3.1. Svake ACID-egenskaper
Datakonsistens har i lang tid vært en hellig ku for arkitekter og utviklere. Alle relasjonsdatabaser ga en viss grad av isolasjon, enten gjennom oppdateringslåser og blokkering av lesinger, eller gjennom angrelogger. Med bruken av enorme mengder informasjon og distribuerte systemer ble det klart at det var umulig å sikre et transaksjonssett med operasjoner for dem på den ene siden, og å oppnå høy tilgjengelighet og rask responstid på den andre.
Dessuten garanterer ikke en oppdatering av en post at andre brukere umiddelbart vil se endringer i systemet, fordi endringen kan skje, for eksempel i masternoden, og replikaen kopieres asynkront til slavenoden, som en annen bruker med. virker. I dette tilfellet vil han se resultatet etter en viss tidsperiode. Dette kalles eventuell konsistens, og det er dette alle de største internettselskapene i verden går til nå, inkludert Facebook og Amazon. Sistnevnte erklærer stolt at det maksimale intervallet der brukeren kan se inkonsistente data ikke er mer enn et sekund. Et eksempel på en slik situasjon er vist i figuren:
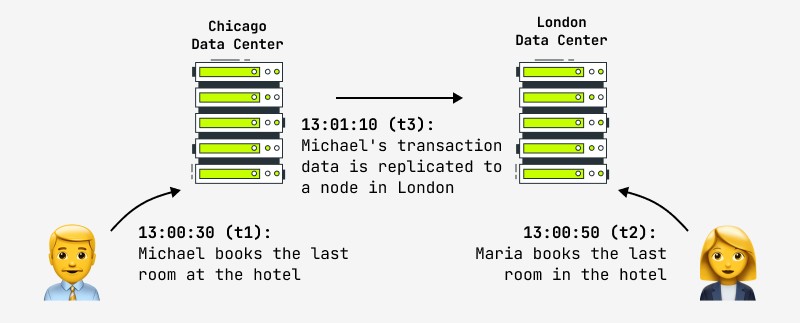
Det logiske spørsmålet som dukker opp i en slik situasjon er hva man skal gjøre med systemer som klassisk sett stiller høye krav til driftens atomitet-konsistens og samtidig trenger raskt distribuerte klynger – finansielle, nettbutikker osv.? Praksis viser at disse kravene ikke lenger er relevante: her er hva en designer av finansbanksystemet sa: "Hvis vi virkelig ventet på fullføringen av hver transaksjon i det globale nettverket av minibanker (minibanker), ville transaksjoner ta så lang tid at kundene ville stikke av i raseri. Hva skjer hvis du og partneren din tar ut penger samtidig og overskrider grensen? "Dere vil både få pengene, og vi fikser det senere."

Et annet eksempel er hotellbestillingen vist på bildet. Nettbutikker hvis datapolicy forutsetter eventuell konsistens, er pålagt å gi tiltak i tilfelle slike situasjoner (automatisk konfliktløsning, tilbakerulling av operasjoner, oppdatering med andre data). Hoteller prøver i praksis alltid å ha en «pool» av ledige rom i nødstilfeller, og dette kan være en løsning på en kontroversiell situasjon.
Faktisk betyr svake ACID-egenskaper ikke at de ikke eksisterer i det hele tatt. I de fleste tilfeller bruker en applikasjon som arbeider med en relasjonsdatabase en transaksjon for å endre logisk relaterte objekter (ordre - ordre elementer), noe som er nødvendig, siden disse er forskjellige tabeller. Med riktig design av datamodellen i en NoSQL-database (et aggregat er en ordre sammen med en liste over ordreelementer), kan du oppnå samme nivå av isolasjon når du endrer en enkelt post som i en relasjonsdatabase.
3.2. Distribuerte systemer, ingen delte ressurser (del ingenting)
Igjen, dette gjelder ikke databasegrafer, hvis struktur, per definisjon, ikke sprer seg godt over eksterne noder.
Dette er kanskje hovedledemotivet i utviklingen av NoSQL-databaser. Med skredveksten av informasjon i verden og behovet for å behandle den innen rimelig tid, oppsto problemet med vertikal skalerbarhet - veksten av prosessorhastigheten stoppet ved 3,5 GHz, hastigheten på lesing fra disken vokser også med en sakte tempo, pluss at prisen på en kraftig server alltid er høyere enn totalprisen på flere enkle servere. I denne situasjonen er konvensjonelle relasjonsdatabaser, selv gruppert på en rekke disker, ikke i stand til å løse problemet med hastighet, skalerbarhet og gjennomstrømning.
Den eneste veien ut av situasjonen er horisontal skalering, når flere uavhengige servere er koblet sammen med et raskt nettverk og hver eier / behandler bare deler av dataene og/eller bare deler av leseoppdateringsforespørslene. I denne arkitekturen, for å øke lagringskapasiteten (kapasitet, responstid, gjennomstrømning), trenger du bare å legge til en ny server til klyngen – og det er det. Deling, replikering, feiltoleranse (resultatet vil bli oppnådd selv om en eller flere servere slutter å svare), omdistribuering av data ved å legge til en node håndteres av selve NoSQL-databasen.
Jeg vil kort presentere hovedegenskapene til distribuerte NoSQL-databaser:
Replikering - kopiering av data til andre noder ved oppdatering. Tillater både å oppnå større skalerbarhet og øke tilgjengeligheten og sikkerheten til data. Det er vanlig å dele inn i to typer:
master-slave : og peer-to-peer :
og peer-to-peer : 
Den første typen forutsetter god skalerbarhet for lesing (kan skje fra hvilken som helst node), men ikke-skalerbar skriving (bare til masternoden). Det er også finesser med å sikre konstant tilgjengelighet (i tilfelle en masterkrasj, enten manuelt eller automatisk blir en av de gjenværende nodene tildelt sin plass). Den andre typen replikering forutsetter at alle noder er like og kan betjene både lese- og skriveforespørsler.
Sharding er deling av data etter noder:

Sharding ble ofte brukt som en "krykke" til relasjonsdatabaser for å øke hastigheten og gjennomstrømningen: brukerapplikasjonen partisjonerte data på tvers av flere uavhengige databaser og, når brukeren ba om tilsvarende data, fikk han tilgang til en spesifikk database. I NoSQL-databaser gjøres sharding, som replikering, automatisk av databasen selv, og brukerapplikasjonen er atskilt fra disse komplekse mekanismene.
3.3. NoSQL-databaser er stort sett åpen kildekode og opprettet i det 21. århundre
Det er på den andre grunnen at Sadalaj og Fowler ikke klassifiserte objektdatabaser som NoSQL (selv om http://nosql-database.org/ inkluderer dem i den generelle listen), siden de ble opprettet på 90-tallet og aldri fikk mye popularitet ...
NoSQL-bevegelsen blir stadig mer populær i et gigantisk tempo. Dette betyr imidlertid ikke at relasjonsdatabaser blir rudimentale eller noe arkaisk. Mest sannsynlig vil de bli brukt og brukt som før aktivt, men flere og flere NoSQL-databaser vil opptre i symbiose med dem. Vi går inn i en epoke med polyglot-utholdenhet, en epoke hvor forskjellige datalagre brukes til forskjellige behov. Nå er det ikke monopol på relasjonsdatabaser som en ubestridt kilde til data. I økende grad velger arkitekter lagring basert på naturen til selve dataene og hvordan vi ønsker å manipulere dem, hvilke mengder informasjon som forventes. Og så blir alt bare mer interessant.
Nedenfor vil vi prøve å forstå driften av en distribuert database ved å bruke NoSQL Cassandra DBMS som et eksempel ...
GO TO FULL VERSION