3.1. Svaga SYRA-egenskaper
Under lång tid har datakonsistens varit en helig ko för arkitekter och utvecklare. Alla relationsdatabaser gav en viss grad av isolering, antingen genom uppdateringslås och blockerande läsningar eller genom ångraloggar. Med tillkomsten av enorma mängder information och distribuerade system blev det klart att det var omöjligt att säkerställa en transaktionsuppsättning av operationer för dem, å ena sidan, och att få hög tillgänglighet och snabb svarstid, å andra sidan.
Dessutom garanterar inte ens uppdatering av en post att någon annan användare omedelbart kommer att se ändringar i systemet, eftersom ändringen kan ske, till exempel i masternoden, och repliken kopieras asynkront till slavnoden, med vilken en annan användare Arbetar. I det här fallet kommer han att se resultatet efter en viss tid. Detta kallas eventuell konsekvens och detta är vad alla de största internetföretagen i världen går till nu, inklusive Facebook och Amazon. De senare förklarar stolt att det maximala intervallet under vilket användaren kan se inkonsekventa data inte är mer än en sekund. Ett exempel på en sådan situation visas i figuren:
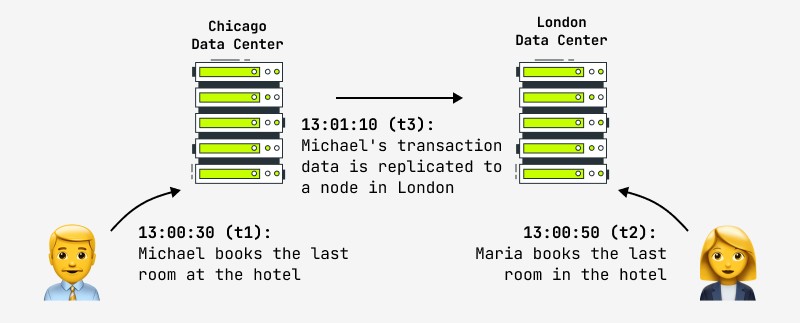
Den logiska frågan som uppstår i en sådan situation är vad man ska göra med system som klassiskt ställer höga krav på verksamhetens atomicitetskonsistens och som samtidigt behöver snabbt distribuerade kluster - finansiella, nätbutiker etc.? Praxis visar att dessa krav inte längre är relevanta: här är vad en designer av det finansiella banksystemet sa: "Om vi verkligen väntade på slutförandet av varje transaktion i det globala nätverket av uttagsautomater, skulle transaktionerna ta så lång tid att kunderna skulle springa iväg i raseri. Vad händer om du och din partner tar ut pengar samtidigt och överskrider gränsen? "Ni kommer båda att få pengarna och vi fixar det senare."

Ett annat exempel är hotellbokningen som visas på bilden. Onlinebutiker vars datapolicy förutsätter eventuell överensstämmelse är skyldiga att vidta åtgärder vid sådana situationer (automatisk konfliktlösning, återställning av operation, uppdatering med annan data). I praktiken försöker hotell alltid ha en "pool" av lediga rum i händelse av en nödsituation, och detta kan vara en lösning på en kontroversiell situation.
Faktum är att svaga ACID-egenskaper inte betyder att de inte existerar alls. I de flesta fall använder en applikation som arbetar med en relationsdatabas en transaktion för att ändra logiskt relaterade objekt (order - beställningsartiklar), vilket är nödvändigt, eftersom dessa är olika tabeller. Med korrekt design av datamodellen i en NoSQL-databas (ett aggregat är en beställning tillsammans med en lista med beställningsartiklar) kan du uppnå samma nivå av isolering när du ändrar en enskild post som i en relationsdatabas.
3.2. Distribuerade system, inga delade resurser (dela ingenting)
Återigen, detta gäller inte databasgrafer, vars struktur, per definition, inte sprider sig bra över avlägsna noder.
Detta är kanske det främsta ledmotivet i utvecklingen av NoSQL-databaser. Med lavintillväxten av information i världen och behovet av att bearbeta den inom rimlig tid uppstod problemet med vertikal skalbarhet - tillväxten av processorhastigheten stannade vid 3,5 GHz, hastigheten för att läsa från disken växer också med en långsamt tempo, plus att priset för en kraftfull server alltid är högre än det totala priset för flera enkla servrar. I den här situationen kan konventionella relationsdatabaser, även klustrade på en rad diskar, inte lösa problemet med hastighet, skalbarhet och genomströmning.
Den enda vägen ut ur situationen är horisontell skalning, när flera oberoende servrar är sammankopplade med ett snabbt nätverk och var och en äger/bearbetar endast en del av datan och/eller endast en del av läsuppdateringsbegäran. I den här arkitekturen, för att öka lagringskapaciteten (kapacitet, svarstid, genomströmning), behöver du bara lägga till en ny server till klustret - och det är allt. Sharding, replikering, feltolerans (resultatet kommer att erhållas även om en eller flera servrar slutar svara), omfördelning av data vid tillägg av en nod hanteras av själva NoSQL-databasen.
Jag kommer kort att presentera huvudegenskaperna hos distribuerade NoSQL-databaser:
Replikering - kopiering av data till andra noder vid uppdatering. Tillåter både att uppnå större skalbarhet och öka tillgängligheten och säkerheten för data. Det är vanligt att dela upp i två typer:
master-slave : och peer-to-peer :
och peer-to-peer : 
Den första typen förutsätter god skalbarhet för läsning (kan ske från vilken nod som helst), men icke-skalbar skrivning (endast till masternoden). Det finns också finesser med att säkerställa konstant tillgänglighet (i händelse av en masterkrasch, antingen manuellt eller automatiskt tilldelas en av de återstående noderna sin plats). Den andra typen av replikering förutsätter att alla noder är lika och kan betjäna både läs- och skrivförfrågningar.
Sharding är uppdelningen av data efter noder:

Sharding användes ofta som en "krycka" till relationsdatabaser för att öka hastigheten och genomströmningen: användarapplikationen partitionerade data över flera oberoende databaser och, när användaren begärde motsvarande data, kom åt en specifik databas. I NoSQL-databaser görs sharding, liksom replikering, automatiskt av databasen själv och användarapplikationen är skild från dessa komplexa mekanismer.
3.3. NoSQL-databaser är mestadels öppen källkod och skapades på 2000-talet
Det är på den andra grunden att Sadalaj och Fowler inte klassificerade objektdatabaser som NoSQL (även om http://nosql-database.org/ inkluderar dem i den allmänna listan), eftersom de skapades på 90-talet och aldrig blev så populärt. ...
NoSQL-rörelsen vinner popularitet i en gigantisk takt. Detta betyder dock inte att relationsdatabaser håller på att bli rudimentala eller något ålderdomliga. Troligtvis kommer de att användas och användas som tidigare aktivt, men fler och fler NoSQL-databaser kommer att agera i symbios med dem. Vi går in i en era av polyglot persistens, en era där olika datalager används för olika behov. Nu finns det inget monopol på relationsdatabaser som en obestridd datakälla. Allt oftare väljer arkitekter lagring baserat på själva datan och hur vi vill manipulera den, vilka mängder information som förväntas. Och så blir allt bara mer intressant.
Nedan kommer vi att försöka förstå driften av en distribuerad databas med hjälp av NoSQL Cassandra DBMS som ett exempel ...
GO TO FULL VERSION