3.1. คุณสมบัติของกรดอ่อน
เป็นเวลานานแล้วที่ความสอดคล้องของข้อมูลเป็นสิ่งศักดิ์สิทธิ์สำหรับสถาปนิกและนักพัฒนา ฐานข้อมูลเชิงสัมพันธ์ทั้งหมดจัดให้มีการแยกในระดับหนึ่ง ไม่ว่าจะผ่านการล็อกการอัปเดตและการบล็อกการอ่าน หรือผ่านการเลิกทำล็อก ด้วยการกำเนิดของข้อมูลจำนวนมากและระบบกระจาย เป็นที่ชัดเจนว่าเป็นไปไม่ได้ที่จะรับประกันชุดการดำเนินการทางธุรกรรมสำหรับพวกเขา ในแง่หนึ่ง และเพื่อให้ได้ความพร้อมใช้งานสูงและเวลาตอบสนองที่รวดเร็ว ในทางกลับกัน
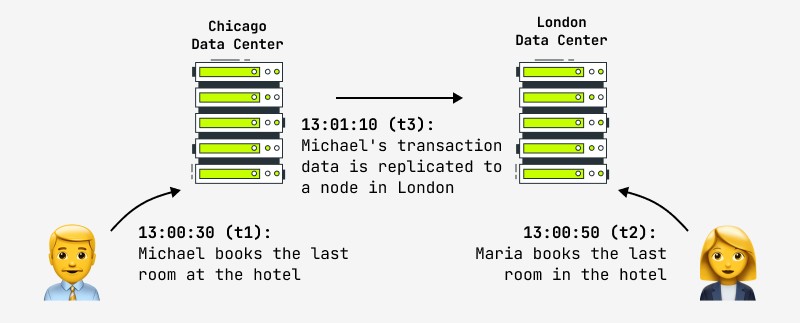
ยิ่งกว่านั้น การอัปเดตเรกคอร์ดหนึ่งรายการไม่ได้รับประกันว่าผู้ใช้รายอื่นจะเห็นการเปลี่ยนแปลงในระบบทันที เนื่องจากการเปลี่ยนแปลงสามารถเกิดขึ้นได้ เช่น ในโหนดหลัก และแบบจำลองจะถูกคัดลอกแบบอะซิงโครนัสไปยังโหนดสเลฟ โดยที่ผู้ใช้รายอื่น ทำงาน ในกรณีนี้เขาจะเห็นผลหลังจากช่วงระยะเวลาหนึ่ง สิ่งนี้เรียกว่าความสม่ำเสมอในท้ายที่สุด และนี่คือสิ่งที่บริษัทอินเทอร์เน็ตรายใหญ่ที่สุดในโลกกำลังดำเนินการอยู่ในขณะนี้ รวมถึง Facebook และ Amazon หลังประกาศอย่างภาคภูมิใจว่าช่วงเวลาสูงสุดที่ผู้ใช้สามารถดูข้อมูลที่ไม่สอดคล้องกันนั้นไม่เกินหนึ่งวินาที ตัวอย่างของสถานการณ์ดังกล่าวแสดงในรูป:
คำถามเชิงตรรกะที่เกิดขึ้นในสถานการณ์เช่นนี้คือจะทำอย่างไรกับระบบที่มีความต้องการสูงในการดำเนินงานที่สอดคล้องกันในระดับปรมาณูและในขณะเดียวกันก็ต้องการคลัสเตอร์แบบกระจายอย่างรวดเร็ว เช่น การเงิน ร้านค้าออนไลน์ ฯลฯ การปฏิบัติแสดงให้เห็นว่าข้อกำหนดเหล่านี้ไม่เกี่ยวข้องอีกต่อไป: นี่คือสิ่งที่ผู้ออกแบบระบบการเงินการธนาคารคนหนึ่งกล่าวว่า: "หากเรารอให้ธุรกรรมแต่ละรายการเสร็จสิ้นในเครือข่ายตู้เอทีเอ็ม (ATM) ทั่วโลก การทำธุรกรรมจะใช้เวลานานมากจนลูกค้า จะวิ่งหนีด้วยความโกรธ จะเกิดอะไรขึ้นหากคุณและคู่ของคุณถอนเงินพร้อมกันและเกินวงเงิน? “คุณจะได้เงินทั้งคู่ และเราจะแก้ไขในภายหลัง”

อีกตัวอย่างหนึ่งคือการจองโรงแรมที่แสดงในภาพ ร้านค้าออนไลน์ที่มีนโยบายข้อมูลถือว่ามีความสอดคล้องกันในขั้นสุดท้ายจำเป็นต้องจัดเตรียมมาตรการในกรณีของสถานการณ์ดังกล่าว (การแก้ไขข้อขัดแย้งโดยอัตโนมัติ การย้อนกลับการดำเนินการ การอัปเดตด้วยข้อมูลอื่นๆ) ในทางปฏิบัติ โรงแรมมักจะพยายามรักษา "สระว่ายน้ำ" ของห้องพักว่างไว้เสมอในกรณีฉุกเฉิน และนี่อาจเป็นวิธีแก้ปัญหาสำหรับสถานการณ์ที่เป็นข้อขัดแย้ง
ในความเป็นจริง คุณสมบัติของกรดอ่อนไม่ได้หมายความว่าไม่มีอยู่จริง ในกรณีส่วนใหญ่ แอปพลิเคชันที่ทำงานกับฐานข้อมูลเชิงสัมพันธ์จะใช้ธุรกรรมเพื่อเปลี่ยนออบเจ็กต์ที่เกี่ยวข้องเชิงตรรกะ (ลำดับ - รายการสั่งซื้อ) ซึ่งจำเป็น เนื่องจากเป็นตารางที่แตกต่างกัน ด้วยการออกแบบโมเดลข้อมูลที่ถูกต้องในฐานข้อมูล NoSQL (การรวมคือคำสั่งซื้อพร้อมกับรายการของรายการสั่งซื้อ) คุณสามารถบรรลุการแยกระดับเดียวกันได้เมื่อเปลี่ยนระเบียนเดียวในฐานข้อมูลเชิงสัมพันธ์
3.2. ระบบกระจาย ไม่มีทรัพยากรที่ใช้ร่วมกัน (ไม่มีอะไรแบ่งปัน)
อีกครั้ง สิ่งนี้ใช้ไม่ได้กับกราฟฐานข้อมูล ซึ่งตามคำนิยาม โครงสร้างไม่กระจายไปทั่วโหนดระยะไกล
นี่อาจเป็นบรรทัดฐานหลักของการพัฒนาฐานข้อมูล NoSQL ด้วยการเติบโตของข้อมูลในโลกอย่างถล่มทลายและความจำเป็นในการประมวลผลในเวลาที่เหมาะสม ปัญหาของความสามารถในการปรับขนาดตามแนวตั้งจึงเกิดขึ้น - การเติบโตของความเร็วโปรเซสเซอร์หยุดที่ 3.5 GHz ความเร็วในการอ่านจากดิสก์ก็เพิ่มขึ้นเช่นกัน ก้าวช้า บวกกับราคาของเซิร์ฟเวอร์ที่ทรงพลังมักจะสูงกว่าราคารวมของเซิร์ฟเวอร์ทั่วไปหลายตัวเสมอ ในสถานการณ์นี้ ฐานข้อมูลเชิงสัมพันธ์ทั่วไป แม้แต่คลัสเตอร์ในอาร์เรย์ของดิสก์ ก็ไม่สามารถแก้ปัญหาความเร็ว ความสามารถในการปรับขนาด และปริมาณงานได้
ทางออกเดียวของสถานการณ์คือการปรับขนาดในแนวนอนเมื่อเซิร์ฟเวอร์อิสระหลายเครื่องเชื่อมต่อกันด้วยเครือข่ายที่รวดเร็วและแต่ละเซิร์ฟเวอร์เป็นเจ้าของ / ประมวลผลข้อมูลเพียงบางส่วนและ / หรือเพียงส่วนหนึ่งของคำขออ่าน-อัปเดต ในสถาปัตยกรรมนี้ หากต้องการเพิ่มความจุของหน่วยเก็บข้อมูล (ความจุ เวลาตอบสนอง ปริมาณงาน) คุณเพียงแค่เพิ่มเซิร์ฟเวอร์ใหม่ลงในคลัสเตอร์เท่านั้น เพียงเท่านี้ การแยกย่อย การจำลองแบบ การยอมรับข้อผิดพลาด (ผลลัพธ์จะได้รับแม้ว่าเซิร์ฟเวอร์อย่างน้อยหนึ่งเซิร์ฟเวอร์จะหยุดตอบสนอง) การกระจายข้อมูลในกรณีที่มีการเพิ่มโหนดจะถูกจัดการโดยฐานข้อมูล NoSQL เอง
ฉันจะนำเสนอคุณสมบัติหลักของฐานข้อมูล NoSQL แบบกระจายโดยสังเขป:
การจำลองแบบ - คัดลอกข้อมูลไปยังโหนดอื่นเมื่ออัปเดต ช่วยให้ทั้งสองบรรลุความสามารถในการปรับขนาดได้มากขึ้นและเพิ่มความพร้อมใช้งานและความปลอดภัยของข้อมูล เป็นเรื่องปกติที่จะแบ่งออกเป็นสองประเภท:
master-slave : และpeer-to-peer :
และpeer-to-peer : 
ประเภทแรกถือว่ามีความสามารถในการปรับขนาดได้ดีสำหรับการอ่าน (สามารถเกิดขึ้นได้จากโหนดใดก็ได้) แต่เป็นการเขียนที่ไม่สามารถปรับขนาดได้ (เฉพาะกับโหนดหลักเท่านั้น) นอกจากนี้ยังมีรายละเอียดปลีกย่อยที่รับประกันความพร้อมใช้งานอย่างต่อเนื่อง (ในกรณีที่มาสเตอร์ขัดข้อง โหนดที่เหลืออันใดอันหนึ่งจะถูกกำหนดด้วยตนเองหรือโดยอัตโนมัติ) การจำลองแบบที่สองถือว่าโหนดทั้งหมดเท่ากันและสามารถให้บริการทั้งคำขออ่านและเขียน
Shardingคือการแบ่งข้อมูลตามโหนด:

Shardingมักถูกใช้เป็น "ค้ำยัน" ให้กับฐานข้อมูลเชิงสัมพันธ์เพื่อเพิ่มความเร็วและปริมาณงาน: แอปพลิเคชันของผู้ใช้แบ่งพาร์ติชันข้อมูลในฐานข้อมูลอิสระหลายฐานข้อมูล และเมื่อผู้ใช้ร้องขอข้อมูลที่เกี่ยวข้อง จะเข้าถึงฐานข้อมูลเฉพาะ ในฐานข้อมูล NoSQL การแบ่งส่วน เช่น การจำลองแบบ จะทำโดยอัตโนมัติโดยตัวฐานข้อมูลเอง และแอปพลิเคชันของผู้ใช้จะแยกออกจากกลไกที่ซับซ้อนเหล่านี้
3.3. ฐานข้อมูล NoSQL ส่วนใหญ่เป็นโอเพ่นซอร์สและสร้างขึ้นในศตวรรษที่ 21
ด้วยเหตุผลที่สอง Sadalaj และ Fowler ไม่ได้จัดประเภทฐานข้อมูลวัตถุเป็น NoSQL (แม้ว่า http://nosql-database.org/ จะรวมไว้ในรายการทั่วไป) เนื่องจากสร้างขึ้นในทศวรรษที่ 90 และไม่เคยได้รับความนิยมมากนัก . .
การเคลื่อนไหวของ NoSQL กำลังได้รับความนิยมอย่างรวดเร็ว อย่างไรก็ตาม นี่ไม่ได้หมายความว่าฐานข้อมูลเชิงสัมพันธ์จะกลายเป็นร่องรอยหรือเป็นสิ่งที่ล้าสมัย เป็นไปได้มากว่าพวกมันจะถูกใช้และใช้งานเหมือนเมื่อก่อน แต่ฐานข้อมูล NoSQL จำนวนมากขึ้นเรื่อย ๆ จะทำงานร่วมกัน เรากำลังเข้าสู่ยุคของการคงอยู่ของหลายภาษา ซึ่งเป็นยุคที่มีการใช้ที่เก็บข้อมูลที่แตกต่างกันสำหรับความต้องการที่แตกต่างกัน ขณะนี้ไม่มีการผูกขาดฐานข้อมูลเชิงสัมพันธ์ในฐานะแหล่งข้อมูลที่ไม่มีใครโต้แย้ง สถาปนิกเลือกที่เก็บข้อมูลมากขึ้นเรื่อยๆ ตามลักษณะของข้อมูลและวิธีที่เราต้องการจัดการ ปริมาณข้อมูลที่คาดว่าจะได้รับ และทุกอย่างก็น่าสนใจยิ่งขึ้น
ด้านล่างนี้เราจะพยายามทำความเข้าใจการทำงานของฐานข้อมูลแบบกระจายโดยใช้ NoSQL Cassandra DBMS เป็นตัวอย่าง ...
GO TO FULL VERSION