3.1. Propiedades ACID débiles
Durante mucho tiempo, la consistencia de los datos ha sido una vaca sagrada para arquitectos y desarrolladores. Todas las bases de datos relacionales proporcionaron cierto nivel de aislamiento, ya sea mediante bloqueos de actualización y bloqueo de lecturas, o mediante registros de deshacer. Con la llegada de grandes cantidades de información y sistemas distribuidos, se hizo evidente que era imposible asegurarles un conjunto transaccional de operaciones, por un lado, y obtener una alta disponibilidad y un tiempo de respuesta rápido, por el otro.
Además, incluso la actualización de un registro no garantiza que cualquier otro usuario vea instantáneamente los cambios en el sistema, porque el cambio puede ocurrir, por ejemplo, en el nodo maestro, y la réplica se copia de forma asíncrona en el nodo esclavo, con el que otro usuario obras. En este caso, verá el resultado después de un cierto período de tiempo. Esto se llama consistencia eventual y esto es lo que van a hacer ahora todas las empresas de Internet más grandes del mundo, incluidas Facebook y Amazon. Estos últimos declaran con orgullo que el intervalo máximo durante el cual el usuario puede ver datos inconsistentes no es más de un segundo. Un ejemplo de tal situación se muestra en la figura:
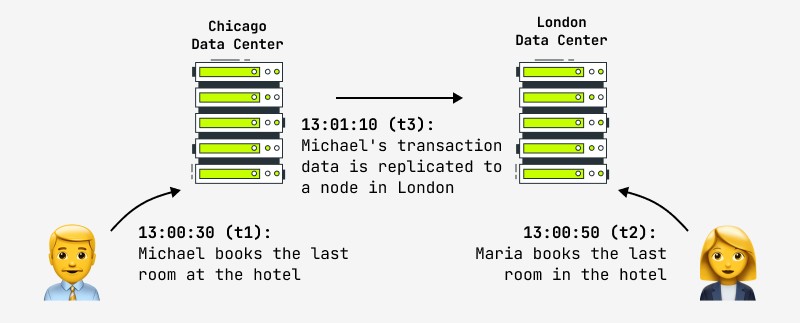
La pregunta lógica que surge en tal situación es qué hacer con los sistemas que clásicamente imponen altas demandas en la atomicidad-consistencia de las operaciones y al mismo tiempo necesitan clústeres distribuidos rápidamente (financieros, tiendas en línea, etc.). La práctica demuestra que estos requisitos ya no son relevantes: esto es lo que dijo un diseñador del sistema bancario financiero: “Si realmente esperáramos a que se completara cada transacción en la red global de cajeros automáticos (ATM), las transacciones tardarían tanto que los clientes huiría en un ataque de furia. ¿Qué sucede si usted y su pareja retiran dinero al mismo tiempo y superan el límite? "Ambos obtendrán el dinero y lo arreglaremos más tarde".

Otro ejemplo es la reserva de hotel que se muestra en la imagen. Las tiendas en línea cuya política de datos asume la coherencia eventual están obligadas a proporcionar medidas en caso de tales situaciones (resolución automática de conflictos, reversión de operaciones, actualización con otros datos). En la práctica, los hoteles siempre intentan mantener un “pool” de habitaciones libres en caso de emergencia, y esto puede ser una solución a una situación controvertida.
De hecho, las propiedades débiles de ACID no significan que no existan en absoluto. En la mayoría de los casos, una aplicación que trabaja con una base de datos relacional utiliza una transacción para cambiar objetos relacionados lógicamente (pedido - artículos de pedido), lo cual es necesario, ya que se trata de tablas diferentes. Con el diseño correcto del modelo de datos en una base de datos NoSQL (un agregado es un pedido junto con una lista de artículos de pedido), puede lograr el mismo nivel de aislamiento al cambiar un solo registro que en una base de datos relacional.
3.2. Sistemas distribuidos, sin recursos compartidos (no comparten nada)
Una vez más, esto no se aplica a los gráficos de bases de datos, cuya estructura, por definición, no se distribuye bien entre los nodos remotos.
Este es quizás el principal leitmotiv del desarrollo de las bases de datos NoSQL. Con el crecimiento de la avalancha de información en el mundo y la necesidad de procesarla en un tiempo razonable, surgió el problema de la escalabilidad vertical: el crecimiento de la velocidad del procesador se detuvo en 3,5 GHz, la velocidad de lectura del disco también está creciendo a un ritmo ritmo lento, además el precio de un servidor potente es siempre más que el precio total de varios servidores simples. En esta situación, las bases de datos relacionales convencionales, incluso agrupadas en una matriz de discos, no pueden resolver el problema de la velocidad, la escalabilidad y el rendimiento.
La única forma de salir de la situación es el escalado horizontal, cuando varios servidores independientes están conectados por una red rápida y cada uno posee/procesa solo una parte de los datos y/o solo una parte de las solicitudes de lectura y actualización. En esta arquitectura, para aumentar la capacidad de almacenamiento (capacidad, tiempo de respuesta, rendimiento), solo necesita agregar un nuevo servidor al clúster, y eso es todo. Sharding, replicación, tolerancia a fallas (el resultado se obtendrá incluso si uno o más servidores dejan de responder), la redistribución de datos en caso de agregar un nodo es manejada por la propia base de datos NoSQL.
Presentaré brevemente las principales propiedades de las bases de datos NoSQL distribuidas:
Replicación: copia de datos a otros nodos al actualizar. Permite tanto lograr una mayor escalabilidad como aumentar la disponibilidad y seguridad de los datos. Es costumbre subdividir en dos tipos:
maestro-esclavo : y peer-to-peer :
y peer-to-peer : 
El primer tipo asume una buena escalabilidad para lectura (puede ocurrir desde cualquier nodo), pero escritura no escalable (solo para el nodo maestro). También hay sutilezas para garantizar una disponibilidad constante (en caso de un bloqueo maestro, ya sea de forma manual o automática, uno de los nodos restantes se asigna a su lugar). El segundo tipo de replicación supone que todos los nodos son iguales y pueden atender solicitudes de lectura y escritura.
Sharding es la división de datos por nodos:

La fragmentación se usaba a menudo como una “muleta” para las bases de datos relacionales con el fin de aumentar la velocidad y el rendimiento: la aplicación del usuario particionaba los datos en varias bases de datos independientes y, cuando el usuario solicitaba los datos correspondientes, accedía a una base de datos específica. En las bases de datos NoSQL, la fragmentación, como la replicación, la realiza automáticamente la propia base de datos y la aplicación del usuario está separada de estos complejos mecanismos.
3.3. Las bases de datos NoSQL son en su mayoría de código abierto y se crearon en el siglo XXI.
Es por el segundo motivo que Sadalaj y Fowler no clasificaron las bases de datos de objetos como NoSQL (aunque http://nosql-database.org/ las incluye en la lista general), ya que fueron creadas allá por los años 90 y nunca alcanzaron mucha popularidad. . .
El movimiento NoSQL está ganando popularidad a un ritmo gigantesco. Sin embargo, esto no significa que las bases de datos relacionales se estén volviendo vestigiales o algo arcaicas. Lo más probable es que se utilicen y utilicen como antes de forma activa, pero cada vez más bases de datos NoSQL actuarán en simbiosis con ellas. Estamos entrando en una era de persistencia políglota, una era en la que se utilizan diferentes almacenes de datos para diferentes necesidades. Ahora no existe el monopolio de las bases de datos relacionales como fuente indiscutible de datos. Cada vez más, los arquitectos eligen el almacenamiento en función de la naturaleza de los datos en sí y de cómo queremos manipularlos, qué volúmenes de información se esperan. Y así todo se vuelve más interesante.
A continuación intentaremos entender el funcionamiento de una base de datos distribuida utilizando como ejemplo el DBMS NoSQL Cassandra...
GO TO FULL VERSION