 Recentemente, encontrei algumas grandes listas de perguntas de entrevistas para cargos de desenvolvedor Java. As perguntas são divididas em diferentes níveis: júnior, nível médio e sênior. Não se assuste: nem todas as perguntas são fáceis, mas aquelas com um asterisco raramente são feitas. As perguntas são boas, e eu gostaria de tentar responder a maioria delas. Claramente, isso não vai caber em um único artigo. Afinal, há muitas perguntas lá. Isso significa que haverá toda uma série de artigos com respostas a essas perguntas da entrevista. Deixe-me enfatizar alguns pontos de imediato: as respostas serão curtas, porque as respostas escritas em grande detalhe podem ser extraídas em um artigo separado. Além disso, em entrevistas, respostas super detalhadas e volumosas não são desejadas, porque seu entrevistador tem apenas uma hora para entrevistá-lo sobre tópicos essenciais (e,
Recentemente, encontrei algumas grandes listas de perguntas de entrevistas para cargos de desenvolvedor Java. As perguntas são divididas em diferentes níveis: júnior, nível médio e sênior. Não se assuste: nem todas as perguntas são fáceis, mas aquelas com um asterisco raramente são feitas. As perguntas são boas, e eu gostaria de tentar responder a maioria delas. Claramente, isso não vai caber em um único artigo. Afinal, há muitas perguntas lá. Isso significa que haverá toda uma série de artigos com respostas a essas perguntas da entrevista. Deixe-me enfatizar alguns pontos de imediato: as respostas serão curtas, porque as respostas escritas em grande detalhe podem ser extraídas em um artigo separado. Além disso, em entrevistas, respostas super detalhadas e volumosas não são desejadas, porque seu entrevistador tem apenas uma hora para entrevistá-lo sobre tópicos essenciais (e,
Perguntas e respostas para uma posição de desenvolvedor júnior
Questões gerais
1. Quais padrões de projeto você conhece? Conte-nos sobre dois padrões de projeto que você usou em seu trabalho.
Há uma enorme variedade de padrões. Para aqueles que desejam se familiarizar completamente com os padrões de design, recomendo a leitura do livro "Head First. Design Patterns". Isso ajudará você a aprender facilmente os detalhes dos padrões de design mais básicos. Em termos de padrões de design que você poderia mencionar em uma entrevista de emprego, lembre-se do seguinte:- Builder — um modelo usado com frequência, uma alternativa à abordagem clássica de criação de objetos;
- Estratégia — um padrão que representa essencialmente o polimorfismo. Ou seja, temos uma interface, mas o comportamento do programa muda dependendo da implementação da interface específica passada para a função (o padrão de estratégia agora é usado em praticamente todos os aplicativos Java).
- Factory — esse padrão pode ser encontrado em ApplicationContext (ou em BeanFactory);
- Singleton — todos os beans são singletons por padrão;
- Proxy — basicamente, tudo no Spring usa esse padrão de uma forma ou de outra, por exemplo, AOP;
- Cadeia de responsabilidade — um padrão que sustenta o Spring Security;
- Modelo — usado no Spring JDBC.

Núcleo Java

2. Quais tipos de dados existem em Java?
Java tem os seguintes tipos de dados primitivos:- byte — inteiros variando de -128 a 127, ocupa 1 byte;
- short — inteiros variando de -32768 a 32767, ocupam 2 bytes;
- int — inteiros variando de -2147483648 a 2147483647, ocupa 4 bytes;
- long — inteiros variando de 9223372036854775808 a 9223372036854775807, ocupa 8 bytes;
- float — números de ponto flutuante variando de -3.4E+38 a 3.4E+38, ocupa 4 bytes;
- double — números de ponto flutuante variando de -1.7E+308 a 1.7E+308, ocupa 8 bytes;
- char — caracteres únicos em UTF-16, ocupa 2 bytes;
- valores booleanos verdadeiro/falso, ocupa 1 byte.
3. Como um objeto difere dos tipos de dados primitivos?
A primeira diferença é a quantidade de memória ocupada: os primitivos ocupam muito pouco porque contêm apenas seu próprio valor, mas os objetos podem conter muitos valores diferentes — tanto primitivos quanto referências a outros objetos. Uma segunda diferença é esta: Java é uma linguagem orientada a objetos, então tudo em Java funciona é uma interação entre objetos. Primitivos não se encaixam muito bem aqui. Na verdade, é por isso que Java não é uma linguagem 100% orientada a objetos. A terceira diferença, decorrente da segunda, é que, como Java se concentra nas interações de objetos, há muitos mecanismos diferentes para gerenciar objetos. Por exemplo, construtores, métodos, exceções (que funcionam principalmente com objetos), etc. E para permitir que as primitivas funcionem de alguma forma neste ambiente orientado a objetos, os criadores de Java criaramwrappers para os tipos primitivos ( Integer , Character , Double , Boolean ...)4. Qual é a diferença entre passar argumentos por referência e por valor?
Os campos primitivos armazenam seus valores: por exemplo, se definirmos int i = 9; , então o campo i armazena o valor 9. Quando temos uma referência a um objeto, isso significa que temos um campo com uma referência ao objeto. Em outras palavras, temos um campo que armazena o endereço do objeto na memória.
Cat cat = new Cat();
5. O que é JVM, JDK e JRE?
JVM significa Java Virtual Machine , que executa o bytecode Java pré-gerado pelo compilador. JRE significa Java Runtime Environment . Basicamente, é um ambiente para execução de aplicativos Java. Inclui a JVM, bibliotecas padrão e outros componentes para execução de applets e aplicativos escritos na linguagem de programação Java. Em outras palavras, o JRE é um pacote de tudo o que é necessário para executar um programa Java compilado, mas não inclui ferramentas e utilitários como compiladores ou depuradores para desenvolvimento de aplicativos. JDK significa Java Development Kit , que é uma extensão do JRE. Ou seja, é um ambiente não só para rodar aplicações Java, mas também para desenvolvê-las. O JDK contém tudo no JRE, além de várias ferramentas adicionais — compiladores e depuradores — necessárias para criar aplicativos Java (inclui documentos Java).
6. Por que usar a JVM?
Conforme declarado acima, a Java Virtual Machine é uma máquina virtual que executa o bytecode Java que foi pré-gerado pelo compilador. Isso significa que a JVM não entende o código-fonte Java. Então, primeiro, compilamos os arquivos .java . Os arquivos compilados têm a extensão .classextensão e agora estão na forma de bytecode, que a JVM entende. A JVM é diferente para cada sistema operacional. Quando a JVM executa arquivos bytecode, ela os adapta para o sistema operacional no qual está sendo executada. Na verdade, como existem diferentes JVMs, o JDK (ou JRE) também difere para diferentes sistemas operacionais (cada versão precisa de sua própria JVM). Vamos relembrar como o desenvolvimento funciona em outras linguagens de programação. Você escreve um programa, então seu código é compilado em código de máquina para um sistema operacional específico e, então, você pode executá-lo. Em outras palavras, você precisa escrever diferentes versões do programa para cada plataforma. Mas o processamento duplo do código do Java (compilação do código-fonte em bytecode e, em seguida, processamento do bytecode pela JVM) permite que você aproveite os benefícios de uma solução de plataforma cruzada. Criamos o código uma vez e o compilamos em bytecode. Em seguida, podemos levá-lo para qualquer sistema operacional e a JVM nativa é capaz de executá-lo. E este é precisamente o lendário Javaescreva uma vez, execute em qualquer lugar .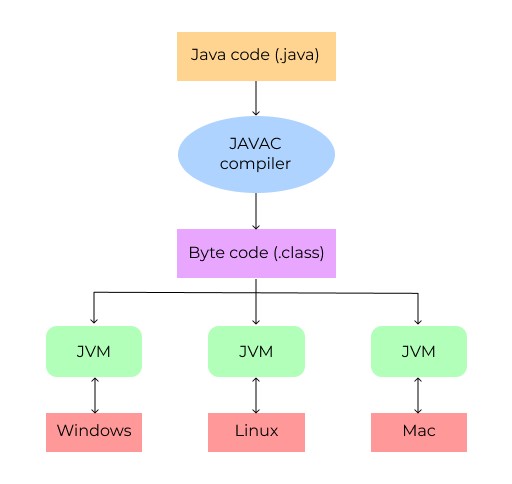
7. O que é bytecode?
Como eu disse acima, o compilador converte código Java em bytecode intermediário (passamos de arquivos com a extensão .java para arquivos com a extensão .class). De muitas maneiras, o bytecode é semelhante ao código de máquina, exceto que seu conjunto de instruções não é para um processador real, mas virtual. Dito isso, ele pode incluir seções projetadas para um compilador JIT, que otimiza a execução de comandos para o processador real no qual o programa está sendo executado. A compilação JIT, também chamada de compilação on-the-fly, é uma tecnologia que aumenta o desempenho de um programa de bytecode ao compilar o bytecode em código de máquina ou outro formato enquanto o programa está em execução. Como você deve ter adivinhado, a JVM usa o compilador JIT quando executa bytecode. Vamos dar uma olhada em alguns exemplos de bytecode: Não muito legível, hein? A boa notícia é que esta instrução não é para nós. É para a JVM.
Não muito legível, hein? A boa notícia é que esta instrução não é para nós. É para a JVM.
8. Quais são os recursos de um JavaBean?
Um JavaBean é uma classe Java que segue certas regras. Aqui estão algumas das regras para escrever um JavaBean :-
A classe deve conter um construtor vazio (sem argumentos) com o modificador de acesso público . Este construtor permite criar um objeto da classe sem problemas desnecessários (para que não haja confusão desnecessária com argumentos).
-
Os campos internos são acessados por meio dos métodos de instância get e set , que devem ter a implementação padrão. Por exemplo, se tivermos um campo de nome , devemos ter getName e setName , etc. Isso permite que várias ferramentas (frameworks) obtenham e definam automaticamente o conteúdo dos beans sem nenhuma dificuldade.
-
A classe deve substituir os métodos equals() , hashCode() e toString() .
-
A classe deve ser serializável. Ou seja, deve possuir a interface marcadora Serializable ou implementar a interface Externalizable . Isso é feito para que o estado do bean possa ser salvo, armazenado e restaurado de forma confiável.

9. O que é OutOfMemoryError?
OutOfMemoryError é um erro crítico de tempo de execução relacionado à Java Virtual Machine (JVM). Este erro ocorre quando a JVM não pode alocar um objeto porque não há memória suficiente para ele e o coletor de lixo não pode alocar mais memória. Alguns tipos de OutOfMemoryError :-
OutOfMemoryError: Java heap space — o objeto não pode ser alocado no heap Java devido à memória insuficiente. Esse erro pode ser causado por um vazamento de memória ou por um tamanho de heap padrão muito pequeno para o aplicativo atual.
-
OutOfMemoryError: Limite de sobrecarga de GC excedido — como os dados do aplicativo mal cabem no heap, o coletor de lixo é executado o tempo todo, fazendo com que o programa Java seja executado muito lentamente. Como resultado, o limite de sobrecarga do coletor de lixo é excedido e o aplicativo trava com esse erro.
-
OutOfMemoryError: o tamanho do array solicitado excede o limite da VM — isso indica que o aplicativo tentou alocar memória para um array que excede o tamanho do heap. Novamente, isso pode significar que memória insuficiente foi alocada por padrão.
-
OutOfMemoryError: Metaspace — o heap ficou sem espaço alocado para metadados (metadados são instruções para classes e métodos).
-
OutOfMemoryError: solicita tamanho de bytes por motivo. Out of swap space — ocorreu algum erro ao tentar alocar memória do heap e, como resultado, o heap não tem espaço suficiente.

10. O que é um rastreamento de pilha? Como faço para obtê-lo?
Um rastreamento de pilha é uma lista das classes e métodos que foram chamados até este ponto na execução de um aplicativo. Você pode obter o rastreamento de pilha em um ponto específico no aplicativo fazendo isso:
StackTraceElement[] stackTraceElements =Thread.currentThread().getStackTrace();
 Em Java, quando as pessoas falam sobre rastreamento de pilha, elas geralmente se referem a um rastreamento de pilha exibido no console quando ocorre um erro (ou exceção). Você pode obter o rastreamento de pilha de exceções como esta:
Em Java, quando as pessoas falam sobre rastreamento de pilha, elas geralmente se referem a um rastreamento de pilha exibido no console quando ocorre um erro (ou exceção). Você pode obter o rastreamento de pilha de exceções como esta:
StackTraceElement[] stackTraceElements;
try{
...
} catch (Exception e) {
stackTraceElements = e.getStackTrace();
}
try{
...
} catch (Exception e) {
e.printStackTrace();
}
 E com essa observação, concluiremos nossa discussão sobre esse tópico hoje.
E com essa observação, concluiremos nossa discussão sobre esse tópico hoje.
GO TO FULL VERSION