Invece di un'introduzione
Ciao! Oggi parleremo di un sistema di controllo della versione, ovvero Git. Non hai niente a che fare con la programmazione se non conosci/capisci Git. Ma il bello è che non devi tenere in testa tutti i comandi e le funzionalità di Git per essere impiegato continuamente. Devi conoscere una serie di comandi che ti aiuteranno a capire tutto ciò che sta accadendo.
Non hai niente a che fare con la programmazione se non conosci/capisci Git. Ma il bello è che non devi tenere in testa tutti i comandi e le funzionalità di Git per essere impiegato continuamente. Devi conoscere una serie di comandi che ti aiuteranno a capire tutto ciò che sta accadendo.
Nozioni di base su Git
Git è un sistema di controllo della versione distribuito per il nostro codice. Perchè ne abbiamo bisogno? I team distribuiti hanno bisogno di un qualche tipo di sistema per gestire il proprio lavoro. È necessario per tenere traccia dei cambiamenti che si verificano nel tempo. Cioè, dobbiamo essere in grado di vedere passo dopo passo quali file sono cambiati e come. Ciò è particolarmente importante quando si esamina cosa è cambiato nel contesto di una singola attività, rendendo possibile annullare le modifiche.Installazione di Git
Installiamo Java sul tuo computer.Installazione su Windows
Come al solito, devi scaricare ed eseguire un file exe. Qui è tutto semplice: fai clic sul primo link di Google , esegui l'installazione e il gioco è fatto. Per fare ciò, utilizzeremo la console bash fornita da Windows. Su Windows, devi eseguire Git Bash. Ecco come appare nel menu Start: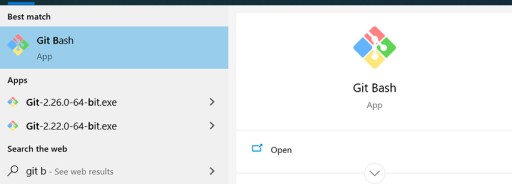 Ora questo è un prompt dei comandi con cui puoi lavorare. Per evitare di dover andare ogni volta nella cartella con il progetto per aprire Git lì, puoi aprire il prompt dei comandi nella cartella del progetto con il tasto destro del mouse con il percorso di cui abbiamo bisogno:
Ora questo è un prompt dei comandi con cui puoi lavorare. Per evitare di dover andare ogni volta nella cartella con il progetto per aprire Git lì, puoi aprire il prompt dei comandi nella cartella del progetto con il tasto destro del mouse con il percorso di cui abbiamo bisogno: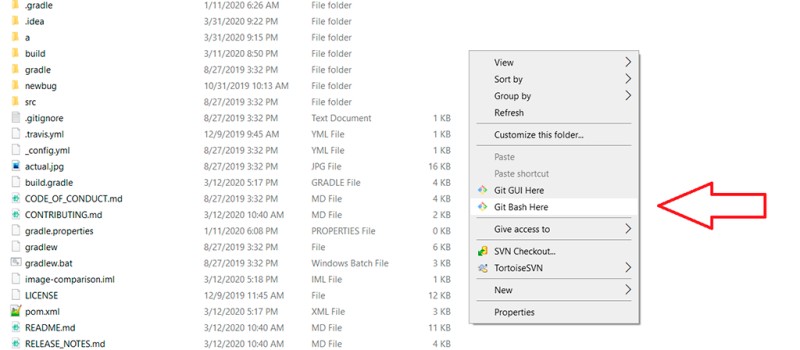
Installazione su Linux
Di solito Git fa parte delle distribuzioni Linux ed è già installato, poiché è uno strumento originariamente scritto per lo sviluppo del kernel Linux. Ma ci sono situazioni in cui non lo è. Per verificare, devi aprire un terminale e scrivere: git --version. Se ottieni una risposta comprensibile, non è necessario installare nulla. Apri un terminale e installa Git su Ubuntu . Sto lavorando su Ubuntu, quindi posso dirti cosa scrivere: sudo apt-get install git.Installazione su macOS
Anche qui devi prima verificare se Git è già presente. Se non ce l'hai, il modo più semplice per ottenerlo è scaricare l'ultima versione qui . Se Xcode è installato, Git verrà sicuramente installato automaticamente.Impostazioni Git
Git ha le impostazioni utente per l'utente che invierà il lavoro. Questo ha senso ed è necessario, perché Git prende queste informazioni per il campo Autore quando viene creato un commit. Imposta un nome utente e una password per tutti i tuoi progetti eseguendo i seguenti comandi:
git config --global user.name "Ivan Ivanov"
git config --global user.email ivan.ivanov@gmail.com
git config user.name "Ivan Ivanov"
git config user.email ivan.ivanov@gmail.com
Un po' di teoria...
Per approfondire l'argomento, dovremmo presentarvi alcune nuove parole e azioni...- repository git
- commettere
- ramo
- unire
- conflitti
- tiro
- spingere
- come ignorare alcuni file (.gitignore)
Stati in Git
Git ha diverse statue che devono essere comprese e ricordate:- non tracciato
- modificata
- messo in scena
- impegnato
Come dovresti capirlo?
Questi sono gli stati che si applicano ai file contenenti il nostro codice:- Un file creato ma non ancora aggiunto al repository ha lo stato "non tracciato".
- Quando apportiamo modifiche ai file che sono già stati aggiunti al repository Git, il loro stato è "modificato".
- Tra i file che abbiamo modificato, selezioniamo quelli di cui abbiamo bisogno e queste classi vengono modificate nello stato "messo in scena".
- Un commit viene creato da file preparati nello stato a fasi e va nel repository Git. Successivamente, non ci sono file con lo stato "messo in scena". Ma potrebbero esserci ancora file il cui stato è "modificato".
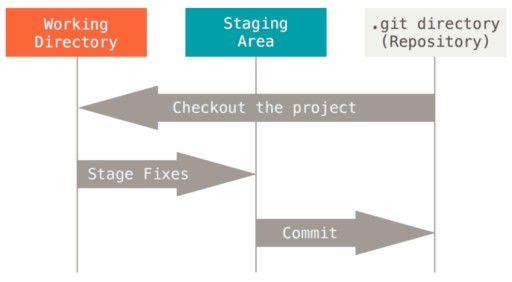
Cos'è un impegno?
Un commit è l'evento principale quando si tratta di controllo della versione. Contiene tutte le modifiche apportate dall'inizio del commit. I commit sono collegati tra loro come un elenco collegato singolarmente. Più specificamente: c'è un primo commit. Quando viene creato il secondo commit, sa cosa viene dopo il primo. E in questo modo, le informazioni possono essere monitorate. Un commit ha anche le proprie informazioni, i cosiddetti metadati:
- l'identificatore univoco del commit, che può essere utilizzato per trovarlo
- il nome dell'autore del commit, che lo ha creato
- la data di creazione del commit
- un commento che descrive cosa è stato fatto durante il commit
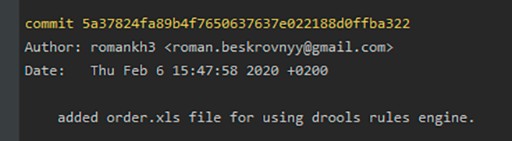
Cos'è un ramo?
Un ramo è un puntatore a qualche commit. Poiché un commit sa quale commit lo precede, quando un ramo punta a un commit, anche tutti i commit precedenti si applicano ad esso. Di conseguenza, potremmo dire che puoi avere tutti i rami che vuoi che puntano allo stesso commit. Il lavoro avviene nei rami, quindi quando viene creato un nuovo commit, il ramo sposta il suo puntatore sul commit più recente.Iniziare con Git
Puoi lavorare sia con un repository locale che con uno remoto. Per esercitarti con i comandi richiesti, puoi limitarti al repository locale. Memorizza solo tutte le informazioni del progetto localmente nella cartella .git. Se stiamo parlando del repository remoto, tutte le informazioni sono archiviate da qualche parte sul server remoto: solo una copia del progetto è archiviata localmente. Le modifiche apportate alla tua copia locale possono essere inviate (git push) al repository remoto. Nella nostra discussione qui e sotto, stiamo parlando di lavorare con Git nella console. Naturalmente, puoi utilizzare una sorta di soluzione basata su GUI (ad esempio, IntelliJ IDEA), ma prima dovresti capire quali comandi vengono eseguiti e cosa significano.Lavorare con Git in un repository locale
Successivamente, ti suggerisco di seguire ed eseguire tutti i passaggi che ho fatto mentre leggi l'articolo. Ciò migliorerà la tua comprensione e padronanza del materiale. Bene, buon appetito! :) Per creare un repository locale, devi scrivere:
git init
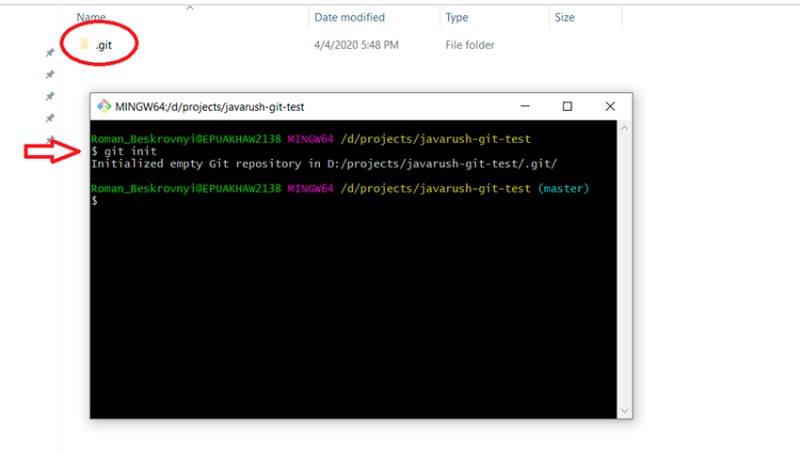 Questo creerà una cartella .git nella directory corrente della console. La cartella .git memorizza tutte le informazioni sul repository Git. Non eliminarlo ;) Successivamente, i file vengono aggiunti al progetto e viene loro assegnato lo stato "Non tracciato". Per controllare lo stato attuale del tuo lavoro, scrivi questo:
Questo creerà una cartella .git nella directory corrente della console. La cartella .git memorizza tutte le informazioni sul repository Git. Non eliminarlo ;) Successivamente, i file vengono aggiunti al progetto e viene loro assegnato lo stato "Non tracciato". Per controllare lo stato attuale del tuo lavoro, scrivi questo:
git status
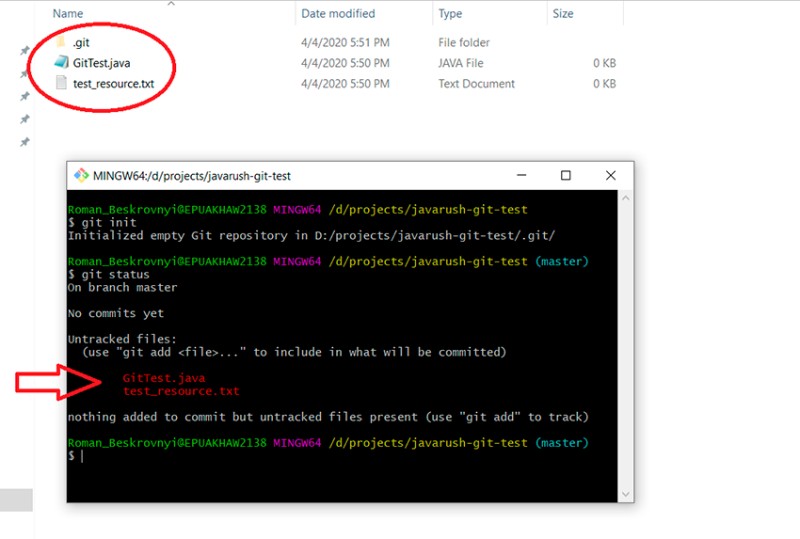 Siamo nel ramo principale e qui rimarremo fino a quando non passeremo a un altro ramo. Questo mostra quali file sono stati modificati ma non sono ancora stati aggiunti allo stato "messo in scena". Per aggiungerli allo stato "staged", devi scrivere "git add". Abbiamo alcune opzioni qui, ad esempio:
Siamo nel ramo principale e qui rimarremo fino a quando non passeremo a un altro ramo. Questo mostra quali file sono stati modificati ma non sono ancora stati aggiunti allo stato "messo in scena". Per aggiungerli allo stato "staged", devi scrivere "git add". Abbiamo alcune opzioni qui, ad esempio:
- git add -A — aggiunge tutti i file allo stato "staged".
- git aggiungi . — aggiungi tutti i file da questa cartella e da tutte le sottocartelle. In sostanza, questo è lo stesso del precedente
- git add <nome file> — aggiunge un file specifico. Qui puoi usare espressioni regolari per aggiungere file secondo uno schema. Ad esempio, git add *.java: significa che vuoi aggiungere solo file con estensione java.
git add *.txt
git status
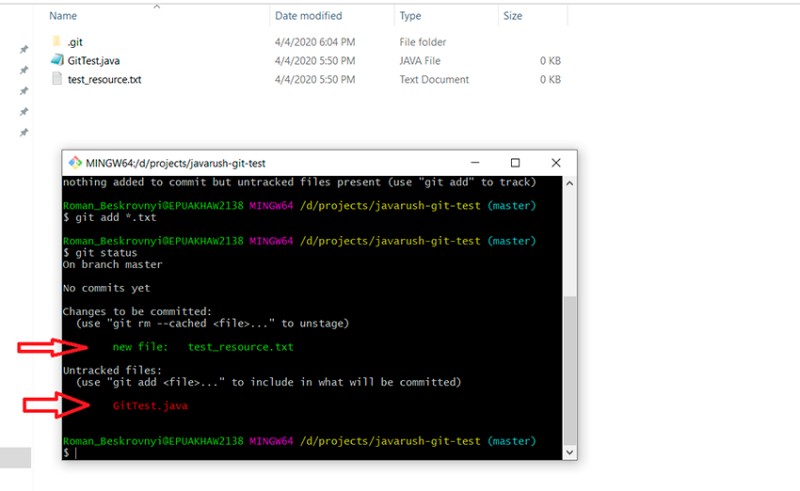 Qui puoi vedere che l'espressione regolare ha funzionato correttamente: test_resource.txt ora ha lo stato "staged". E infine, l'ultima fase per lavorare con un repository locale (ce n'è un'altra quando si lavora con il repository remoto ;)) — creando un nuovo commit:
Qui puoi vedere che l'espressione regolare ha funzionato correttamente: test_resource.txt ora ha lo stato "staged". E infine, l'ultima fase per lavorare con un repository locale (ce n'è un'altra quando si lavora con il repository remoto ;)) — creando un nuovo commit:
git commit -m "all txt files were added to the project"
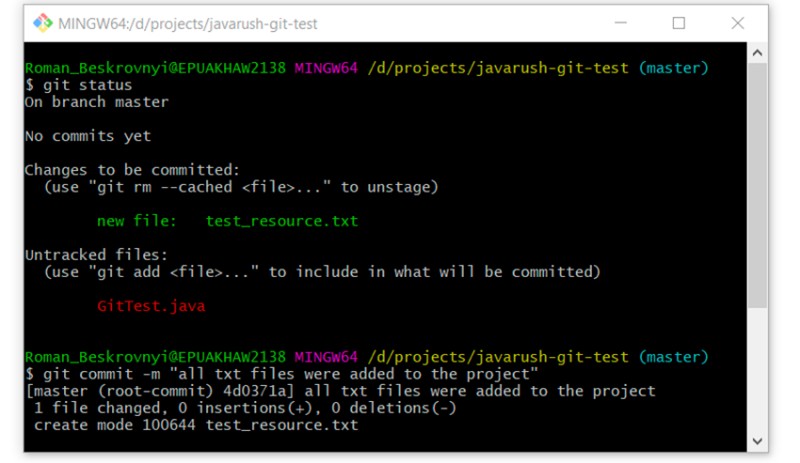 Il prossimo è un ottimo comando per guardare la cronologia dei commit su un ramo. Facciamone uso:
Il prossimo è un ottimo comando per guardare la cronologia dei commit su un ramo. Facciamone uso:
git log
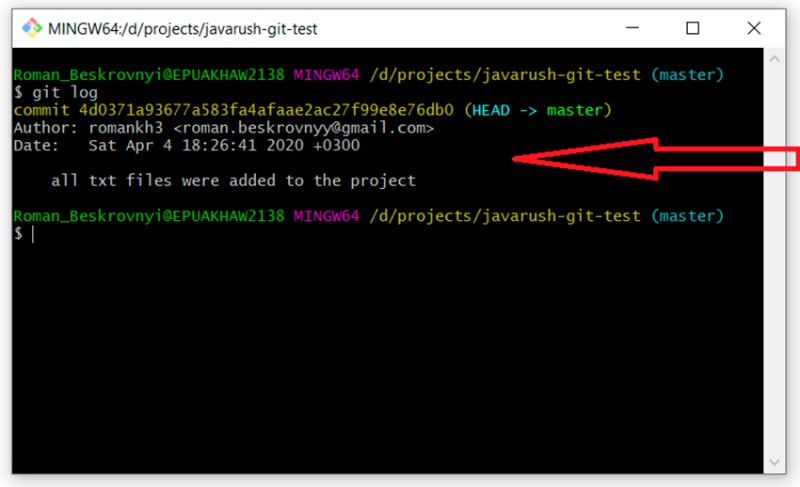 Qui puoi vedere che abbiamo creato il nostro primo commit e include il testo che abbiamo fornito sulla riga di comando. È molto importante capire che questo testo dovrebbe spiegare nel modo più accurato possibile ciò che è stato fatto durante questo commit. Questo ci aiuterà molte volte in futuro. Un lettore curioso che non si è ancora addormentato potrebbe chiedersi cosa sia successo al file GitTest.java. Scopriamolo subito. Per farlo utilizziamo:
Qui puoi vedere che abbiamo creato il nostro primo commit e include il testo che abbiamo fornito sulla riga di comando. È molto importante capire che questo testo dovrebbe spiegare nel modo più accurato possibile ciò che è stato fatto durante questo commit. Questo ci aiuterà molte volte in futuro. Un lettore curioso che non si è ancora addormentato potrebbe chiedersi cosa sia successo al file GitTest.java. Scopriamolo subito. Per farlo utilizziamo:
git status
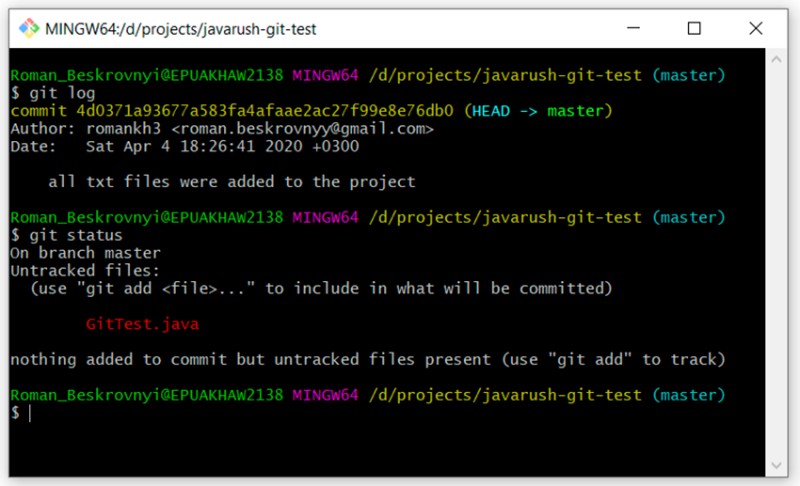 Come puoi vedere, è ancora "non tracciato" e sta aspettando dietro le quinte. Ma cosa succede se non vogliamo aggiungerlo affatto al progetto? A volte succede. Per rendere le cose più interessanti, proviamo ora a modificare il nostro file test_resource.txt. Aggiungiamo del testo lì e controlliamo lo stato:
Come puoi vedere, è ancora "non tracciato" e sta aspettando dietro le quinte. Ma cosa succede se non vogliamo aggiungerlo affatto al progetto? A volte succede. Per rendere le cose più interessanti, proviamo ora a modificare il nostro file test_resource.txt. Aggiungiamo del testo lì e controlliamo lo stato:
git status
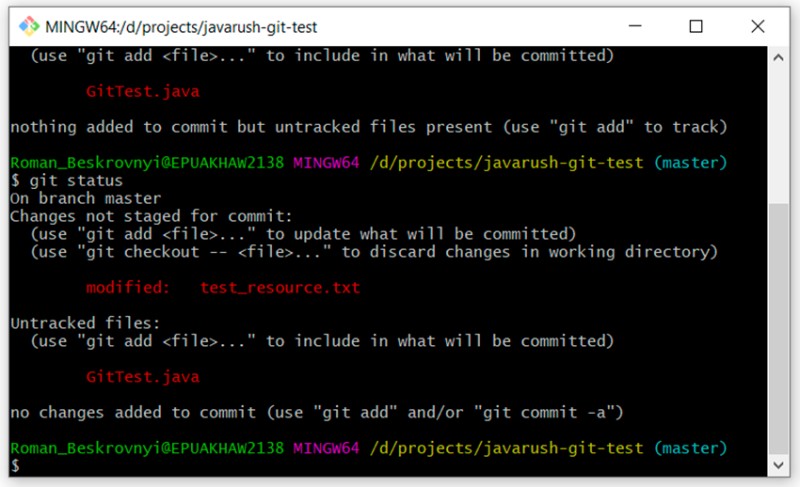 Qui puoi vedere chiaramente la differenza tra gli stati "non tracciati" e "modificati". GitTest.java è "non tracciato", mentre test_resource.txt è "modificato". Ora che abbiamo i file nello stato modificato, possiamo esaminare le modifiche apportate ad essi. Questo può essere fatto usando il seguente comando:
Qui puoi vedere chiaramente la differenza tra gli stati "non tracciati" e "modificati". GitTest.java è "non tracciato", mentre test_resource.txt è "modificato". Ora che abbiamo i file nello stato modificato, possiamo esaminare le modifiche apportate ad essi. Questo può essere fatto usando il seguente comando:
git diff
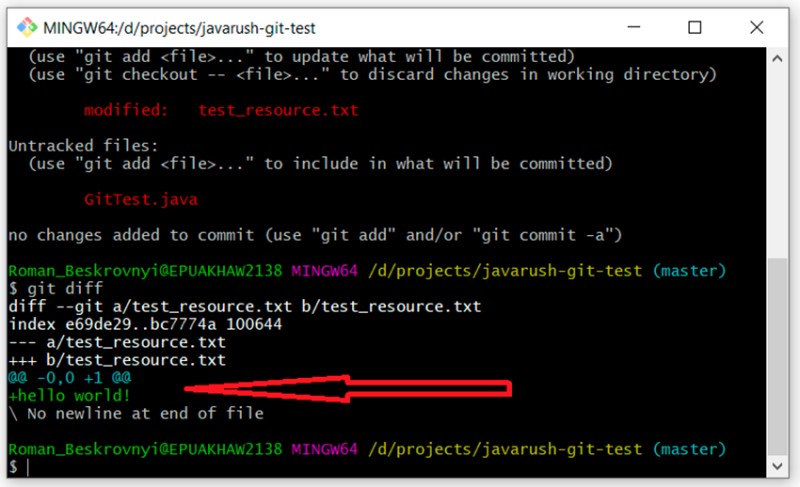 Cioè, puoi vedere chiaramente qui cosa ho aggiunto al nostro file di testo: ciao mondo! Aggiungiamo le nostre modifiche al file di testo e creiamo un commit:
Cioè, puoi vedere chiaramente qui cosa ho aggiunto al nostro file di testo: ciao mondo! Aggiungiamo le nostre modifiche al file di testo e creiamo un commit:
git add test_resource.txt
git commit -m "added hello word! to test_resource.txt"
git log
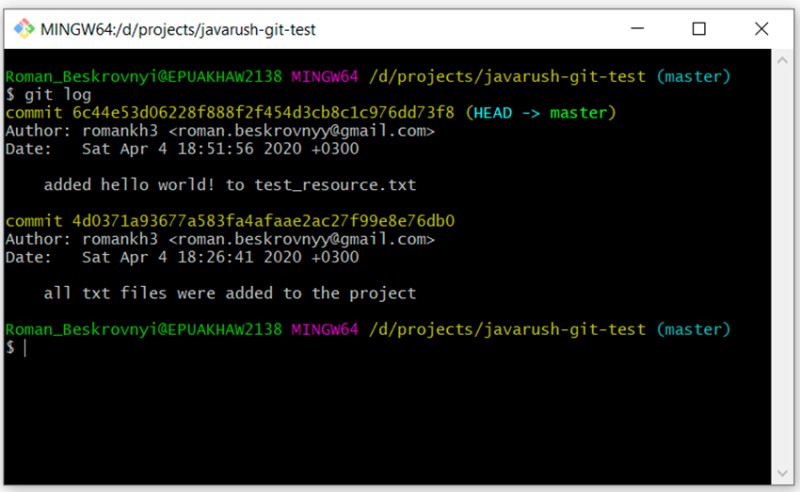 Come puoi vedere, ora abbiamo due commit. Aggiungeremo GitTest.java allo stesso modo. Nessun commento qui, solo comandi:
Come puoi vedere, ora abbiamo due commit. Aggiungeremo GitTest.java allo stesso modo. Nessun commento qui, solo comandi:
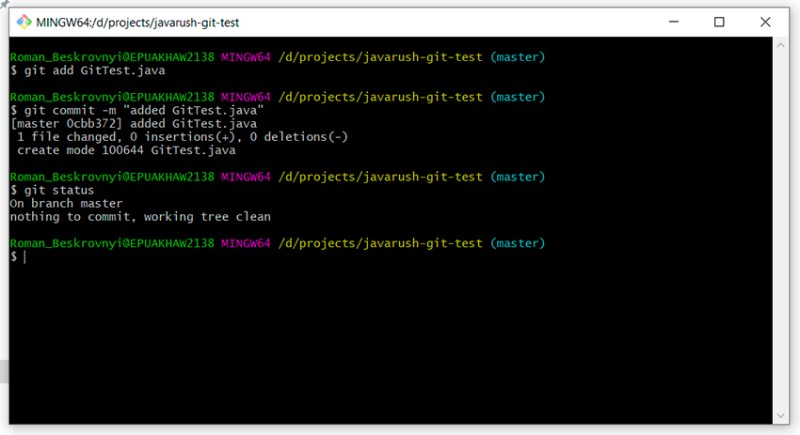
git add GitTest.java
git commit -m "added GitTest.java"
git status
Lavorare con .gitignore
Chiaramente, vogliamo solo mantenere il codice sorgente da solo, e nient'altro, nel repository. Quindi cos'altro potrebbe esserci? Come minimo, classi compilate e/o file generati dagli ambienti di sviluppo. Per dire a Git di ignorarli, dobbiamo creare un file speciale. Fai questo: crea un file chiamato .gitignore nella root del progetto. Ogni riga in questo file rappresenta un modello da ignorare. In questo esempio, il file .gitignore avrà questo aspetto:
```
*.class
target/
*.iml
.idea/
```
- La prima riga è ignorare tutti i file con estensione .class
- La seconda riga è ignorare la cartella "target" e tutto ciò che contiene
- La terza riga consiste nell'ignorare tutti i file con estensione .iml
- La quarta riga è ignorare la cartella .idea
git status
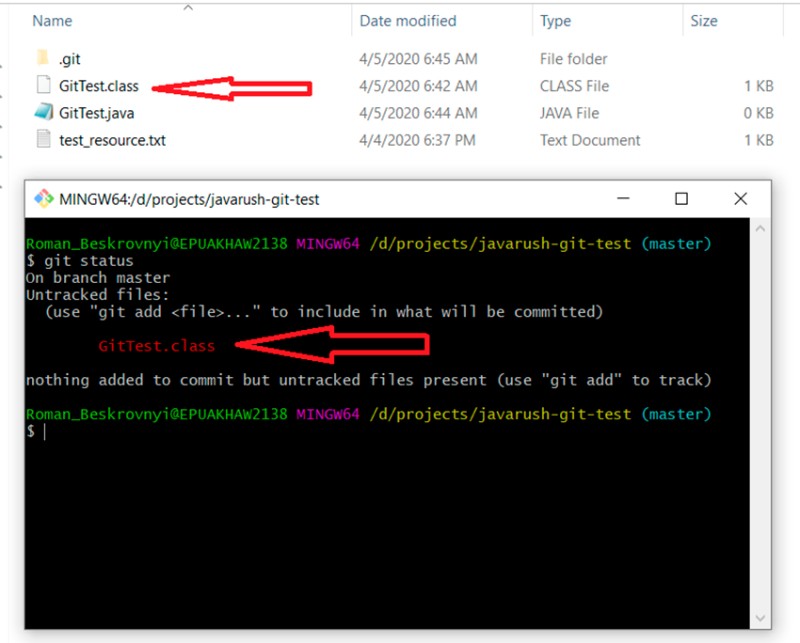 Chiaramente, non vogliamo in qualche modo aggiungere accidentalmente la classe compilata al progetto (usando git add -A). Per fare ciò, crea un file .gitignore e aggiungi tutto ciò che è stato descritto in precedenza:
Chiaramente, non vogliamo in qualche modo aggiungere accidentalmente la classe compilata al progetto (usando git add -A). Per fare ciò, crea un file .gitignore e aggiungi tutto ciò che è stato descritto in precedenza: 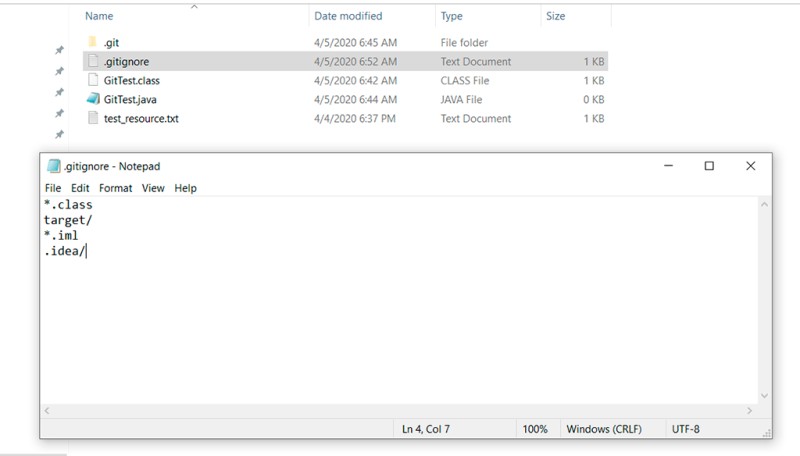 Ora usiamo un commit per aggiungere il file .gitignore al progetto:
Ora usiamo un commit per aggiungere il file .gitignore al progetto:
git add .gitignore
git commit -m "added .gitignore file"
git status
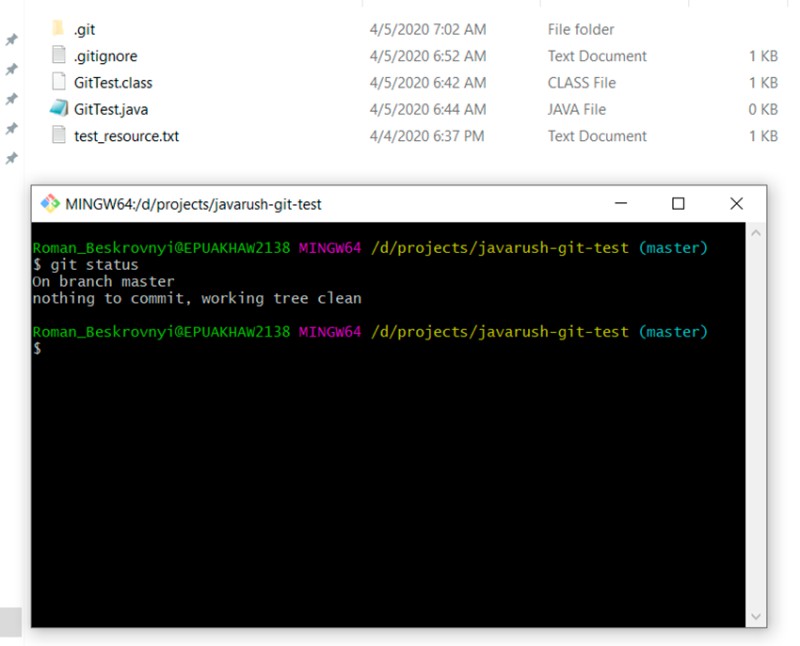 Perfetto! .gitignore +1 :)
Perfetto! .gitignore +1 :)
Lavorare con filiali e simili
Naturalmente, lavorare in un solo ramo è scomodo per gli sviluppatori solitari, ed è impossibile quando c'è più di una persona in un team. Questo è il motivo per cui abbiamo filiali. Come ho detto prima, un ramo è solo un puntatore mobile ai commit. In questa parte, esploreremo il lavoro in diversi rami: come unire le modifiche da un ramo all'altro, quali conflitti possono sorgere e molto altro. Per vedere un elenco di tutti i rami presenti nel repository e capire in quale ci si trova, è necessario scrivere:
git branch -a
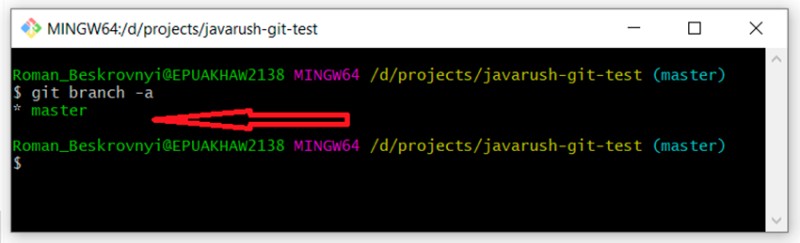 Puoi vedere che abbiamo solo un ramo principale. L'asterisco davanti indica che ci siamo dentro. A proposito, puoi anche usare il comando "git status" per scoprire in quale ramo ci troviamo. Quindi ci sono diverse opzioni per creare rami (potrebbero essercene di più - questi sono quelli che uso io):
Puoi vedere che abbiamo solo un ramo principale. L'asterisco davanti indica che ci siamo dentro. A proposito, puoi anche usare il comando "git status" per scoprire in quale ramo ci troviamo. Quindi ci sono diverse opzioni per creare rami (potrebbero essercene di più - questi sono quelli che uso io):
- creare una nuova filiale in base a quella in cui ci troviamo (99% dei casi)
- creare un branch sulla base di un commit specifico (1% dei casi)
Creiamo un ramo basato su un commit specifico
Faremo affidamento sull'identificatore univoco del commit. Per trovarlo scriviamo:
git log
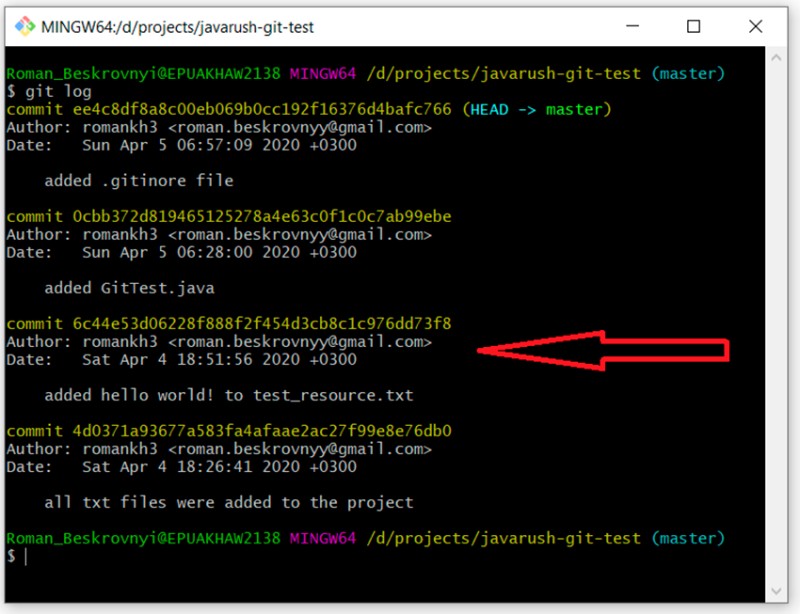 Ho evidenziato il commit con il commento "added hello world..." Il suo identificatore univoco è 6c44e53d06228f888f2f454d3cb8c1c976dd73f8. Voglio creare un ramo di "sviluppo" che parta da questo commit. Per farlo scrivo:
Ho evidenziato il commit con il commento "added hello world..." Il suo identificatore univoco è 6c44e53d06228f888f2f454d3cb8c1c976dd73f8. Voglio creare un ramo di "sviluppo" che parta da questo commit. Per farlo scrivo:
git checkout -b development 6c44e53d06228f888f2f454d3cb8c1c976dd73f8
git status
git log
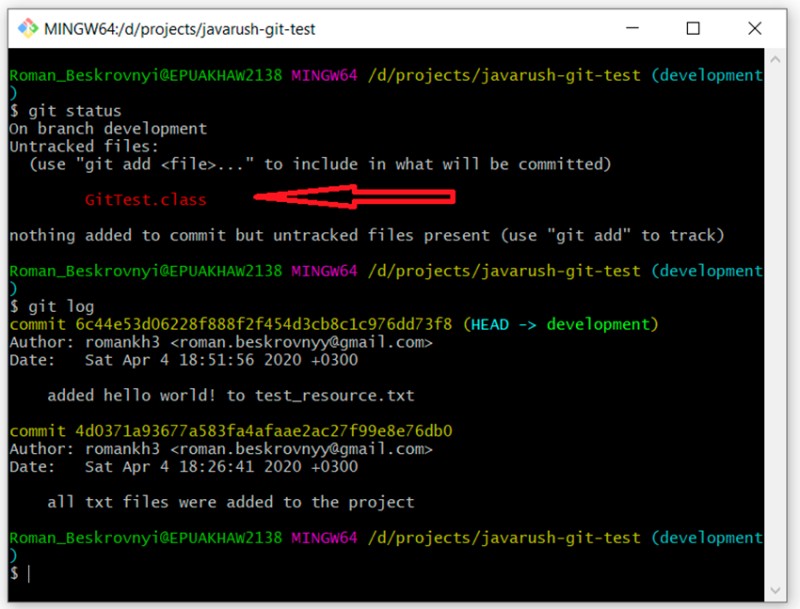 E come previsto, abbiamo due commit. A proposito, ecco un punto interessante: non esiste ancora un file .gitignore in questo ramo, quindi il nostro file compilato (GitTest.class) è ora evidenziato con lo stato "non tracciato". Ora possiamo rivedere nuovamente i nostri rami scrivendo questo:
E come previsto, abbiamo due commit. A proposito, ecco un punto interessante: non esiste ancora un file .gitignore in questo ramo, quindi il nostro file compilato (GitTest.class) è ora evidenziato con lo stato "non tracciato". Ora possiamo rivedere nuovamente i nostri rami scrivendo questo:
git branch -a
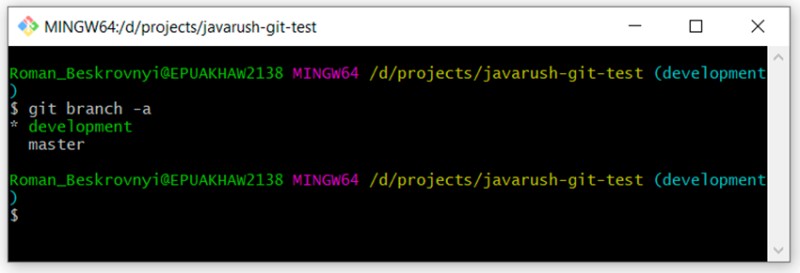 Puoi vedere che ci sono due rami: "master" e "development". Siamo attualmente in fase di sviluppo.
Puoi vedere che ci sono due rami: "master" e "development". Siamo attualmente in fase di sviluppo.
Creiamo un ramo basato su quello attuale
Il secondo modo per creare un ramo è crearlo da un altro. Voglio creare un ramo basato sul ramo principale. Innanzitutto, devo passare ad esso e il passaggio successivo è crearne uno nuovo. Diamo un'occhiata:- git checkout master — passa al ramo master
- git status — verifica che ci troviamo effettivamente nel ramo master
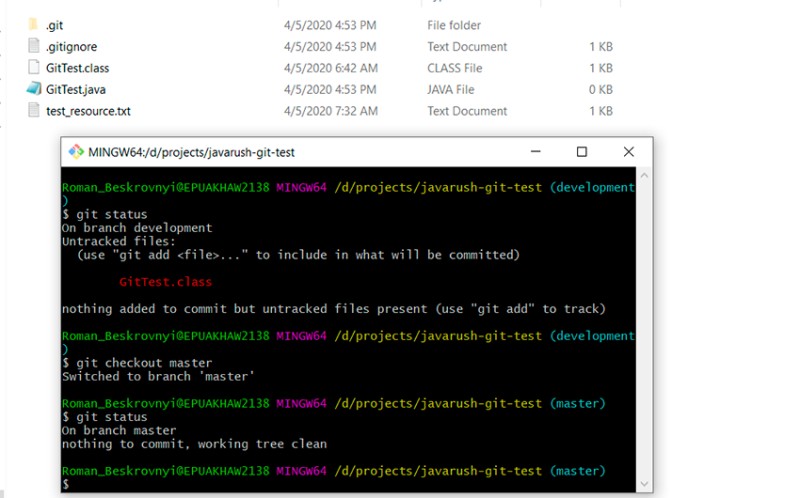 Qui puoi vedere che siamo passati al ramo master, il file .gitignore è attivo e la classe compilata non è più evidenziata come "non tracciata". Ora creiamo un nuovo ramo basato sul ramo master:
Qui puoi vedere che siamo passati al ramo master, il file .gitignore è attivo e la classe compilata non è più evidenziata come "non tracciata". Ora creiamo un nuovo ramo basato sul ramo master:
git checkout -b feature/update-txt-files
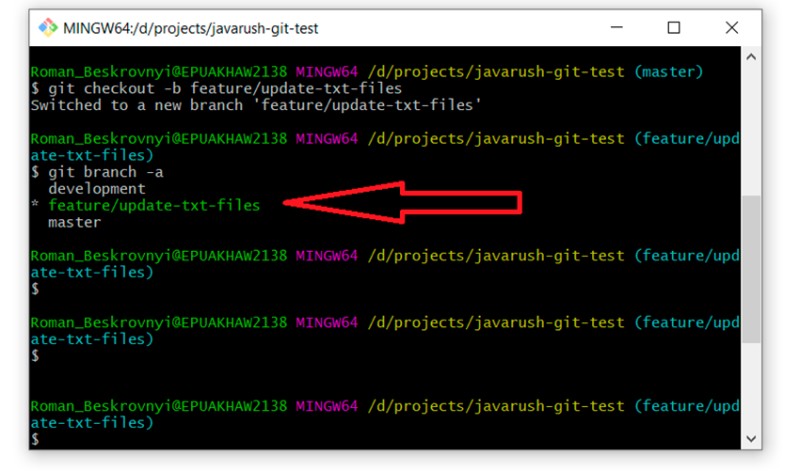 Se non sei sicuro che questo ramo sia lo stesso di "master", puoi facilmente verificare eseguendo "git log" e osservando tutti i commit. Dovrebbero essercene quattro.
Se non sei sicuro che questo ramo sia lo stesso di "master", puoi facilmente verificare eseguendo "git log" e osservando tutti i commit. Dovrebbero essercene quattro.
Risoluzione del conflitto
Prima di esplorare cos'è un conflitto, dobbiamo parlare della fusione di un ramo in un altro. Questa immagine mostra il processo di fusione di un ramo in un altro: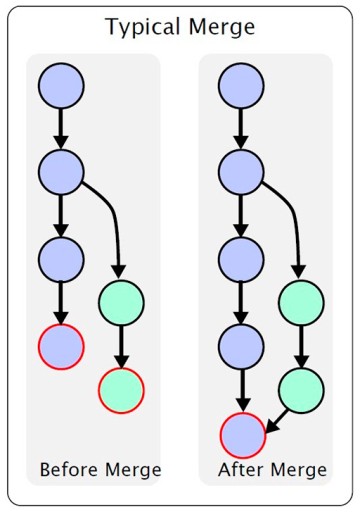 qui abbiamo un ramo principale. Ad un certo punto, viene creato un ramo secondario dal ramo principale e quindi modificato. Una volta terminato il lavoro, dobbiamo unire un ramo nell'altro. Non descriverò le varie caratteristiche: in questo articolo, voglio solo trasmettere una comprensione generale. Se hai bisogno dei dettagli, puoi cercarli tu stesso. Nel nostro esempio, abbiamo creato il ramo feature/update-txt-files. Come indicato dal nome del ramo, stiamo aggiornando il testo.
qui abbiamo un ramo principale. Ad un certo punto, viene creato un ramo secondario dal ramo principale e quindi modificato. Una volta terminato il lavoro, dobbiamo unire un ramo nell'altro. Non descriverò le varie caratteristiche: in questo articolo, voglio solo trasmettere una comprensione generale. Se hai bisogno dei dettagli, puoi cercarli tu stesso. Nel nostro esempio, abbiamo creato il ramo feature/update-txt-files. Come indicato dal nome del ramo, stiamo aggiornando il testo. 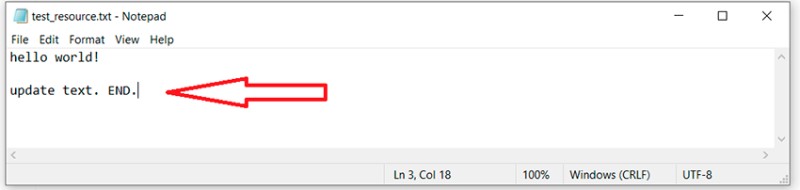 Ora dobbiamo creare un nuovo commit per questo lavoro:
Ora dobbiamo creare un nuovo commit per questo lavoro:
git add *.txt
git commit -m "updated txt files"
git log
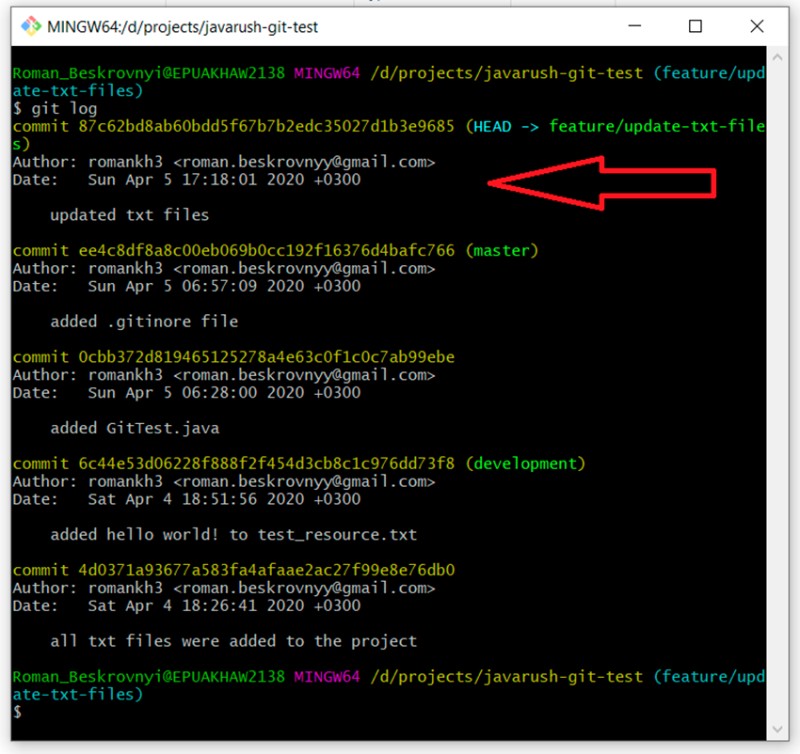 Ora, se vogliamo unire il ramo feature/update-txt-files in master, dobbiamo andare su master e scrivere "git merge feature/update-txt-files":
Ora, se vogliamo unire il ramo feature/update-txt-files in master, dobbiamo andare su master e scrivere "git merge feature/update-txt-files":
git checkout master
git merge feature/update-txt-files
git log
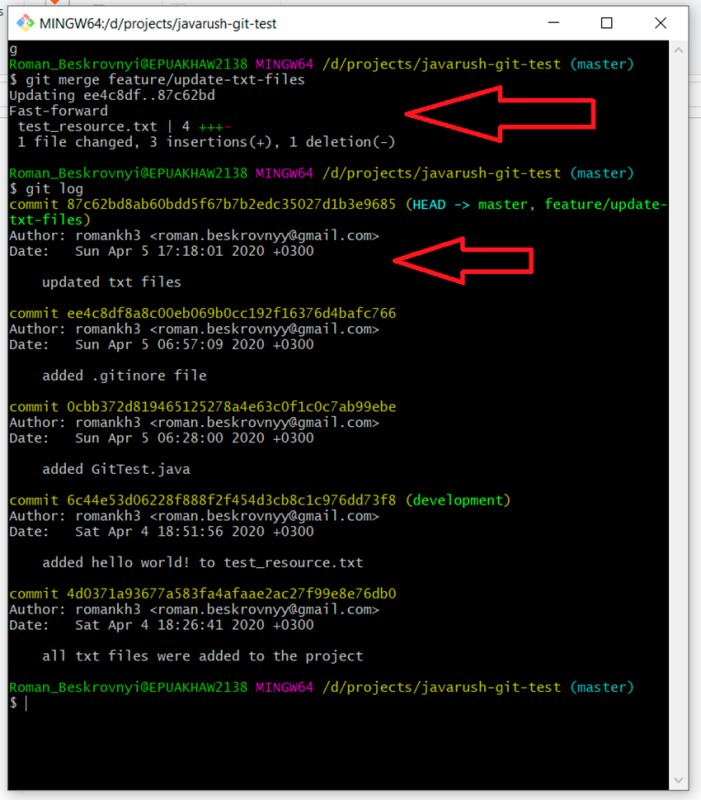 Di conseguenza, il ramo master ora include anche il commit che è stato aggiunto a feature/update-txt-files. Questa funzionalità è stata aggiunta, quindi puoi eliminare un ramo di funzionalità. Per farlo scriviamo:
Di conseguenza, il ramo master ora include anche il commit che è stato aggiunto a feature/update-txt-files. Questa funzionalità è stata aggiunta, quindi puoi eliminare un ramo di funzionalità. Per farlo scriviamo:
git branch -D feature/update-txt-files
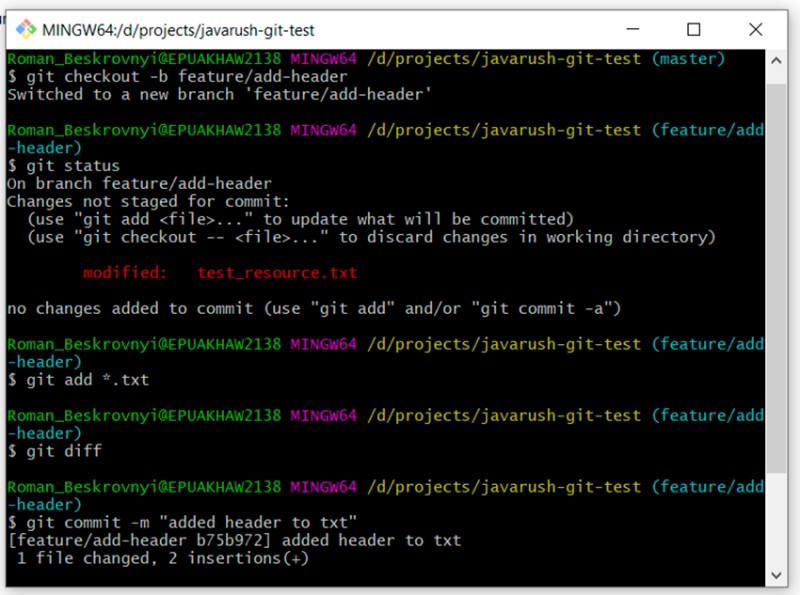
git checkout -b feature/add-header
... we make changes to the file
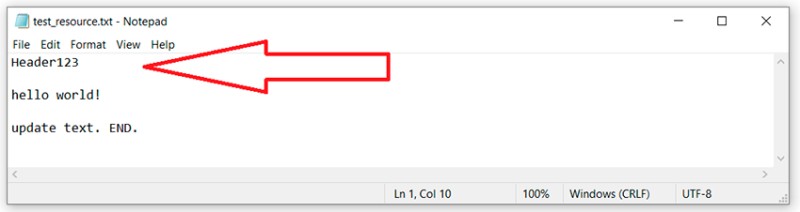
git add *.txt
git commit -m "added header to txt"
 Vai al ramo principale e aggiorna anche questo file di testo sulla stessa riga del ramo delle caratteristiche:
Vai al ramo principale e aggiorna anche questo file di testo sulla stessa riga del ramo delle caratteristiche:
git checkout master
… we updated test_resource.txt
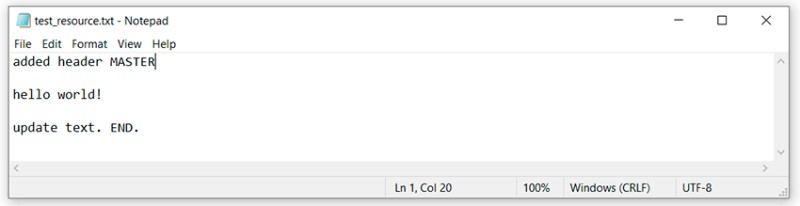
git add test_resource.txt
git commit -m "added master header to txt"
git merge feature/add-header
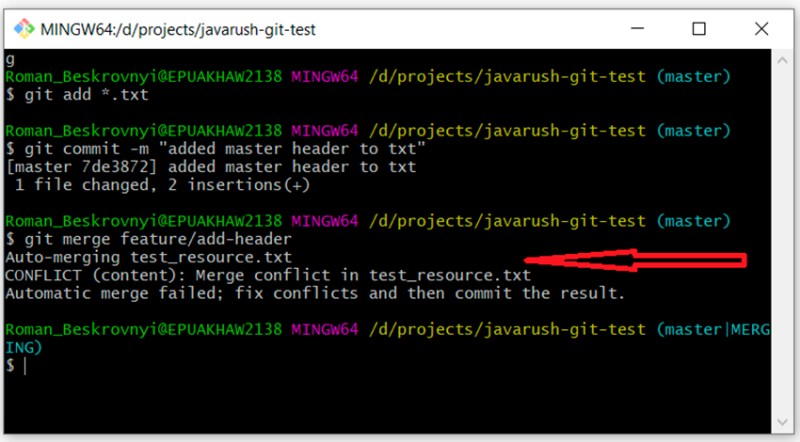 qui possiamo vedere che Git non può decidere da solo come unire questo codice. Ci dice che dobbiamo prima risolvere il conflitto e solo dopo eseguire il commit. OK. Apriamo il file con il conflitto in un editor di testo e vediamo:
qui possiamo vedere che Git non può decidere da solo come unire questo codice. Ci dice che dobbiamo prima risolvere il conflitto e solo dopo eseguire il commit. OK. Apriamo il file con il conflitto in un editor di testo e vediamo: 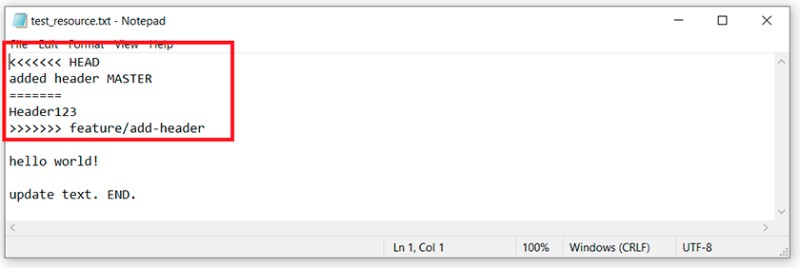 Per capire cosa ha fatto Git qui, dobbiamo ricordare quali modifiche abbiamo apportato e dove, quindi confrontare:
Per capire cosa ha fatto Git qui, dobbiamo ricordare quali modifiche abbiamo apportato e dove, quindi confrontare:
- Le modifiche presenti su questa riga nel ramo principale si trovano tra "<<<<<<< HEAD" e "=======".
- Le modifiche apportate al ramo feature/add-header si trovano tra "=======" e ">>>>>>> feature/add-header".

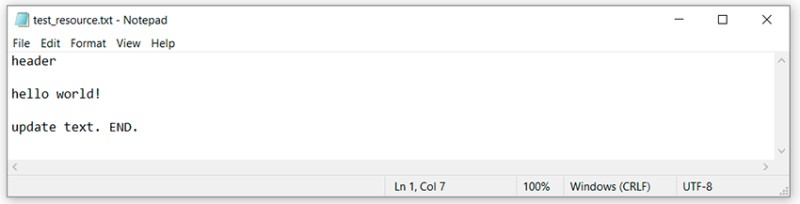 guardiamo lo stato delle modifiche. La descrizione sarà leggermente diversa. Piuttosto che uno stato "modificato", abbiamo "separato". Quindi avremmo potuto menzionare un quinto stato? Non credo sia necessario. Vediamo:
guardiamo lo stato delle modifiche. La descrizione sarà leggermente diversa. Piuttosto che uno stato "modificato", abbiamo "separato". Quindi avremmo potuto menzionare un quinto stato? Non credo sia necessario. Vediamo:
git status
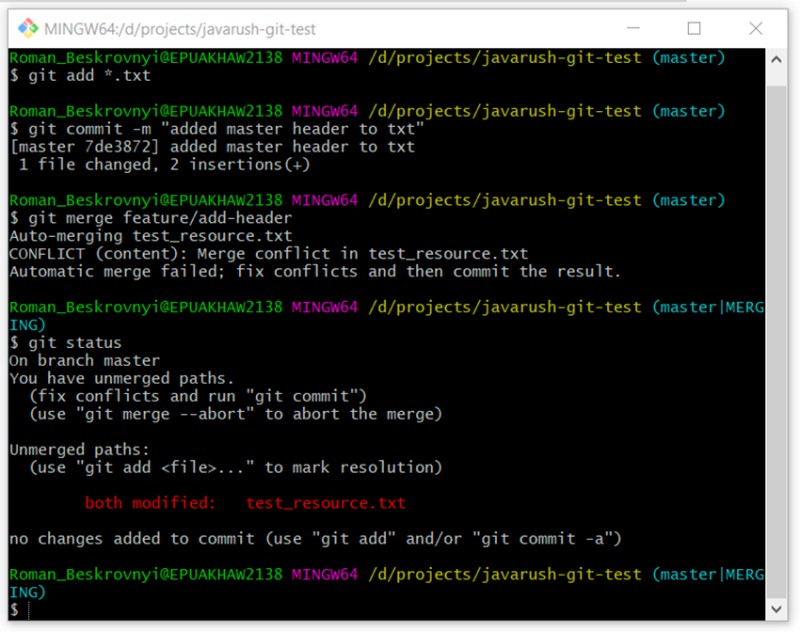 Possiamo convincerci che questo è un caso speciale, insolito. Continuiamo:
Possiamo convincerci che questo è un caso speciale, insolito. Continuiamo:
git add *.txt
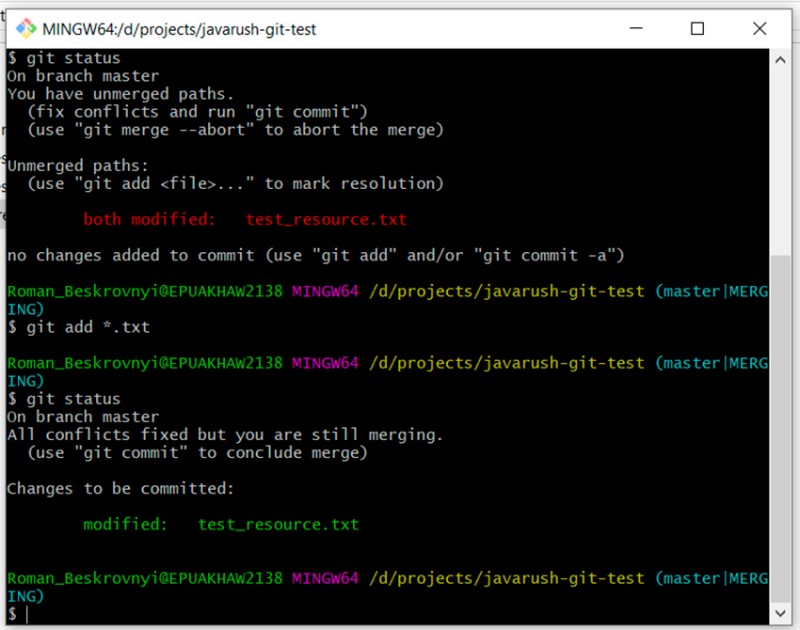 Potresti notare che la descrizione suggerisce di scrivere solo "git commit". Proviamo a scrivere che:
Potresti notare che la descrizione suggerisce di scrivere solo "git commit". Proviamo a scrivere che:
git commit
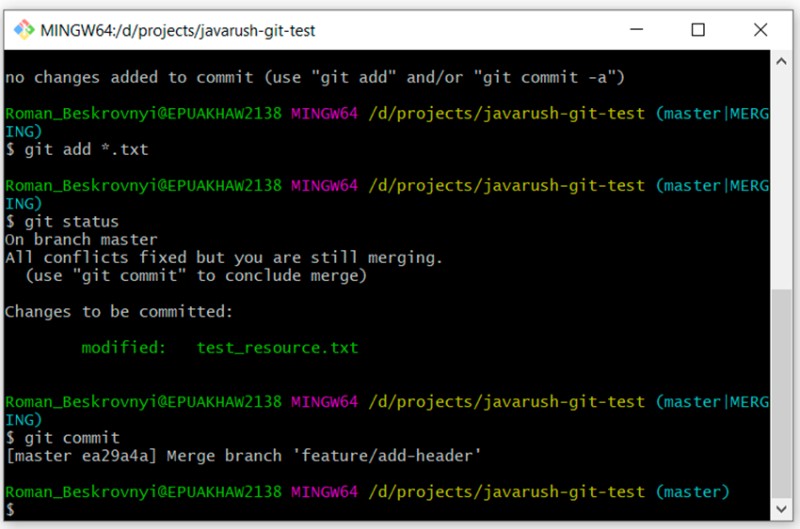 E proprio così, l'abbiamo fatto: abbiamo risolto il conflitto nella console. Naturalmente, questo può essere fatto un po' più facilmente in ambienti di sviluppo integrati. Ad esempio, in IntelliJ IDEA, tutto è impostato così bene che puoi eseguire tutte le azioni necessarie direttamente al suo interno. Ma gli IDE fanno molte cose "sotto il cofano" e spesso non capiamo cosa stia succedendo esattamente lì. E quando non c'è comprensione, possono sorgere problemi.
E proprio così, l'abbiamo fatto: abbiamo risolto il conflitto nella console. Naturalmente, questo può essere fatto un po' più facilmente in ambienti di sviluppo integrati. Ad esempio, in IntelliJ IDEA, tutto è impostato così bene che puoi eseguire tutte le azioni necessarie direttamente al suo interno. Ma gli IDE fanno molte cose "sotto il cofano" e spesso non capiamo cosa stia succedendo esattamente lì. E quando non c'è comprensione, possono sorgere problemi.
Lavorare con repository remoti
L'ultimo passo è capire alcuni altri comandi necessari per lavorare con il repository remoto. Come ho detto, un repository remoto è un luogo in cui è archiviato il repository e da cui è possibile clonarlo. Che tipo di repository remoti ci sono? Esempi:-
GitHub è la più grande piattaforma di storage per repository e sviluppo collaborativo. L'ho già descritto in articoli precedenti.
Seguimi su GitHub . Spesso mostro il mio lavoro lì in quelle aree che sto studiando per lavoro. -
GitLab è uno strumento basato sul Web per il ciclo di vita DevOps con open source . È un sistema basato su Git per la gestione dei repository di codice con il proprio wiki, sistema di tracciamento dei bug , pipeline CI/CD e altre funzioni.
Dopo la notizia che Microsoft ha acquistato GitHub, alcuni sviluppatori hanno duplicato i loro progetti in GitLab. -
BitBucket è un servizio Web per l'hosting di progetti e lo sviluppo collaborativo basato sui sistemi di controllo della versione Mercurial e Git. Un tempo aveva un grande vantaggio rispetto a GitHub in quanto offriva repository privati gratuiti. L'anno scorso, GitHub ha anche introdotto questa funzionalità gratuitamente a tutti.
-
E così via…
git clone https://github.com/romankh3/git-demo
git pull
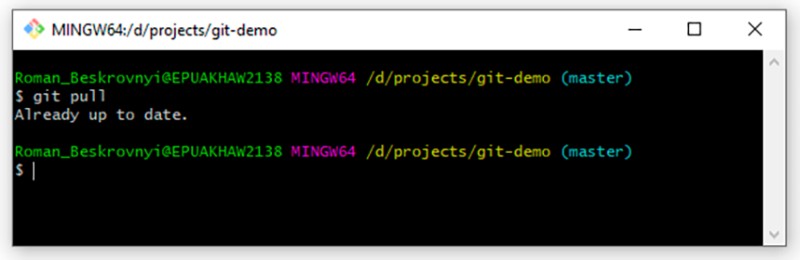 Nel nostro caso, al momento non è cambiato nulla nel repository remoto, quindi la risposta è: Già aggiornato. Ma se apporto modifiche al repository remoto, quello locale viene aggiornato dopo che le abbiamo estratte. Infine, l'ultimo comando consiste nell'inviare i dati al repository remoto. Quando abbiamo fatto qualcosa in locale e vogliamo inviarlo al repository remoto, dobbiamo prima creare un nuovo commit in locale. Per dimostrarlo, aggiungiamo qualcos'altro al nostro file di testo:
Nel nostro caso, al momento non è cambiato nulla nel repository remoto, quindi la risposta è: Già aggiornato. Ma se apporto modifiche al repository remoto, quello locale viene aggiornato dopo che le abbiamo estratte. Infine, l'ultimo comando consiste nell'inviare i dati al repository remoto. Quando abbiamo fatto qualcosa in locale e vogliamo inviarlo al repository remoto, dobbiamo prima creare un nuovo commit in locale. Per dimostrarlo, aggiungiamo qualcos'altro al nostro file di testo: 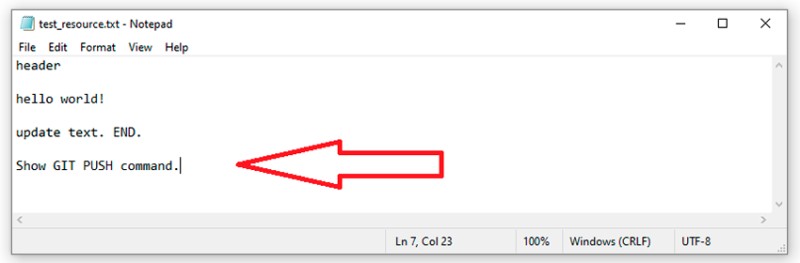 Ora qualcosa di abbastanza comune per noi — creiamo un commit per questo lavoro:
Ora qualcosa di abbastanza comune per noi — creiamo un commit per questo lavoro:
git add test_resource.txt
git commit -m "prepared txt for pushing"
git push
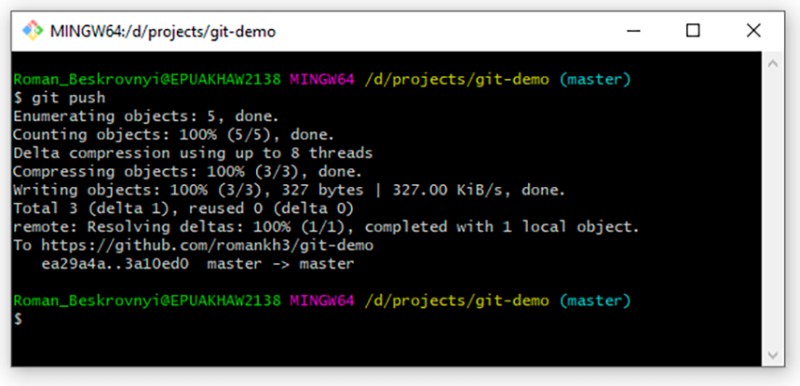 Bene, questo è tutto quello che volevo dire. Grazie per l'attenzione. Seguimi su GitHub , dove pubblico vari fantastici progetti di esempio relativi al mio studio e lavoro personale.
Bene, questo è tutto quello che volevo dire. Grazie per l'attenzione. Seguimi su GitHub , dove pubblico vari fantastici progetti di esempio relativi al mio studio e lavoro personale.
Collegamento utile
- Documentazione Git ufficiale . Lo consiglio come riferimento.
GO TO FULL VERSION