके बीच कोई अंतर नहीं देखता है:"
char c = 'A'; //The code (number) for 'A' is 65
c++; //Now c contains the number 66, which is the code for 'B'"दिलचस्प।"
"तो, एक एन्कोडिंग प्रतीकों का एक सेट है और उनके संबंधित कोड का सेट है। लेकिन केवल एक एन्कोडिंग का आविष्कार नहीं किया गया है - बहुत कुछ हैं। बाद में यह तब तक नहीं था जब तक कि एक सामान्य सार्वभौमिक एन्कोडिंग, यूनिकोड का आविष्कार नहीं किया गया था।"

"लेकिन कोई फर्क नहीं पड़ता कि कितने सार्वभौमिक मानकों का आविष्कार किया गया है, कोई भी पुराने को छोड़ने की जल्दी में नहीं है। और फिर इस कार्टून की तरह ही सब कुछ होता है:"
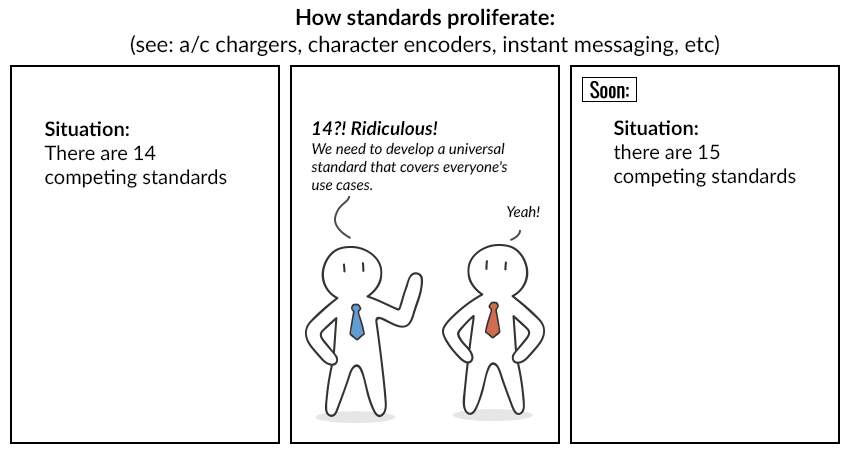
"कल्पना कीजिए कि विन्सेंट और निक अपने स्वयं के एन्कोडिंग बनाने का निर्णय लेते हैं।"
"यहाँ विन्सेंट की एन्कोडिंग है:"
"और यहाँ निक का एन्कोडिंग है:"
"वे समान वर्णों का उपयोग भी करते हैं, लेकिन वर्णों के लिए कोड भिन्न होते हैं।"
"जब विन्सेंट के एन्कोडिंग का उपयोग कर स्ट्रिंग 'एबीसी -123' फ़ाइल में लिखा जाता है, तो हमें बाइट्स का निम्नलिखित सेट मिलता है:"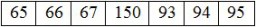
"और अब निक के एन्कोडिंग का उपयोग करने वाला एक अन्य प्रोग्राम फ़ाइल को पढ़ना चाहता है:"
"यहाँ वह है जो इसे पढ़ेगा: «345-IJK»।"
"और सबसे बुरी बात यह है कि एन्कोडिंग आमतौर पर फ़ाइलों में कहीं भी संग्रहीत नहीं होती हैं, इसलिए डेवलपर्स को अनुमान लगाना पड़ता है।"
"अच्छा, वे उनका अनुमान कैसे लगाते हैं?"
"यह एक अलग विषय है। लेकिन मैं समझाना चाहता हूं कि एन्कोडिंग के साथ कैसे काम करना है। जैसा कि आप पहले से ही जानते हैं, जावा में एक चार का आकार दो बाइट्स है। और जावा स्ट्रिंग्स यूनिकोड प्रारूप का उपयोग करते हैं।"
"लेकिन जावा आपको किसी भी एन्कोडिंग में एक स्ट्रिंग को बाइट्स के एक सेट में बदलने देता है जिसे वह जानता है। स्ट्रिंग वर्ग के पास इसके लिए विशेष तरीके हैं। जावा में एक विशेष वर्णसेट वर्ग भी है जो एक विशिष्ट एन्कोडिंग का वर्णन करता है।"
1) मैं जावा द्वारा समर्थित सभी एनकोडिंग की सूची कैसे प्राप्त करूं?
"इसके लिए एक विशेष स्टैटिक मेथड है जिसे अवेलेबल चारसेट्स कहा जाता है।" यह मेथड जोड़े का एक सेट लौटाता है (एन्कोडिंग नाम, ऑब्जेक्ट जो एन्कोडिंग का वर्णन करता है): "
SortedMap<String,Charset> charsets = Charset.availableCharsets();"प्रत्येक एन्कोडिंग का एक अनूठा नाम है। यहाँ उनमें से कुछ हैं: UTF-8, UTF-16, Windows-1251, KOI8-R,…"
2) मैं वर्तमान सक्रिय एन्कोडिंग (यूनिकोड) कैसे प्राप्त करूं?
" उसके लिए एक विशेष विधि है जिसे डिफॉल्ट चारसेट कहा जाता है।
Charset currentCharset = Charset.defaultCharset();3) मैं एक स्ट्रिंग को एक विशिष्ट एन्कोडिंग में कैसे परिवर्तित करूं?
"जावा में, आप किसी भी एन्कोडिंग में स्ट्रिंग को बाइट सरणी में परिवर्तित कर सकते हैं जिसे जावा जानता है:"
| तरीका | उदाहरण |
|---|---|
|
|
|
|
|
|
4) मैं एक बाइट सरणी को कैसे परिवर्तित कर सकता हूं जिसे मैंने फ़ाइल से स्ट्रिंग में पढ़ा है, अगर मुझे पता है कि फ़ाइल में इसका एन्कोडिंग क्या था?
"यह और भी आसान है। स्ट्रिंग क्लास में एक विशेष कन्स्ट्रक्टर है:"
| तरीका | उदाहरण |
|---|---|
|
|
|
|
|
|
5) मैं एक बाइट सरणी को एक एन्कोडिंग से दूसरे में कैसे परिवर्तित करूं?
"कई तरीके हैं। यहाँ सबसे सरल में से एक है:"
Charset koi8 = Charset.forName("KOI8-R");
Charset windows1251 = Charset.forName("Windows-1251");
byte[] buffer = new byte[1000];
inputStream.read(buffer);
String s = new String(buffer, koi8);
buffer = s.getBytes(windows1251);
outputStream.write(buffer);"मैंने यही सोचा। दिलचस्प पाठ के लिए धन्यवाद, ऋषि।"
GO TO FULL VERSION