 最近、Java 開発者の職に関する面接の質問の大きなリストをいくつか見つけました。問題は、ジュニア、中級、上級のさまざまなレベルに分かれています。心配しないでください。すべての質問が簡単なわけではありませんが、アスタリスクが付いている質問はめったに聞かれません。質問は良いので、そのほとんどに答えたいと思います。明らかに、これらすべてを 1 つの記事に収めることはできません。結局のところ、そこには多くの質問があります。つまり、これらのインタビューの質問に対する回答を含む一連の記事が存在することになります。すぐにいくつかの点を強調しておきます。非常に詳細に書かれた回答は別の記事になる可能性があるため、回答は短くなります。また、面接では、非常に詳細で膨大な回答は求められません。面接官が重要なトピックについて面接できる時間は 1 時間しかないからです (そして、
最近、Java 開発者の職に関する面接の質問の大きなリストをいくつか見つけました。問題は、ジュニア、中級、上級のさまざまなレベルに分かれています。心配しないでください。すべての質問が簡単なわけではありませんが、アスタリスクが付いている質問はめったに聞かれません。質問は良いので、そのほとんどに答えたいと思います。明らかに、これらすべてを 1 つの記事に収めることはできません。結局のところ、そこには多くの質問があります。つまり、これらのインタビューの質問に対する回答を含む一連の記事が存在することになります。すぐにいくつかの点を強調しておきます。非常に詳細に書かれた回答は別の記事になる可能性があるため、回答は短くなります。また、面接では、非常に詳細で膨大な回答は求められません。面接官が重要なトピックについて面接できる時間は 1 時間しかないからです (そして、
ジュニア開発者のポジションに関する Q&A
一般的な質問
1. どのようなデザインパターンを知っていますか? あなたの作品で使用した 2 つのデザイン パターンについて教えてください。
膨大な種類のパターンがあります。デザインパターンを徹底的に知りたい人は、「Head First. Design Patterns」という本を読むことをおすすめします。最も基本的なデザイン パターンの詳細を簡単に学ぶのに役立ちます。就職面接で言及できるデザイン パターンとしては、次のものが思い浮かびます。- ビルダー— 頻繁に使用されるテンプレートであり、オブジェクト作成の古典的なアプローチに代わるものです。
- 戦略— 本質的にポリモーフィズムを表すパターン。つまり、インターフェイスは 1 つですが、プログラムの動作は関数に渡される特定のインターフェイス実装に応じて変化します (戦略パターンは現在、Java アプリケーションのほぼあらゆる場所で使用されています)。
- Factory — このパターンは ApplicationContext (または BeanFactory) にあります。
- シングルトン— すべての Bean はデフォルトでシングルトンです。
- プロキシ— 基本的に、Spring のすべてのものは何らかの方法でこのパターンを使用します。たとえば、AOP です。
- 責任の連鎖- Spring Security を支えるパターン。
- テンプレート— Spring JDBC で使用されます。
Javaコア

2. Java にはどのようなデータ型がありますか?
Java には次のプリミティブ データ型があります。- byte — -128 ~ 127 の範囲の整数は 1 バイトを占めます。
- short — -32768 ~ 32767 の範囲の整数は 2 バイトを占めます。
- int — -2147483648 ~ 2147483647 の範囲の整数。4 バイトを占めます。
- long — 9223372036854775808 ~ 9223372036854775807 の範囲の整数は 8 バイトを占めます。
- float — -3.4E+38 ~ 3.4E+38 の範囲の浮動小数点数。4 バイトを占めます。
- double — -1.7E+308 から 1.7E+308 の範囲の浮動小数点数、8 バイトを占有します。
- char — UTF-16 の単一文字。2 バイトを占めます。
- ブール値のtrue/false 値。1 バイトを占めます。

3. オブジェクトはプリミティブ データ型とどのように異なりますか?
最初の違いは、占有されるメモリの量です。プリミティブには独自の値のみが含まれるため、占有されるメモリの量はほとんどありませんが、オブジェクトには、プリミティブと他のオブジェクトへの参照の両方で、さまざまな値が多数含まれる可能性があります。2 番目の違いは、Java はオブジェクト指向言語であるため、Java の動作はすべてオブジェクト間の対話です。プリミティブはここではあまりうまく適合しません。実際、これが Java が 100% オブジェクト指向言語ではない理由です。3 番目の違いは、2 番目の違いに続きますが、Java はオブジェクトの対話に重点を置いているため、オブジェクトを管理するためのさまざまなメカニズムが存在するということです。たとえば、コンストラクター、メソッド、例外 (主にオブジェクトで動作する) などです。そして、このオブジェクト指向環境でプリミティブが何らかの方法で動作できるようにするために、Java の作成者は次のことを考え出しました。プリミティブ型 ( Integer、Character、Double、Boolean ...) のラッパー4. 引数を参照渡しと値渡しの違いは何ですか?
プリミティブ フィールドには値が保存されます。たとえば、int i = 9 に設定した場合、の場合、iフィールドには値 9 が格納されます。オブジェクトへの参照があるということは、オブジェクトへの参照を持つフィールドがあることを意味します。言い換えれば、メモリ内にオブジェクトのアドレスを格納するフィールドがあります。
Cat cat = new Cat();
5. JVM、JDK、および JRE とは何ですか?
JVM はJava Virtual Machineの略で、コンパイラによって事前に生成された Java バイトコードを実行します。 JRE はJava ランタイム環境の略です。基本的にはJavaアプリケーションを実行するための環境です。これには、Java プログラミング言語で記述されたアプレットやアプリケーションを実行するための JVM、標準ライブラリ、その他のコンポーネントが含まれています。つまり、JRE は、コンパイルされた Java プログラムを実行するために必要なすべてのパッケージですが、アプリケーションを開発するためのコンパイラーやデバッガーなどのツールやユーティリティは含まれていません。 JDK はJava Development Kitの略で、 JREの拡張機能です。。つまり、Java アプリケーションを実行するだけでなく、開発するための環境でもあります。JDK には、JRE のすべてに加えて、Java アプリケーションの作成に必要なさまざまな追加ツール (コンパイラやデバッガ) が含まれています (Java ドキュメントを含む)。
6. JVM を使用する理由は何ですか?
上で述べたように、Java 仮想マシンは、コンパイラによって事前に生成された Java バイトコードを実行する仮想マシンです。これは、JVM が Java ソース コードを理解できないことを意味します。したがって、最初に.javaファイルをコンパイルします。コンパイルされたファイルには.classが含まれます。拡張子が拡張され、JVM が理解できるバイトコードの形式になっています。JVMはOSごとに異なります。JVM はバイトコード ファイルを実行するときに、そのファイルを実行している OS に合わせて調整します。実際、JVM が異なるため、JDK (または JRE) も OS ごとに異なります (バージョンごとに独自の JVM が必要です)。他のプログラミング言語で開発がどのように行われるかを思い出してみましょう。プログラムを作成すると、そのコードが特定の OS 用のマシン コードにコンパイルされ、実行できるようになります。つまり、プラットフォームごとに異なるバージョンのプログラムを作成する必要があります。ただし、Java のコードの二重処理 (ソース コードをバイトコードにコンパイルし、次に JVM によるバイトコードの処理) により、クロスプラットフォーム ソリューションの利点を享受できます。コードを一度作成し、それをバイトコードにコンパイルします。そうすれば、それを任意の OS に取り込むことができ、ネイティブ JVM で実行できるようになります。そしてこれはまさに Java の伝説です一度書けばどこでも実行できる機能。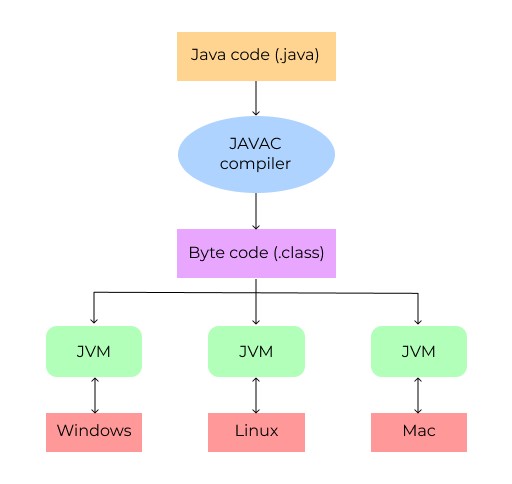
7. バイトコードとは何ですか?
上で述べたように、コンパイラは Java コードを中間バイトコードに変換します(拡張子が .java のファイルから拡張子が .class のファイルに変換します)。多くの点で、バイトコードはマシンコードと似ていますが、その命令セットが実際のプロセッサ用ではなく仮想プロセッサ用である点が異なります。ただし、プログラムが実行されている実際のプロセッサに合わせてコマンドの実行を最適化する、JIT コンパイラ用に設計されたセクションを含めることができます。JIT コンパイルは、オンザフライ コンパイルとも呼ばれ、プログラムの実行中にバイトコードをマシン コードまたは別の形式にコンパイルすることによって、バイトコード プログラムのパフォーマンスを向上させるテクノロジです。ご想像のとおり、JVM はバイトコードを実行するときに JIT コンパイラーを使用します。サンプルのバイトコードを見てみましょう。 あまり読みにくいですよね?幸いなことに、この指示は私たちを対象としたものではありません。JVM 用です。
あまり読みにくいですよね?幸いなことに、この指示は私たちを対象としたものではありません。JVM 用です。
8. JavaBean の特徴は何ですか?
JavaBean は、特定のルールに従う Java クラスです。JavaBean を作成するためのルールの一部を次に示します。-
クラスには、 publicアクセス修飾子を持つ空の (引数なし) コンストラクターが含まれている必要があります。このコンストラクターを使用すると、不必要な問題を発生させずにクラスのオブジェクトを作成できます (引数を不必要にいじる必要がなくなります)。
-
内部フィールドには、標準実装が必要なgetおよびsetインスタンス メソッドを介してアクセスします。たとえば、名前フィールドがある場合は、 getNameやsetNameなどが必要になります。これにより、さまざまなツール (フレームワーク) が自動的に Bean のコンテンツを簡単に取得および設定できるようになります。
-
クラスは、equals()、hashCode()、およびtoString()メソッドをオーバーライドする必要があります。
-
クラスはシリアル化可能である必要があります。つまり、Serializable マーカー インターフェイスを備えているか、またはExternalizableインターフェイスを実装している必要があります。これは、Bean の状態を確実に保存、保存、復元できるようにするためです。

9. OutOfMemoryError とは何ですか?
OutOfMemoryError は、Java 仮想マシン (JVM) に関連する重大なランタイム エラーです。このエラーは、オブジェクトに十分なメモリがないために JVM がオブジェクトを割り当てることができず、ガベージ コレクタがそれ以上のメモリを割り当てることができない場合に発生します。OutOfMemoryErrorのいくつかのタイプ:-
OutOfMemoryError: Java ヒープ スペース- メモリ不足のため、オブジェクトを Java ヒープに割り当てることができません。このエラーは、メモリ リーク、または現在のアプリケーションに対して小さすぎるデフォルトのヒープ サイズによって発生する可能性があります。
-
OutOfMemoryError: GC オーバーヘッド制限を超えました。アプリケーションのデータがヒープにほとんど収まらないため、ガベージ コレクターが常に実行され、Java プログラムの実行が非常に遅くなります。その結果、ガベージ コレクターのオーバーヘッド制限を超え、アプリケーションがこのエラーでクラッシュします。
-
OutOfMemoryError: 要求された配列サイズが VM 制限を超えています- これは、アプリケーションがヒープ サイズを超える配列にメモリを割り当てようとしたことを示します。繰り返しますが、これはデフォルトで割り当てられたメモリが不十分であることを意味している可能性があります。
-
OutOfMemoryError: Metaspace — ヒープでメタデータに割り当てられたスペースが不足しました (メタデータはクラスとメソッドの命令です)。
-
OutOfMemoryError: 理由によりサイズ バイトを要求しました。スワップ スペース不足— ヒープからメモリを割り当てようとしたときにエラーが発生し、その結果、ヒープに十分なスペースが不足しました。

10. スタック トレースとは何ですか? どうすれば入手できますか?
スタック トレースは、アプリケーションの実行のこの時点までに呼び出されたクラスとメソッドのリストです。これを実行すると、アプリケーション内の特定の時点でスタック トレースを取得できます。
StackTraceElement[] stackTraceElements =Thread.currentThread().getStackTrace();
 Java では、スタック トレースについて話すとき、通常、エラー (または例外) が発生したときにコンソールに表示されるスタック トレースを意味します。次のように例外からスタック トレースを取得できます。
Java では、スタック トレースについて話すとき、通常、エラー (または例外) が発生したときにコンソールに表示されるスタック トレースを意味します。次のように例外からスタック トレースを取得できます。
StackTraceElement[] stackTraceElements;
try{
...
} catch (Exception e) {
stackTraceElements = e.getStackTrace();
}
try{
...
} catch (Exception e) {
e.printStackTrace();
}
 これを踏まえて、今日のこのトピックの説明を終了します。
これを踏まえて、今日のこのトピックの説明を終了します。
GO TO FULL VERSION