Zamiast wstępu
Cześć! Dzisiaj porozmawiamy o systemie kontroli wersji, a mianowicie Git. Nie masz nic wspólnego z programowaniem, jeśli nie znasz/nie rozumiesz Gita. Ale piękno polega na tym, że nie musisz mieć w głowie wszystkich poleceń i funkcji Gita, aby być stale zatrudnionym. Musisz znać zestaw poleceń, które pomogą ci zrozumieć wszystko, co się dzieje.
Nie masz nic wspólnego z programowaniem, jeśli nie znasz/nie rozumiesz Gita. Ale piękno polega na tym, że nie musisz mieć w głowie wszystkich poleceń i funkcji Gita, aby być stale zatrudnionym. Musisz znać zestaw poleceń, które pomogą ci zrozumieć wszystko, co się dzieje.
Podstawy Gita
Git to rozproszony system kontroli wersji naszego kodu. Dlaczego tego potrzebujemy? Rozproszone zespoły potrzebują jakiegoś systemu do zarządzania swoją pracą. Konieczne jest śledzenie zmian zachodzących w czasie. Oznacza to, że musimy zobaczyć krok po kroku, które pliki uległy zmianie i jak. Jest to szczególnie ważne, gdy badasz, co się zmieniło w kontekście pojedynczego zadania, umożliwiając cofnięcie zmian.Instalowanie Gita
Zainstalujmy Javę na twoim komputerze.Instalowanie w systemie Windows
Jak zwykle musisz pobrać i uruchomić plik exe. Tutaj wszystko jest proste: kliknij pierwszy link Google , przeprowadź instalację i to wszystko. W tym celu użyjemy konsoli bash dostarczanej przez system Windows. W systemie Windows musisz uruchomić Git Bash. Oto jak to wygląda w menu Start: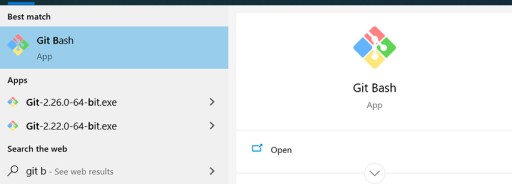 Teraz jest to wiersz polecenia, z którym możesz pracować. Aby uniknąć konieczności każdorazowego przechodzenia do folderu z projektem w celu otwarcia tam Gita, możesz otworzyć wiersz poleceń w folderze projektu prawym przyciskiem myszy ze ścieżką, której potrzebujemy:
Teraz jest to wiersz polecenia, z którym możesz pracować. Aby uniknąć konieczności każdorazowego przechodzenia do folderu z projektem w celu otwarcia tam Gita, możesz otworzyć wiersz poleceń w folderze projektu prawym przyciskiem myszy ze ścieżką, której potrzebujemy: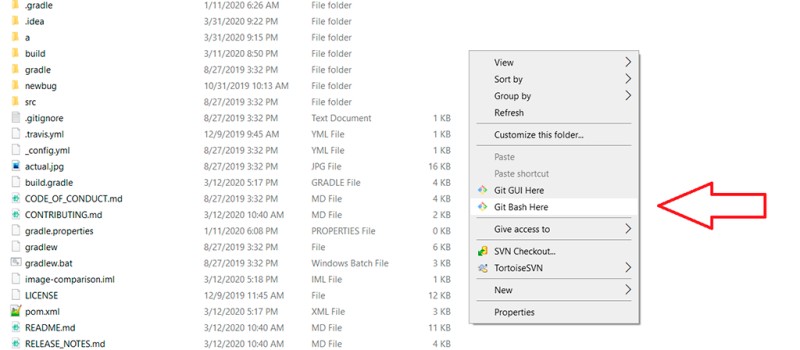
Instalacja w Linuksie
Zwykle Git jest częścią dystrybucji Linuksa i jest już zainstalowany, ponieważ jest to narzędzie, które zostało pierwotnie napisane do rozwoju jądra Linuksa. Ale są sytuacje, kiedy tak nie jest. Aby to sprawdzić, musisz otworzyć terminal i napisać: git --version. Jeśli otrzymasz zrozumiałą odpowiedź, nic nie trzeba instalować. Otwórz terminal i zainstaluj Git na Ubuntu . Pracuję nad Ubuntu, więc mogę ci powiedzieć, co dla niego napisać: sudo apt-get install git.Instalacja na macOS
Tutaj również musisz najpierw sprawdzić, czy Git już tam jest. Jeśli go nie masz, najłatwiejszym sposobem na jego zdobycie jest pobranie najnowszej wersji tutaj . Jeśli Xcode jest zainstalowany, Git na pewno zostanie automatycznie zainstalowany.Ustawienia Gita
Git ma ustawienia użytkownika dla użytkownika, który prześle pracę. Ma to sens i jest konieczne, ponieważ Git pobiera te informacje dla pola Autor podczas tworzenia zatwierdzenia. Skonfiguruj nazwę użytkownika i hasło dla wszystkich swoich projektów, uruchamiając następujące polecenia:
git config --global user.name "Ivan Ivanov"
git config --global user.email ivan.ivanov@gmail.com
git config user.name "Ivan Ivanov"
git config user.email ivan.ivanov@gmail.com
Trochę teorii...
Aby zagłębić się w temat, powinniśmy przedstawić Ci kilka nowych słów i działań...- repozytorium git
- popełniać
- oddział
- łączyć
- konflikty
- ciągnąć
- naciskać
- jak zignorować niektóre pliki (.gitignore)
Statusy w Git
Git ma kilka posągów, które należy zrozumieć i zapamiętać:- nieśledzony
- zmodyfikowane
- wystawiany na scenie
- zaangażowany
Jak należy to rozumieć?
Oto statusy, które dotyczą plików zawierających nasz kod:- Plik, który został utworzony, ale nie został jeszcze dodany do repozytorium, ma status „nieśledzony”.
- Gdy dokonujemy zmian w plikach, które zostały już dodane do repozytorium Git, wówczas ich status to „zmodyfikowany”.
- Spośród plików, które zmieniliśmy, wybieramy te, które są nam potrzebne, i tym klasom zmieniamy status na „staged”.
- Zatwierdzenie jest tworzone z przygotowanych plików w stanie etapowym i trafia do repozytorium Git. Po tym nie ma plików ze statusem „wystawiony”. Ale nadal mogą istnieć pliki, których status to „zmodyfikowany”.
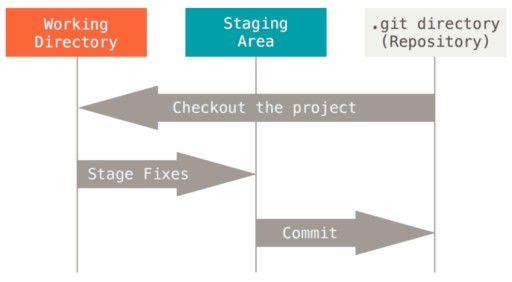
Co to jest zatwierdzenie?
Zatwierdzenie jest głównym wydarzeniem, jeśli chodzi o kontrolę wersji. Zawiera wszystkie zmiany dokonane od początku zatwierdzenia. Zatwierdzenia są ze sobą połączone jak pojedynczo połączona lista. Dokładniej: jest pierwsze zatwierdzenie. Kiedy tworzone jest drugie zatwierdzenie, wie, co następuje po pierwszym. W ten sposób można śledzić informacje. Zatwierdzenie ma również swoje własne informacje, tzw. metadane:
- unikalny identyfikator zatwierdzenia, którego można użyć do jego znalezienia
- nazwisko autora zatwierdzenia, który je utworzył
- datę utworzenia zatwierdzenia
- komentarz opisujący, co zostało zrobione podczas zatwierdzenia
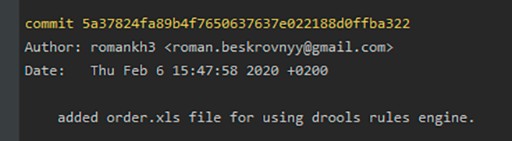
Co to jest oddział?
Gałąź jest wskaźnikiem do jakiegoś zatwierdzenia. Ponieważ zatwierdzenie wie, które zatwierdzenie je poprzedza, gdy gałąź wskazuje na zatwierdzenie, wszystkie poprzednie zatwierdzenia również mają do niego zastosowanie. W związku z tym możemy powiedzieć, że możesz mieć dowolną liczbę gałęzi wskazujących na to samo zatwierdzenie. Praca odbywa się w gałęziach, więc kiedy tworzone jest nowe zatwierdzenie, gałąź przenosi swój wskaźnik do nowszego zatwierdzenia.Pierwsze kroki z Gitem
Możesz pracować zarówno z lokalnym repozytorium, jak i zdalnym. Aby przećwiczyć wymagane polecenia, możesz ograniczyć się do lokalnego repozytorium. Przechowuje tylko wszystkie informacje o projekcie lokalnie w folderze .git. Jeśli mówimy o zdalnym repozytorium, to wszystkie informacje są przechowywane gdzieś na zdalnym serwerze: tylko kopia projektu jest przechowywana lokalnie. Zmiany dokonane w twojej lokalnej kopii mogą zostać wypchnięte (git push) do zdalnego repozytorium. W naszej dyskusji tutaj i poniżej mówimy o pracy z Gitem w konsoli. Oczywiście możesz użyć jakiegoś rozwiązania opartego na GUI (na przykład IntelliJ IDEA), ale najpierw powinieneś dowiedzieć się, jakie polecenia są wykonywane i co oznaczają.Praca z Git w lokalnym repozytorium
Następnie sugeruję, abyś postępował zgodnie z instrukcjami i wykonał wszystkie kroki, które wykonałem podczas czytania artykułu. Poprawi to twoje zrozumienie i opanowanie materiału. Cóż, smacznego! :) Aby utworzyć lokalne repozytorium, musisz napisać:
git init
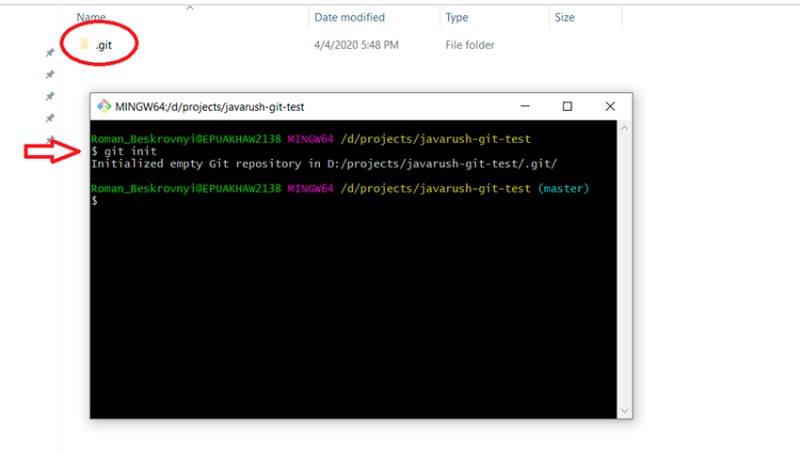 Spowoduje to utworzenie folderu .git w bieżącym katalogu konsoli. Folder .git przechowuje wszystkie informacje o repozytorium Git. Nie usuwaj go ;) Następnie pliki są dodawane do projektu i otrzymują status "Nieśledzone". Aby sprawdzić aktualny status swojej pracy, napisz:
Spowoduje to utworzenie folderu .git w bieżącym katalogu konsoli. Folder .git przechowuje wszystkie informacje o repozytorium Git. Nie usuwaj go ;) Następnie pliki są dodawane do projektu i otrzymują status "Nieśledzone". Aby sprawdzić aktualny status swojej pracy, napisz:
git status
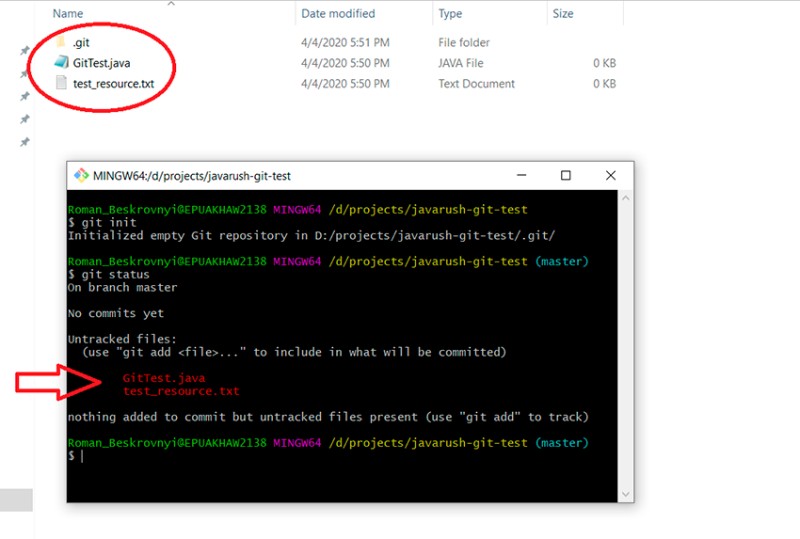 Jesteśmy w gałęzi głównej i tutaj pozostaniemy, dopóki nie przełączymy się na inną gałąź. Pokazuje, które pliki zostały zmienione, ale nie zostały jeszcze dodane do stanu „stadium”. Aby dodać je do statusu „staged”, musisz napisać „git add”. Mamy tu kilka opcji, na przykład:
Jesteśmy w gałęzi głównej i tutaj pozostaniemy, dopóki nie przełączymy się na inną gałąź. Pokazuje, które pliki zostały zmienione, ale nie zostały jeszcze dodane do stanu „stadium”. Aby dodać je do statusu „staged”, musisz napisać „git add”. Mamy tu kilka opcji, na przykład:
- git add -A — dodaje wszystkie pliki do stanu „stadium”.
- dodaj git. — dodaj wszystkie pliki z tego folderu i wszystkich podfolderów. Zasadniczo jest to to samo, co poprzednie
- git add <nazwa pliku> — dodaje określony plik. Tutaj możesz użyć wyrażeń regularnych, aby dodać pliki według jakiegoś wzorca. Na przykład git add *.java: Oznacza to, że chcesz dodać tylko pliki z rozszerzeniem java.
git add *.txt
git status
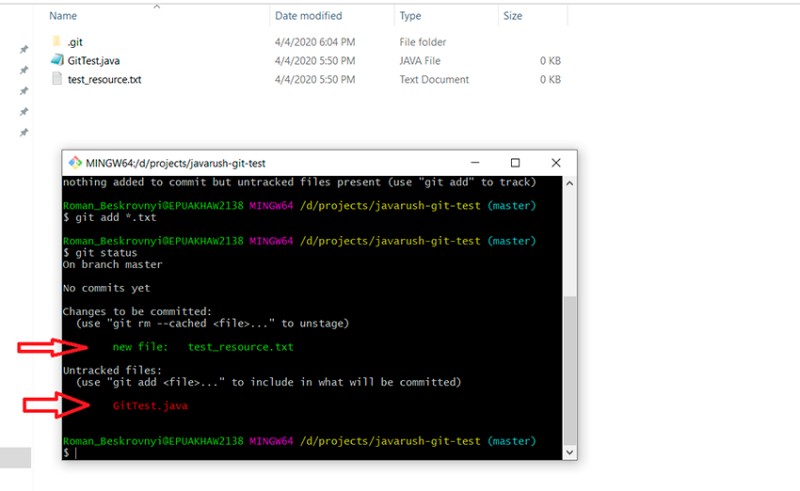 Tutaj widać, że wyrażenie regularne zadziałało poprawnie: plik test_resource.txt ma teraz status „staged”. I na koniec ostatni etap pracy z lokalnym repozytorium (przy pracy ze zdalnym repozytorium jest jeszcze jeden ;)) — utworzenie nowego zatwierdzenia:
Tutaj widać, że wyrażenie regularne zadziałało poprawnie: plik test_resource.txt ma teraz status „staged”. I na koniec ostatni etap pracy z lokalnym repozytorium (przy pracy ze zdalnym repozytorium jest jeszcze jeden ;)) — utworzenie nowego zatwierdzenia:
git commit -m "all txt files were added to the project"
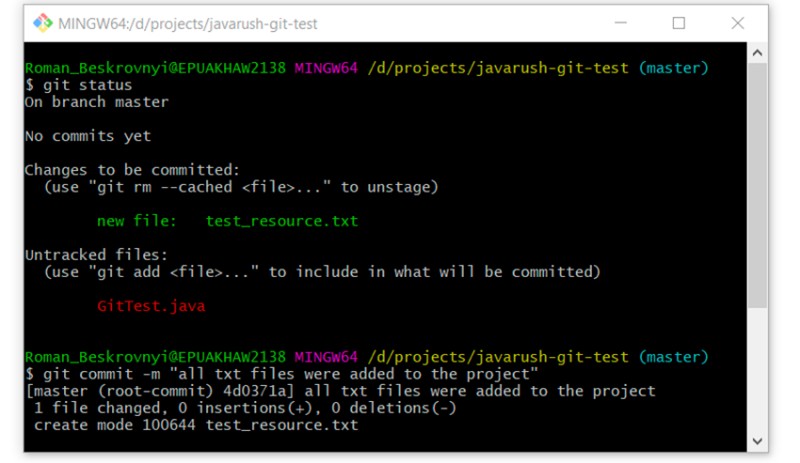 Następne jest świetne polecenie do przeglądania historii zatwierdzeń w gałęzi. Wykorzystajmy to:
Następne jest świetne polecenie do przeglądania historii zatwierdzeń w gałęzi. Wykorzystajmy to:
git log
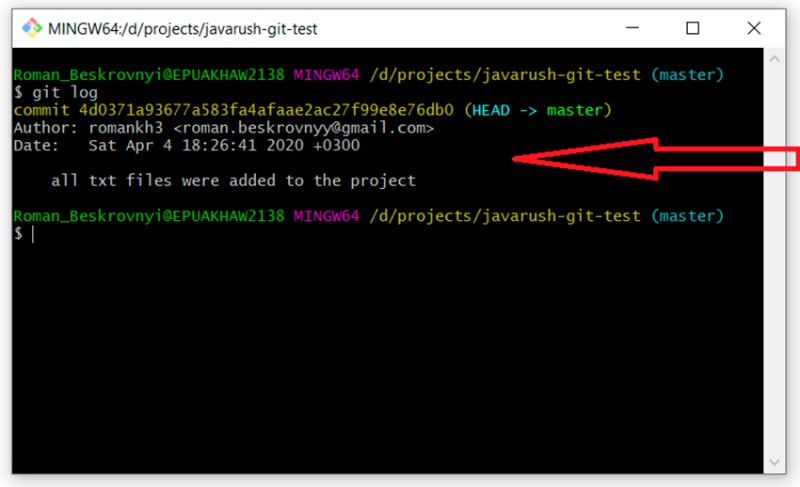 Tutaj możesz zobaczyć, że stworzyliśmy nasze pierwsze zatwierdzenie i zawiera ono tekst, który podaliśmy w wierszu poleceń. Bardzo ważne jest, aby zrozumieć, że ten tekst powinien jak najdokładniej wyjaśniać, co zostało zrobione podczas tego zatwierdzenia. Pomoże nam to wiele razy w przyszłości. Dociekliwy czytelnik, który jeszcze nie zasnął, może się zastanawiać, co stało się z plikiem GitTest.java. Dowiedzmy się teraz. W tym celu używamy:
Tutaj możesz zobaczyć, że stworzyliśmy nasze pierwsze zatwierdzenie i zawiera ono tekst, który podaliśmy w wierszu poleceń. Bardzo ważne jest, aby zrozumieć, że ten tekst powinien jak najdokładniej wyjaśniać, co zostało zrobione podczas tego zatwierdzenia. Pomoże nam to wiele razy w przyszłości. Dociekliwy czytelnik, który jeszcze nie zasnął, może się zastanawiać, co stało się z plikiem GitTest.java. Dowiedzmy się teraz. W tym celu używamy:
git status
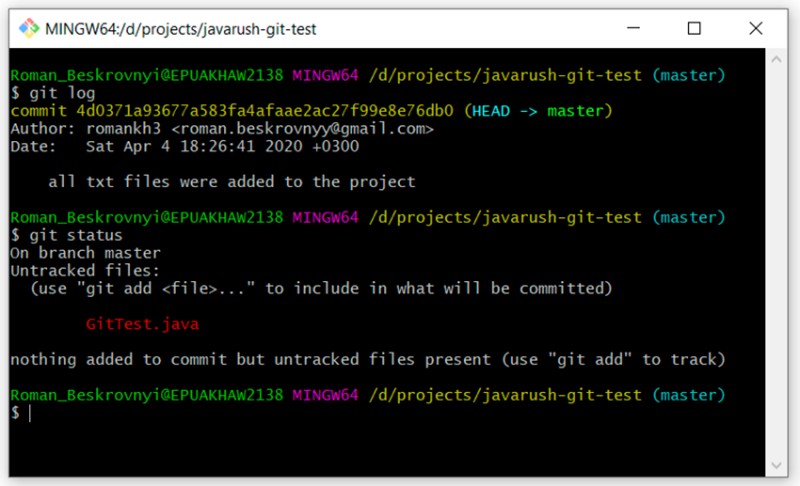 Jak widać, wciąż jest „nieśledzony” i czeka w zaułkach. Ale co, jeśli w ogóle nie chcemy dodawać go do projektu? Czasami tak się dzieje. Aby było ciekawiej, spróbujmy teraz zmienić nasz plik test_resource.txt. Dodajmy tam trochę tekstu i sprawdźmy status:
Jak widać, wciąż jest „nieśledzony” i czeka w zaułkach. Ale co, jeśli w ogóle nie chcemy dodawać go do projektu? Czasami tak się dzieje. Aby było ciekawiej, spróbujmy teraz zmienić nasz plik test_resource.txt. Dodajmy tam trochę tekstu i sprawdźmy status:
git status
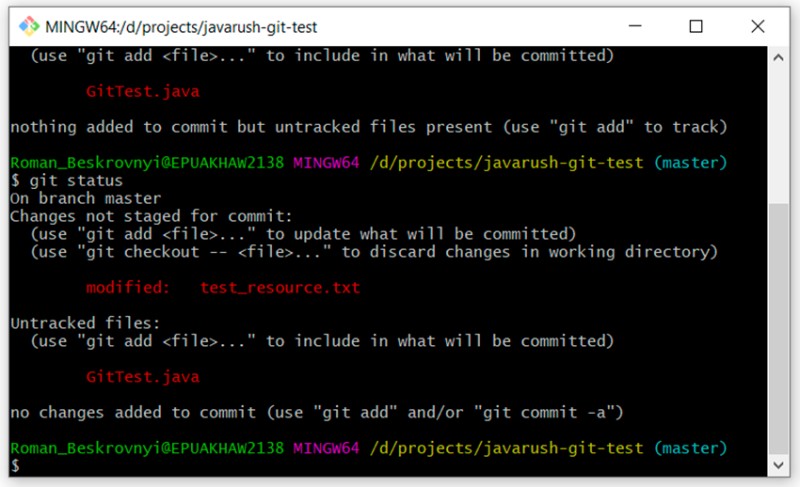 Tutaj możesz wyraźnie zobaczyć różnicę między statusami „nieśledzone” i „zmodyfikowane”. GitTest.java jest „nieśledzony”, podczas gdy plik test_resource.txt jest „zmodyfikowany”. Teraz, gdy mamy pliki w stanie zmodyfikowanym, możemy przeanalizować wprowadzone w nich zmiany. Można to zrobić za pomocą następującego polecenia:
Tutaj możesz wyraźnie zobaczyć różnicę między statusami „nieśledzone” i „zmodyfikowane”. GitTest.java jest „nieśledzony”, podczas gdy plik test_resource.txt jest „zmodyfikowany”. Teraz, gdy mamy pliki w stanie zmodyfikowanym, możemy przeanalizować wprowadzone w nich zmiany. Można to zrobić za pomocą następującego polecenia:
git diff
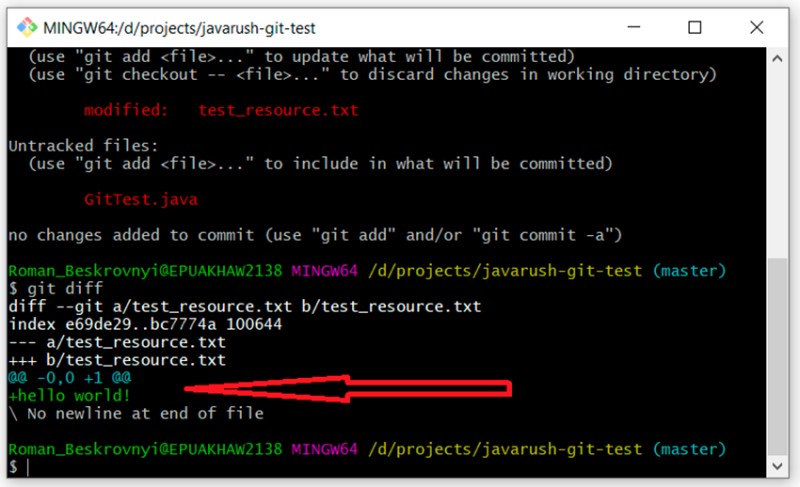 Oznacza to, że możesz tutaj wyraźnie zobaczyć, co dodałem do naszego pliku tekstowego: witaj, świecie! Dodajmy nasze zmiany do pliku tekstowego i utwórzmy zatwierdzenie:
Oznacza to, że możesz tutaj wyraźnie zobaczyć, co dodałem do naszego pliku tekstowego: witaj, świecie! Dodajmy nasze zmiany do pliku tekstowego i utwórzmy zatwierdzenie:
git add test_resource.txt
git commit -m "added hello word! to test_resource.txt"
git log
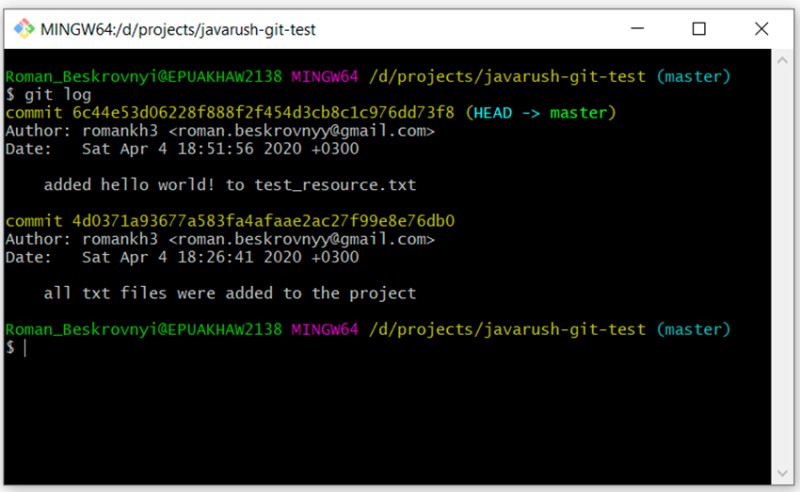 Jak widać, mamy teraz dwa zatwierdzenia. W ten sam sposób dodamy GitTest.java. Bez komentarzy, tylko polecenia:
Jak widać, mamy teraz dwa zatwierdzenia. W ten sam sposób dodamy GitTest.java. Bez komentarzy, tylko polecenia:
git add GitTest.java
git commit -m "added GitTest.java"
git status
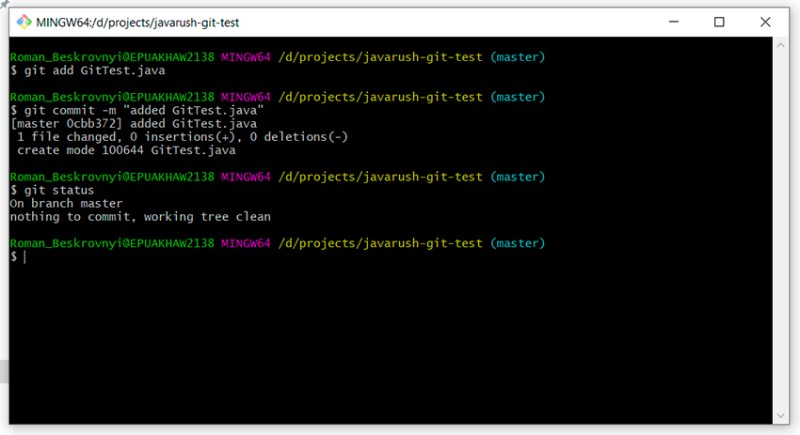
Praca z .gitignore
Najwyraźniej chcemy tylko przechowywać sam kod źródłowy i nic więcej w repozytorium. Więc co jeszcze może być? Jako minimum skompilowane klasy i/lub pliki generowane przez środowiska programistyczne. Aby powiedzieć Gitowi, aby je ignorował, musimy utworzyć specjalny plik. Zrób to: utwórz plik o nazwie .gitignore w katalogu głównym projektu. Każda linia w tym pliku reprezentuje wzorzec do zignorowania. W tym przykładzie plik .gitignore będzie wyglądał następująco:
```
*.class
target/
*.iml
.idea/
```
- Pierwsza linia to ignorowanie wszystkich plików z rozszerzeniem .class
- Drugi wiersz to zignorowanie folderu „docelowego” i wszystkiego, co zawiera
- Trzecia linia to ignorowanie wszystkich plików z rozszerzeniem .iml
- Czwarta linia to zignorowanie folderu .idea
git status
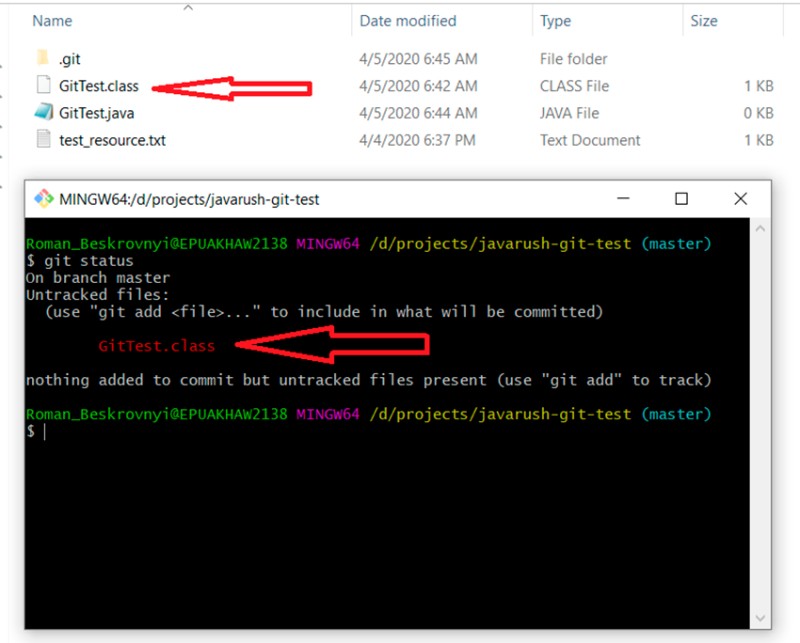 Oczywiście nie chcemy jakoś przypadkowo dodać skompilowanej klasy do projektu (za pomocą git add -A). Aby to zrobić, utwórz plik .gitignore i dodaj wszystko, co zostało opisane wcześniej:
Oczywiście nie chcemy jakoś przypadkowo dodać skompilowanej klasy do projektu (za pomocą git add -A). Aby to zrobić, utwórz plik .gitignore i dodaj wszystko, co zostało opisane wcześniej: 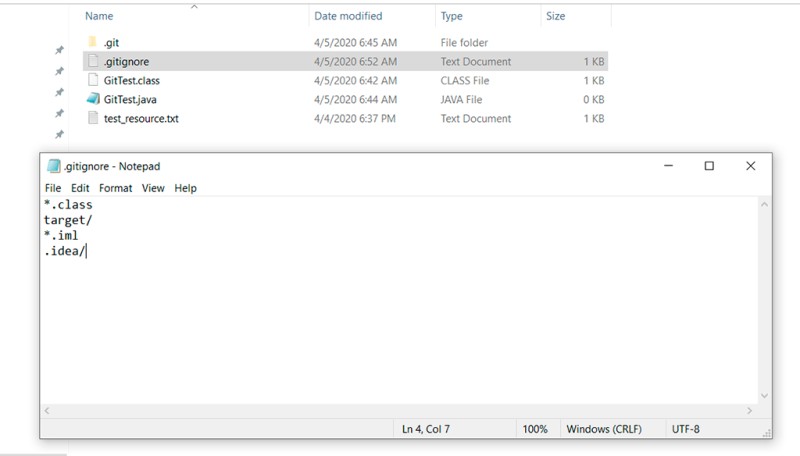 Teraz użyjmy zatwierdzenia, aby dodać plik .gitignore do projektu:
Teraz użyjmy zatwierdzenia, aby dodać plik .gitignore do projektu:
git add .gitignore
git commit -m "added .gitignore file"
git status
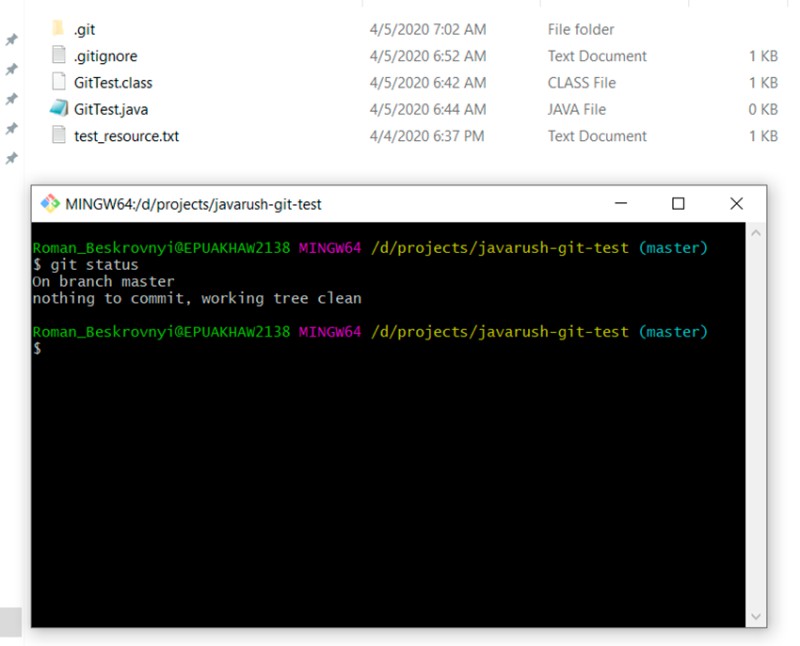 Doskonały! .gitignore +1 :)
Doskonały! .gitignore +1 :)
Praca z oddziałami i tym podobne
Oczywiście praca tylko w jednym oddziale jest niewygodna dla samotnych programistów i jest niemożliwa, gdy w zespole jest więcej niż jedna osoba. Od tego mamy oddziały. Jak powiedziałem wcześniej, gałąź jest po prostu ruchomym wskaźnikiem do zatwierdzeń. W tej części przyjrzymy się pracy w różnych gałęziach: jak scalać zmiany z jednej gałęzi w drugą, jakie konflikty mogą się pojawić i wiele więcej. Aby zobaczyć listę wszystkich oddziałów w repozytorium i zrozumieć, w którym się znajdujesz, musisz napisać:
git branch -a
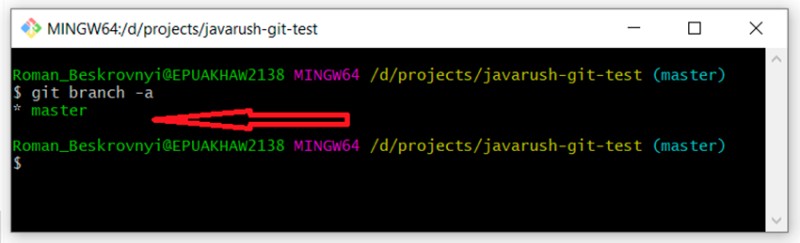 Jak widać, mamy tylko jedną gałąź główną. Gwiazdka przed nim wskazuje, że w nim jesteśmy. Nawiasem mówiąc, możesz również użyć polecenia „git status”, aby dowiedzieć się, w której gałęzi się znajdujemy. Następnie istnieje kilka opcji tworzenia gałęzi (może być ich więcej — ja korzystam z tych):
Jak widać, mamy tylko jedną gałąź główną. Gwiazdka przed nim wskazuje, że w nim jesteśmy. Nawiasem mówiąc, możesz również użyć polecenia „git status”, aby dowiedzieć się, w której gałęzi się znajdujemy. Następnie istnieje kilka opcji tworzenia gałęzi (może być ich więcej — ja korzystam z tych):
- utwórz nowy oddział na podstawie tego, w którym jesteśmy (99% przypadków)
- utwórz branch na podstawie konkretnego commita (1% przypadków)
Stwórzmy gałąź na podstawie konkretnego zatwierdzenia
Będziemy polegać na unikalnym identyfikatorze zatwierdzenia. Aby go znaleźć, piszemy:
git log
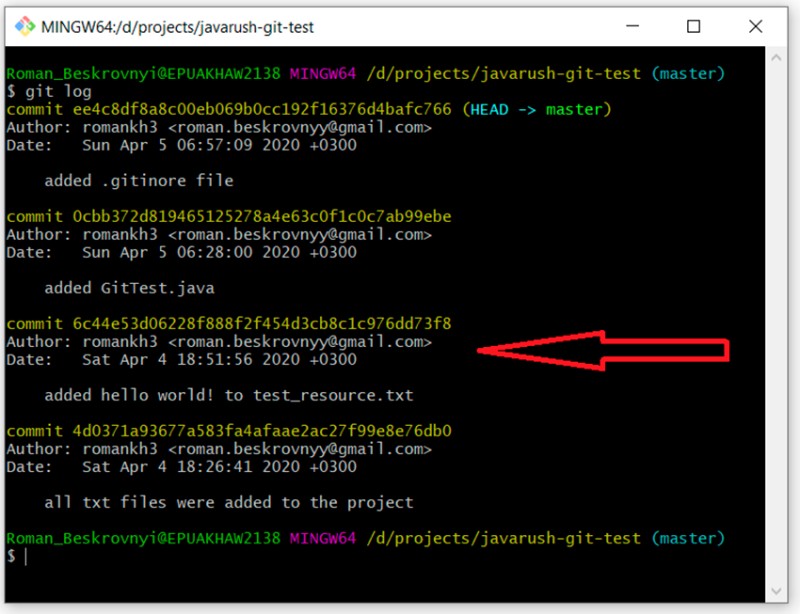 Zatwierdzenie zaznaczyłem komentarzem „dodano hello world…” Jego unikalny identyfikator to 6c44e53d06228f888f2f454d3cb8c1c976dd73f8. Chcę utworzyć gałąź „rozwojową”, która zaczyna się od tego zatwierdzenia. W tym celu piszę:
Zatwierdzenie zaznaczyłem komentarzem „dodano hello world…” Jego unikalny identyfikator to 6c44e53d06228f888f2f454d3cb8c1c976dd73f8. Chcę utworzyć gałąź „rozwojową”, która zaczyna się od tego zatwierdzenia. W tym celu piszę:
git checkout -b development 6c44e53d06228f888f2f454d3cb8c1c976dd73f8
git status
git log
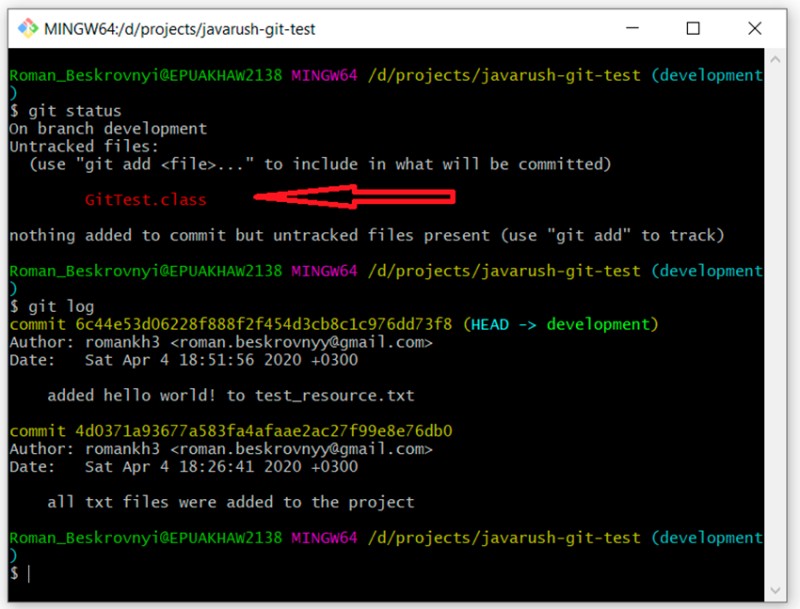 Zgodnie z oczekiwaniami mamy dwa zatwierdzenia. Nawiasem mówiąc, oto interesujący punkt: w tej gałęzi nie ma jeszcze pliku .gitignore, więc nasz skompilowany plik (GitTest.class) ma teraz status „nieśledzony”. Teraz możemy ponownie przejrzeć nasze oddziały, pisząc to:
Zgodnie z oczekiwaniami mamy dwa zatwierdzenia. Nawiasem mówiąc, oto interesujący punkt: w tej gałęzi nie ma jeszcze pliku .gitignore, więc nasz skompilowany plik (GitTest.class) ma teraz status „nieśledzony”. Teraz możemy ponownie przejrzeć nasze oddziały, pisząc to:
git branch -a
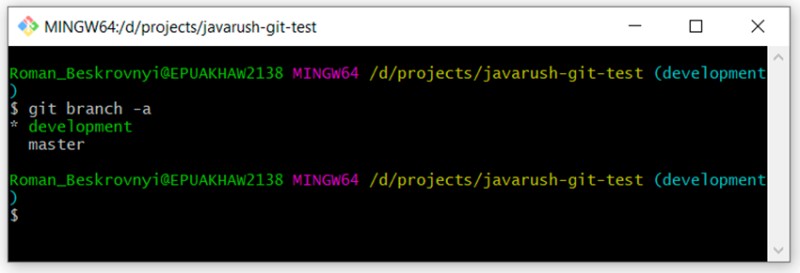 Widać, że są dwie gałęzie: „master” i „development”. Obecnie jesteśmy w fazie rozwoju.
Widać, że są dwie gałęzie: „master” i „development”. Obecnie jesteśmy w fazie rozwoju.
Stwórzmy gałąź opartą na obecnej
Drugim sposobem na utworzenie gałęzi jest utworzenie jej z innej. Chcę utworzyć gałąź opartą na gałęzi głównej. Najpierw muszę się na niego przełączyć, a następnym krokiem jest utworzenie nowego. Spójrzmy:- git checkout master — przełącz się do gałęzi master
- git status — sprawdź, czy rzeczywiście jesteśmy w gałęzi master
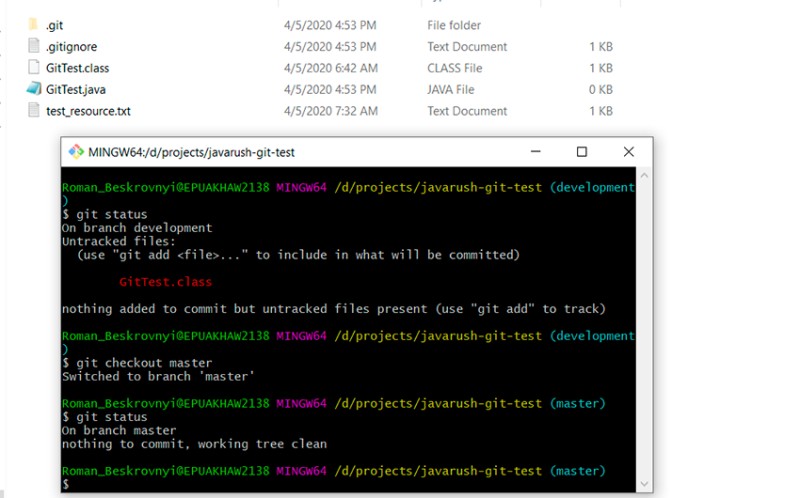 Tutaj możesz zobaczyć, że przełączyliśmy się na gałąź główną, plik .gitignore działa, a skompilowana klasa nie jest już podświetlona jako „nieśledzona”. Teraz tworzymy nową gałąź opartą na gałęzi głównej:
Tutaj możesz zobaczyć, że przełączyliśmy się na gałąź główną, plik .gitignore działa, a skompilowana klasa nie jest już podświetlona jako „nieśledzona”. Teraz tworzymy nową gałąź opartą na gałęzi głównej:
git checkout -b feature/update-txt-files
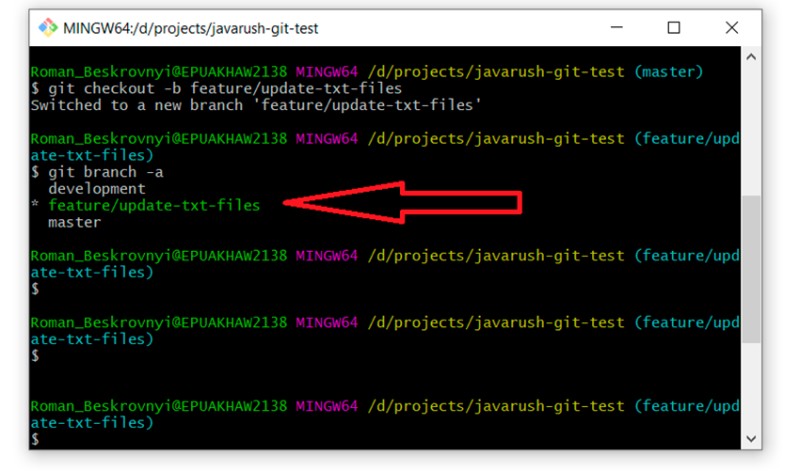 Jeśli nie masz pewności, czy ta gałąź jest taka sama jak „master”, możesz łatwo to sprawdzić, uruchamiając „git log” i przeglądając wszystkie zatwierdzenia. Powinno być ich czterech.
Jeśli nie masz pewności, czy ta gałąź jest taka sama jak „master”, możesz łatwo to sprawdzić, uruchamiając „git log” i przeglądając wszystkie zatwierdzenia. Powinno być ich czterech.
Rozwiązanie konfliktu
Zanim zbadamy, czym jest konflikt, musimy porozmawiać o łączeniu jednej gałęzi w drugą. Ten obraz przedstawia proces łączenia jednej gałęzi w drugą: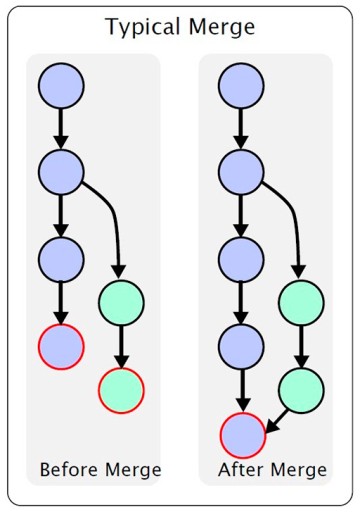 Tutaj mamy główną gałąź. W pewnym momencie gałąź dodatkowa jest tworzona poza gałęzią główną, a następnie modyfikowana. Po zakończeniu pracy musimy połączyć jedną gałąź z drugą. Nie będę opisywał różnych funkcji: w tym artykule chcę tylko przekazać ogólne zrozumienie. Jeśli potrzebujesz szczegółów, możesz sam je wyszukać. W naszym przykładzie utworzyliśmy gałąź Feature/update-txt-files. Jak wskazuje nazwa oddziału, aktualizujemy tekst.
Tutaj mamy główną gałąź. W pewnym momencie gałąź dodatkowa jest tworzona poza gałęzią główną, a następnie modyfikowana. Po zakończeniu pracy musimy połączyć jedną gałąź z drugą. Nie będę opisywał różnych funkcji: w tym artykule chcę tylko przekazać ogólne zrozumienie. Jeśli potrzebujesz szczegółów, możesz sam je wyszukać. W naszym przykładzie utworzyliśmy gałąź Feature/update-txt-files. Jak wskazuje nazwa oddziału, aktualizujemy tekst. 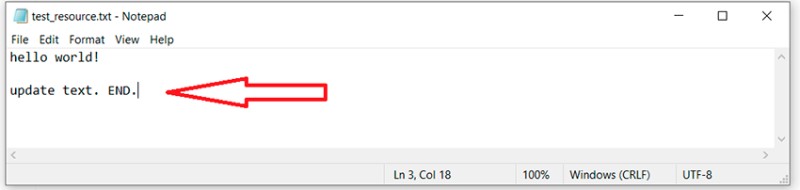 Teraz musimy utworzyć nowe zatwierdzenie dla tej pracy:
Teraz musimy utworzyć nowe zatwierdzenie dla tej pracy:
git add *.txt
git commit -m "updated txt files"
git log
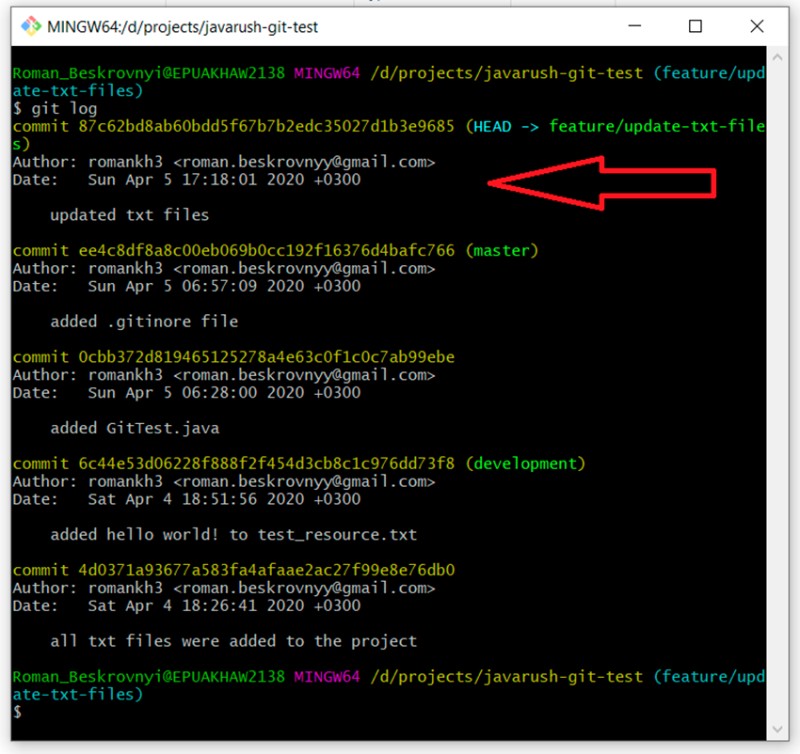 Teraz, jeśli chcemy scalić gałąź feature/update-txt-files w master, musimy przejść do master i napisać „git merge feature/update-txt-files”:
Teraz, jeśli chcemy scalić gałąź feature/update-txt-files w master, musimy przejść do master i napisać „git merge feature/update-txt-files”:
git checkout master
git merge feature/update-txt-files
git log
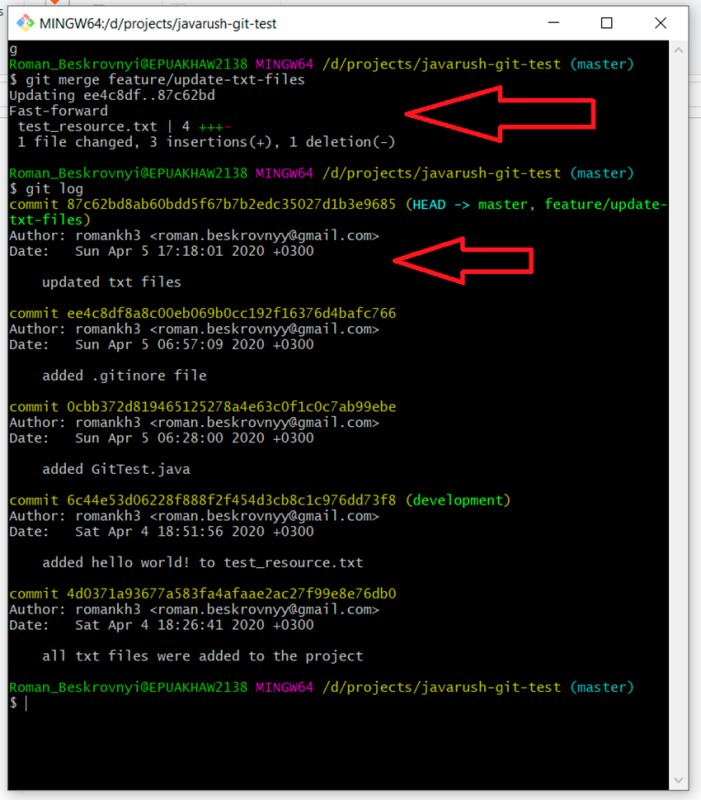 W rezultacie gałąź główna zawiera teraz również zatwierdzenie, które zostało dodane do plików funkcji/aktualizacji-txt. Ta funkcja została dodana, więc możesz usunąć gałąź funkcji. W tym celu piszemy:
W rezultacie gałąź główna zawiera teraz również zatwierdzenie, które zostało dodane do plików funkcji/aktualizacji-txt. Ta funkcja została dodana, więc możesz usunąć gałąź funkcji. W tym celu piszemy:
git branch -D feature/update-txt-files
git checkout -b feature/add-header
... we make changes to the file
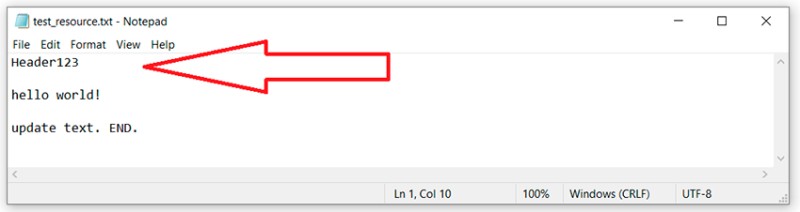
git add *.txt
git commit -m "added header to txt"
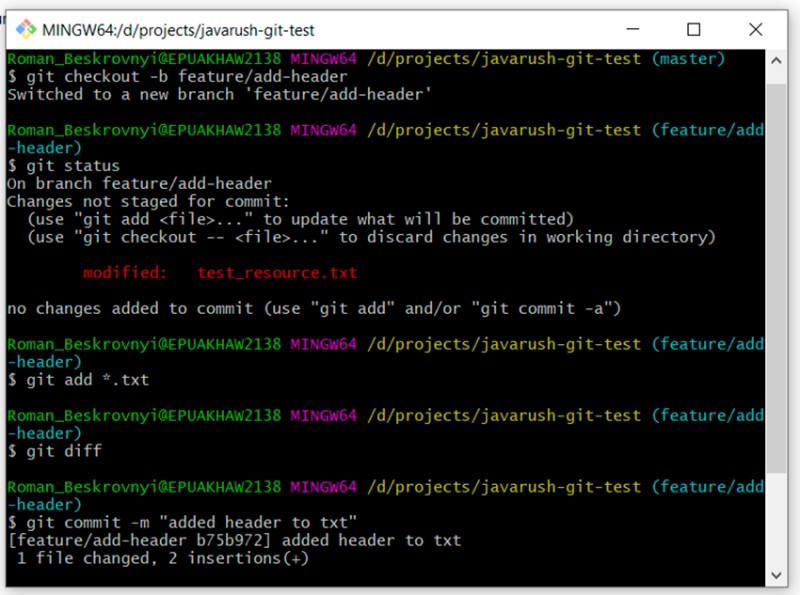 Przejdź do gałęzi głównej, a także zaktualizuj ten plik tekstowy w tym samym wierszu, co w gałęzi funkcji:
Przejdź do gałęzi głównej, a także zaktualizuj ten plik tekstowy w tym samym wierszu, co w gałęzi funkcji:
git checkout master
… we updated test_resource.txt
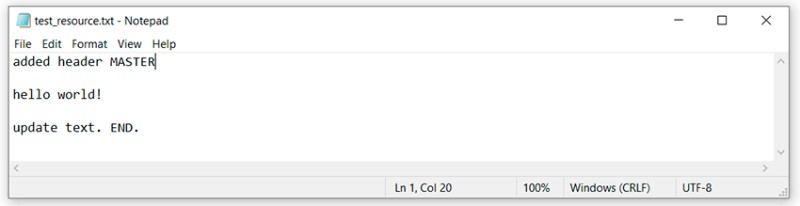
git add test_resource.txt
git commit -m "added master header to txt"
git merge feature/add-header
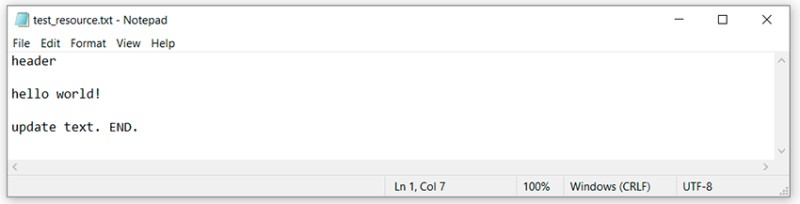
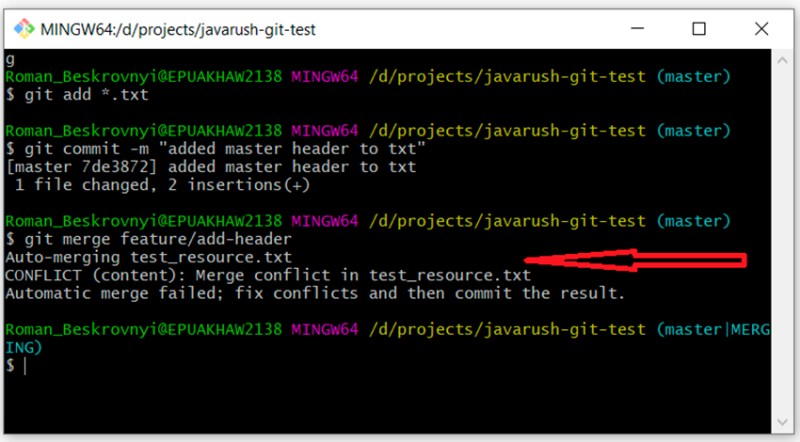 Tutaj widzimy, że Git nie mógł sam zdecydować, jak scalić ten kod. Mówi nam, że najpierw musimy rozwiązać konflikt, a dopiero potem wykonać zatwierdzenie. OK. Otwieramy plik z konfliktem w edytorze tekstu i widzimy:
Tutaj widzimy, że Git nie mógł sam zdecydować, jak scalić ten kod. Mówi nam, że najpierw musimy rozwiązać konflikt, a dopiero potem wykonać zatwierdzenie. OK. Otwieramy plik z konfliktem w edytorze tekstu i widzimy: 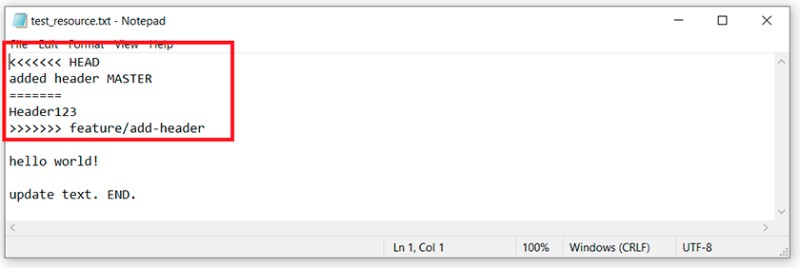 Aby zrozumieć, co zrobił tutaj Git, musimy pamiętać, jakie zmiany i gdzie wprowadziliśmy, a następnie porównać:
Aby zrozumieć, co zrobił tutaj Git, musimy pamiętać, jakie zmiany i gdzie wprowadziliśmy, a następnie porównać:
- Zmiany, które były w tej linii w gałęzi master, znajdują się między „<<<<<<< HEAD” i „=======”.
- Zmiany, które były w gałęzi Feature/add-header, znajdują się między „=======” a „>>>>>>> feature/add-header”.

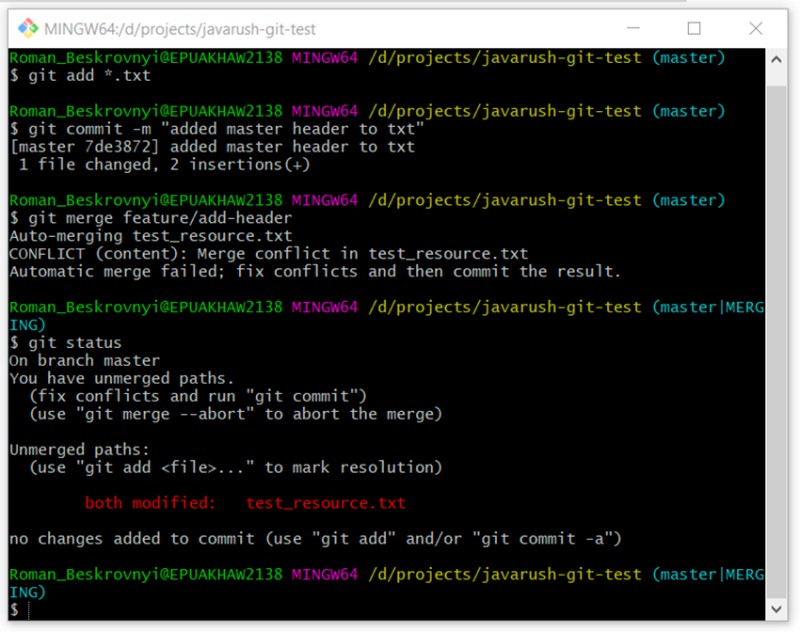
 Przyjrzyjmy się statusowi zmian. Opis będzie trochę inny. Zamiast statusu „zmodyfikowany” mamy status „unmerged”. Czy moglibyśmy więc wspomnieć o piątym statusie? Nie sądzę, żeby to było konieczne. Zobaczmy:
Przyjrzyjmy się statusowi zmian. Opis będzie trochę inny. Zamiast statusu „zmodyfikowany” mamy status „unmerged”. Czy moglibyśmy więc wspomnieć o piątym statusie? Nie sądzę, żeby to było konieczne. Zobaczmy:
git status
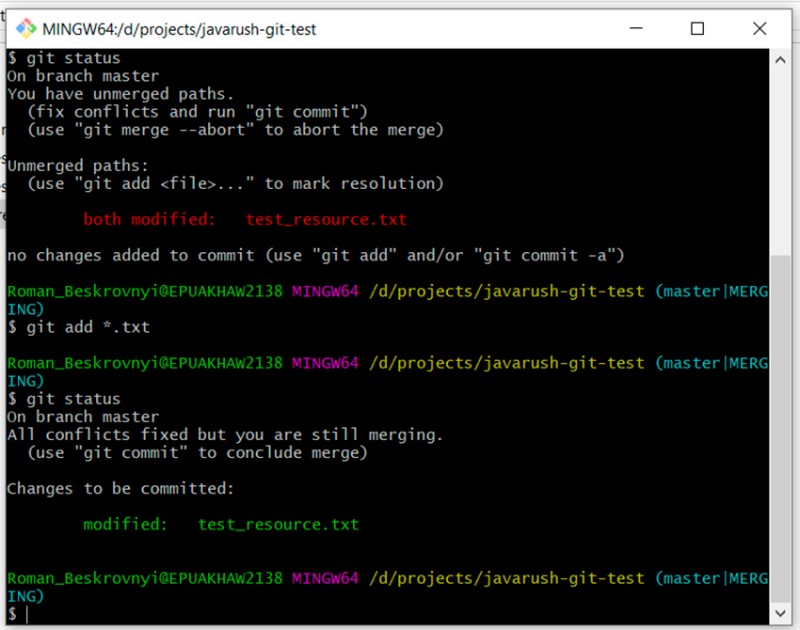
 Możemy się przekonać, że jest to przypadek szczególny, niezwykły. Kontynuujmy:
Możemy się przekonać, że jest to przypadek szczególny, niezwykły. Kontynuujmy:
git add *.txt
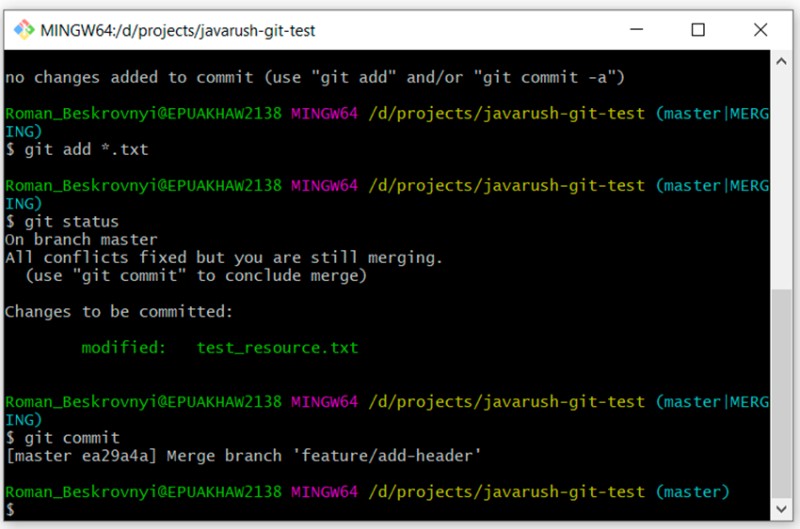
 Możesz zauważyć, że opis sugeruje napisanie tylko „git commit”. Spróbujmy napisać, że:
Możesz zauważyć, że opis sugeruje napisanie tylko „git commit”. Spróbujmy napisać, że:
git commit
 I tak po prostu to zrobiliśmy — rozwiązaliśmy konflikt w konsoli. Oczywiście można to zrobić nieco łatwiej w zintegrowanych środowiskach programistycznych. Na przykład w IntelliJ IDEA wszystko jest ustawione tak dobrze, że możesz wykonać wszystkie niezbędne czynności bezpośrednio w nim. Ale IDE robią wiele rzeczy „pod maską” i często nie rozumiemy, co dokładnie się tam dzieje. A kiedy nie ma zrozumienia, mogą pojawić się problemy.
I tak po prostu to zrobiliśmy — rozwiązaliśmy konflikt w konsoli. Oczywiście można to zrobić nieco łatwiej w zintegrowanych środowiskach programistycznych. Na przykład w IntelliJ IDEA wszystko jest ustawione tak dobrze, że możesz wykonać wszystkie niezbędne czynności bezpośrednio w nim. Ale IDE robią wiele rzeczy „pod maską” i często nie rozumiemy, co dokładnie się tam dzieje. A kiedy nie ma zrozumienia, mogą pojawić się problemy.
Praca ze zdalnymi repozytoriami
Ostatnim krokiem jest wymyślenie kilku dodatkowych poleceń, które są potrzebne do pracy ze zdalnym repozytorium. Jak powiedziałem, zdalne repozytorium to jakieś miejsce, w którym przechowywane jest repozytorium iz którego można je sklonować. Jakie są rodzaje zdalnych repozytoriów? Przykłady:-
GitHub to największa platforma do przechowywania repozytoriów i wspólnego programowania. Opisywałem to już w poprzednich artykułach.
Śledź mnie na GitHub . Często popisuję się tam swoją pracą w obszarach, których uczę się do pracy. -
GitLab to internetowe narzędzie do cyklu życia DevOps z otwartym kodem źródłowym . Jest to oparty na Git system do zarządzania repozytoriami kodu z własną wiki, systemem śledzenia błędów , potokiem CI/CD i innymi funkcjami.
Po wiadomości, że Microsoft kupił GitHub, niektórzy programiści zduplikowali swoje projekty w GitLabie. -
BitBucket to usługa internetowa do hostingu projektów i wspólnego rozwoju oparta na systemach kontroli wersji Mercurial i Git. Kiedyś miał dużą przewagę nad GitHubem, ponieważ oferował darmowe prywatne repozytoria. W zeszłym roku GitHub również udostępnił tę możliwość wszystkim za darmo.
-
I tak dalej…
git clone https://github.com/romankh3/git-demo
git pull
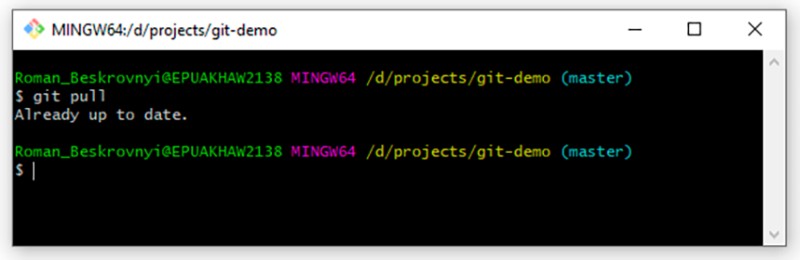 W naszym przypadku obecnie nic się nie zmieniło w zdalnym repozytorium, więc odpowiedź brzmi: Już aktualne. Ale jeśli dokonam jakichkolwiek zmian w zdalnym repozytorium, lokalne zostanie zaktualizowane po ich ściągnięciu. I wreszcie ostatnie polecenie to przekazanie danych do zdalnego repozytorium. Kiedy zrobiliśmy coś lokalnie i chcemy wysłać to do zdalnego repozytorium, musimy najpierw lokalnie utworzyć nowe zatwierdzenie. Aby to zademonstrować, dodajmy coś jeszcze do naszego pliku tekstowego:
W naszym przypadku obecnie nic się nie zmieniło w zdalnym repozytorium, więc odpowiedź brzmi: Już aktualne. Ale jeśli dokonam jakichkolwiek zmian w zdalnym repozytorium, lokalne zostanie zaktualizowane po ich ściągnięciu. I wreszcie ostatnie polecenie to przekazanie danych do zdalnego repozytorium. Kiedy zrobiliśmy coś lokalnie i chcemy wysłać to do zdalnego repozytorium, musimy najpierw lokalnie utworzyć nowe zatwierdzenie. Aby to zademonstrować, dodajmy coś jeszcze do naszego pliku tekstowego: 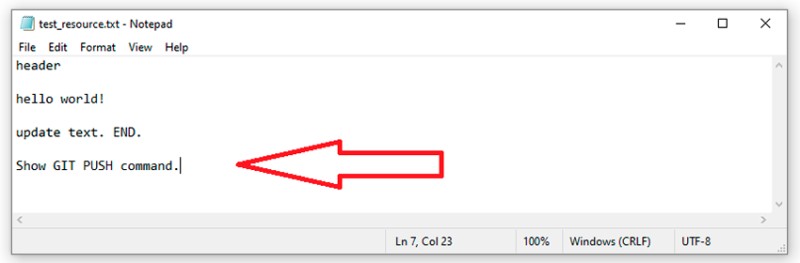 Teraz coś, co nas często spotyka — tworzymy zatwierdzenie tej pracy:
Teraz coś, co nas często spotyka — tworzymy zatwierdzenie tej pracy:
git add test_resource.txt
git commit -m "prepared txt for pushing"
git push
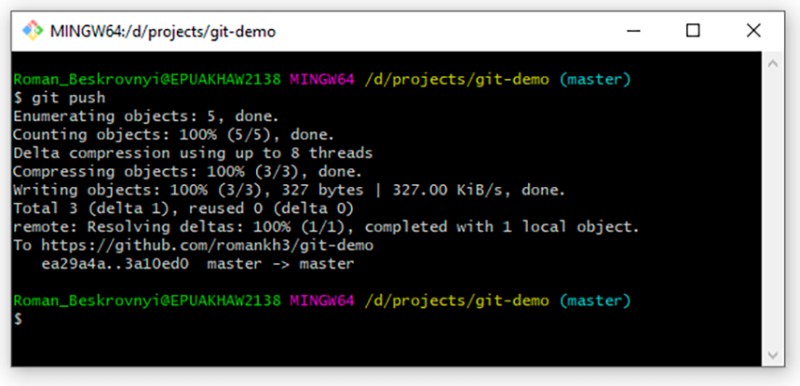 Cóż, to wszystko, co chciałem powiedzieć. Dziękuję za uwagę. Śledź mnie na GitHub , gdzie publikuję różne fajne przykładowe projekty związane z moją osobistą nauką i pracą.
Cóż, to wszystko, co chciałem powiedzieć. Dziękuję za uwagę. Śledź mnie na GitHub , gdzie publikuję różne fajne przykładowe projekty związane z moją osobistą nauką i pracą.
Przydatne łącze
- Oficjalna dokumentacja Gita . Polecam jako punkt odniesienia.
GO TO FULL VERSION