"Merhaba, Amigo!"
"Şimdi başka bir ilginç konunun zamanı geldi: kodlamalar."
"Belki bir yerlerde her karakterin bir kodu (sayı) olduğunu duymuşsundur. Bu yüzden karakter türü hem sembolleri hem de sayıları temsil edebilir."
"Örneğin İngiliz alfabesindeki 'A' harfinin kodu 65'tir. 'B' 66'dır, 'C' 67'dir vs. Büyük harfler, küçük harfler, Kiril harfleri, Çin harfleri için benzersiz kodlar vardır. karakterler (evet, bir sürü kod), sayılar ve çeşitli semboller.Kısacası, karakter diyebileceğiniz neredeyse her şey için bir kod var."
"Yani, her harf ve karakter bir sayıya mı karşılık geliyor?"
"Açık olarak."
"Bir karakter bir sayıya ve bir sayı da bir karaktere dönüştürülebilir. Java genellikle aralarında bir fark görmez:"
char c = 'A'; //The code (number) for 'A' is 65
c++; //Now c contains the number 66, which is the code for 'B'"İlginç."
"Dolayısıyla, bir kodlama, bir dizi sembol ve bunlara karşılık gelen kodlar kümesidir. Ancak yalnızca bir kodlama icat edilmedi - epeyce var. Ortak bir evrensel kodlama olan Unicode daha sonra icat edildi."

"Ama ne kadar evrensel standart icat edilirse edilsin, kimse eskileri terk etmek için acele etmiyor. Ve sonra her şey tıpkı bu çizgi filmdeki gibi oluyor:"
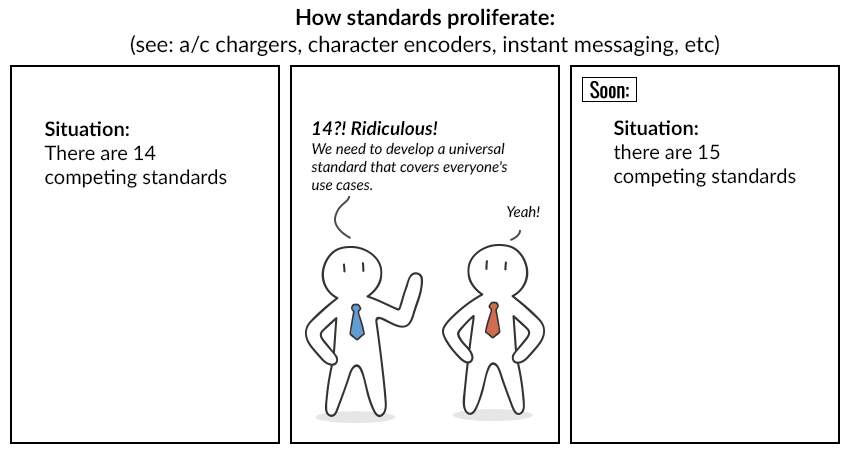
"Vincent ve Nick'in kendi kodlamalarını yapmaya karar verdiklerini hayal edin."
"İşte Vincent'ın kodlaması:"
"Ve işte Nick'in kodlaması:"
"Aynı karakterleri bile kullanıyorlar ama karakterlerin kodları farklı."
"'ABC-123' dizisi, Vincent'ın kodlaması kullanılarak bir dosyaya yazıldığında, aşağıdaki bayt kümesini elde ederiz:"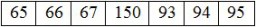
"Ve şimdi Nick'in kodlamasını kullanan başka bir program dosyayı okumak istiyor:"
"İşte okuyacağı şey: «345-IJK»."
"Ve en kötüsü, kodlamaların tipik olarak dosyalarda hiçbir yerde saklanmaması, bu nedenle geliştiricilerin tahmin etmesi gerekiyor."
"Peki, onları nasıl tahmin ediyorlar?"
"Bu farklı bir konu. Ama ben kodlamalarla nasıl çalışılacağını açıklamak istiyorum. Bildiğiniz gibi, Java'da bir karakterin boyutu iki bayttır. Java Dizgileri de Unicode biçimini kullanır."
"Ancak Java, bildiği herhangi bir kodlamada bir String'i bir bayt kümesine dönüştürmenize izin verir. String sınıfının bunun için özel yöntemleri vardır. Java'nın ayrıca belirli bir kodlamayı tanımlayan özel bir Charset sınıfı vardır."
1) Java'nın desteklediği tüm kodlamaların bir listesini nasıl alabilirim?
"Bunun için availableCharsets adında özel bir statik yöntem var. "Bu yöntem bir dizi çift döndürür (kodlama adı, kodlamayı açıklayan nesne):"
SortedMap<String,Charset> charsets = Charset.availableCharsets();"Her kodlamanın benzersiz bir adı vardır. İşte bunlardan bazıları: UTF-8, UTF-16, Windows-1251, KOI8-R,..."
2) Geçerli aktif kodlamayı (Unicode) nasıl edinebilirim?
" Bunun için defaultCharset adlı özel bir yöntem var .
Charset currentCharset = Charset.defaultCharset();3) Bir String'i belirli bir kodlamaya nasıl dönüştürebilirim?
"Java'da, Java'nın bildiği herhangi bir kodlamada bir String'i bayt dizisine dönüştürebilirsiniz:"
| Yöntem | Örnek |
|---|---|
|
|
|
|
|
|
4) Dosyada kodlamasının ne olduğunu biliyorsam, bir dosyadan okuduğum bir bayt dizisini bir String'e nasıl dönüştürebilirim?
"Bu daha da kolay. String sınıfının özel bir yapıcısı var:"
| Yöntem | Örnek |
|---|---|
|
|
|
|
|
|
5) Bir bayt dizisini bir kodlamadan diğerine nasıl dönüştürebilirim?
"Pek çok yol var. İşte en basitlerinden biri:"
Charset koi8 = Charset.forName("KOI8-R");
Charset windows1251 = Charset.forName("Windows-1251");
byte[] buffer = new byte[1000];
inputStream.read(buffer);
String s = new String(buffer, koi8);
buffer = s.getBytes(windows1251);
outputStream.write(buffer);"Ben de öyle düşünmüştüm. İlginç ders için teşekkürler, Rishi."
GO TO FULL VERSION