Em vez de uma introdução
Olá! Hoje vamos falar sobre um sistema de controle de versão, chamado Git. Você não tem nada a ver com programação se não conhece/entende o Git. Mas a beleza é que você não precisa manter todos os comandos e recursos do Git em sua cabeça para ser empregado continuamente. Você precisa conhecer um conjunto de comandos que o ajudarão a entender tudo o que está acontecendo.
Você não tem nada a ver com programação se não conhece/entende o Git. Mas a beleza é que você não precisa manter todos os comandos e recursos do Git em sua cabeça para ser empregado continuamente. Você precisa conhecer um conjunto de comandos que o ajudarão a entender tudo o que está acontecendo.
Noções básicas do Git
Git é um sistema de controle de versão distribuído para nosso código. Por que precisamos disso? Equipes distribuídas precisam de algum tipo de sistema para gerenciar seu trabalho. É necessário rastrear as mudanças que ocorrem ao longo do tempo. Ou seja, precisamos conseguir ver passo a passo quais arquivos foram alterados e como. Isso é especialmente importante quando você está investigando o que mudou no contexto de uma única tarefa, possibilitando a reversão das alterações.Instalando o Git
Vamos instalar o Java em seu computador.Instalando no Windows
Como de costume, você precisa baixar e executar um arquivo exe. Tudo é simples aqui: clique no primeiro link do Google , faça a instalação e pronto. Para fazer isso, usaremos o console bash fornecido pelo Windows. No Windows, você precisa executar o Git Bash. Veja como fica no Menu Iniciar: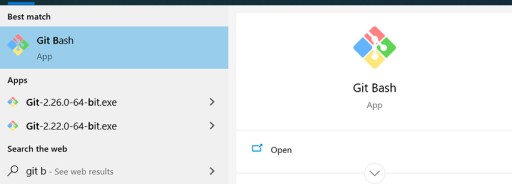 Este é um prompt de comando com o qual você pode trabalhar. Para evitar ter que ir para a pasta com o projeto toda vez para abrir o Git lá, você pode abrir o prompt de comando na pasta do projeto com o botão direito do mouse com o caminho que precisamos:
Este é um prompt de comando com o qual você pode trabalhar. Para evitar ter que ir para a pasta com o projeto toda vez para abrir o Git lá, você pode abrir o prompt de comando na pasta do projeto com o botão direito do mouse com o caminho que precisamos: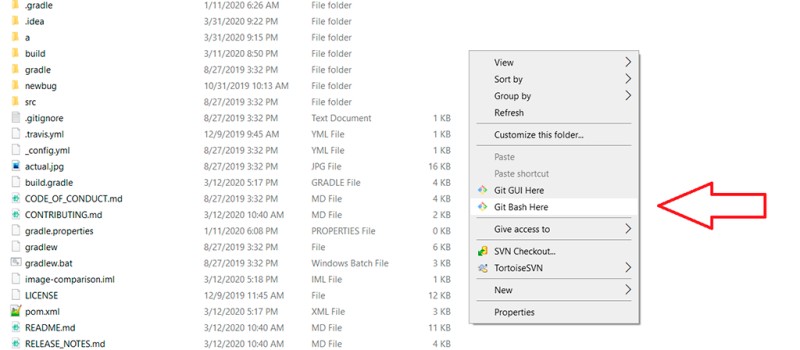
Instalando no Linux
Normalmente o Git faz parte das distribuições do Linux e já vem instalado, pois é uma ferramenta originalmente escrita para o desenvolvimento do kernel do Linux. Mas há situações em que não é. Para verificar, você precisa abrir um terminal e escrever: git --version. Se você obtiver uma resposta inteligível, nada precisará ser instalado. Abra um terminal e instale o Git no Ubuntu . Estou trabalhando no Ubuntu, então posso dizer o que escrever para ele: sudo apt-get install git.Instalando no macOS
Aqui também, primeiro você precisa verificar se o Git já está lá. Se você não o possui, a maneira mais fácil de obtê-lo é fazer o download da versão mais recente aqui . Se o Xcode estiver instalado, o Git definitivamente será instalado automaticamente.Configurações do Git
O Git possui configurações de usuário para o usuário que enviará o trabalho. Isso faz sentido e é necessário, pois o Git leva essas informações para o campo Autor quando um commit é criado. Configure um nome de usuário e senha para todos os seus projetos executando os seguintes comandos:
git config --global user.name "Ivan Ivanov"
git config --global user.email ivan.ivanov@gmail.com
git config user.name "Ivan Ivanov"
git config user.email ivan.ivanov@gmail.com
Um pouco de teoria...
Para mergulhar no assunto, devemos apresentá-lo a algumas novas palavras e ações...- repositório git
- comprometer-se
- filial
- fundir
- conflitos
- puxar
- empurrar
- como ignorar alguns arquivos (.gitignore)
Status no Git
O Git possui várias estátuas que precisam ser compreendidas e lembradas:- não rastreado
- modificado
- encenado
- empenhado
Como você deve entender isso?
Estes são os status que se aplicam aos arquivos que contêm nosso código:- Um arquivo criado, mas ainda não adicionado ao repositório, tem o status "não rastreado".
- Quando fazemos alterações em arquivos que já foram adicionados ao repositório Git, seu status é "modificado".
- Entre os arquivos que alteramos, selecionamos os de que precisamos e essas classes são alteradas para o status "encenado".
- Um commit é criado a partir de arquivos preparados no estado preparado e vai para o repositório Git. Depois disso, não há arquivos com o status "encenado". Mas ainda pode haver arquivos cujo status é "modificado".
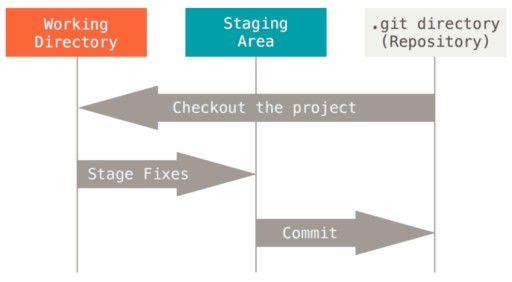
O que é um commit?
Um commit é o evento principal quando se trata de controle de versão. Ele contém todas as alterações feitas desde o início do commit. Os commits são vinculados como uma lista vinculada individualmente. Mais especificamente: há um primeiro commit. Quando o segundo commit é criado, ele sabe o que vem depois do primeiro. E desta forma, as informações podem ser rastreadas. Um commit também tem suas próprias informações, os chamados metadados:
- o identificador exclusivo do commit, que pode ser usado para encontrá-lo
- o nome do autor do commit, que o criou
- a data em que o commit foi criado
- um comentário que descreve o que foi feito durante o commit
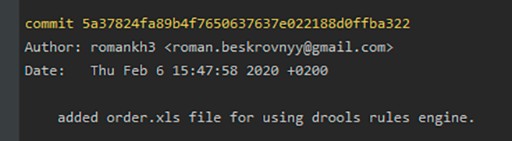
O que é um ramo?
Um branch é um ponteiro para algum commit. Como um commit sabe qual commit o precede, quando um branch aponta para um commit, todos os commits anteriores também se aplicam a ele. Assim, podemos dizer que você pode ter quantas ramificações quiser apontando para o mesmo commit. O trabalho acontece em branches, então quando um novo commit é criado, o branch move seu ponteiro para o commit mais recente.Introdução ao Git
Você pode trabalhar apenas com um repositório local ou remoto. Para praticar os comandos necessários, você pode limitar-se ao repositório local. Ele apenas armazena todas as informações do projeto localmente na pasta .git. Se estivermos falando sobre o repositório remoto, todas as informações são armazenadas em algum lugar no servidor remoto: apenas uma cópia do projeto é armazenada localmente. As alterações feitas em sua cópia local podem ser enviadas (git push) para o repositório remoto. Em nossa discussão aqui e abaixo, estamos falando sobre como trabalhar com o Git no console. Claro, você pode usar algum tipo de solução baseada em GUI (por exemplo, IntelliJ IDEA), mas primeiro você deve descobrir quais comandos estão sendo executados e o que eles significam.Trabalhando com Git em um repositório local
Em seguida, sugiro que você siga e execute todas as etapas que fiz ao ler o artigo. Isso melhorará sua compreensão e domínio do material. Bem, bom apetite! :) Para criar um repositório local, você precisa escrever:
git init
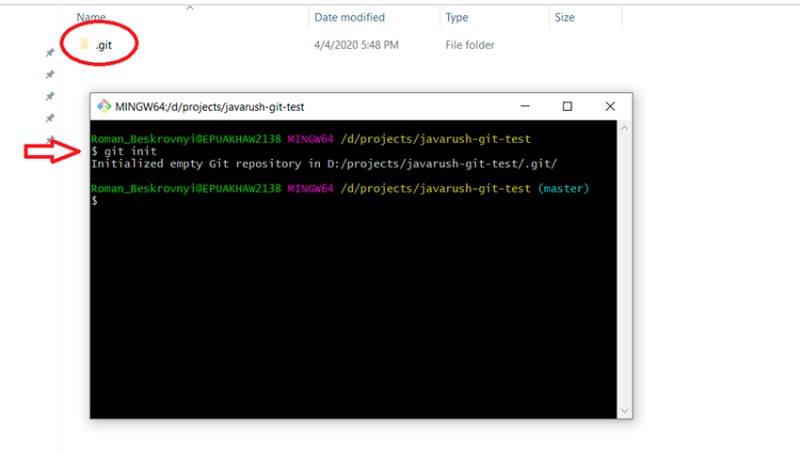 Isso criará uma pasta .git no diretório atual do console. A pasta .git armazena todas as informações sobre o repositório Git. Não exclua ;) Em seguida, os arquivos são adicionados ao projeto e recebem o status "Não rastreado". Para verificar o status atual do seu trabalho, escreva isto:
Isso criará uma pasta .git no diretório atual do console. A pasta .git armazena todas as informações sobre o repositório Git. Não exclua ;) Em seguida, os arquivos são adicionados ao projeto e recebem o status "Não rastreado". Para verificar o status atual do seu trabalho, escreva isto:
git status
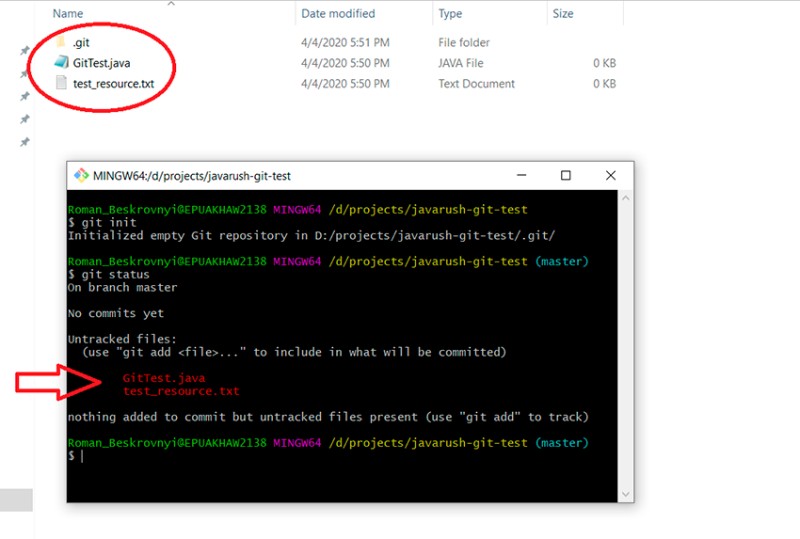 Estamos no branch master, e aqui permaneceremos até mudarmos para outro branch. Isso mostra quais arquivos foram alterados, mas ainda não foram adicionados ao status "preparado". Para adicioná-los ao status "encenado", você precisa escrever "git add". Temos algumas opções aqui, por exemplo:
Estamos no branch master, e aqui permaneceremos até mudarmos para outro branch. Isso mostra quais arquivos foram alterados, mas ainda não foram adicionados ao status "preparado". Para adicioná-los ao status "encenado", você precisa escrever "git add". Temos algumas opções aqui, por exemplo:
- git add -A — adiciona todos os arquivos ao status "encenado"
- adicionar git. — adicione todos os arquivos desta pasta e todas as subpastas. Essencialmente, este é o mesmo que o anterior
- git add <nome do arquivo> — adiciona um arquivo específico. Aqui você pode usar expressões regulares para adicionar arquivos de acordo com algum padrão. Por exemplo, git add *.java: Isso significa que você só deseja adicionar arquivos com a extensão java.
git add *.txt
git status
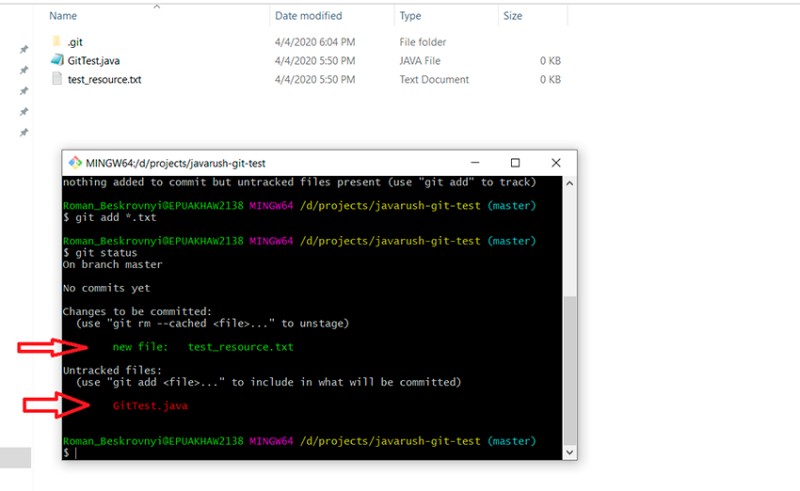 Aqui você pode ver que a expressão regular funcionou corretamente: test_resource.txt agora tem o status "staged". E, finalmente, a última etapa para trabalhar com um repositório local (há mais uma ao trabalhar com o repositório remoto ;)) — criar um novo commit:
Aqui você pode ver que a expressão regular funcionou corretamente: test_resource.txt agora tem o status "staged". E, finalmente, a última etapa para trabalhar com um repositório local (há mais uma ao trabalhar com o repositório remoto ;)) — criar um novo commit:
git commit -m "all txt files were added to the project"
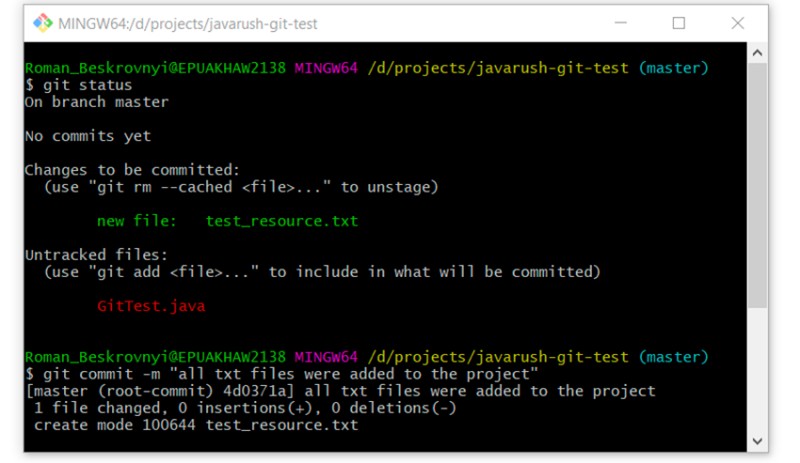 O próximo é um ótimo comando para olhar o histórico de commits em um branch. Vamos aproveitá-lo:
O próximo é um ótimo comando para olhar o histórico de commits em um branch. Vamos aproveitá-lo:
git log
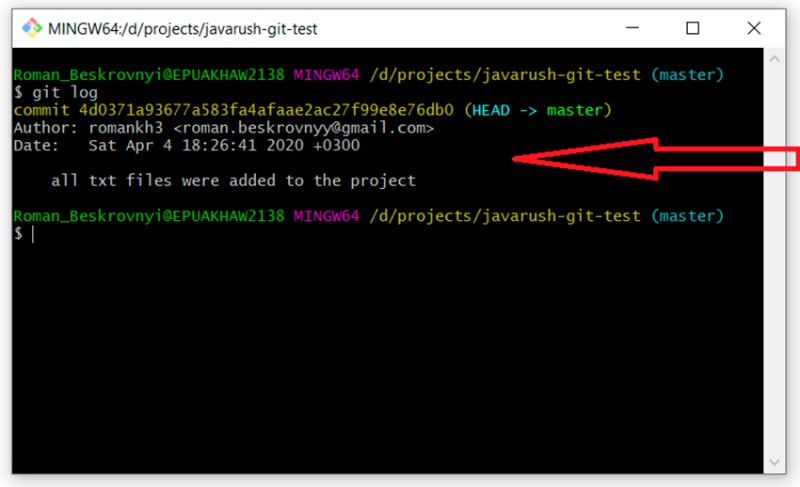 Aqui você pode ver que criamos nosso primeiro commit e inclui o texto que fornecemos na linha de comando. É muito importante entender que este texto deve explicar com a maior precisão possível o que foi feito durante este commit. Isso nos ajudará muitas vezes no futuro. Um leitor curioso que ainda não dormiu pode estar se perguntando o que aconteceu com o arquivo GitTest.java. Vamos descobrir agora. Para fazer isso, usamos:
Aqui você pode ver que criamos nosso primeiro commit e inclui o texto que fornecemos na linha de comando. É muito importante entender que este texto deve explicar com a maior precisão possível o que foi feito durante este commit. Isso nos ajudará muitas vezes no futuro. Um leitor curioso que ainda não dormiu pode estar se perguntando o que aconteceu com o arquivo GitTest.java. Vamos descobrir agora. Para fazer isso, usamos:
git status
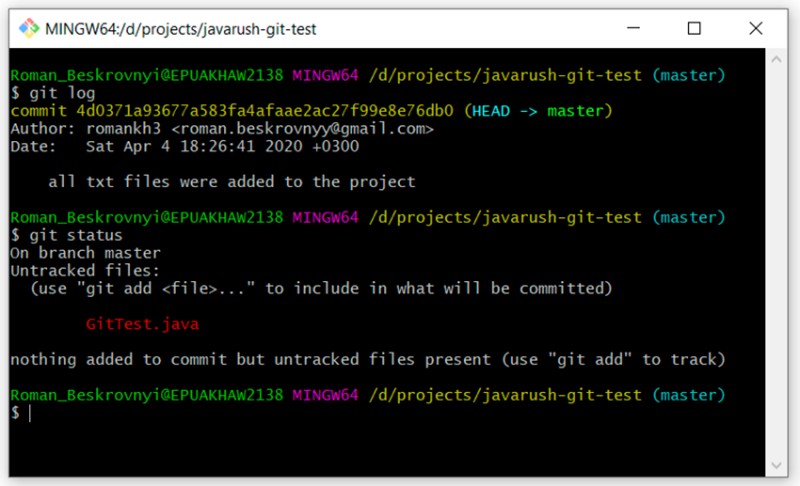 Como você pode ver, ainda está "não rastreado" e está esperando nos bastidores. Mas e se não quisermos adicioná-lo ao projeto? Às vezes isso acontece. Para tornar as coisas mais interessantes, vamos agora tentar alterar nosso arquivo test_resource.txt. Vamos adicionar algum texto lá e verificar o status:
Como você pode ver, ainda está "não rastreado" e está esperando nos bastidores. Mas e se não quisermos adicioná-lo ao projeto? Às vezes isso acontece. Para tornar as coisas mais interessantes, vamos agora tentar alterar nosso arquivo test_resource.txt. Vamos adicionar algum texto lá e verificar o status:
git status
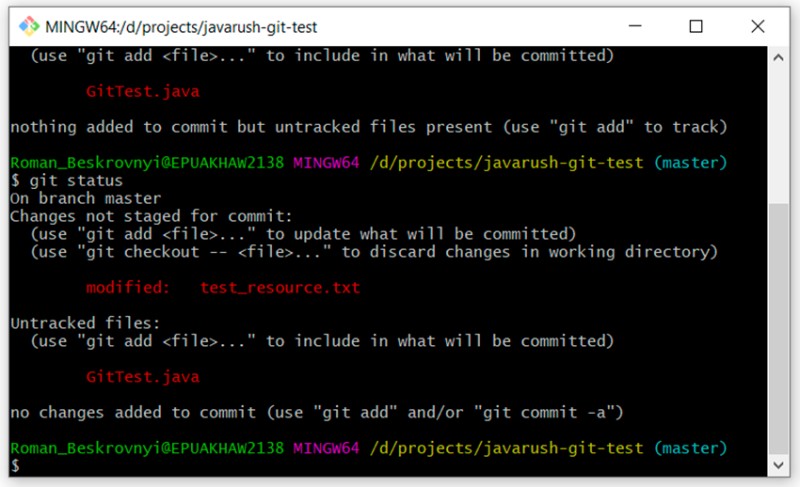 Aqui você pode ver claramente a diferença entre os status "não rastreado" e "modificado". GitTest.java é "não rastreado", enquanto test_resource.txt é "modificado". Agora que temos os arquivos no estado modificado, podemos examinar as alterações feitas neles. Isso pode ser feito usando o seguinte comando:
Aqui você pode ver claramente a diferença entre os status "não rastreado" e "modificado". GitTest.java é "não rastreado", enquanto test_resource.txt é "modificado". Agora que temos os arquivos no estado modificado, podemos examinar as alterações feitas neles. Isso pode ser feito usando o seguinte comando:
git diff
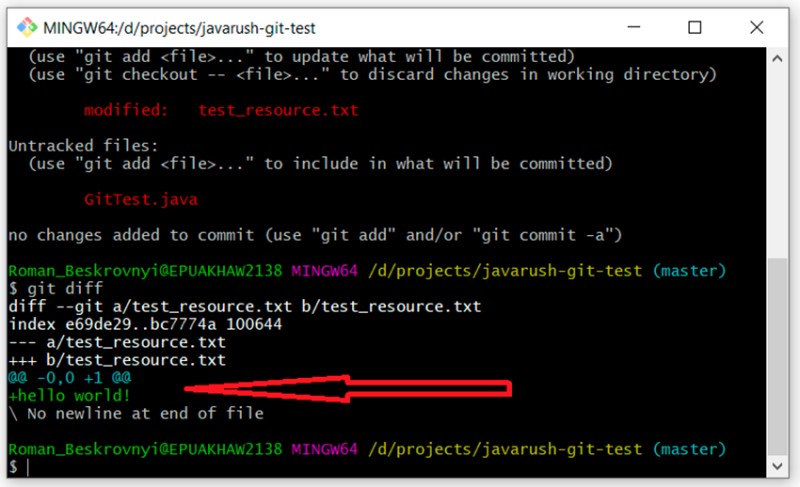 Ou seja, você pode ver claramente aqui o que adicionei ao nosso arquivo de texto: hello world! Vamos adicionar nossas alterações ao arquivo de texto e criar um commit:
Ou seja, você pode ver claramente aqui o que adicionei ao nosso arquivo de texto: hello world! Vamos adicionar nossas alterações ao arquivo de texto e criar um commit:
git add test_resource.txt
git commit -m "added hello word! to test_resource.txt"
git log
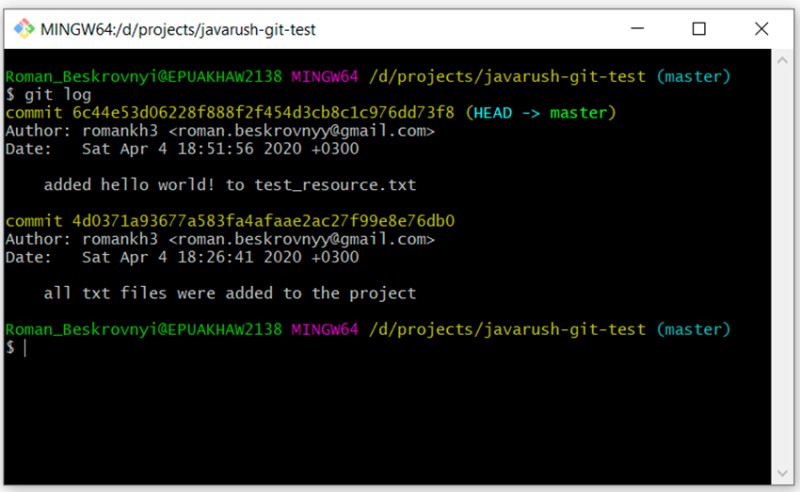 Como você pode ver, agora temos dois commits. Adicionaremos GitTest.java da mesma maneira. Sem comentários aqui, apenas comandos:
Como você pode ver, agora temos dois commits. Adicionaremos GitTest.java da mesma maneira. Sem comentários aqui, apenas comandos:
git add GitTest.java
git commit -m "added GitTest.java"
git status
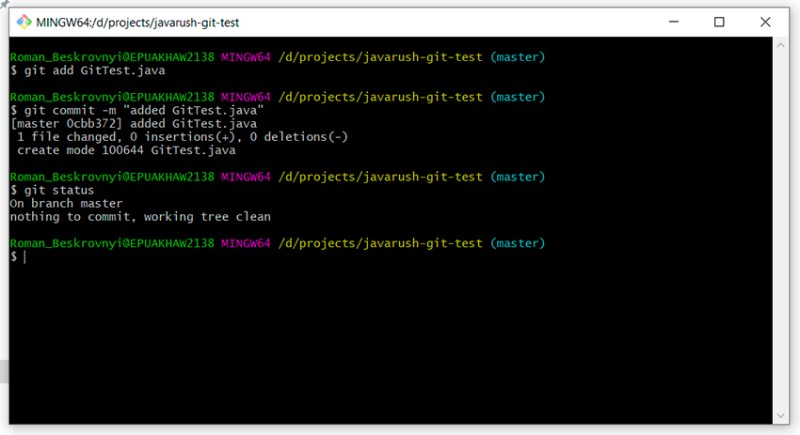
Trabalhando com .gitignore
Claramente, queremos apenas manter o código-fonte sozinho, e nada mais, no repositório. Então, o que mais poderia haver? No mínimo, classes compiladas e/ou arquivos gerados por ambientes de desenvolvimento. Para dizer ao Git para ignorá-los, precisamos criar um arquivo especial. Faça o seguinte: crie um arquivo chamado .gitignore na raiz do projeto. Cada linha neste arquivo representa um padrão a ser ignorado. Neste exemplo, o arquivo .gitignore ficará assim:
```
*.class
target/
*.iml
.idea/
```
- A primeira linha é ignorar todos os arquivos com a extensão .class
- A segunda linha é ignorar a pasta "target" e tudo o que ela contém
- A terceira linha é ignorar todos os arquivos com a extensão .iml
- A quarta linha é ignorar a pasta .idea
git status
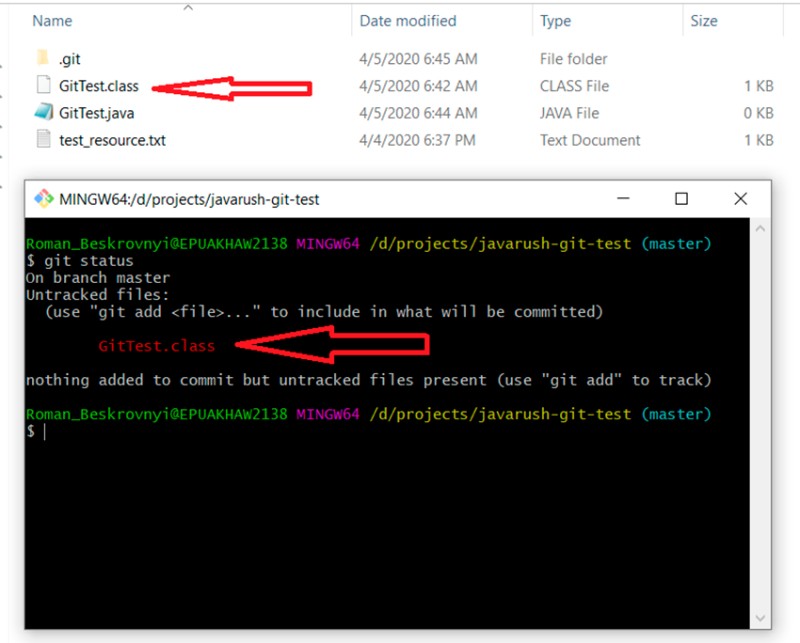 Claramente, não queremos adicionar acidentalmente a classe compilada ao projeto (usando git add -A). Para isso, crie um arquivo .gitignore e adicione tudo o que foi descrito anteriormente:
Claramente, não queremos adicionar acidentalmente a classe compilada ao projeto (usando git add -A). Para isso, crie um arquivo .gitignore e adicione tudo o que foi descrito anteriormente: 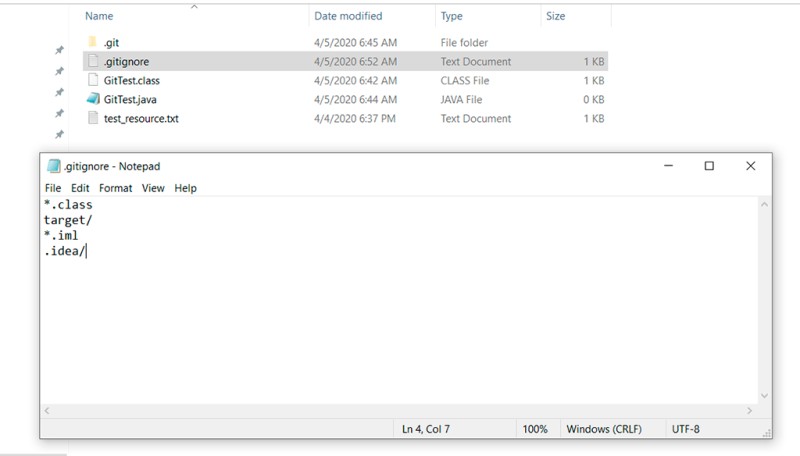 Agora vamos usar um commit para adicionar o arquivo .gitignore ao projeto:
Agora vamos usar um commit para adicionar o arquivo .gitignore ao projeto:
git add .gitignore
git commit -m "added .gitignore file"
git status
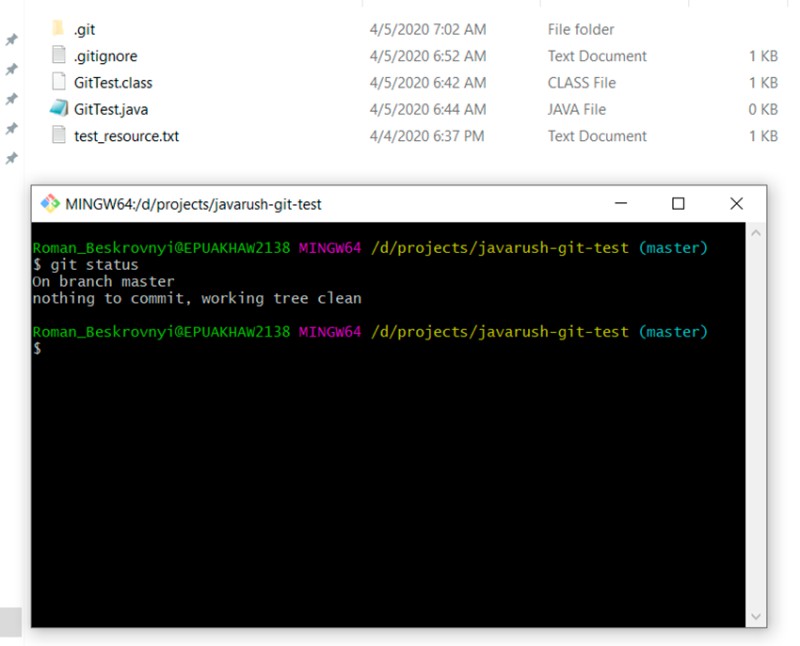 Perfeito! .gitignore +1 :)
Perfeito! .gitignore +1 :)
Trabalhando com filiais e afins
Naturalmente, trabalhar em apenas uma ramificação é inconveniente para desenvolvedores solitários e é impossível quando há mais de uma pessoa em uma equipe. É por isso que temos filiais. Como eu disse anteriormente, um branch é apenas um ponteiro móvel para commits. Nesta parte, exploraremos o trabalho em diferentes branches: como mesclar alterações de um branch em outro, quais conflitos podem surgir e muito mais. Para ver uma lista de todos os branches no repositório e entender em qual deles você está, você precisa escrever:
git branch -a
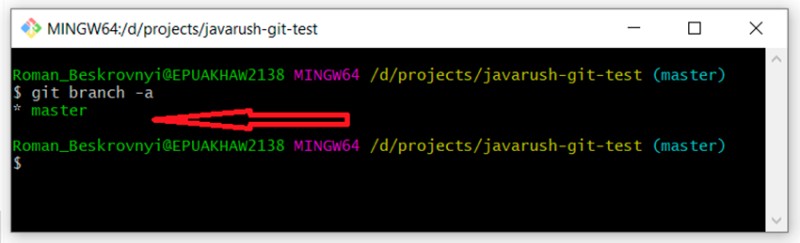 Você pode ver que temos apenas uma ramificação master. O asterisco na frente indica que estamos nele. A propósito, você também pode usar o comando "git status" para descobrir em qual ramificação estamos. Existem várias opções para criar ramificações (pode haver mais - estas são as que eu uso):
Você pode ver que temos apenas uma ramificação master. O asterisco na frente indica que estamos nele. A propósito, você também pode usar o comando "git status" para descobrir em qual ramificação estamos. Existem várias opções para criar ramificações (pode haver mais - estas são as que eu uso):
- criar um novo ramo baseado naquele em que estamos (99% dos casos)
- criar uma ramificação com base em um commit específico (1% dos casos)
Vamos criar um branch baseado em um commit específico
Contaremos com o identificador exclusivo do commit. Para encontrá-lo, escrevemos:
git log
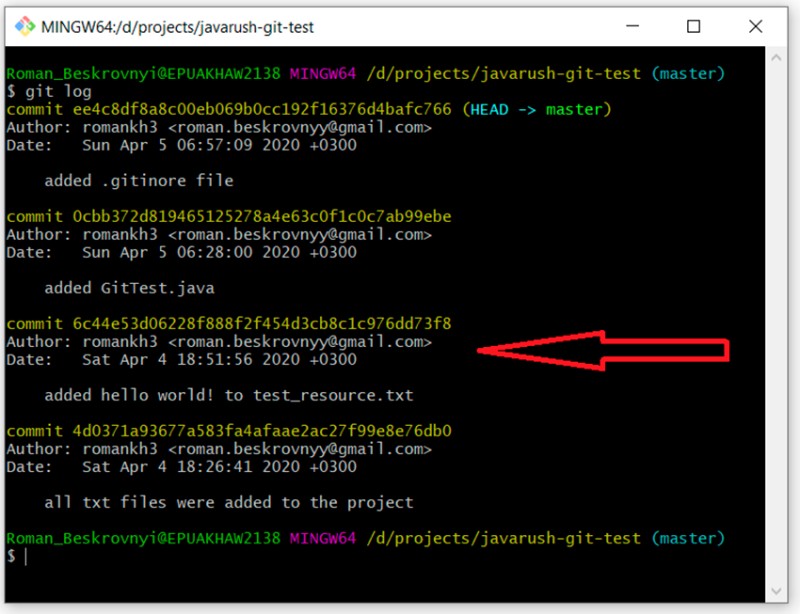 Destaquei o commit com o comentário "added hello world..." Seu identificador único é 6c44e53d06228f888f2f454d3cb8c1c976dd73f8. Eu quero criar uma ramificação de "desenvolvimento" que comece a partir deste commit. Para isso, escrevo:
Destaquei o commit com o comentário "added hello world..." Seu identificador único é 6c44e53d06228f888f2f454d3cb8c1c976dd73f8. Eu quero criar uma ramificação de "desenvolvimento" que comece a partir deste commit. Para isso, escrevo:
git checkout -b development 6c44e53d06228f888f2f454d3cb8c1c976dd73f8
git status
git log
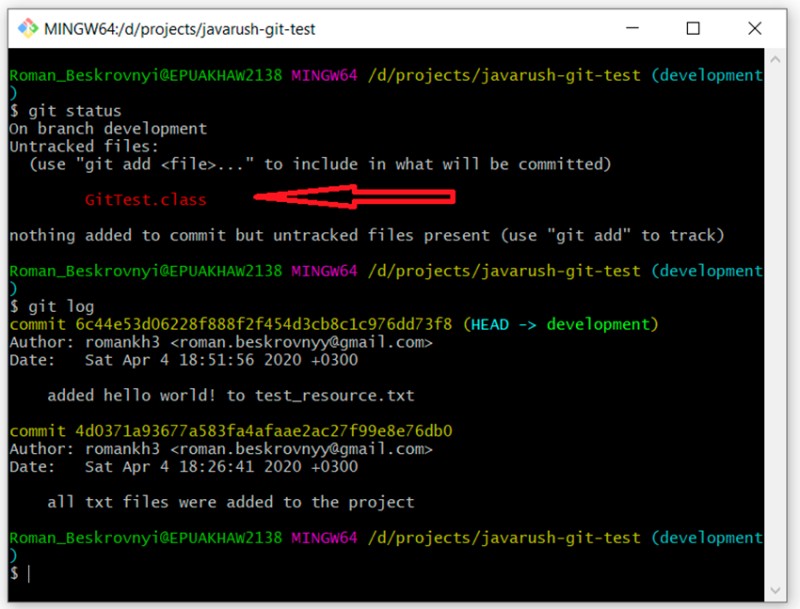 E como esperado, temos dois commits. A propósito, aqui está um ponto interessante: ainda não há nenhum arquivo .gitignore neste branch, então nosso arquivo compilado (GitTest.class) agora está destacado com o status "untracked". Agora podemos revisar nossos ramos novamente escrevendo isto:
E como esperado, temos dois commits. A propósito, aqui está um ponto interessante: ainda não há nenhum arquivo .gitignore neste branch, então nosso arquivo compilado (GitTest.class) agora está destacado com o status "untracked". Agora podemos revisar nossos ramos novamente escrevendo isto:
git branch -a
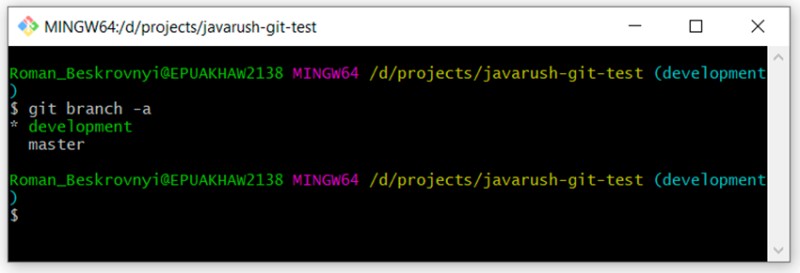 Você pode ver que existem duas ramificações: "mestre" e "desenvolvimento". Estamos atualmente em desenvolvimento.
Você pode ver que existem duas ramificações: "mestre" e "desenvolvimento". Estamos atualmente em desenvolvimento.
Vamos criar um branch baseado no atual
A segunda maneira de criar uma ramificação é criá-la a partir de outra. Eu quero criar um branch baseado no branch master. Primeiro, preciso mudar para ele e o próximo passo é criar um novo. Vamos dar uma olhada:- git checkout master — mude para o branch master
- git status — verifique se estamos realmente na ramificação master
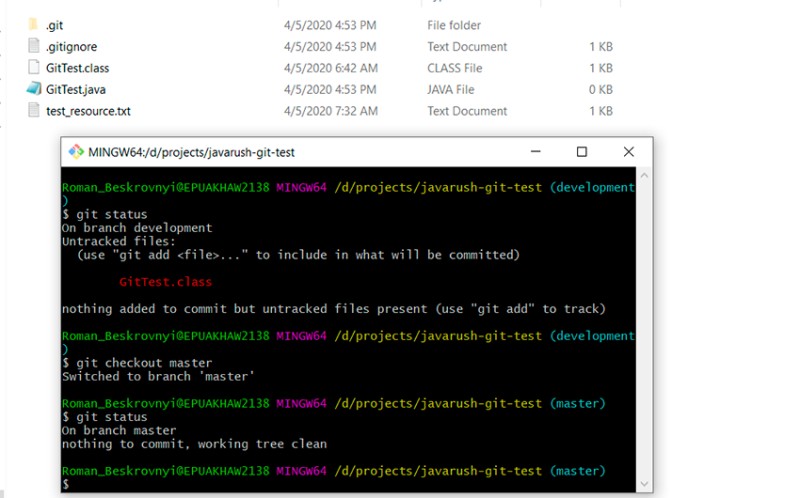 Aqui você pode ver que mudamos para a ramificação master, o arquivo .gitignore está em vigor e a classe compilada não está mais destacada como "não rastreada". Agora criamos um novo branch baseado no branch master:
Aqui você pode ver que mudamos para a ramificação master, o arquivo .gitignore está em vigor e a classe compilada não está mais destacada como "não rastreada". Agora criamos um novo branch baseado no branch master:
git checkout -b feature/update-txt-files
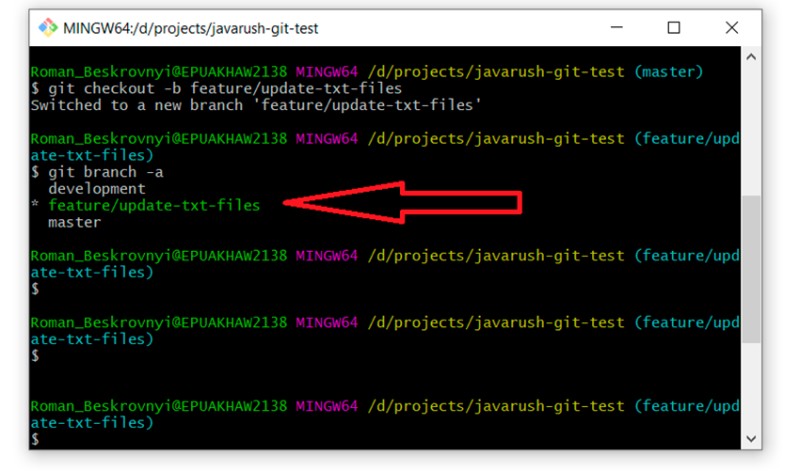 Se você não tem certeza se este branch é o mesmo que "master", você pode verificar facilmente executando "git log" e observando todos os commits. Deve haver quatro deles.
Se você não tem certeza se este branch é o mesmo que "master", você pode verificar facilmente executando "git log" e observando todos os commits. Deve haver quatro deles.
Resolução de conflitos
Antes de explorarmos o que é um conflito, precisamos falar sobre a fusão de um ramo em outro. Esta figura mostra o processo de fusão de uma ramificação em outra: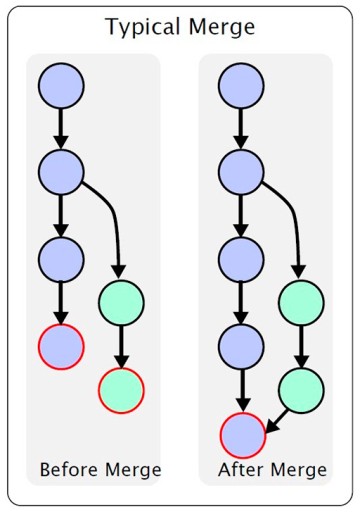 Aqui, temos uma ramificação principal. Em algum momento, uma ramificação secundária é criada a partir da ramificação principal e depois modificada. Depois que o trabalho estiver concluído, precisamos mesclar um ramo no outro. Não vou descrever as várias características: Neste artigo, quero apenas transmitir um entendimento geral. Se precisar dos detalhes, você mesmo pode procurá-los. Em nosso exemplo, criamos o branch feature/update-txt-files. Conforme indicado pelo nome da ramificação, estamos atualizando o texto.
Aqui, temos uma ramificação principal. Em algum momento, uma ramificação secundária é criada a partir da ramificação principal e depois modificada. Depois que o trabalho estiver concluído, precisamos mesclar um ramo no outro. Não vou descrever as várias características: Neste artigo, quero apenas transmitir um entendimento geral. Se precisar dos detalhes, você mesmo pode procurá-los. Em nosso exemplo, criamos o branch feature/update-txt-files. Conforme indicado pelo nome da ramificação, estamos atualizando o texto. 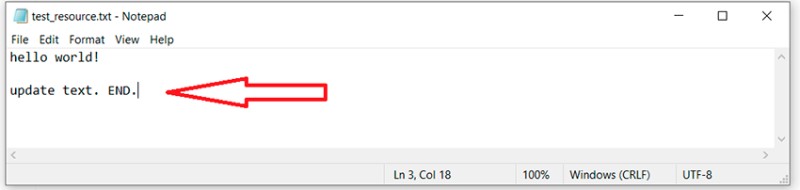 Agora precisamos criar um novo commit para este trabalho:
Agora precisamos criar um novo commit para este trabalho:
git add *.txt
git commit -m "updated txt files"
git log
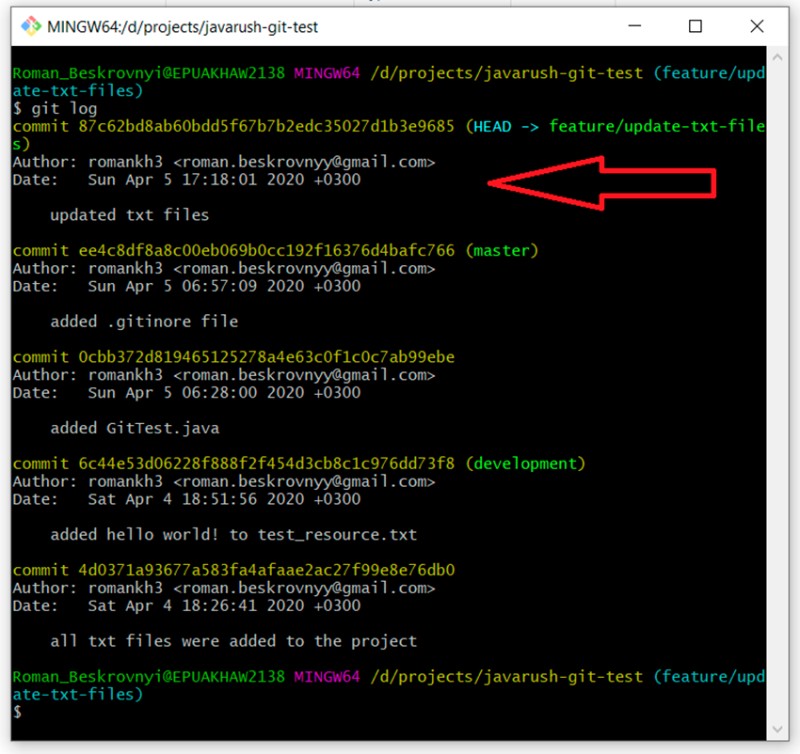 Agora, se quisermos mesclar o branch feature/update-txt-files no master, precisamos ir para master e escrever "git merge feature/update-txt-files":
Agora, se quisermos mesclar o branch feature/update-txt-files no master, precisamos ir para master e escrever "git merge feature/update-txt-files":
git checkout master
git merge feature/update-txt-files
git log
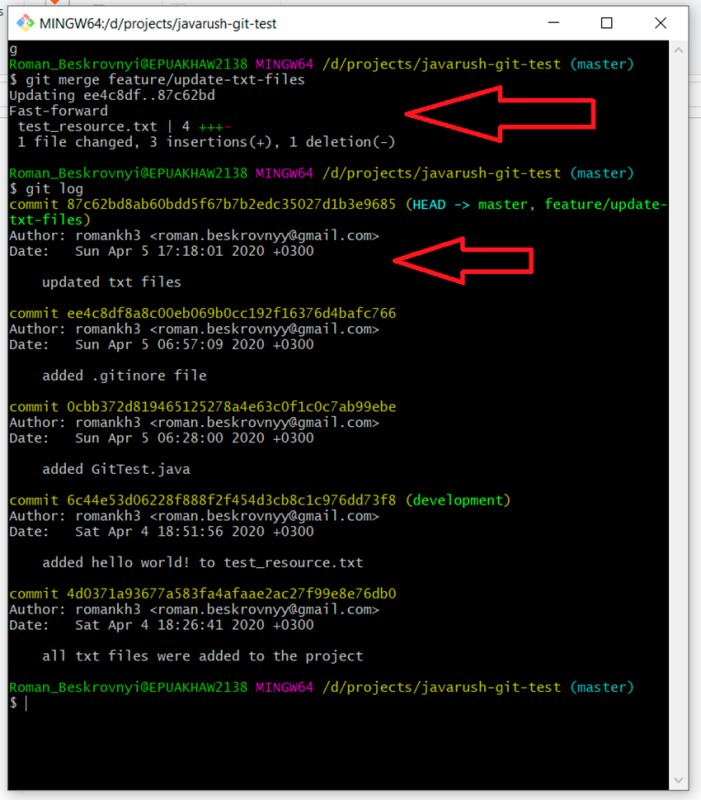 Como resultado, o branch master agora também inclui o commit que foi adicionado aos arquivos feature/update-txt. Essa funcionalidade foi adicionada para que você possa excluir uma ramificação de recurso. Para isso, escrevemos:
Como resultado, o branch master agora também inclui o commit que foi adicionado aos arquivos feature/update-txt. Essa funcionalidade foi adicionada para que você possa excluir uma ramificação de recurso. Para isso, escrevemos:
git branch -D feature/update-txt-files
git checkout -b feature/add-header
... we make changes to the file
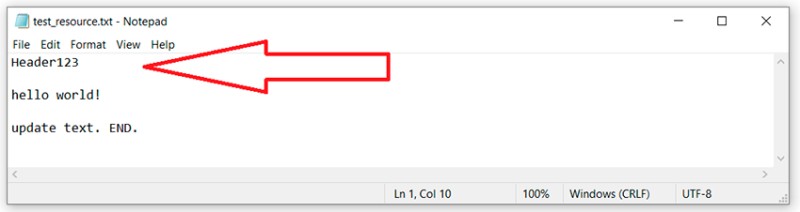
git add *.txt
git commit -m "added header to txt"
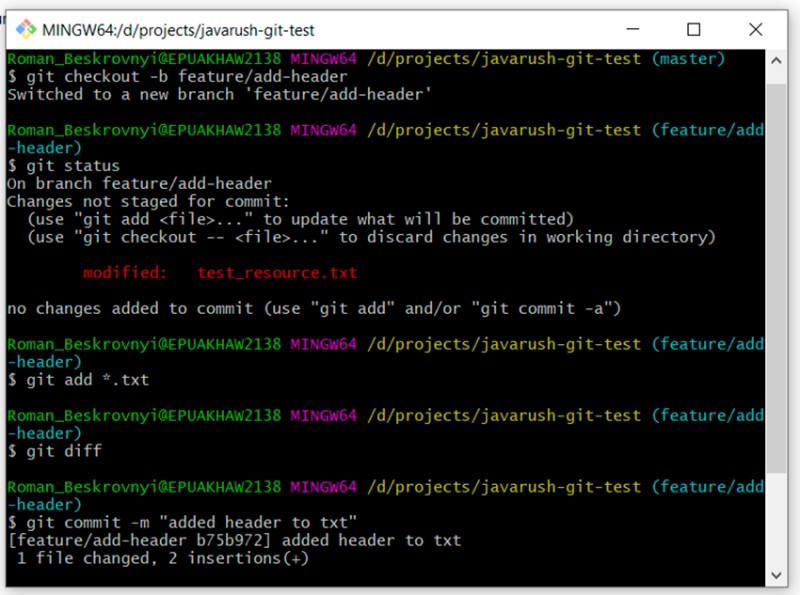 Vá para o branch master e também atualize este arquivo de texto na mesma linha do branch do recurso:
Vá para o branch master e também atualize este arquivo de texto na mesma linha do branch do recurso:
git checkout master
… we updated test_resource.txt
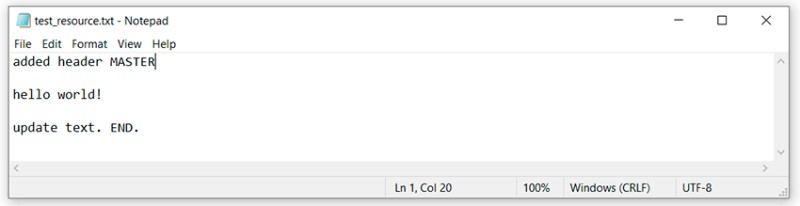
git add test_resource.txt
git commit -m "added master header to txt"
git merge feature/add-header
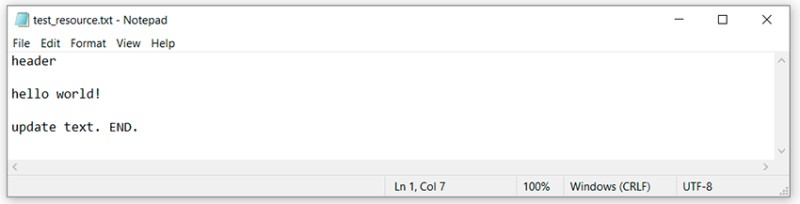
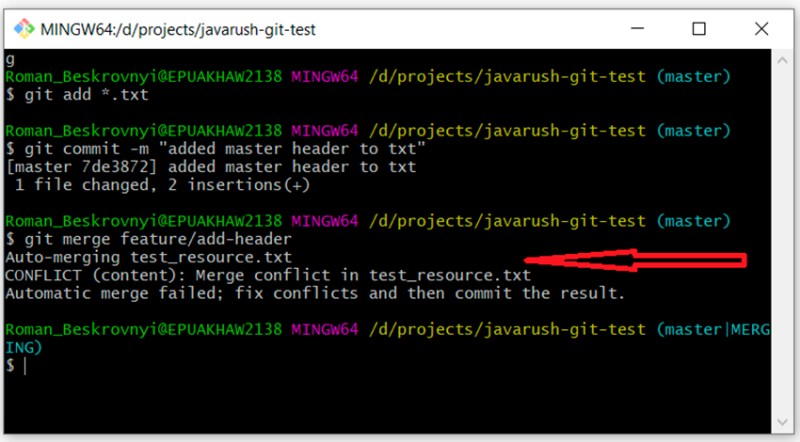 Aqui podemos ver que o Git não conseguiu decidir sozinho como mesclar esse código. Ele nos diz que precisamos resolver o conflito primeiro e só então realizar o commit. OK. Abrimos o arquivo com o conflito em um editor de texto e vemos:
Aqui podemos ver que o Git não conseguiu decidir sozinho como mesclar esse código. Ele nos diz que precisamos resolver o conflito primeiro e só então realizar o commit. OK. Abrimos o arquivo com o conflito em um editor de texto e vemos: 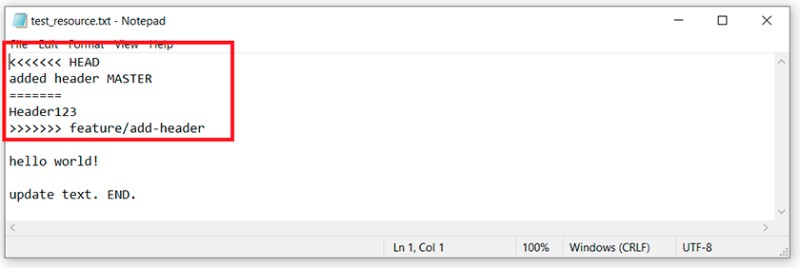 Para entender o que o Git fez aqui, precisamos lembrar quais alterações fizemos e onde, e então comparar:
Para entender o que o Git fez aqui, precisamos lembrar quais alterações fizemos e onde, e então comparar:
- As alterações que estavam nesta linha no branch master são encontradas entre "<<<<<<< HEAD" e "=======".
- As mudanças que estavam na ramificação feature/add-header são encontradas entre "=======" e ">>>>>>> feature/add-header".

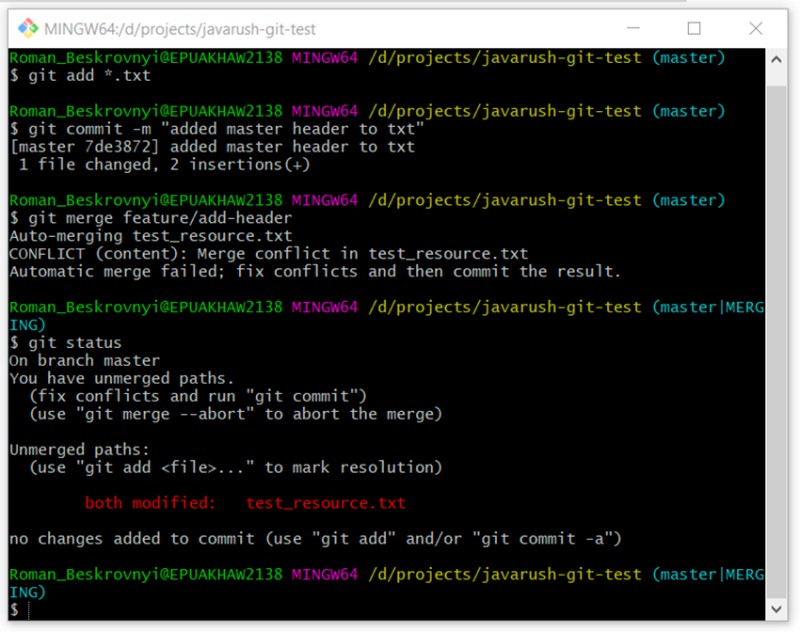
 vamos ver o status das alterações. A descrição será um pouco diferente. Em vez de um status "modificado", temos "não mesclado". Então, poderíamos ter mencionado um quinto status? Eu não acho que isso seja necessário. Vamos ver:
vamos ver o status das alterações. A descrição será um pouco diferente. Em vez de um status "modificado", temos "não mesclado". Então, poderíamos ter mencionado um quinto status? Eu não acho que isso seja necessário. Vamos ver:
git status
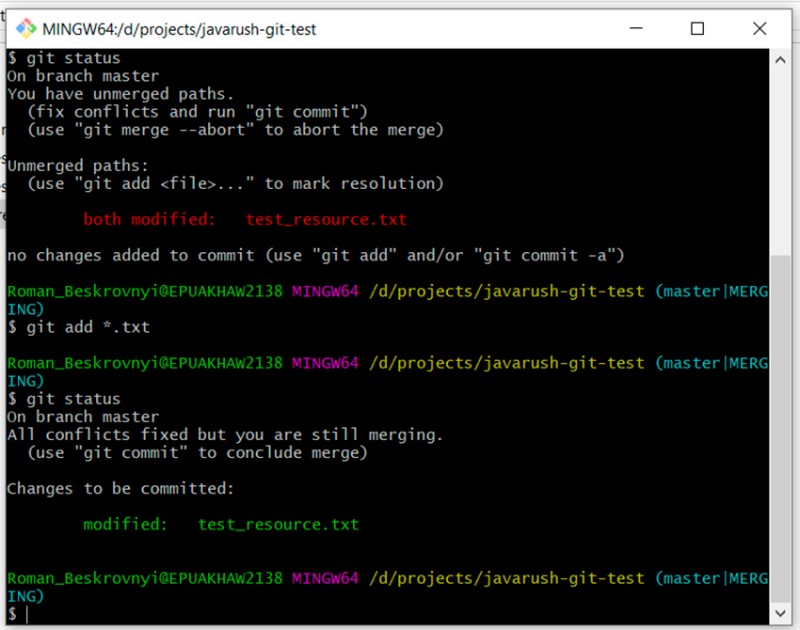
 Podemos nos convencer de que este é um caso especial e incomum. Vamos continuar:
Podemos nos convencer de que este é um caso especial e incomum. Vamos continuar:
git add *.txt
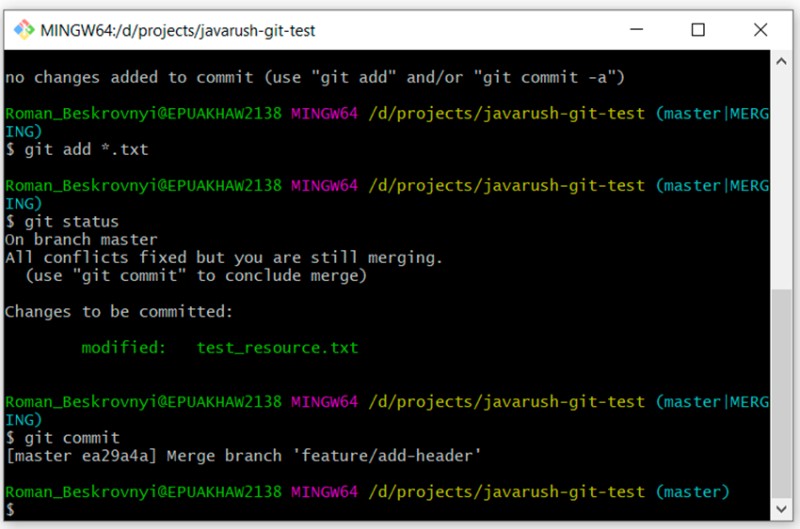
 Você pode notar que a descrição sugere escrever apenas "git commit". Vamos tentar escrever isso:
Você pode notar que a descrição sugere escrever apenas "git commit". Vamos tentar escrever isso:
git commit
 E assim fizemos - resolvemos o conflito no console. Claro, isso pode ser feito um pouco mais facilmente em ambientes de desenvolvimento integrado. Por exemplo, no IntelliJ IDEA, tudo é configurado tão bem que você pode realizar todas as ações necessárias dentro dele. Mas os IDEs fazem muitas coisas "sob o capô" e muitas vezes não entendemos exatamente o que está acontecendo lá. E quando não há compreensão, podem surgir problemas.
E assim fizemos - resolvemos o conflito no console. Claro, isso pode ser feito um pouco mais facilmente em ambientes de desenvolvimento integrado. Por exemplo, no IntelliJ IDEA, tudo é configurado tão bem que você pode realizar todas as ações necessárias dentro dele. Mas os IDEs fazem muitas coisas "sob o capô" e muitas vezes não entendemos exatamente o que está acontecendo lá. E quando não há compreensão, podem surgir problemas.
Trabalhando com repositórios remotos
A última etapa é descobrir mais alguns comandos necessários para trabalhar com o repositório remoto. Como eu disse, um repositório remoto é algum lugar onde o repositório é armazenado e de onde você pode cloná-lo. Que tipo de repositórios remotos existem? Exemplos:-
O GitHub é a maior plataforma de armazenamento para repositórios e desenvolvimento colaborativo. Já o descrevi em artigos anteriores.
Siga-me no GitHub . Costumo mostrar meu trabalho lá nas áreas que estou estudando para trabalhar. -
O GitLab é uma ferramenta baseada na Web para o ciclo de vida do DevOps com código aberto . É um sistema baseado em Git para gerenciar repositórios de código com seu próprio wiki, sistema de rastreamento de bugs , pipeline de CI/CD e outras funções.
Após a notícia de que a Microsoft comprou o GitHub, alguns desenvolvedores duplicaram seus projetos no GitLab. -
BitBucket é um serviço web para hospedagem de projetos e desenvolvimento colaborativo baseado nos sistemas de controle de versão Mercurial e Git. Ao mesmo tempo, ele tinha uma grande vantagem sobre o GitHub, pois oferecia repositórios privados gratuitos. No ano passado, o GitHub também introduziu esse recurso gratuitamente para todos.
-
E assim por diante…
git clone https://github.com/romankh3/git-demo
git pull
 No nosso caso, nada mudou no repositório remoto no momento, então a resposta é: Já atualizado. Mas se eu fizer alguma alteração no repositório remoto, o local é atualizado depois que os extraímos. E, finalmente, o último comando é enviar os dados para o repositório remoto. Quando tivermos feito algo localmente e quisermos enviá-lo para o repositório remoto, devemos primeiro criar um novo commit localmente. Para demonstrar isso, vamos adicionar algo mais ao nosso arquivo de texto:
No nosso caso, nada mudou no repositório remoto no momento, então a resposta é: Já atualizado. Mas se eu fizer alguma alteração no repositório remoto, o local é atualizado depois que os extraímos. E, finalmente, o último comando é enviar os dados para o repositório remoto. Quando tivermos feito algo localmente e quisermos enviá-lo para o repositório remoto, devemos primeiro criar um novo commit localmente. Para demonstrar isso, vamos adicionar algo mais ao nosso arquivo de texto:  Agora algo bastante comum para nós — criamos um commit para este trabalho:
Agora algo bastante comum para nós — criamos um commit para este trabalho:
git add test_resource.txt
git commit -m "prepared txt for pushing"
git push
 Bem, isso é tudo que eu queria dizer. Agradecimentos para sua atenção. Siga-me no GitHub , onde posto vários exemplos de projetos interessantes relacionados ao meu estudo e trabalho pessoal.
Bem, isso é tudo que eu queria dizer. Agradecimentos para sua atenção. Siga-me no GitHub , onde posto vários exemplos de projetos interessantes relacionados ao meu estudo e trabalho pessoal.
link útil
- Documentação oficial do Git . Recomendo como referência.
GO TO FULL VERSION