"Bună, Amigo!"
„Acum este timpul pentru un alt subiect interesant: codificări”.
"Poate că ați auzit deja undeva că fiecare caracter are un cod (număr). De aceea tipul de caracter poate reprezenta atât simboluri, cât și numere."
„De exemplu, codul pentru litera „A” din alfabetul englez este 65. „B” este 66, „C” este 67 și așa mai departe. Există coduri unice pentru litere mari, litere mici, litere chirilice, chineză caractere (da, o mulțime de coduri), numere și diferite simboluri. Pe scurt, există un cod pentru practic tot ceea ce ai numi personaj."
— Deci, fiecare literă și caracter corespunde unui număr?
"Exact."
„Un caracter poate fi convertit într-un număr, iar un număr într-un caracter. Java, în general, nu vede o diferență între ele:”
char c = 'A'; //The code (number) for 'A' is 65
c++; //Now c contains the number 66, which is the code for 'B'"Interesant."
„Deci, o codificare este un set de simboluri și setul corespunzător de coduri ale acestora. Dar nu a fost inventată o singură codificare – sunt destul de multe. Abia mai târziu a fost inventată o codificare universală comună, Unicode”.

"Dar oricâte standarde universale sunt inventate, nimeni nu se grăbește să le abandoneze pe cele vechi. Și apoi totul se întâmplă la fel ca în acest desen animat:"
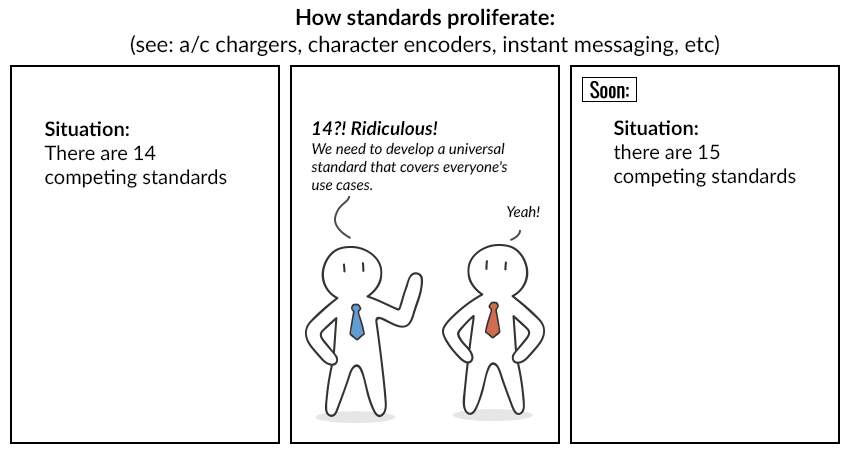
„Imaginați-vă că Vincent și Nick decid să-și facă propriile codificări”.
„Iată codarea lui Vincent:”
„Și iată codarea lui Nick:”
„Chiar folosesc aceleași caractere, dar codurile pentru personaje sunt diferite”.
„Când șirul „ABC-123” este scris într-un fișier folosind codarea lui Vincent, obținem următorul set de octeți:”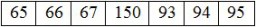
„Și acum un alt program care folosește codarea lui Nick vrea să citească fișierul:”
„Iată ce se va citi: «345-IJK».”
„Și cel mai rău lucru este că, de obicei, codificările nu sunt stocate nicăieri în fișiere, așa că dezvoltatorii trebuie să ghicească.”
— Ei, cum le ghicesc?
"Acesta este un subiect diferit. Dar vreau să explic cum să lucrez cu codificări. După cum știți deja, dimensiunea unui caracter în Java este de doi octeți. Și Java Strings utilizează formatul Unicode."
"Dar Java vă permite să convertiți un String într-un set de octeți în orice codificare pe care o cunoaște. Clasa String are metode speciale pentru aceasta. Java are și o clasă specială Charset care descrie o anumită codificare."
1) Cum obțin o listă cu toate codificările suportate de Java?
„Există o metodă statică specială numită availableCharsets pentru asta. „Această metodă returnează un set de perechi (nume codificare, obiect care descrie codificarea):”
SortedMap<String,Charset> charsets = Charset.availableCharsets();„Fiecare codificare are un nume unic. Iată câteva dintre ele: UTF-8, UTF-16, Windows-1251, KOI8-R,…”
2) Cum obțin codificarea activă curentă (Unicode)?
„Există o metodă specială numită defaultCharset pentru asta.
Charset currentCharset = Charset.defaultCharset();3) Cum convertesc un șir într-o anumită codificare?
„În Java, puteți converti un șir într-o matrice de octeți în orice codificare pe care o cunoaște Java:”
| Metodă | Exemplu |
|---|---|
|
|
|
|
|
|
4) Cum pot converti o matrice de octeți pe care am citit-o dintr-un fișier într-un șir, dacă știu ce codificare a fost în fișier?
„Acest lucru este și mai ușor. Clasa String are un constructor special:”
| Metodă | Exemplu |
|---|---|
|
|
|
|
|
|
5) Cum convertesc o matrice de octeți de la o codificare la alta?
"Există multe moduri. Iată una dintre cele mai simple:"
Charset koi8 = Charset.forName("KOI8-R");
Charset windows1251 = Charset.forName("Windows-1251");
byte[] buffer = new byte[1000];
inputStream.read(buffer);
String s = new String(buffer, koi8);
buffer = s.getBytes(windows1251);
outputStream.write(buffer);"Asta am crezut. Mulțumesc pentru lecția interesantă, Rishi."
GO TO FULL VERSION