"Hai, Amigo!"
"Sekarang saatnya untuk topik menarik lainnya: penyandian."
"Mungkin Anda pernah mendengar di suatu tempat bahwa setiap karakter memiliki kode (angka). Itu sebabnya tipe karakter dapat mewakili simbol dan angka."
“Misalnya kode huruf ‘A’ pada abjad Inggris adalah 65. ‘B’ adalah 66, ‘C’ adalah 67, dan seterusnya. Ada kode unik untuk huruf besar, huruf kecil, huruf Cyrillic, huruf Cina karakter (ya, banyak sekali kode), angka, dan berbagai simbol. Singkatnya, ada kode untuk hampir semua hal yang Anda sebut karakter."
"Jadi, setiap huruf dan karakter berhubungan dengan angka tertentu?"
"Dengan tepat."
"Karakter dapat diubah menjadi angka, dan angka menjadi karakter. Java umumnya tidak melihat perbedaan di antara keduanya:"
char c = 'A'; //The code (number) for 'A' is 65
c++; //Now c contains the number 66, which is the code for 'B'"Menarik."
"Jadi, pengkodean adalah sekumpulan simbol dan kumpulan kode yang sesuai. Tetapi tidak hanya satu pengkodean yang ditemukan—ada beberapa. Baru kemudian pengkodean universal yang umum, Unicode, ditemukan."

"Tapi tidak peduli berapa banyak standar universal yang ditemukan, tidak ada yang terburu-buru untuk meninggalkan yang lama. Dan kemudian semuanya terjadi seperti di kartun ini:"
"Bayangkan Vincent dan Nick memutuskan untuk membuat penyandian sendiri."
"Ini penyandian Vincent:"
"Dan inilah penyandian Nick:"
"Mereka bahkan menggunakan karakter yang sama, tetapi kode untuk karakternya berbeda."
"Ketika string 'ABC-123' ditulis ke file menggunakan pengkodean Vincent, kami mendapatkan kumpulan byte berikut:"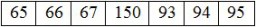
"Dan sekarang program lain yang menggunakan penyandian Nick ingin membaca file tersebut:"
"Ini yang akan terbaca: «345-IJK»."
"Dan yang terburuk adalah pengkodean biasanya tidak disimpan di mana pun dalam file, jadi pengembang harus menebak."
"Yah, bagaimana mereka menebaknya?"
"Itu topik yang berbeda. Tapi saya ingin menjelaskan cara bekerja dengan pengkodean. Seperti yang sudah Anda ketahui, ukuran char di Java adalah dua byte. Dan Java Strings menggunakan format Unicode."
"Tapi Java memungkinkan Anda mengonversi sebuah String menjadi satu set byte dalam pengkodean apa pun yang diketahuinya. Kelas String memiliki metode khusus untuk ini. Java juga memiliki kelas Charset khusus yang menjelaskan pengkodean tertentu."
1) Bagaimana cara mendapatkan daftar semua pengkodean yang didukung Java?
"Ada metode statis khusus yang disebut availableCharsets untuk itu. "Metode ini mengembalikan sekumpulan pasangan (nama penyandian, objek yang menjelaskan penyandian):"
SortedMap<String,Charset> charsets = Charset.availableCharsets();"Setiap penyandian memiliki nama yang unik. Berikut adalah beberapa di antaranya: UTF-8, UTF-16, Windows-1251, KOI8-R,…"
2) Bagaimana cara mendapatkan pengkodean aktif saat ini (Unicode)?
"Ada metode khusus yang disebut defaultCharset untuk itu.
Charset currentCharset = Charset.defaultCharset();3) Bagaimana cara mengonversi String ke pengkodean tertentu?
"Di Java, Anda dapat mengonversi String menjadi array byte dalam pengkodean apa pun yang diketahui Java:"
| metode | Contoh |
|---|---|
|
|
|
|
|
|
4) Bagaimana cara mengonversi array byte yang saya baca dari file ke String, jika saya tahu apa pengkodeannya di dalam file?
"Ini bahkan lebih mudah. Kelas String memiliki konstruktor khusus:"
| metode | Contoh |
|---|---|
|
|
|
|
|
|
5) Bagaimana cara mengonversi array byte dari satu pengkodean ke pengkodean lainnya?
"Ada banyak cara. Ini salah satu yang paling sederhana:"
Charset koi8 = Charset.forName("KOI8-R");
Charset windows1251 = Charset.forName("Windows-1251");
byte[] buffer = new byte[1000];
inputStream.read(buffer);
String s = new String(buffer, koi8);
buffer = s.getBytes(windows1251);
outputStream.write(buffer);"Itu yang kupikirkan. Terima kasih atas pelajaran menariknya, Rishi."
GO TO FULL VERSION