"Ciao, Amico!"
"Ora è il momento di un altro argomento interessante: le codifiche."
"Forse hai già sentito da qualche parte che ogni carattere ha un codice (numero). Ecco perché il tipo di carattere può rappresentare sia simboli che numeri."
"Ad esempio, il codice per la lettera 'A' nell'alfabeto inglese è 65. 'B' è 66, 'C' è 67 e così via. Esistono codici univoci per lettere maiuscole, lettere minuscole, lettere cirilliche, caratteri cinesi caratteri (sì, un sacco di codici), numeri e vari simboli. In breve, c'è un codice praticamente per tutto ciò che chiameresti carattere."
"Quindi, ogni lettera e carattere corrisponde a un numero?"
"Precisamente."
"Un carattere può essere convertito in un numero e un numero in un carattere. Java generalmente non vede alcuna differenza tra loro:"
char c = 'A'; //The code (number) for 'A' is 65
c++; //Now c contains the number 66, which is the code for 'B'"Interessante."

"Quindi, una codifica è un insieme di simboli e il corrispondente insieme di codici. Ma non è stata inventata solo una codifica, ce ne sono parecchie. Solo più tardi è stata inventata una codifica universale comune, Unicode."
"Ma non importa quanti standard universali vengano inventati, nessuno ha fretta di abbandonare quelli vecchi. E poi tutto accade proprio come in questo cartone animato:"
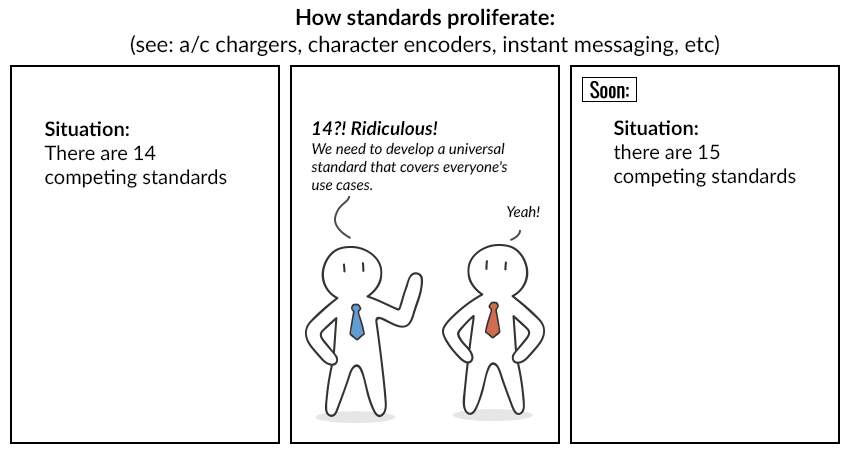
"Immagina che Vincent e Nick decidano di creare le proprie codifiche."
"Ecco la codifica di Vincent:"
"Ed ecco la codifica di Nick:"
"Usano persino gli stessi caratteri, ma i codici per i caratteri sono diversi."
"Quando la stringa 'ABC-123' viene scritta in un file utilizzando la codifica di Vincent, otteniamo il seguente set di byte:"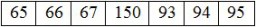
"E ora un altro programma che usa la codifica di Nick vuole leggere il file:"
"Ecco cosa si leggerà: «345-IJK»."
"E la cosa peggiore è che le codifiche in genere non sono memorizzate da nessuna parte nei file, quindi gli sviluppatori devono indovinare."
"Beh, come fanno a indovinarli?"
"Questo è un argomento diverso. Ma voglio spiegare come lavorare con le codifiche. Come già sai, la dimensione di un carattere in Java è di due byte. E le stringhe Java usano il formato Unicode."
"Ma Java ti consente di convertire una stringa in un insieme di byte in qualsiasi codifica che conosce. La classe String ha metodi speciali per questo. Java ha anche una speciale classe Charset che descrive una codifica specifica."
1) Come posso ottenere un elenco di tutte le codifiche supportate da Java?
"Esiste un metodo statico speciale chiamato availableCharsets per questo. "Questo metodo restituisce un insieme di coppie (nome di codifica, oggetto che descrive la codifica):"
SortedMap<String,Charset> charsets = Charset.availableCharsets();"Ogni codifica ha un nome univoco. Eccone alcune: UTF-8, UTF-16, Windows-1251, KOI8-R,..."
2) Come ottengo la codifica attiva corrente (Unicode)?
"Esiste un metodo speciale chiamato defaultCharset per questo.
Charset currentCharset = Charset.defaultCharset();3) Come posso convertire una stringa in una codifica specifica?
"In Java, puoi convertire una stringa in un array di byte in qualsiasi codifica che Java conosce:"
| Metodo | Esempio |
|---|---|
|
|
|
|
|
|
4) Come posso convertire un array di byte che ho letto da un file in una stringa, se so qual era la sua codifica nel file?
"Questo è ancora più semplice. La classe String ha un costruttore speciale:"
| Metodo | Esempio |
|---|---|
|
|
|
|
|
|
5) Come posso convertire un array di byte da una codifica a un'altra?
"Ci sono molti modi. Ecco uno dei più semplici:"
Charset koi8 = Charset.forName("KOI8-R");
Charset windows1251 = Charset.forName("Windows-1251");
byte[] buffer = new byte[1000];
inputStream.read(buffer);
String s = new String(buffer, koi8);
buffer = s.getBytes(windows1251);
outputStream.write(buffer);"È quello che pensavo. Grazie per l'interessante lezione, Rishi."
GO TO FULL VERSION