Instead of an introduction
Hello! Today we're going to talk about a version control system, namely Git. You have nothing to do with programming if you don't know/understand Git. But the beauty is that you don't have to keep all the Git commands and features in your head in order to be continuously employed. You need to know a set of commands that will help you understand everything that is happening.
You have nothing to do with programming if you don't know/understand Git. But the beauty is that you don't have to keep all the Git commands and features in your head in order to be continuously employed. You need to know a set of commands that will help you understand everything that is happening.Git basics
Git is a distributed version control system for our code. Why do we need it? Distributed teams need some kind of system for managing their work. It is needed to track changes that occur over time. That is, we need to be able to see step-by-step which files have changed and how. This is especially important when you are investigating what changed in the context of a single task, making it possible to revert the changes.Installing Git
Let's install Java on your computer.Installing on Windows
As usual, you need to download and run an exe file. Everything is simple here: click on the first Google link, perform the install, and that's it. To do this, we will use the bash console provided by Windows. On Windows, you need to run Git Bash. Here's how it looks in the Start Menu: Now this is a command prompt you can work with.
To avoid having to go to the folder with the project every time in order to open Git there, you can open the command prompt in the project folder with the right mouse button with the path we need:
Now this is a command prompt you can work with.
To avoid having to go to the folder with the project every time in order to open Git there, you can open the command prompt in the project folder with the right mouse button with the path we need: 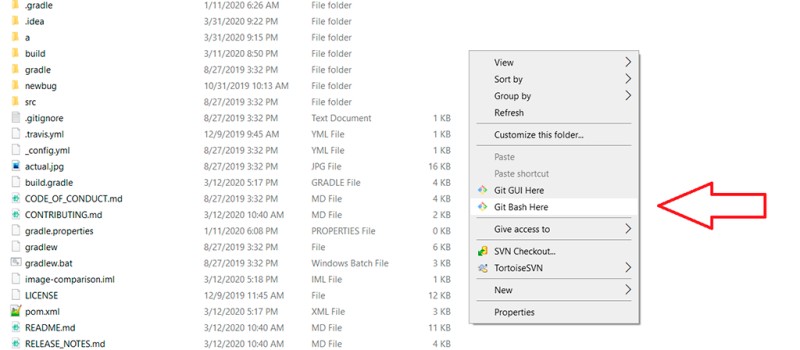
Installing on Linux
Usually Git is part of Linux distributions and is already installed, since it is a tool that was originally written for Linux kernel development. But there are situations when it is not. To check, you need to open a terminal and write: git --version. If you get an intelligible answer, then nothing needs to be installed. Open a terminal and install Git on Ubuntu. I'm working on Ubuntu, so I can tell you what to write for it: sudo apt-get install git.Installing on macOS
Here, too, you first need to check whether Git is already there. If you don't have it, then the easiest way to get it is to download the latest version here. If Xcode is installed, then Git will definitely be automatically installed.Git settings
Git has user settings for the user who will submit work. This makes sense and is necessary, because Git takes this information for the Author field when a commit is created. Set up a username and password for all your projects by running the following commands:
git config --global user.name "Ivan Ivanov"
git config --global user.email ivan.ivanov@gmail.com
git config user.name "Ivan Ivanov"
git config user.email ivan.ivanov@gmail.com
A bit of theory...
To dive into the topic, we should introduce you to a few new words and actions...- git repository
- commit
- branch
- merge
- conflicts
- pull
- push
- how to ignore some files (.gitignore)
Statuses in Git
Git has several statues that need to be understood and remembered:- untracked
- modified
- staged
- committed
How should you understand this?
These are statuses that apply to the files containing our code:- A file that is created but not yet added to the repository has the "untracked" status.
- When we make changes to files that have already been added to the Git repository, then their status is "modified".
- Among the files that we have changed, we select the ones that we need, and these classes are changed to the "staged" status.
- A commit is created from prepared files in the staged state and goes into the Git repository. After that, there are no files with the "staged" status. But there may still be files whose status is "modified".
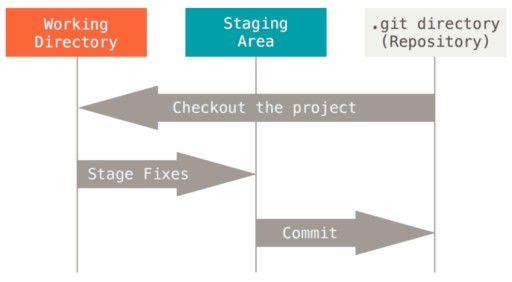
What is a commit?
A commit is the main event when it comes to version control. It contains all the changes made since the commit began. Commits are linked together like a singly linked list. More specifically: There is a first commit. When the second commit is created, it knows what comes after the first. And in this manner, information can be tracked. A commit also has its own information, so-called metadata:
- the commit's unique identifier, which can be used to find it
- the name of the commit's author, who created it
- the date the commit was created
- a comment that describes what was done during the commit
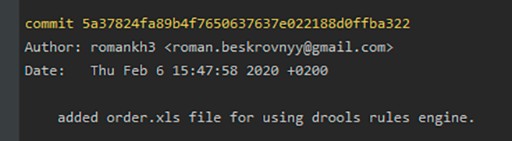
What is a branch?
A branch is a pointer to some commit. Because a commit knows which commit precedes it, when a branch points to a commit, all those previous commits also apply to it. Accordingly, we could say that you can have as many branches as you want pointing to the same commit. Work happens in branches, so when a new commit is created, the branch moves its pointer to the more recent commit.Getting started with Git
You can work with a local repository alone as well as with a remote one. To practice the required commands, you can limit yourself to the local repository. It only stores all the project's information locally in the .git folder. If we're talking about the remote repository, then all the information is stored somewhere on the remote server: only a copy of the project is stored locally. Changes made to your local copy can be pushed (git push) to the remote repository. In our discussion here and below, we are talking about working with Git in the console. Of course, you can use some sort of GUI-based solution (for example, IntelliJ IDEA), but first you should figure out what commands are being executed and what they mean.Working with Git in a local repository
Next, I suggest that you follow along and perform all the steps that I did as you read the article. This will improve your understanding and mastery of the material. Well, bon appetit! :) To create a local repository, you need to write:
git init
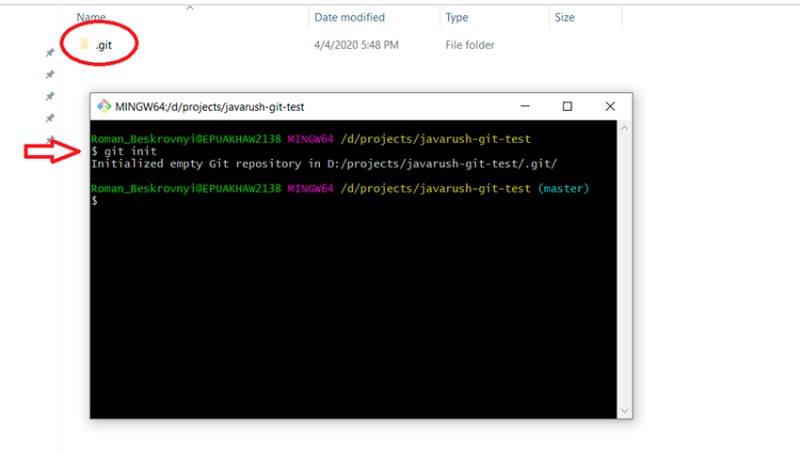 This will create a .git folder in the console's current directory.
The .git folder stores all information about the Git repository. Don't delete it ;)
Next, files are added to the project, and they are assigned the "Untracked" status. To check the current status of your work, write this:
This will create a .git folder in the console's current directory.
The .git folder stores all information about the Git repository. Don't delete it ;)
Next, files are added to the project, and they are assigned the "Untracked" status. To check the current status of your work, write this:
git status
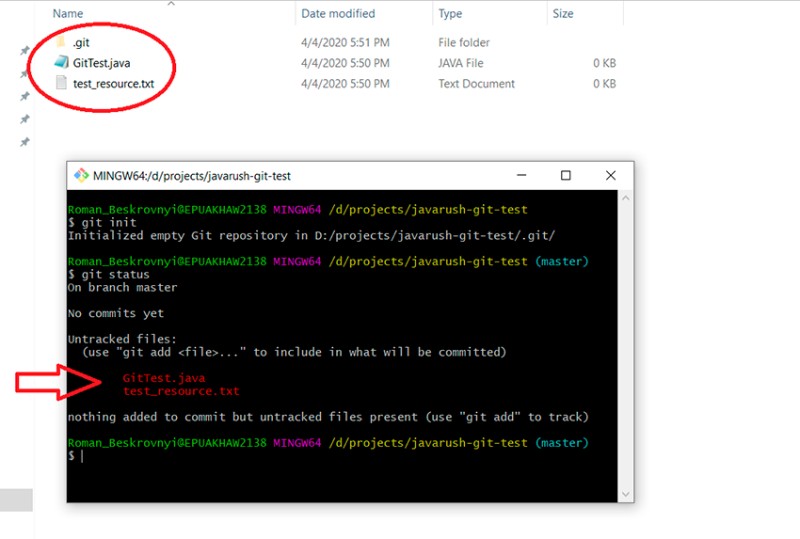 We are in the master branch, and here we will remain until we switch to another branch.
This shows which files have changed but have not yet been added to the "staged" status. To add them to the "staged" status, you need to write "git add". We have a few options here, for example:
We are in the master branch, and here we will remain until we switch to another branch.
This shows which files have changed but have not yet been added to the "staged" status. To add them to the "staged" status, you need to write "git add". We have a few options here, for example:
- git add -A — add all files to the "staged" status
- git add . — add all files from this folder and all subfolders. Essentially, this is the same as the previous one
- git add <file name> — adds a specific file. Here you can use regular expressions to add files according to some pattern. For example, git add *.java: This means that you only want to add files with the java extension.
git add *.txt
git status
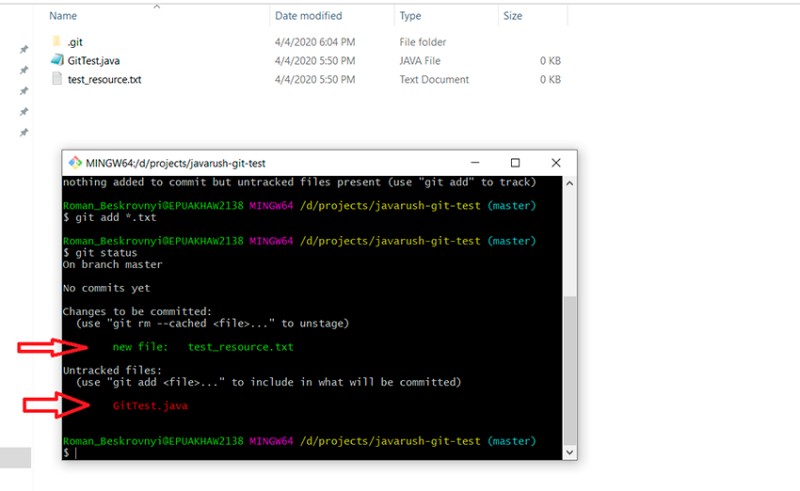 Here you can see that the regular expression has worked correctly: test_resource.txt is now has the "staged" status.
And finally, the last stage for working with a local repository (there is one more when working with the remote repository ;)) — creating a new commit:
Here you can see that the regular expression has worked correctly: test_resource.txt is now has the "staged" status.
And finally, the last stage for working with a local repository (there is one more when working with the remote repository ;)) — creating a new commit:
git commit -m "all txt files were added to the project"
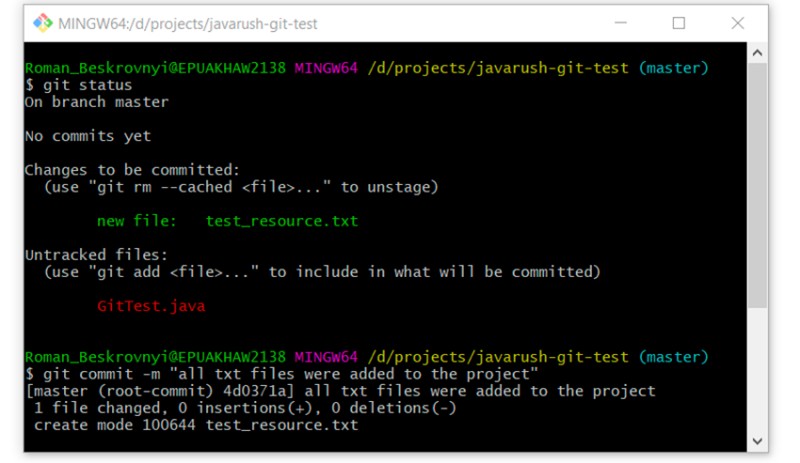 Next up is a great command for looking at the commit history on a branch. Let's make use of it:
Next up is a great command for looking at the commit history on a branch. Let's make use of it:
git log
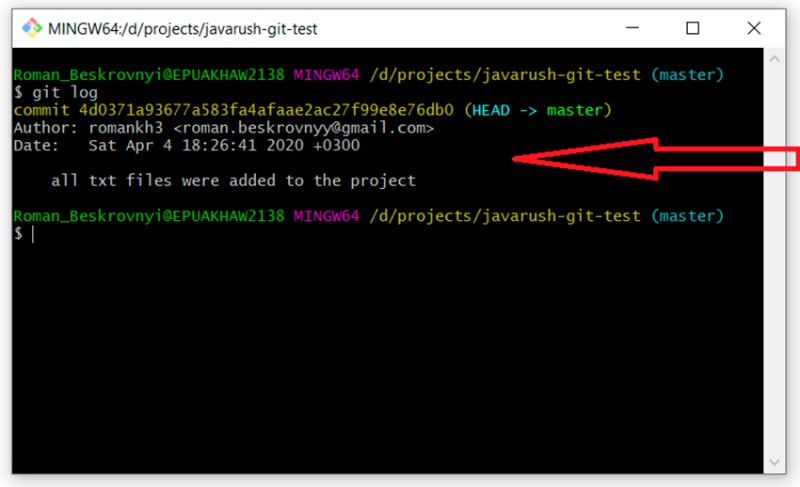 Here you can see that we have created our first commit and it includes the text that we provided on the command line. It is very important to understand that this text should explain as accurately as possible what was done during this commit. This will help us many times in the future.
An inquisitive reader who has not yet fallen asleep may be wondering what happened to the GitTest.java file. Let's find out right now. To do this, we use:
Here you can see that we have created our first commit and it includes the text that we provided on the command line. It is very important to understand that this text should explain as accurately as possible what was done during this commit. This will help us many times in the future.
An inquisitive reader who has not yet fallen asleep may be wondering what happened to the GitTest.java file. Let's find out right now. To do this, we use:
git status
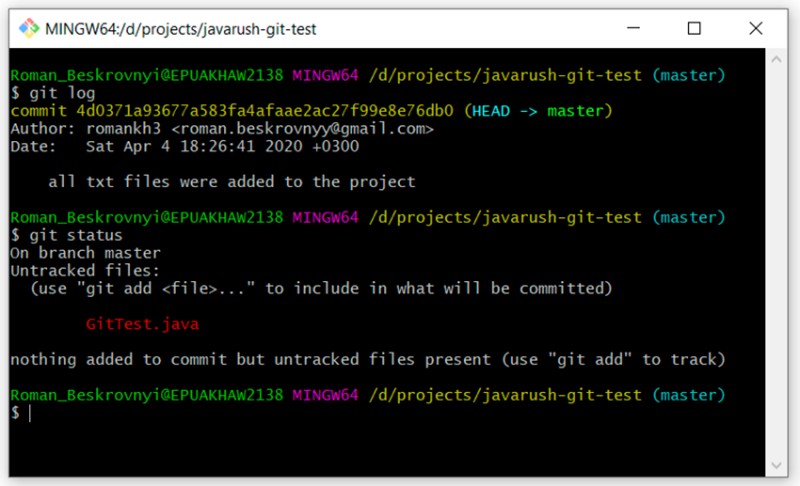 As you can see, it is still "untracked" and is waiting in the wings. But what if we don't want to add it to the project at all? Sometimes that happens.
To make things more interesting, let's now try to change our test_resource.txt file. Let's add some text there and check the status:
As you can see, it is still "untracked" and is waiting in the wings. But what if we don't want to add it to the project at all? Sometimes that happens.
To make things more interesting, let's now try to change our test_resource.txt file. Let's add some text there and check the status:
git status
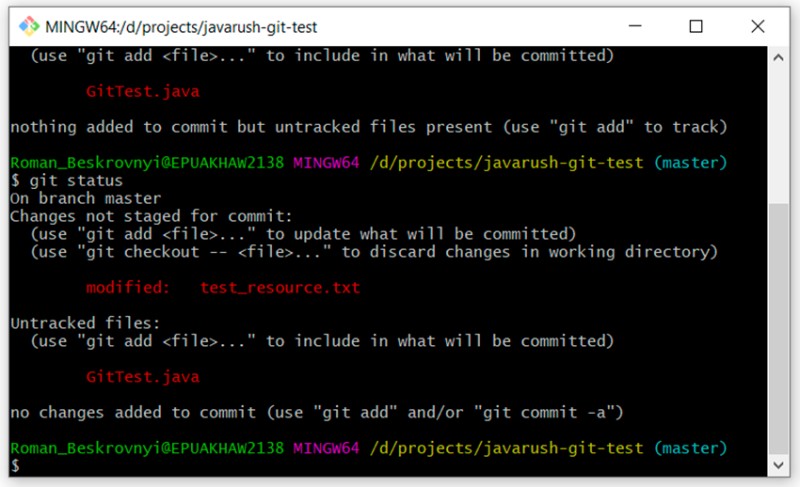 Here you can clearly see the difference between the "untracked" and "modified" statuses.
GitTest.java is "untracked", while test_resource.txt is "modified".
Now that we have files in the modified state, we can examine the changes made to them. This can be done using the following command:
Here you can clearly see the difference between the "untracked" and "modified" statuses.
GitTest.java is "untracked", while test_resource.txt is "modified".
Now that we have files in the modified state, we can examine the changes made to them. This can be done using the following command:
git diff
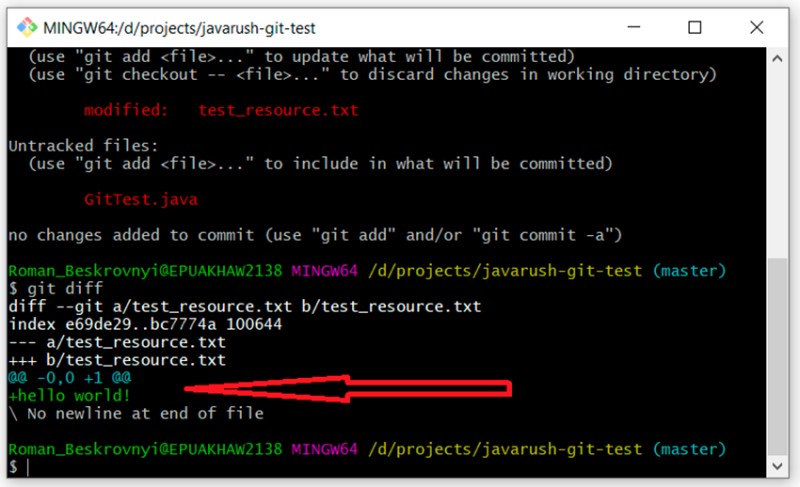 That is, you can clearly see here what I added to our text file: hello world!
Let's add our changes to the text file and create a commit:
That is, you can clearly see here what I added to our text file: hello world!
Let's add our changes to the text file and create a commit:
git add test_resource.txt
git commit -m "added hello word! to test_resource.txt"
git log
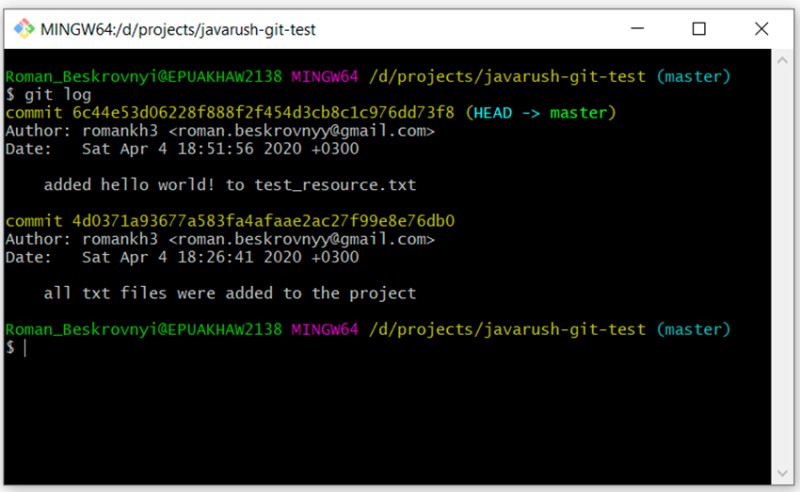 As you can see, we now have two commits.
We'll add GitTest.java in the same way. No comments here, just commands:
As you can see, we now have two commits.
We'll add GitTest.java in the same way. No comments here, just commands:
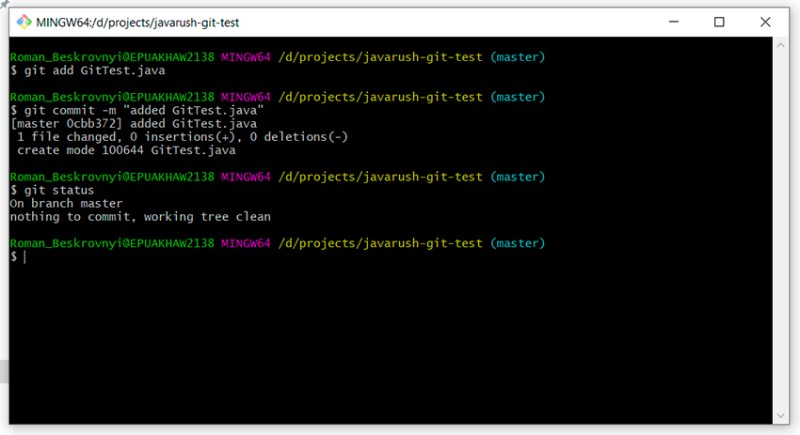
git add GitTest.java
git commit -m "added GitTest.java"
git status
Working with .gitignore
Clearly, we only want to keep source code alone, and nothing else, in the repository. So what else could there be? At a minimum, compiled classes and/or files generated by development environments. To tell Git to ignore them, we need to create a special file. Do this: create a file called .gitignore in the root of the project. Each line in this file represents a pattern to ignore. In this example, the .gitignore file will look like this:
```
*.class
target/
*.iml
.idea/
```
- The first line is to ignore all files with the .class extension
- The second line is to ignore the "target" folder and everything it contains
- The third line is to ignore all files with the .iml extension
- The fourth line is to ignore the .idea folder
git status
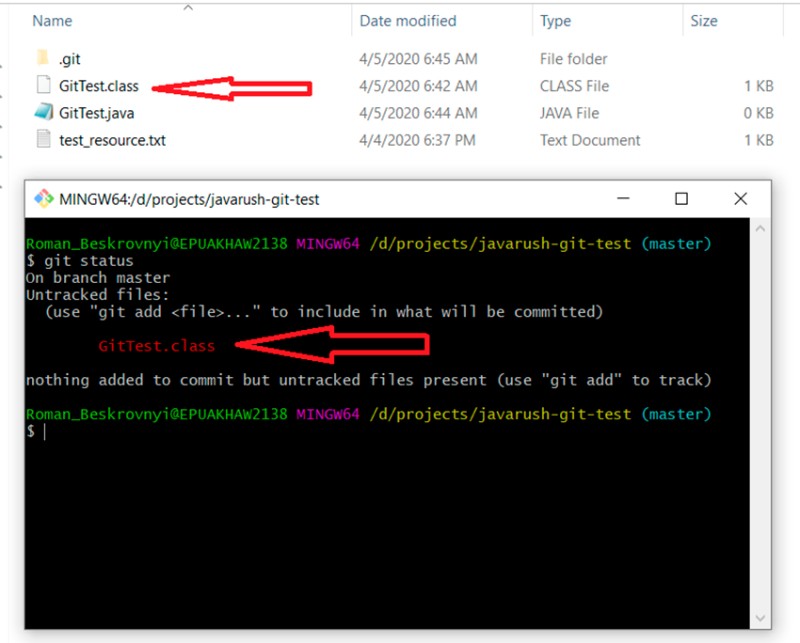 Clearly, we do not want to somehow accidentally add the compiled class to the project (using git add -A). To do this, create a .gitignore file and add everything that was described earlier:
Clearly, we do not want to somehow accidentally add the compiled class to the project (using git add -A). To do this, create a .gitignore file and add everything that was described earlier: 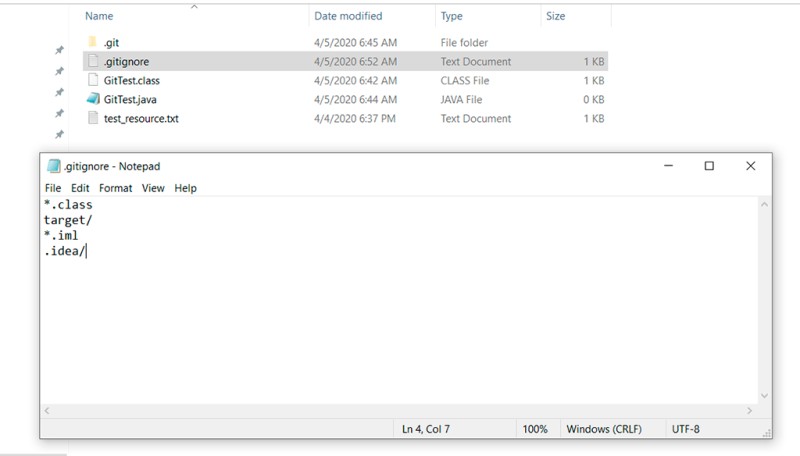 Now let's use a commit to add the .gitignore file to the project:
Now let's use a commit to add the .gitignore file to the project:
git add .gitignore
git commit -m "added .gitignore file"
git status
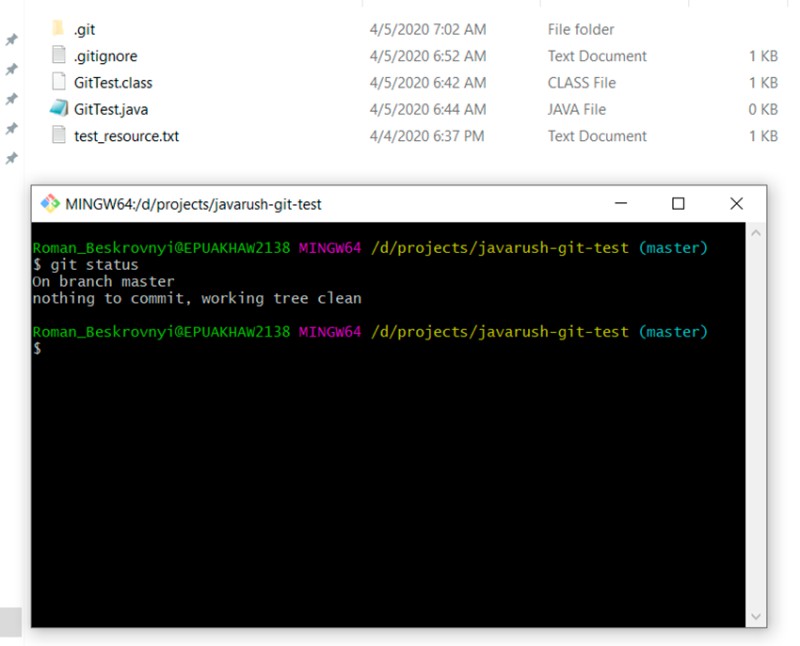 Perfect! .gitignore +1 :)
Perfect! .gitignore +1 :)
Working with branches and such
Naturally, working in just one branch is inconvenient for solitary developers, and it is impossible when there is more than one person on a team. This is why we have branches. As I said earlier, a branch is just a movable pointer to commits. In this part, we'll explore working in different branches: how to merge changes from one branch into another, what conflicts may arise, and much more. To see a list of all branches in the repository and understand which one you are in, you need to write:
git branch -a
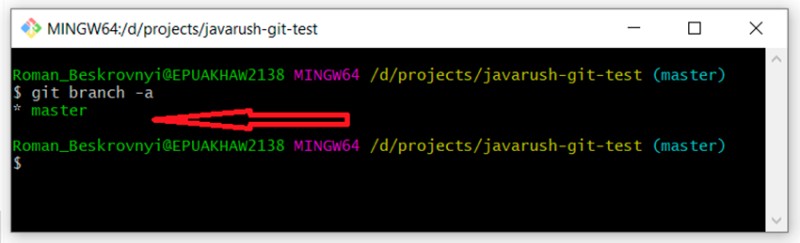 You can see that we only have one master branch. The asterisk in front of it indicates that we are in it. By the way, you can also use the "git status" command to find out which branch we are in.
Then there are several options for creating branches (there may be more — these are the ones that I use):
You can see that we only have one master branch. The asterisk in front of it indicates that we are in it. By the way, you can also use the "git status" command to find out which branch we are in.
Then there are several options for creating branches (there may be more — these are the ones that I use):
- create a new branch based on the one we are in (99% of cases)
- create a branch based on a specific commit (1% of cases)
Let's create a branch based on a specific commit
We will rely on the commit's unique identifier. To find it, we write:
git log
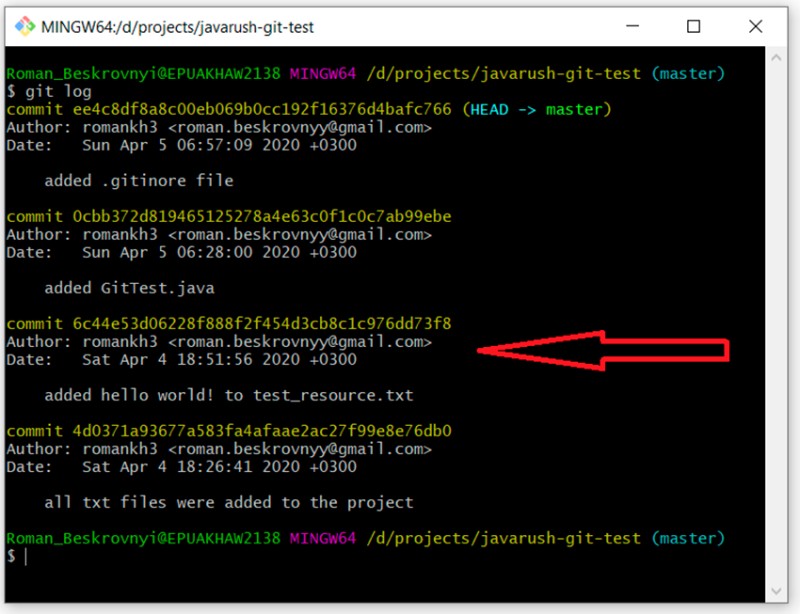 I have highlighted the commit with the comment "added hello world..." Its unique identifier is 6c44e53d06228f888f2f454d3cb8c1c976dd73f8. I want to create a "development" branch that starts from this commit. To do this, I write:
I have highlighted the commit with the comment "added hello world..." Its unique identifier is 6c44e53d06228f888f2f454d3cb8c1c976dd73f8. I want to create a "development" branch that starts from this commit. To do this, I write:
git checkout -b development 6c44e53d06228f888f2f454d3cb8c1c976dd73f8
git status
git log
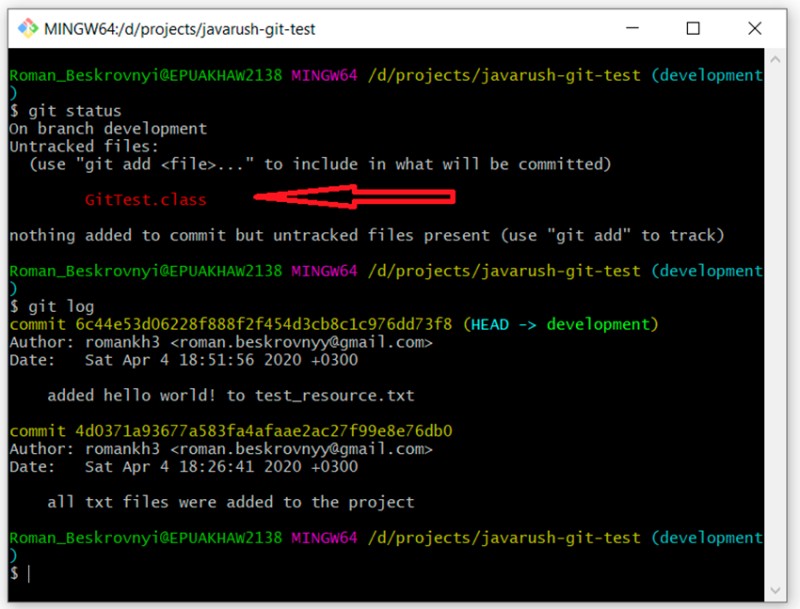 And as expected, we have two commits. By the way, here's an interesting point: there is no .gitignore file in this branch yet, so our compiled file (GitTest.class) is now highlighted with "untracked" status.
Now we can review our branches again by writing this:
And as expected, we have two commits. By the way, here's an interesting point: there is no .gitignore file in this branch yet, so our compiled file (GitTest.class) is now highlighted with "untracked" status.
Now we can review our branches again by writing this:
git branch -a
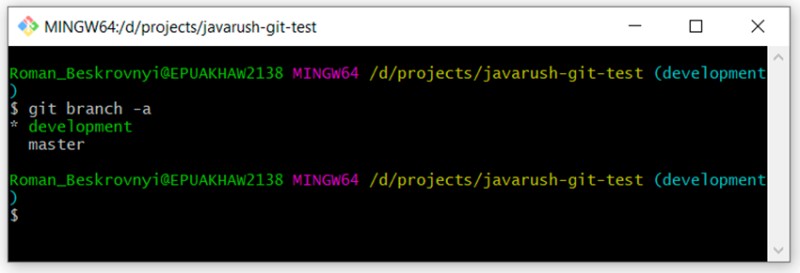 You can see that there are two branches: "master" and "development". We are currently in development.
You can see that there are two branches: "master" and "development". We are currently in development.
Let's create a branch based on the current one
The second way to create a branch is to create it from another. I want to create a branch based on the master branch. First, I need to switch to it, and the next step is to create a new one. Let's take a look:- git checkout master — switch to the master branch
- git status — verify that we are actually in the master branch
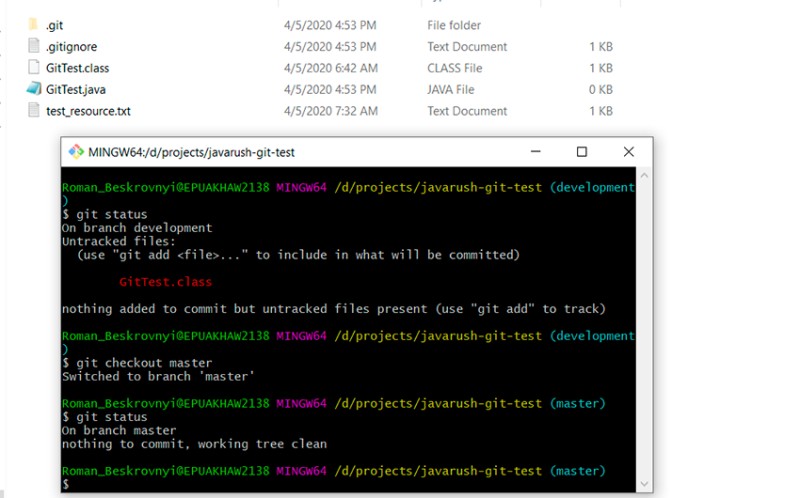 Here you can see that we switched to the master branch, the .gitignore file is in effect, and the compiled class is no longer highlighted as "untracked".
Now we create a new branch based on the master branch:
Here you can see that we switched to the master branch, the .gitignore file is in effect, and the compiled class is no longer highlighted as "untracked".
Now we create a new branch based on the master branch:
git checkout -b feature/update-txt-files
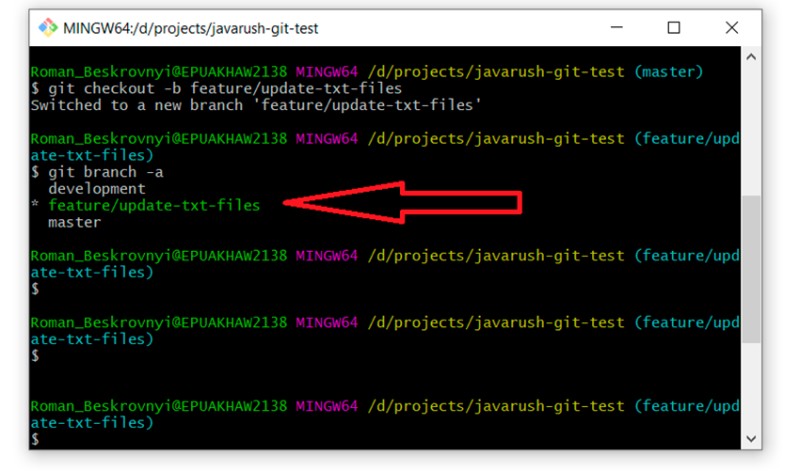 If you are unsure whether this branch is the same as "master", you can easily check by executing "git log" and looking at all the commits. There should be four of them.
If you are unsure whether this branch is the same as "master", you can easily check by executing "git log" and looking at all the commits. There should be four of them.
Conflict resolution
Before we explore what a conflict is, we need to talk about merging one branch into another. This picture depicts the process of merging one branch into another: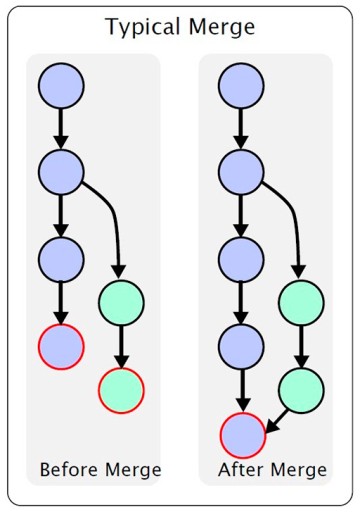 Here, we have a main branch. At some point, a secondary branch is created off of the main branch and then modified. Once the work is done, we need to merge one branch into the other.
I will not describe the various features: In this article, I only want to convey a general understanding. If you need the details, you can look them up yourself.
In our example, we created the feature/update-txt-files branch. As indicated by the name of the branch, we're updating text.
Here, we have a main branch. At some point, a secondary branch is created off of the main branch and then modified. Once the work is done, we need to merge one branch into the other.
I will not describe the various features: In this article, I only want to convey a general understanding. If you need the details, you can look them up yourself.
In our example, we created the feature/update-txt-files branch. As indicated by the name of the branch, we're updating text. 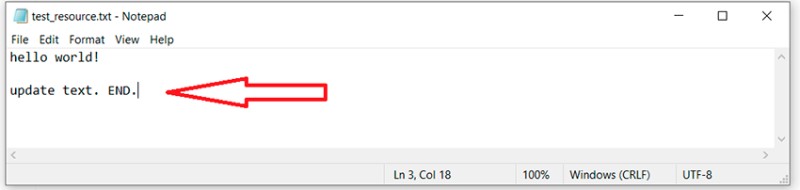 Now we need to create a new commit for this work:
Now we need to create a new commit for this work:
git add *.txt
git commit -m "updated txt files"
git log
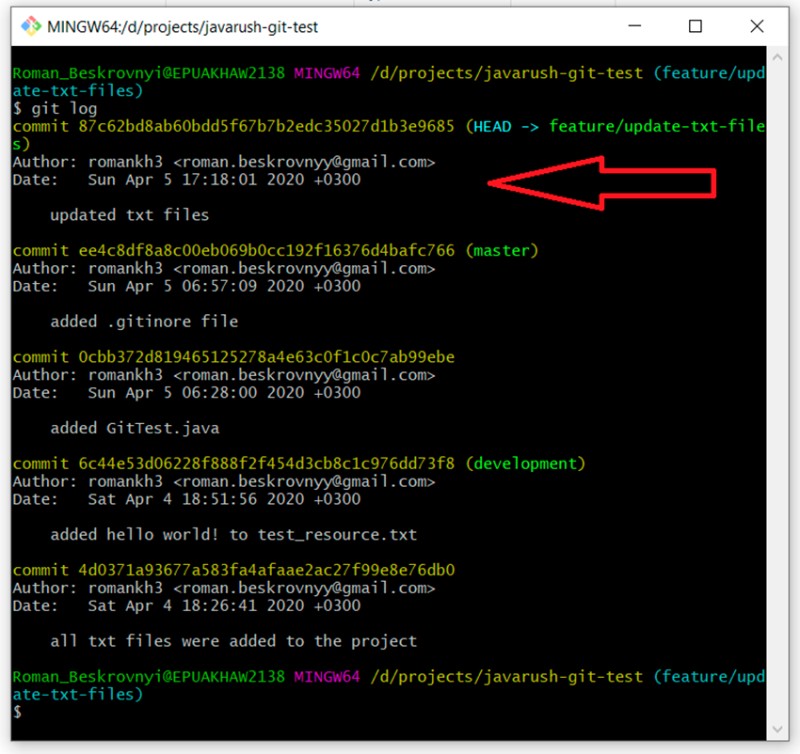 Now, if we want to merge the feature/update-txt-files branch into master, we need to go to master and write "git merge feature/update-txt-files":
Now, if we want to merge the feature/update-txt-files branch into master, we need to go to master and write "git merge feature/update-txt-files":
git checkout master
git merge feature/update-txt-files
git log
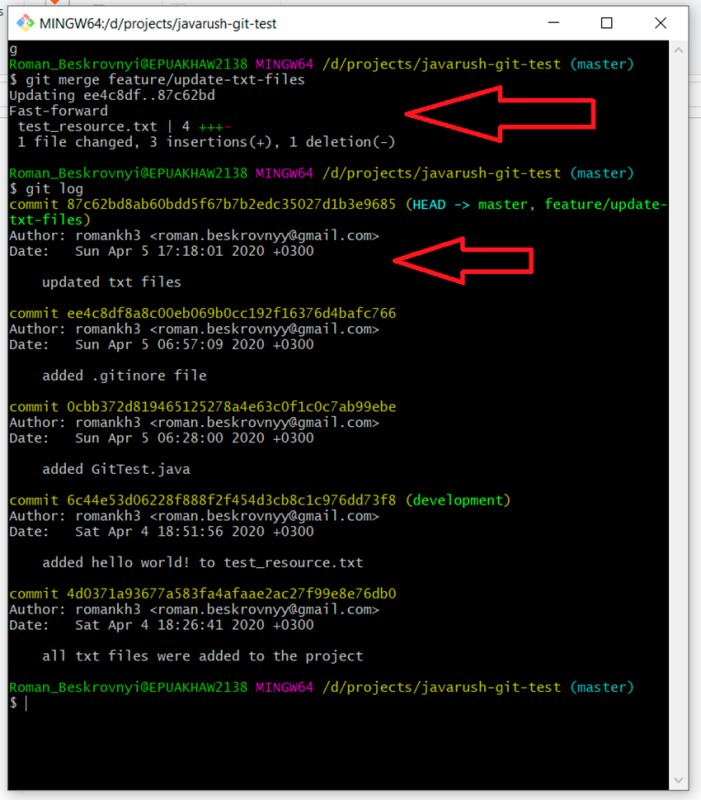 As a result, the master branch now also includes the commit that was added to feature/update-txt-files.
This functionality was added, so you can delete a feature branch. To do this, we write:
As a result, the master branch now also includes the commit that was added to feature/update-txt-files.
This functionality was added, so you can delete a feature branch. To do this, we write:
git branch -D feature/update-txt-files
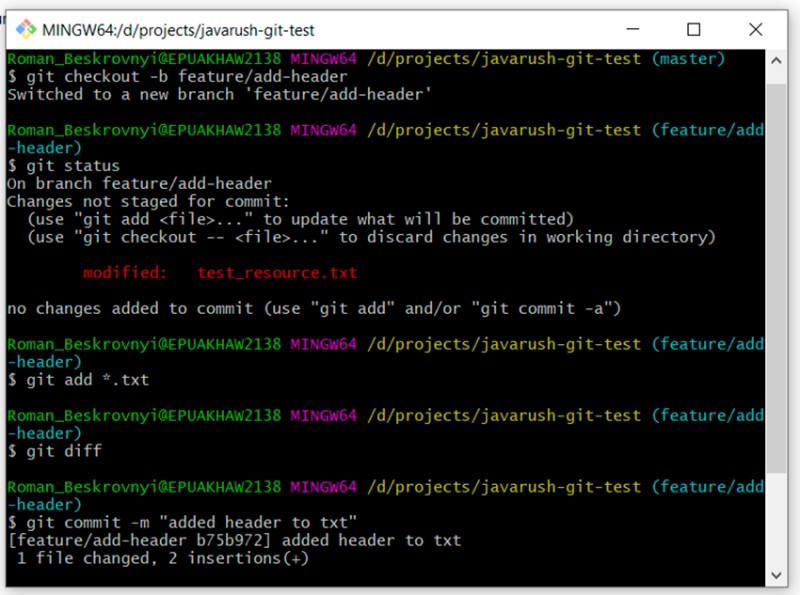
git checkout -b feature/add-header
... we make changes to the file
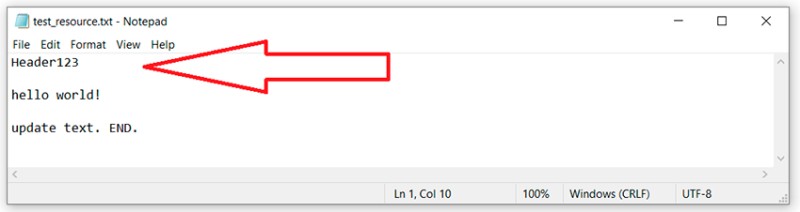
git add *.txt
git commit -m "added header to txt"
 Go to the master branch and also update this text file on the same line as in the feature branch:
Go to the master branch and also update this text file on the same line as in the feature branch:
git checkout master
… we updated test_resource.txt
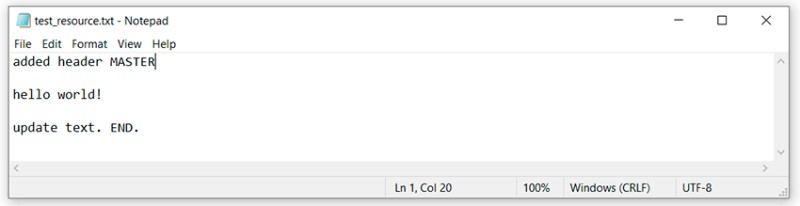
git add test_resource.txt
git commit -m "added master header to txt"
git merge feature/add-header
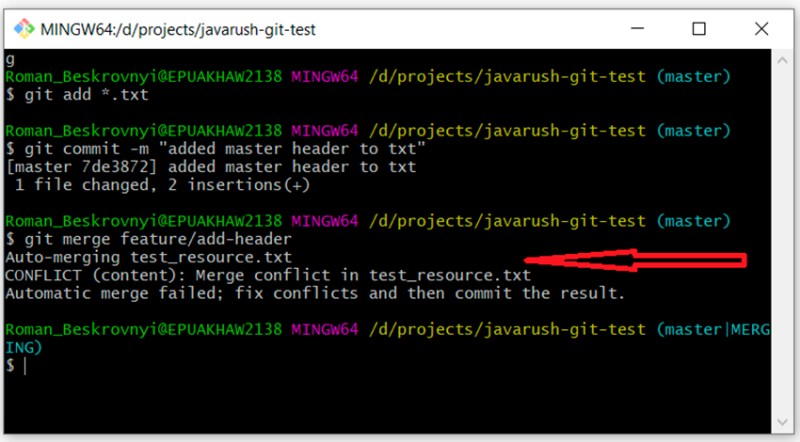 Here we can see that Git could not decide on its own how to merge this code. It tells us that we need to resolve the conflict first, and only then perform the commit.
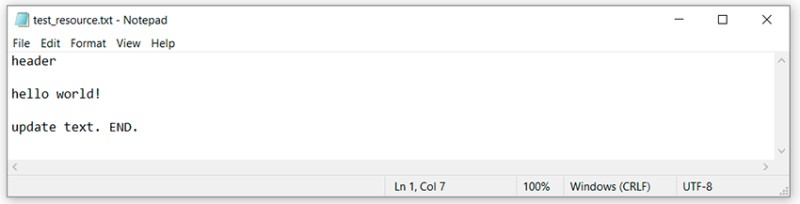
OK. We open the file with the conflict in a text editor and see:
Here we can see that Git could not decide on its own how to merge this code. It tells us that we need to resolve the conflict first, and only then perform the commit.
OK. We open the file with the conflict in a text editor and see: 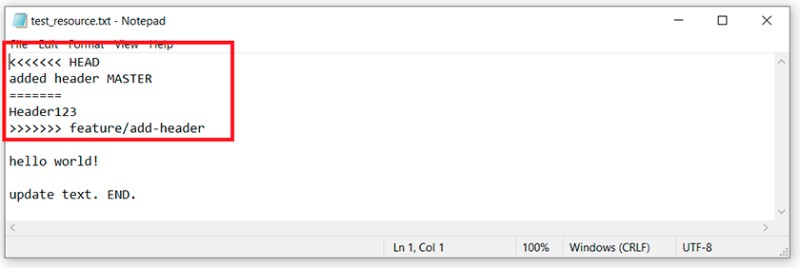 To understand what Git did here, we need to remember which changes we made and where, and then compare:
To understand what Git did here, we need to remember which changes we made and where, and then compare:
- The changes that were on this line in the master branch are found between "<<<<<<< HEAD" and "=======".
- The changes that were in the feature/add-header branch are found between "=======" and ">>>>>>> feature/add-header".

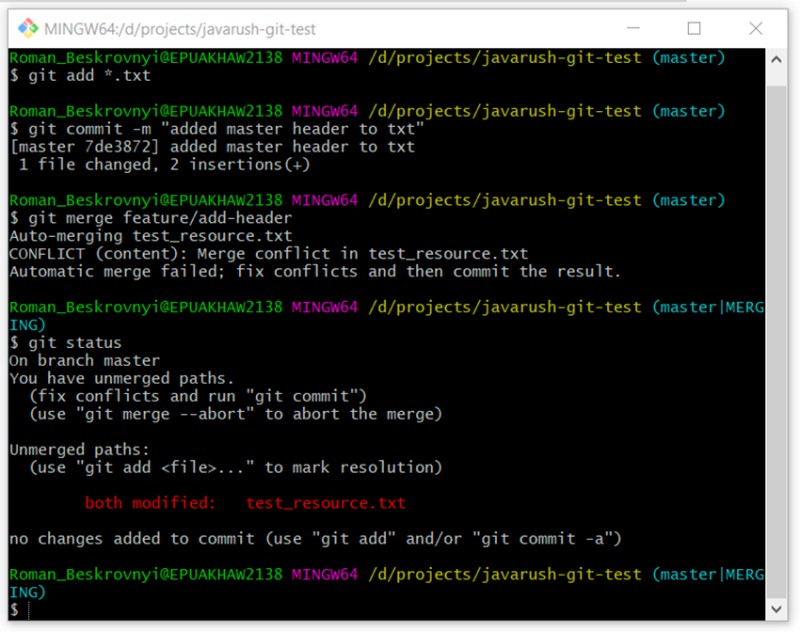
 Let's look at the status of the changes. The description will be slightly different. Rather than a "modified" status, we have "unmerged". So could we have mentioned a fifth status? I don't think this is necessary. Let's see:
Let's look at the status of the changes. The description will be slightly different. Rather than a "modified" status, we have "unmerged". So could we have mentioned a fifth status? I don't think this is necessary. Let's see:
git status
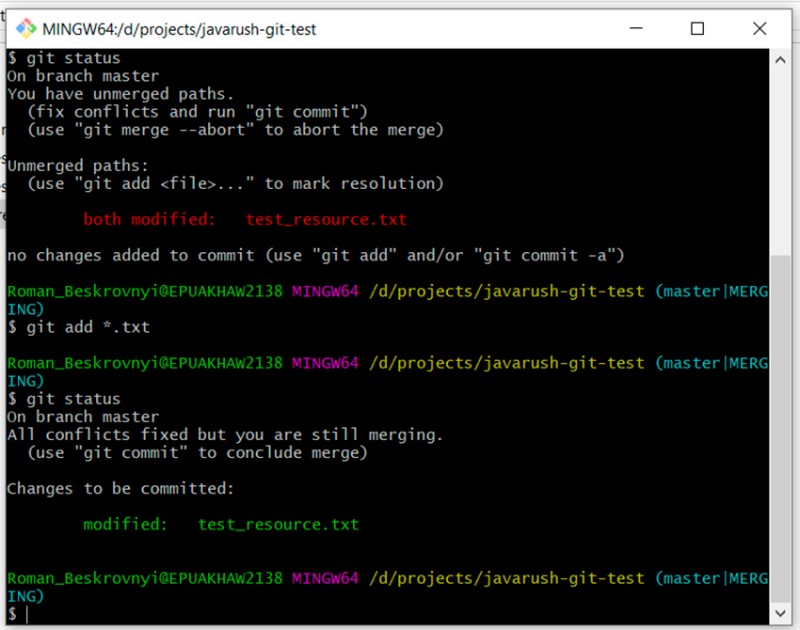
 We can convince ourselves that this is a special, unusual case. Let's continue:
We can convince ourselves that this is a special, unusual case. Let's continue:
git add *.txt
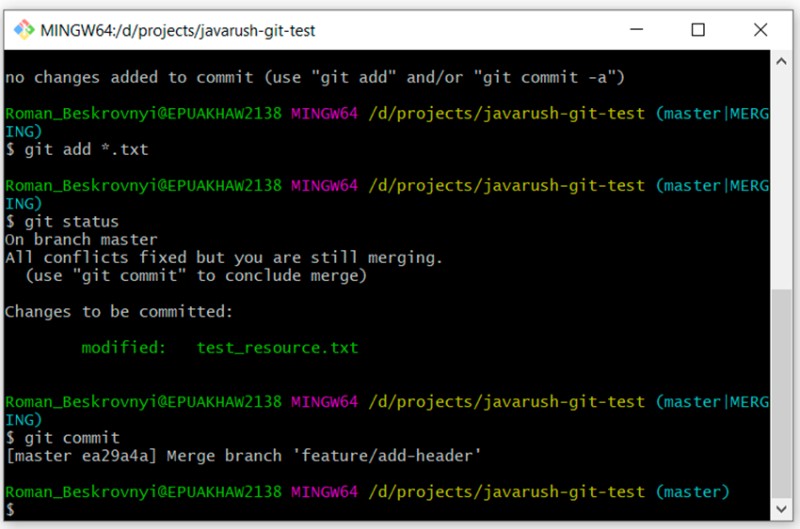
 You may notice that the description suggest writing only "git commit". Let's try writing that:
You may notice that the description suggest writing only "git commit". Let's try writing that:
git commit
 And just like that, we did it — we resolved the conflict in the console.
Of course, this can be done a little easier in integrated development environments. For example, in IntelliJ IDEA, everything is set up so well that you can perform all the necessary actions right within it. But IDEs do a lot of things "under the hood", and we often don't understand what exactly is happening there. And when there is no understanding, problems can arise.
And just like that, we did it — we resolved the conflict in the console.
Of course, this can be done a little easier in integrated development environments. For example, in IntelliJ IDEA, everything is set up so well that you can perform all the necessary actions right within it. But IDEs do a lot of things "under the hood", and we often don't understand what exactly is happening there. And when there is no understanding, problems can arise.
Working with remote repositories
The last step is to figure out a few more commands that are needed to work with the remote repository. As I said, a remote repository is some place where the repository is stored and from which you can clone it. What kind of remote repositories are there? Examples:GitHub is the largest storage platform for repositories and collaborative development. I have already described it in previous articles.
Follow me on GitHub. I often show off my work there in those areas that I am studying for work.GitLab is a web-based tool for the DevOps lifecycle with open source. It is a Git-based system for managing code repositories with its own wiki, bug tracking system, CI/CD pipeline, and other functions.
After the news that Microsoft bought GitHub, some developers duplicated their projects in GitLab.BitBucket is a web service for project hosting and collaborative development based on the Mercurial and Git version control systems. At one time it had a big advantage over GitHub in that it offered free private repositories. Last year, GitHub also introduced this capability to everyone for free.
And so on…
git clone https://github.com/romankh3/git-demo
git pull
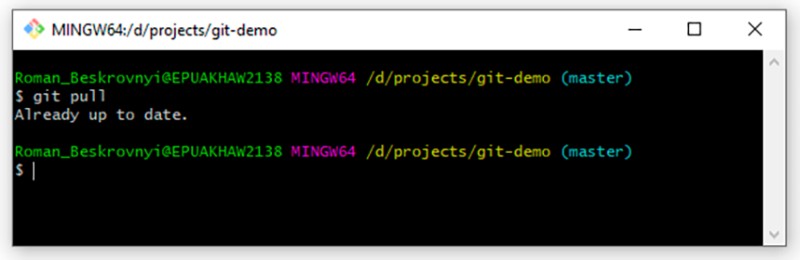 In our case, nothing in the remote repository has changed at present, so the response is: Already up to date. But if I make any changes to the remote repository, the local one is updated after we pull them. And finally, the last command is to push the data to the remote repository. When we have done something locally and want to send it to the remote repository, we must first create a new commit locally. To demonstrate this, let's add something else to our text file:
In our case, nothing in the remote repository has changed at present, so the response is: Already up to date. But if I make any changes to the remote repository, the local one is updated after we pull them. And finally, the last command is to push the data to the remote repository. When we have done something locally and want to send it to the remote repository, we must first create a new commit locally. To demonstrate this, let's add something else to our text file: 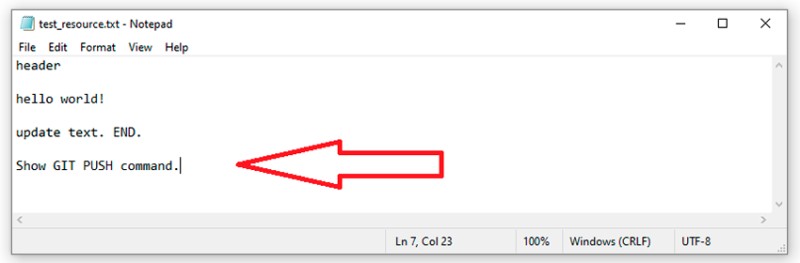 Now something quite common for us — we create a commit for this work:
Now something quite common for us — we create a commit for this work:
git add test_resource.txt
git commit -m "prepared txt for pushing"
git push
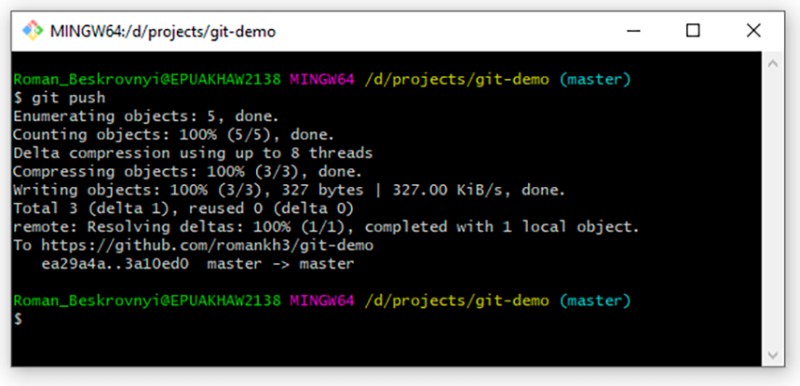 Well, that's all I wanted to say. Thanks for your attention.
Follow me on GitHub, where I post various cool example projects related to my personal study and work.
Well, that's all I wanted to say. Thanks for your attention.
Follow me on GitHub, where I post various cool example projects related to my personal study and work.
Useful link
- Official Git documentation. I recommend it as a reference.
GO TO FULL VERSION