3.1. Zayıf ASİT özellikleri
Uzun süredir veri tutarlılığı, mimarlar ve geliştiriciler için kutsal bir inek olmuştur. Tüm ilişkisel veritabanları, güncelleme kilitleri ve okumaları engelleme veya geri alma günlükleri aracılığıyla bir düzeyde yalıtım sağladı. Büyük miktarda bilgi ve dağıtılmış sistemlerin ortaya çıkmasıyla birlikte, bir yandan onlar için işlemsel bir dizi işlem sağlamanın, diğer yandan yüksek kullanılabilirlik ve hızlı yanıt süresi elde etmenin imkansız olduğu ortaya çıktı.
Ayrıca, bir kaydın güncellenmesi bile, başka herhangi bir kullanıcının sistemdeki değişiklikleri anında göreceğini garanti etmez, çünkü değişiklik, örneğin ana düğümde meydana gelebilir ve kopya, başka bir kullanıcının birlikte olduğu bağımlı düğüme eşzamansız olarak kopyalanır. İşler. Bu durumda belli bir süre sonra sonucu görecektir. Buna nihai tutarlılık denir ve bu, Facebook ve Amazon da dahil olmak üzere dünyanın en büyük İnternet şirketlerinin şimdi gideceği şeydir. İkincisi, kullanıcının tutarsız verileri görebileceği maksimum aralığın bir saniyeden fazla olmadığını gururla beyan eder. Böyle bir duruma bir örnek şekilde gösterilmiştir:
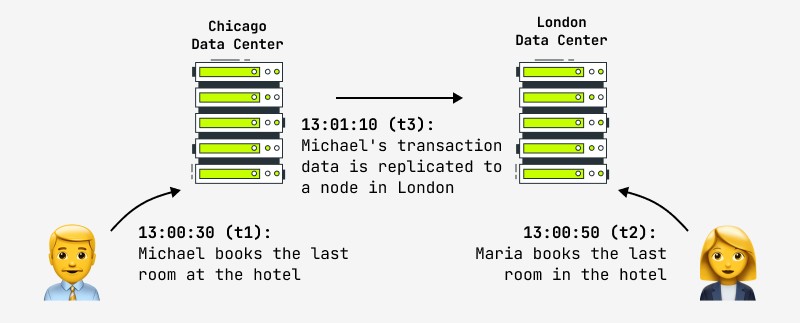
Böyle bir durumda ortaya çıkan mantıksal soru, klasik olarak operasyonların atomikliği-tutarlılığına yüksek talepler getiren ve aynı zamanda hızlı dağıtılmış kümelere (finansal, çevrimiçi mağazalar vb.) ihtiyaç duyan sistemlerle ne yapılacağıdır. Uygulama, bu gereksinimlerin artık geçerli olmadığını gösteriyor: finansal bankacılık sisteminin bir tasarımcısı şöyle dedi: “Küresel ATM ağındaki (ATM'ler) her işlemin tamamlanmasını gerçekten bekleseydik, işlemler o kadar uzun sürerdi ki müşteriler öfkeyle kaçacaktı. Siz ve eşiniz aynı anda para çeker ve limiti aşarsanız ne olur? "İkiniz de parayı alacaksınız, sonra halledeceğiz."

Bir başka örnek de resimde gösterilen otel rezervasyonudur. Veri politikası nihai tutarlılığı kabul eden çevrimiçi mağazaların, bu tür durumlara karşı önlemler (otomatik çakışma çözümü, operasyon geri alma, diğer verilerle güncelleme) sağlaması gerekir. Uygulamada, oteller her zaman acil bir durumda boş odalardan oluşan bir “havuz” tutmaya çalışır ve bu, tartışmalı bir duruma bir çözüm olabilir.
Aslında, zayıf ASİT özellikleri hiç var olmadıkları anlamına gelmez. Çoğu durumda, ilişkisel bir veritabanıyla çalışan bir uygulama, mantıksal olarak ilişkili nesneleri (sipariş - sipariş öğeleri) değiştirmek için bir işlem kullanır; bu, bunlar farklı tablolar olduğundan gereklidir. Bir NoSQL veritabanındaki veri modelinin doğru tasarımıyla (toplama, sipariş öğelerinin listesiyle birlikte bir sipariştir), tek bir kaydı değiştirirken ilişkisel bir veritabanında olduğu gibi aynı düzeyde yalıtım elde edebilirsiniz.
3.2. Dağıtılmış sistemler, paylaşılan kaynak yok (hiçbir şey paylaşma)
Yine, bu, yapısı tanım gereği uzak düğümler arasında iyi yayılmayan veritabanı grafikleri için geçerli değildir.
Bu belki de NoSQL veritabanlarının geliştirilmesinin ana motifidir. Dünyadaki bilginin çığ gibi büyümesi ve onu makul bir sürede işleme ihtiyacı ile dikey ölçeklenebilirlik sorunu ortaya çıktı - işlemci hızındaki artış 3,5 GHz'de durdu, diskten okuma hızı da artıyor. yavaş tempo, artı güçlü bir sunucunun fiyatı her zaman birkaç basit sunucunun toplam fiyatından daha fazladır. Bu durumda, bir dizi disk üzerinde kümelenmiş olsalar bile geleneksel ilişkisel veritabanları hız, ölçeklenebilirlik ve verim sorununu çözemez.
Bu durumdan kurtulmanın tek yolu, birkaç bağımsız sunucu hızlı bir ağ ile bağlandığında ve her birinin verilerin yalnızca bir kısmına ve / veya okuma-güncelleme isteklerinin yalnızca bir kısmına sahip olduğu / işlediği yatay ölçeklendirmedir. Bu mimaride, depolama kapasitesini (kapasite, yanıt süresi, verim) artırmak için yalnızca kümeye yeni bir sunucu eklemeniz yeterlidir - hepsi bu. Sharding, replikasyon, hata toleransı (sonuç, bir veya daha fazla sunucu yanıt vermeyi durdursa bile elde edilecektir), bir düğüm eklenmesi durumunda verilerin yeniden dağıtılması, NoSQL veritabanının kendisi tarafından gerçekleştirilir.
Dağıtılmış NoSQL veritabanlarının ana özelliklerini kısaca sunacağım:
Çoğaltma - güncelleme sırasında verileri diğer düğümlere kopyalama. Hem daha fazla ölçeklenebilirlik elde etmeyi hem de verilerin kullanılabilirliğini ve güvenliğini artırmayı sağlar. İki türe ayırmak gelenekseldir:
master-slave : ve eşler arası :
ve eşler arası : 
İlk tip, okuma için iyi ölçeklenebilirlik (herhangi bir düğümden olabilir), ancak ölçeklenemeyen yazma (yalnızca ana düğüme) varsayar. Sürekli kullanılabilirliği sağlamanın incelikleri de vardır (bir ana çökme durumunda, manuel veya otomatik olarak kalan düğümlerden biri yerine atanır). İkinci çoğaltma türü, tüm düğümlerin eşit olduğunu ve hem okuma hem de yazma isteklerine hizmet edebildiğini varsayar.
Parçalama , verilerin düğümlere göre bölünmesidir:

Parçalama, hızı ve verimi artırmak için genellikle ilişkisel veritabanlarında bir "koltuk değneği" olarak kullanılıyordu: kullanıcı uygulaması, verileri birkaç bağımsız veritabanı arasında bölümledi ve kullanıcı karşılık gelen verileri istediğinde, belirli bir veritabanına erişti. NoSQL veritabanlarında parçalama, replikasyon gibi veritabanının kendisi tarafından otomatik olarak yapılır ve kullanıcı uygulaması bu karmaşık mekanizmalardan ayrıdır.
3.3. NoSQL veritabanları çoğunlukla açık kaynaklıdır ve 21. yüzyılda oluşturulmuştur.
Sadalaj ve Fowler'ın nesne veritabanlarını 90'larda oluşturuldukları ve hiçbir zaman fazla popülerlik kazanmadıkları için (http://nosql-database.org/ onları genel listeye dahil etmesine rağmen) NoSQL olarak sınıflandırmadıkları ikinci gerekçedir. . .
NoSQL hareketi devasa bir hızla popülerlik kazanıyor. Ancak bu, ilişkisel veritabanlarının köreldiği veya arkaik bir şey olduğu anlamına gelmez. Büyük olasılıkla daha önce olduğu gibi aktif olarak kullanılacaklar ve kullanılacaklar, ancak giderek daha fazla NoSQL veri tabanı onlarla ortak yaşam içinde hareket edecek. Farklı ihtiyaçlar için farklı veri depolarının kullanıldığı bir çağ olan çok dilli kalıcılık çağına giriyoruz. Artık tartışmasız bir veri kaynağı olarak ilişkisel veritabanlarının tekeli yoktur. Mimarlar, giderek artan bir şekilde, verilerin doğasına ve onu nasıl manipüle etmek istediğimize, hangi bilgi hacimlerinin beklendiğine bağlı olarak depolamayı seçiyor. Ve böylece her şey daha da ilginçleşiyor.
Aşağıda, örnek olarak NoSQL Cassandra DBMS kullanarak dağıtılmış bir veritabanının çalışmasını anlamaya çalışacağız ...
GO TO FULL VERSION