 Niedawno natknąłem się na kilka dużych list pytań do rozmów kwalifikacyjnych na stanowiska programistów Java. Pytania podzielone są na różne poziomy: junior, mid-level i senior. Nie przejmuj się: nie wszystkie pytania są łatwe, ale te z gwiazdką są rzadko zadawane. Pytania są dobre i chciałbym spróbować odpowiedzieć na większość z nich. Oczywiście nie zmieści się to wszystko w jednym artykule. W końcu jest tam wiele pytań. Oznacza to, że pojawi się cała seria artykułów z odpowiedziami na te pytania z wywiadu. Od razu podkreślę kilka kwestii: odpowiedzi będą krótkie, ponieważ odpowiedzi napisane bardzo szczegółowo mogą zostać wyciągnięte na osobny artykuł. Ponadto podczas wywiadów nie są pożądane szczegółowe i obszerne odpowiedzi, ponieważ osoba przeprowadzająca wywiad ma tylko godzinę, aby przeprowadzić z tobą wywiad na istotne tematy (i,
Niedawno natknąłem się na kilka dużych list pytań do rozmów kwalifikacyjnych na stanowiska programistów Java. Pytania podzielone są na różne poziomy: junior, mid-level i senior. Nie przejmuj się: nie wszystkie pytania są łatwe, ale te z gwiazdką są rzadko zadawane. Pytania są dobre i chciałbym spróbować odpowiedzieć na większość z nich. Oczywiście nie zmieści się to wszystko w jednym artykule. W końcu jest tam wiele pytań. Oznacza to, że pojawi się cała seria artykułów z odpowiedziami na te pytania z wywiadu. Od razu podkreślę kilka kwestii: odpowiedzi będą krótkie, ponieważ odpowiedzi napisane bardzo szczegółowo mogą zostać wyciągnięte na osobny artykuł. Ponadto podczas wywiadów nie są pożądane szczegółowe i obszerne odpowiedzi, ponieważ osoba przeprowadzająca wywiad ma tylko godzinę, aby przeprowadzić z tobą wywiad na istotne tematy (i,
Pytania i odpowiedzi na stanowisko młodszego programisty
Ogólne pytania
1. Jakie znasz wzorce projektowe? Opowiedz nam o dwóch wzorcach projektowych, z których korzystałeś w swojej pracy.
Istnieje ogromna różnorodność wzorów. Tym z Państwa, którzy chcą dokładnie zapoznać się z wzorcami projektowymi, polecam lekturę książki „Najpierw głowa. Wzorce projektowe”. Pomoże Ci łatwo poznać szczegóły najbardziej podstawowych wzorców projektowych. Jeśli chodzi o wzorce projektowe, o których możesz wspomnieć podczas rozmowy kwalifikacyjnej, przychodzą na myśl:- Builder — często używany szablon, alternatywa dla klasycznego podejścia do tworzenia obiektów;
- Strategia — wzorzec, który zasadniczo reprezentuje polimorfizm. Oznacza to, że mamy jeden interfejs, ale zachowanie programu zmienia się w zależności od konkretnej implementacji interfejsu przekazanej do funkcji (wzorzec strategii jest obecnie używany niemal wszędzie w aplikacjach Java).
- Factory — ten wzorzec można znaleźć w ApplicationContext (lub w BeanFactory);
- Singleton — wszystkie komponenty bean są domyślnie singletonami;
- Proxy — w zasadzie wszystko w Springu używa tego wzorca w taki czy inny sposób, na przykład AOP;
- Łańcuch odpowiedzialności — wzorzec leżący u podstaw Spring Security;
- Szablon — używany w Spring JDBC.
Rdzeń Javy

2. Jakie typy danych są dostępne w Javie?

- bajt — liczby całkowite z przedziału od -128 do 127, zajmuje 1 bajt;
- short — liczby całkowite z zakresu od -32768 do 32767, zajmuje 2 bajty;
- int — liczby całkowite z zakresu od -2147483648 do 2147483647, zajmuje 4 bajty;
- long — liczby całkowite z zakresu od 9223372036854775808 do 9223372036854775807, zajmuje 8 bajtów;
- float — liczby zmiennoprzecinkowe z zakresu od -3,4E+38 do 3,4E+38, zajmują 4 bajty;
- double — liczby zmiennoprzecinkowe z zakresu od -1,7E+308 do 1,7E+308, zajmują 8 bajtów;
- char — pojedyncze znaki w UTF-16, zajmuje 2 bajty;
- wartości logiczne prawda/fałsz zajmuje 1 bajt.
3. Czym różni się obiekt od prymitywnych typów danych?
Pierwszą różnicą jest ilość zajmowanej pamięci: prymitywy zajmują bardzo mało, ponieważ zawierają tylko własną wartość, ale obiekty mogą zawierać wiele różnych wartości — zarówno prymitywy, jak i odniesienia do innych obiektów. Druga różnica jest następująca: Java jest językiem zorientowanym obiektowo, więc wszystko w Javie działa jako interakcja między obiektami. Prymitywy nie pasują tu zbyt dobrze. Właśnie dlatego Java nie jest językiem w 100% zorientowanym obiektowo. Trzecia różnica, wynikająca z drugiej, polega na tym, że ponieważ Java koncentruje się na interakcjach między obiektami, istnieje wiele różnych mechanizmów zarządzania obiektami. Na przykład konstruktory, metody, wyjątki (które działają głównie z obiektami) itp. Aby prymitywy mogły w jakiś sposób działać w tym zorientowanym obiektowo środowisku, twórcy Javy wymyśliliopakowania dla typów pierwotnych ( Integer , Character , Double , Boolean ...)4. Jaka jest różnica między przekazywaniem argumentów przez referencję a przez wartość?
Pola pierwotne przechowują swoją wartość: na przykład, jeśli ustawimy int i = 9; , to pole i przechowuje wartość 9. Kiedy mamy referencję do obiektu, oznacza to, że mamy pole z referencją do obiektu. Innymi słowy, mamy pole, które przechowuje adres obiektu w pamięci.
Cat cat = new Cat();
5. Co to jest JVM, JDK i JRE?
JVM to skrót od Java Virtual Machine , która uruchamia kod bajtowy Java wygenerowany przez kompilator. JRE oznacza Java Runtime Environment . Zasadniczo jest to środowisko do uruchamiania aplikacji Java. Obejmuje JVM, standardowe biblioteki i inne komponenty do uruchamiania apletów i aplikacji napisanych w języku programowania Java. Innymi słowy, środowisko JRE to pakiet zawierający wszystko, co jest potrzebne do uruchomienia skompilowanego programu Java, ale nie zawiera narzędzi i narzędzi, takich jak kompilatory czy debuggery do tworzenia aplikacji. JDK oznacza Java Development Kit , który jest rozszerzeniem środowiska JRE. Oznacza to, że jest to środowisko nie tylko do uruchamiania aplikacji Java, ale także do ich rozwijania. Pakiet JDK zawiera wszystkie elementy środowiska JRE oraz różne dodatkowe narzędzia — kompilatory i debugery — potrzebne do tworzenia aplikacji Java (w tym dokumenty Java).
6. Dlaczego warto używać maszyny JVM?
Jak wspomniano powyżej, wirtualna maszyna Java to maszyna wirtualna, na której działa kod bajtowy Java, który został wstępnie wygenerowany przez kompilator. Oznacza to, że JVM nie rozumie kodu źródłowego Java. Najpierw kompilujemy pliki .java . Skompilowane pliki mają rozszerzenie .classrozszerzenie i są teraz w postaci kodu bajtowego, który JVM rozumie. JVM jest inna dla każdego systemu operacyjnego. Gdy JVM uruchamia pliki kodu bajtowego, dostosowuje je do systemu operacyjnego, na którym działa. W rzeczywistości, ponieważ istnieją różne maszyny JVM, JDK (lub JRE) również różnią się dla różnych systemów operacyjnych (każda wersja potrzebuje własnej maszyny JVM). Przypomnijmy sobie, jak działa programowanie w innych językach programowania. Piszesz program, a następnie jego kod jest kompilowany do kodu maszynowego dla określonego systemu operacyjnego, a następnie możesz go uruchomić. Innymi słowy, musisz napisać różne wersje programu dla każdej platformy. Ale podwójne przetwarzanie kodu w Javie (kompilacja kodu źródłowego do kodu bajtowego, a następnie przetwarzanie kodu bajtowego przez maszynę JVM) pozwala czerpać korzyści z rozwiązania wieloplatformowego. Tworzymy kod raz i kompilujemy go do kodu bajtowego. Następnie możemy przenieść go do dowolnego systemu operacyjnego, a natywna JVM jest w stanie go uruchomić. I to jest właśnie legenda Javynapisz raz, uruchom w dowolnym miejscu .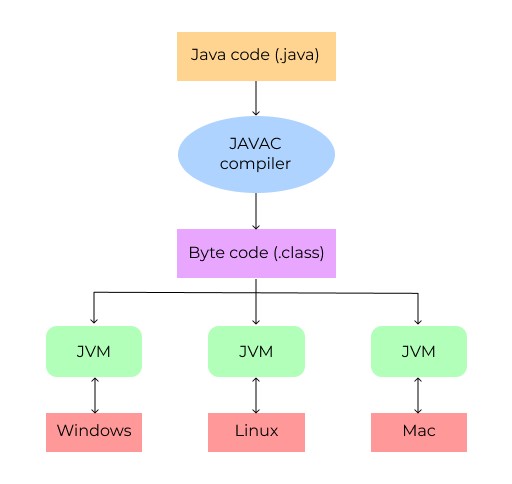
7. Co to jest kod bajtowy?
Jak powiedziałem powyżej, kompilator konwertuje kod Java na pośredni kod bajtowy (przechodzimy od plików z rozszerzeniem .java do plików z rozszerzeniem .class). Pod wieloma względami kod bajtowy jest podobny do kodu maszynowego, z wyjątkiem tego, że jego zestaw instrukcji nie jest przeznaczony dla rzeczywistego procesora, ale dla procesora wirtualnego. To powiedziawszy, może zawierać sekcje zaprojektowane dla kompilatora JIT, który optymalizuje wykonywanie poleceń dla rzeczywistego procesora, na którym działa program. Kompilacja JIT, zwana także kompilacją w locie, to technologia, która zwiększa wydajność programu kodu bajtowego poprzez kompilację kodu bajtowego do kodu maszynowego lub innego formatu podczas działania programu. Jak można się domyślić, JVM używa kompilatora JIT podczas uruchamiania kodu bajtowego. Rzućmy okiem na przykładowy kod bajtowy: Niezbyt czytelne, co? Dobra wiadomość jest taka, że ta instrukcja nie jest przeznaczona dla nas. To dla JVM.
Niezbyt czytelne, co? Dobra wiadomość jest taka, że ta instrukcja nie jest przeznaczona dla nas. To dla JVM.
8. Jakie są cechy komponentu JavaBean?
JavaBean to klasa Java, która podlega pewnym regułom . Oto niektóre zasady pisania komponentu JavaBean :-
Klasa musi zawierać pusty (bezargumentowy) konstruktor z modyfikatorem dostępu publicznego . Konstruktor ten umożliwia stworzenie obiektu klasy bez zbędnych problemów (aby nie było zbędnego kombinowania z argumentami).
-
Dostęp do pól wewnętrznych uzyskuje się za pomocą metod instancji get i set , które powinny mieć standardową implementację. Na przykład, jeśli mamy pole name , powinniśmy mieć getName i setName itd. Dzięki temu różne narzędzia (frameworki) mogą automatycznie pobierać i ustawiać zawartość komponentów bean bez żadnych trudności.
-
Klasa musi zastąpić metody equals() , hashCode() i toString() .
-
Klasa musi być serializowalna. Oznacza to, że musi mieć interfejs znacznika Serializable lub implementować interfejs Externalizable . Ma to na celu niezawodne zapisywanie, przechowywanie i przywracanie stanu komponentu bean.

9. Co to jest błąd OutOfMemory?
OutOfMemoryError to krytyczny błąd czasu wykonywania związany z wirtualną maszyną Java (JVM). Ten błąd występuje, gdy JVM nie może przydzielić obiektu, ponieważ nie ma dla niego wystarczającej ilości pamięci, a moduł wyrzucania elementów bezużytecznych nie może przydzielić więcej pamięci. Kilka typów OutOfMemoryError :-
OutOfMemoryError: Java heap space — obiekt nie może zostać przydzielony na stercie Java z powodu braku pamięci. Ten błąd może być spowodowany wyciekiem pamięci lub domyślnym rozmiarem sterty, który jest zbyt mały dla bieżącej aplikacji.
-
OutOfMemoryError: Przekroczono limit GC Overhead — ponieważ dane aplikacji ledwo mieszczą się na stercie, bezużyteczny moduł zbierania danych działa cały czas, co powoduje, że program Java działa bardzo wolno. W rezultacie limit narzutu modułu wyrzucania elementów bezużytecznych został przekroczony i aplikacja ulega awarii z powodu tego błędu.
-
OutOfMemoryError: Żądany rozmiar tablicy przekracza limit maszyny wirtualnej — oznacza to, że aplikacja próbowała przydzielić pamięć dla tablicy przekraczającej rozmiar sterty. Ponownie może to oznaczać, że domyślnie przydzielono niewystarczającą ilość pamięci.
-
OutOfMemoryError: Metaspace — na stercie zabrakło miejsca przeznaczonego na metadane (metadane to instrukcje dla klas i metod).
-
OutOfMemoryError: żądanie rozmiaru bajtów z powodu. Out of swap space — wystąpił błąd podczas próby przydzielenia pamięci ze sterty, w wyniku czego na stercie brakuje wystarczającej ilości miejsca.

10. Co to jest ślad stosu? Jak mogę to dostać?
Ślad stosu to lista klas i metod, które zostały wywołane do tego momentu podczas wykonywania aplikacji. Możesz uzyskać ślad stosu w określonym punkcie aplikacji, wykonując następujące czynności:
StackTraceElement[] stackTraceElements =Thread.currentThread().getStackTrace();
 W Javie, kiedy ludzie mówią o śladzie stosu, zwykle mają na myśli ślad stosu wyświetlany na konsoli, gdy wystąpi błąd (lub wyjątek). Możesz uzyskać ślad stosu z takich wyjątków:
W Javie, kiedy ludzie mówią o śladzie stosu, zwykle mają na myśli ślad stosu wyświetlany na konsoli, gdy wystąpi błąd (lub wyjątek). Możesz uzyskać ślad stosu z takich wyjątków:
StackTraceElement[] stackTraceElements;
try{
...
} catch (Exception e) {
stackTraceElements = e.getStackTrace();
}
try{
...
} catch (Exception e) {
e.printStackTrace();
}
 I na tej notatce zakończymy dzisiejszą dyskusję na ten temat.
I na tej notatce zakończymy dzisiejszą dyskusję na ten temat.
GO TO FULL VERSION