Szia! A mai lecke kissé eltér a többitől. Abban különbözik, hogy csak közvetve kapcsolódik a Java-hoz. Ez a téma minden programozó számára nagyon fontos. Az algoritmusokról fogunk beszélni . Mi az algoritmus? Egyszerűen fogalmazva, ez egy bizonyos műveletsor, amelyet végre kell hajtani a kívánt eredmény eléréséhez . A mindennapi életben gyakran használunk algoritmusokat. Például minden reggel van egy konkrét feladatod: menj iskolába vagy munkába, és ezzel egyidőben legyél:
Felöltözve
Tiszta
Fed
Milyen algoritmussal érheti el ezt az eredményt?
Ébresztőóra segítségével ébredjen.
Zuhanyozz le és mosakodj meg.
Készítsen reggelit és kávét vagy teát.
Eszik.
Ha előző este nem vasalta ki a ruháit, akkor vasalja ki.
Öltözz fel.
Hagyja el a házat.
Ez a műveletsor biztosan lehetővé teszi a kívánt eredmény elérését. A programozásban folyamatosan dolgozunk a feladatok elvégzésén. E feladatok jelentős része már ismert algoritmusokkal is elvégezhető. Tegyük fel például, hogy a feladat a következő: rendezzen egy 100 nevet tartalmazó listát egy tömbben . Ez a feladat meglehetősen egyszerű, de többféleképpen is megoldható. Íme egy lehetséges megoldás: A nevek ábécé szerinti rendezésének algoritmusa:
Vásárolja meg vagy töltse le a Webster's Third New International Dictionary 1961-es kiadását.
Ebben a szótárban megtalálja a listánk összes nevét.
Írja fel egy papírra a szótár azon oldalát, amelyen a név található.
Használja a papírdarabokat a nevek rendezéséhez.
Vajon egy ilyen akciósorozat teljesíti a feladatunkat? Igen, biztosan így lesz. Hatékony ez a megoldás ? Alig. Itt elérkezünk az algoritmusok másik nagyon fontos szempontjához: a hatékonyságukhoz . Számos módja van ennek a feladatnak a végrehajtására. De mind a programozásban, mind a hétköznapi életben a leghatékonyabb módot akarjuk választani. Ha az a feladatod, hogy vajas pirítóst készíts, kezdheted búzavetéssel és tehenfejéssel. De ez nem lenne hatékonymegoldás – sok időt vesz igénybe és sok pénzbe fog kerülni. Elvégezheti egyszerű feladatát, ha egyszerűen vesz kenyeret és vajat. Bár lehetővé teszi a probléma megoldását, a búzát és a tehenet magában foglaló algoritmus túl bonyolult a gyakorlatban való használathoz. A programozásban van egy speciális jelölésünk, amelyet nagy O jelölésnek nevezünk , hogy felmérjük az algoritmusok összetettségét. A Big O lehetővé teszi annak felmérését, hogy egy algoritmus végrehajtási ideje mennyire függ a bemeneti adatok méretétől . Nézzük a legegyszerűbb példát: adatátvitelt. Képzelje el, hogy bizonyos információkat fájl formájában kell elküldenie nagy távolságra (például 5000 mérföldre). Melyik algoritmus lenne a leghatékonyabb? Ez attól függ, hogy milyen adatokkal dolgozik. Tegyük fel például, hogy van egy 10 MB-os hangfájlunk. Ebben az esetben a leghatékonyabb algoritmus a fájl elküldése az interneten keresztül. Nem tarthatott tovább pár percnél! Ismételjük meg az algoritmusunkat: "Ha 5000 mérföldes távolságra szeretne információkat fájlok formájában továbbítani, az adatokat az interneten keresztül kell elküldenie". Kiváló. Most pedig elemezzük. Elvégzi a feladatunkat?Nos, igen, így van. De mit mondhatunk a bonyolultságáról? Hmm, most a dolgok egyre érdekesebbek. Az a tény, hogy az algoritmusunk nagyon függ a bemeneti adatoktól, nevezetesen a fájlok méretétől. Ha van 10 megabájtunk, akkor minden rendben van. De mi van akkor, ha 500 megabájtot kell küldenünk? 20 gigabájt? 500 terabájt? 30 petabájt? Leáll az algoritmusunk működése? Nem, mindezen mennyiségű adat valóban átvihető. Tovább fog tartani? Igen fog! Most ismerjük algoritmusunk egy fontos jellemzőjét: minél nagyobb az elküldendő adatmennyiség, annál tovább tart az algoritmus futtatása.. De szeretnénk pontosabban megérteni ezt a kapcsolatot (a bemeneti adat mérete és az elküldéshez szükséges idő között). Esetünkben az algoritmus bonyolultsága lineáris . A "lineáris" azt jelenti, hogy a bemeneti adatok mennyiségének növekedésével az elküldéshez szükséges idő hozzávetőlegesen arányosan növekszik. Ha az adatmennyiség megduplázódik, akkor az elküldéshez szükséges idő kétszer annyi lesz. Ha az adatok száma 10-szeresére nő, akkor az átviteli idő 10-szeresére nő. A nagy O jelölést használva algoritmusunk összetettségét O(n) -ként fejezzük ki. Emlékezzen erre a jelölésre a jövőre nézve – mindig a lineáris összetettségű algoritmusoknál használják. Ne feledje, hogy itt nem több olyan dologról beszélünk, amelyek eltérőek lehetnek: az internet sebességéről, a számítógépünk számítási teljesítményéről és így tovább. Egy algoritmus összetettségének értékelése során egyszerűen nincs értelme figyelembe venni ezeket a tényezőket – mindenesetre kívül esnek rajtunk. A Big O jelölés magának az algoritmusnak a bonyolultságát fejezi ki, nem azt a „környezetet”, amelyben fut. Folytassuk példánkkal. Tegyük fel, hogy végül megtudjuk, hogy összesen 800 terabájtnyi fájlt kell küldenünk. Feladatunkat természetesen úgy is teljesíthetjük, ha elküldjük őket az interneten keresztül. Csak egy probléma van: normál háztartási adatátviteli sebesség mellett (100 megabit/másodperc) ez körülbelül 708 napot vesz igénybe. Majdnem 2 éve! :O Az algoritmusunk nyilvánvalóan nem illik ide. Más megoldásra van szükségünk! Váratlanul az IT óriás Amazon jön a segítségünkre! Az Amazon Snowmobile szolgáltatása lehetővé teszi, hogy nagy mennyiségű adatot töltsünk fel mobil tárhelyre, majd teherautóval szállítsuk ki a kívánt címre! Tehát van egy új algoritmusunk! "Ha 5000 mérföldes távolságra szeretne információkat fájlok formájában továbbítani, és ennek az interneten keresztül történő elküldése több mint 14 napot vesz igénybe, akkor az adatokat egy Amazon teherautón kell elküldenie." Itt önkényesen 14 napot választottunk. Tegyük fel, hogy ez a leghosszabb időszak, amit várhatunk. Elemezzük az algoritmusunkat. Mi a helyzet a sebességével? Még ha a teherautó csak 50 mérföld/órás sebességgel halad is, mindössze 100 óra alatt 5000 mérföldet tesz meg. Ez kicsit több, mint négy nap! Ez sokkal jobb, mint az adatok interneten keresztüli küldése. És mi a helyzet ennek az algoritmusnak a bonyolultságával? Lineáris is, azaz O(n)? Nem, ez nem. Végtére is, a teherautónak nem mindegy, milyen erősen rakod fel – továbbra is nagyjából ugyanolyan sebességgel fog haladni, és időben megérkezik. Akár 800 terabájtunk van, akár ennek 10-szerese, a kamion 5 napon belül mégis célba ér. Más szóval, a teherautó-alapú adatátviteli algoritmus állandó bonyolultságú. Itt az "állandó" azt jelenti, hogy nem függ a bemeneti adat méretétől. Tegyél a kamionba egy 1GB-os pendrive-ot, 5 napon belül megérkezik. Tedd be a 800 terabájtnyi adatot tartalmazó lemezeket, 5 napon belül megérkezik. Ha nagy O jelölést használunk, az állandó komplexitást O(1) jelöli . Megismerkedtünk az O(n) és az O(1) -vel, így most nézzünk még több példát a programozás világából :) Tegyük fel, hogy kapsz egy 100 számból álló tömböt, és a feladat az, hogy mindegyiket megjelenítsd a konzolt. Írsz egy közönséges forciklust, amely végrehajtja ezt a feladatot
int[] numbers =newint[100];// ...fill the array with numbersfor(int i: numbers){System.out.println(i);}
Mi ennek az algoritmusnak a bonyolultsága? Lineáris, azaz O(n). A programnak végrehajtandó műveletek száma attól függ, hogy hány számot adnak át neki. Ha 100 szám van a tömbben, akkor 100 művelet lesz (utasítások a karakterláncok képernyőn történő megjelenítéséhez). Ha 10 000 szám van a tömbben, akkor 10 000 műveletet kell végrehajtani. Javítható-e az algoritmusunk valamilyen módon? Nem. Nem számít, mi lesz, N alkalommal kell áthaladnunk a tömbön , és N utasítást kell végrehajtanunk ahhoz, hogy a karakterláncokat megjelenítsük a konzolon. Vegyünk egy másik példát.
Van egy üres LinkedList, amelybe több számot szúrunk be. Értékelnünk kell, hogy a példánkban egy szám beszúrásának milyen algoritmikus bonyolultsága van LinkedList, és hogyan függ ez a lista elemeinek számától. A válasz O(1), azaz állandó komplexitás . Miért? Vegye figyelembe, hogy minden számot beszúrunk a lista elejére. Ezen kívül emlékezni fog arra, hogy ha számot szúr be egy LinkedList, az elemek nem mozdulnak el sehova. A hivatkozások (vagy hivatkozások) frissülnek (ha elfelejtette a LinkedList működését, nézze meg egyik régi leckénket ). Ha a listánk első száma x, és az y számot beszúrjuk a lista elejére, akkor csak a következőt kell tennünk:
x.previous = y;
y.previous =null;
y.next = x;
Amikor frissítjük a hivatkozásokat, nem érdekel, hogy hány szám van már a -banLinkedList , egy vagy egymilliárd. Az algoritmus összetettsége állandó, azaz O(1).
Logaritmikus komplexitás
Ne essen pánikba! :) Ha a „logaritmikus” szó arra készteti, hogy bezárja ezt a leckét, és abbahagyja az olvasást, csak várjon néhány percig. Itt nem lesz őrült matek (bőven van ilyen magyarázat másutt), és minden példát szétszedünk. Képzeld el, hogy az a feladatod, hogy egy 100 számból álló tömbben találj egy adott számot. Pontosabban meg kell nézni, hogy ott van-e vagy sem. Amint megtalálja a kívánt számot, a keresés véget ér, és a következőt jeleníti meg a konzolon: "A szükséges szám megtalálható! Indexe a tömbben = ...." Hogyan valósítaná meg ezt a feladatot? Itt a megoldás kézenfekvő: a tömb elemeit egyenként át kell iterálni, az elsőtől (vagy az utolsótól) kezdve, és ellenőrizni kell, hogy az aktuális szám megegyezik-e a keresett számmal. Eszerint, a műveletek száma közvetlenül függ a tömb elemeinek számától. Ha 100 számunk van, akkor lehetséges, hogy 100-szor kell a következő elemhez lépnünk, és 100 összehasonlítást végeznünk. Ha 1000 szám van, akkor lehet 1000 összehasonlítás. Ez nyilvánvalóan lineáris komplexitás, plO(n) . És most egy finomítást adunk a példánkhoz: a tömb, ahol meg kell találnia a számot, növekvő sorrendben van rendezve . Változtat ez valamit a mi feladatunkon? Még mindig végrehajthatnánk egy brute-force keresést a kívánt számra. De alternatív megoldásként használhatjuk a jól ismert bináris keresési algoritmust . A kép felső sorában egy rendezett tömböt látunk. Meg kell találnunk benne a 23-as számot. A számok iterációja helyett egyszerűen 2 részre osztjuk a tömböt, és ellenőrizzük a tömb középső számát. Keresse meg a 4-es cellában található számot, és jelölje be (a képen a második sor). Ez a szám 16, mi pedig 23-at keresünk. A jelenlegi szám kevesebb, mint amit keresünk. Az mit jelent? Ez azt jelentiaz összes korábbi számot (a 16-os előtti számot) nem kell ellenőrizni : garantáltan kevesebb lesz, mint amit keresünk, mert a tömbünk rendezett! Folytatjuk a keresést a maradék 5 elem között. Jegyzet:csak egy összehasonlítást végeztünk, de a lehetséges lehetőségek felét már kiiktattuk. Már csak 5 elemünk maradt. Megismételjük az előző lépést úgy, hogy még egyszer kettéosztjuk a fennmaradó altömböt, és ismét vesszük a középső elemet (a képen a 3. sor). A szám 56, és nagyobb, mint a keresett. Az mit jelent? Ez azt jelenti, hogy további 3 lehetőséget kiszűrtünk: magát az 56-os számot, valamint az utána lévő két számot (hiszen ezek garantáltan nagyobbak, mint 23, mert a tömb rendezett). Már csak 2 számot kell ellenőriznünk (a képen az utolsó sor) – az 5-ös és 6-os tömbindexű számokat. Ellenőrizzük az elsőt, és megtaláljuk, amit kerestünk – a 23-as számot! Az indexe 5! Nézzük meg az algoritmusunk eredményeit, majd elemezni fogom a bonyolultságát. Egyébként most már megérted, miért hívják ezt bináris keresésnek: az adatok többszöri felezésén alapul. Az eredmény lenyűgöző! Ha lineáris kereséssel keresnénk a számot, akkor akár 10 összehasonlításra lenne szükségünk, de bináris kereséssel csak 3-mal teljesítettük a feladatot! A legrosszabb esetben 4 összehasonlítás lenne (ha az utolsó lépésben a kívánt szám a fennmaradó lehetőségek közül a második lenne, nem pedig az első. Na és mi van a bonyolultságával? Ez egy nagyon érdekes pont :) A bináris keresési algoritmus sokkal kevésbé függ a tömb elemeinek számától, mint a lineáris keresési algoritmus (vagyis az egyszerű iteráció). Ha a tömbben 10 elem van , a lineáris kereséshez legfeljebb 10, a bináris kereséshez viszont legfeljebb 4 összehasonlításra lesz szükség. Ez 2,5-szeres különbség. De egy 1000 elemből álló tömb esetén a lineáris kereséshez legfeljebb 1000 összehasonlításra van szükség, a bináris kereséshez viszont csak 10- re ! A különbség most 100-szoros! Jegyzet:a tömb elemeinek száma 100-szorosára nőtt (10-ről 1000-re), de a bináris kereséshez szükséges összehasonlítások száma mindössze 2,5-szeresére nőtt (4-ről 10-re). Ha elérjük a 10 000 elemet , a különbség még lenyűgözőbb lesz: 10 000 összehasonlítás a lineáris keresésnél, és összesen 14 összehasonlítás a bináris keresésnél. És ismét, ha az elemek száma 1000-szeresére nő (10-ről 10 000-re), akkor az összehasonlítások száma csak 3,5-szeresére nő (4-ről 14-re). A bináris keresési algoritmus bonyolultsága logaritmikus , vagy ha nagy O jelölést használunk, akkor O(log n). Miért hívják így? A logaritmus a hatványozás ellentéte. A bináris logaritmus az a hatvány, amelyre a 2-t fel kell emelni, hogy számot kapjunk. Például 10 000 elemet kell keresnünk a bináris keresési algoritmus segítségével. Jelenleg az értéktáblázatból megtudhatja, hogy ehhez legfeljebb 14 összehasonlításra lesz szükség. De mi van akkor, ha senki sem adott ilyen táblázatot, és ki kell számítania az összehasonlítások pontos maximális számát? Csak egy egyszerű kérdésre kell válaszolni: milyen hatványra kell emelni a 2-es számot, hogy az eredmény nagyobb vagy egyenlő legyen, mint az ellenőrizendő elemek száma? 10 000-ért ez a 14. hatvány. A 2 a 13. hatványhoz túl kicsi (8192), de a 2 a 14. hatványhoz = 16384, és ez a szám kielégíti a feltételünket (nagyobb vagy egyenlő, mint a tömb elemeinek száma). Megtaláltuk a logaritmust: 14. Ennyi összehasonlításra lehet szükségünk! :) Az algoritmusok és az algoritmusok bonyolultsága túl tág téma ahhoz, hogy egy leckébe beleférjen. De ennek ismerete nagyon fontos: sok állásinterjún algoritmusokat tartalmazó kérdések merülnek fel. Elméleti szempontból tudok ajánlani néhány könyvet. Kezdheti a " Grokking algoritmusokkal ". A könyvben található példák Python nyelven készültek, de a könyv nagyon egyszerű nyelvezetet és példákat használ. Kezdőknek a legjobb választás, ráadásul nem is túl nagy. A komolyabb olvasmányok között vannak Robert Lafore és Robert Sedgewick könyvei. Mindkettő Java nyelven íródott, ami egy kicsit megkönnyíti a tanulást. Hiszen jól ismeri ezt a nyelvet! :) A jó matematikai készséggel rendelkező tanulók számára a legjobb választás Thomas Cormen könyve . De az elmélet önmagában nem tölti meg a hasát! Tudás != Képesség . A HackerRank és a LeetCode algoritmusokkal kapcsolatos problémák megoldását gyakorolhatja . Az ezekről az oldalakról származó feladatokat gyakran használják még a Google és a Facebook interjúi során is, így biztosan nem fogtok unatkozni :) A tananyag megerősítéseként javaslom, hogy nézze meg ezt a kiváló videót a nagy O jelölésről a YouTube-on. Találkozunk a következő leckéken! :)
 Ez a téma minden programozó számára nagyon fontos. Az algoritmusokról fogunk beszélni . Mi az algoritmus? Egyszerűen fogalmazva, ez egy bizonyos műveletsor, amelyet végre kell hajtani a kívánt eredmény eléréséhez . A mindennapi életben gyakran használunk algoritmusokat. Például minden reggel van egy konkrét feladatod: menj iskolába vagy munkába, és ezzel egyidőben legyél:
Ez a téma minden programozó számára nagyon fontos. Az algoritmusokról fogunk beszélni . Mi az algoritmus? Egyszerűen fogalmazva, ez egy bizonyos műveletsor, amelyet végre kell hajtani a kívánt eredmény eléréséhez . A mindennapi életben gyakran használunk algoritmusokat. Például minden reggel van egy konkrét feladatod: menj iskolába vagy munkába, és ezzel egyidőben legyél:
 Ebben az esetben a leghatékonyabb algoritmus a fájl elküldése az interneten keresztül. Nem tarthatott tovább pár percnél! Ismételjük meg az algoritmusunkat: "Ha 5000 mérföldes távolságra szeretne információkat fájlok formájában továbbítani, az adatokat az interneten keresztül kell elküldenie". Kiváló. Most pedig elemezzük. Elvégzi a feladatunkat?Nos, igen, így van. De mit mondhatunk a bonyolultságáról? Hmm, most a dolgok egyre érdekesebbek. Az a tény, hogy az algoritmusunk nagyon függ a bemeneti adatoktól, nevezetesen a fájlok méretétől. Ha van 10 megabájtunk, akkor minden rendben van. De mi van akkor, ha 500 megabájtot kell küldenünk? 20 gigabájt? 500 terabájt? 30 petabájt? Leáll az algoritmusunk működése? Nem, mindezen mennyiségű adat valóban átvihető. Tovább fog tartani? Igen fog! Most ismerjük algoritmusunk egy fontos jellemzőjét: minél nagyobb az elküldendő adatmennyiség, annál tovább tart az algoritmus futtatása.. De szeretnénk pontosabban megérteni ezt a kapcsolatot (a bemeneti adat mérete és az elküldéshez szükséges idő között). Esetünkben az algoritmus bonyolultsága lineáris . A "lineáris" azt jelenti, hogy a bemeneti adatok mennyiségének növekedésével az elküldéshez szükséges idő hozzávetőlegesen arányosan növekszik. Ha az adatmennyiség megduplázódik, akkor az elküldéshez szükséges idő kétszer annyi lesz. Ha az adatok száma 10-szeresére nő, akkor az átviteli idő 10-szeresére nő. A nagy O jelölést használva algoritmusunk összetettségét O(n) -ként fejezzük ki. Emlékezzen erre a jelölésre a jövőre nézve – mindig a lineáris összetettségű algoritmusoknál használják. Ne feledje, hogy itt nem több olyan dologról beszélünk, amelyek eltérőek lehetnek: az internet sebességéről, a számítógépünk számítási teljesítményéről és így tovább. Egy algoritmus összetettségének értékelése során egyszerűen nincs értelme figyelembe venni ezeket a tényezőket – mindenesetre kívül esnek rajtunk. A Big O jelölés magának az algoritmusnak a bonyolultságát fejezi ki, nem azt a „környezetet”, amelyben fut. Folytassuk példánkkal. Tegyük fel, hogy végül megtudjuk, hogy összesen 800 terabájtnyi fájlt kell küldenünk. Feladatunkat természetesen úgy is teljesíthetjük, ha elküldjük őket az interneten keresztül. Csak egy probléma van: normál háztartási adatátviteli sebesség mellett (100 megabit/másodperc) ez körülbelül 708 napot vesz igénybe. Majdnem 2 éve! :O Az algoritmusunk nyilvánvalóan nem illik ide. Más megoldásra van szükségünk! Váratlanul az IT óriás Amazon jön a segítségünkre! Az Amazon Snowmobile szolgáltatása lehetővé teszi, hogy nagy mennyiségű adatot töltsünk fel mobil tárhelyre, majd teherautóval szállítsuk ki a kívánt címre!
Ebben az esetben a leghatékonyabb algoritmus a fájl elküldése az interneten keresztül. Nem tarthatott tovább pár percnél! Ismételjük meg az algoritmusunkat: "Ha 5000 mérföldes távolságra szeretne információkat fájlok formájában továbbítani, az adatokat az interneten keresztül kell elküldenie". Kiváló. Most pedig elemezzük. Elvégzi a feladatunkat?Nos, igen, így van. De mit mondhatunk a bonyolultságáról? Hmm, most a dolgok egyre érdekesebbek. Az a tény, hogy az algoritmusunk nagyon függ a bemeneti adatoktól, nevezetesen a fájlok méretétől. Ha van 10 megabájtunk, akkor minden rendben van. De mi van akkor, ha 500 megabájtot kell küldenünk? 20 gigabájt? 500 terabájt? 30 petabájt? Leáll az algoritmusunk működése? Nem, mindezen mennyiségű adat valóban átvihető. Tovább fog tartani? Igen fog! Most ismerjük algoritmusunk egy fontos jellemzőjét: minél nagyobb az elküldendő adatmennyiség, annál tovább tart az algoritmus futtatása.. De szeretnénk pontosabban megérteni ezt a kapcsolatot (a bemeneti adat mérete és az elküldéshez szükséges idő között). Esetünkben az algoritmus bonyolultsága lineáris . A "lineáris" azt jelenti, hogy a bemeneti adatok mennyiségének növekedésével az elküldéshez szükséges idő hozzávetőlegesen arányosan növekszik. Ha az adatmennyiség megduplázódik, akkor az elküldéshez szükséges idő kétszer annyi lesz. Ha az adatok száma 10-szeresére nő, akkor az átviteli idő 10-szeresére nő. A nagy O jelölést használva algoritmusunk összetettségét O(n) -ként fejezzük ki. Emlékezzen erre a jelölésre a jövőre nézve – mindig a lineáris összetettségű algoritmusoknál használják. Ne feledje, hogy itt nem több olyan dologról beszélünk, amelyek eltérőek lehetnek: az internet sebességéről, a számítógépünk számítási teljesítményéről és így tovább. Egy algoritmus összetettségének értékelése során egyszerűen nincs értelme figyelembe venni ezeket a tényezőket – mindenesetre kívül esnek rajtunk. A Big O jelölés magának az algoritmusnak a bonyolultságát fejezi ki, nem azt a „környezetet”, amelyben fut. Folytassuk példánkkal. Tegyük fel, hogy végül megtudjuk, hogy összesen 800 terabájtnyi fájlt kell küldenünk. Feladatunkat természetesen úgy is teljesíthetjük, ha elküldjük őket az interneten keresztül. Csak egy probléma van: normál háztartási adatátviteli sebesség mellett (100 megabit/másodperc) ez körülbelül 708 napot vesz igénybe. Majdnem 2 éve! :O Az algoritmusunk nyilvánvalóan nem illik ide. Más megoldásra van szükségünk! Váratlanul az IT óriás Amazon jön a segítségünkre! Az Amazon Snowmobile szolgáltatása lehetővé teszi, hogy nagy mennyiségű adatot töltsünk fel mobil tárhelyre, majd teherautóval szállítsuk ki a kívánt címre!  Tehát van egy új algoritmusunk! "Ha 5000 mérföldes távolságra szeretne információkat fájlok formájában továbbítani, és ennek az interneten keresztül történő elküldése több mint 14 napot vesz igénybe, akkor az adatokat egy Amazon teherautón kell elküldenie." Itt önkényesen 14 napot választottunk. Tegyük fel, hogy ez a leghosszabb időszak, amit várhatunk. Elemezzük az algoritmusunkat. Mi a helyzet a sebességével? Még ha a teherautó csak 50 mérföld/órás sebességgel halad is, mindössze 100 óra alatt 5000 mérföldet tesz meg. Ez kicsit több, mint négy nap! Ez sokkal jobb, mint az adatok interneten keresztüli küldése. És mi a helyzet ennek az algoritmusnak a bonyolultságával? Lineáris is, azaz O(n)? Nem, ez nem. Végtére is, a teherautónak nem mindegy, milyen erősen rakod fel – továbbra is nagyjából ugyanolyan sebességgel fog haladni, és időben megérkezik. Akár 800 terabájtunk van, akár ennek 10-szerese, a kamion 5 napon belül mégis célba ér. Más szóval, a teherautó-alapú adatátviteli algoritmus állandó bonyolultságú. Itt az "állandó" azt jelenti, hogy nem függ a bemeneti adat méretétől. Tegyél a kamionba egy 1GB-os pendrive-ot, 5 napon belül megérkezik. Tedd be a 800 terabájtnyi adatot tartalmazó lemezeket, 5 napon belül megérkezik. Ha nagy O jelölést használunk, az állandó komplexitást O(1) jelöli . Megismerkedtünk az O(n) és az O(1) -vel, így most nézzünk még több példát a programozás világából :) Tegyük fel, hogy kapsz egy 100 számból álló tömböt, és a feladat az, hogy mindegyiket megjelenítsd a konzolt. Írsz egy közönséges
Tehát van egy új algoritmusunk! "Ha 5000 mérföldes távolságra szeretne információkat fájlok formájában továbbítani, és ennek az interneten keresztül történő elküldése több mint 14 napot vesz igénybe, akkor az adatokat egy Amazon teherautón kell elküldenie." Itt önkényesen 14 napot választottunk. Tegyük fel, hogy ez a leghosszabb időszak, amit várhatunk. Elemezzük az algoritmusunkat. Mi a helyzet a sebességével? Még ha a teherautó csak 50 mérföld/órás sebességgel halad is, mindössze 100 óra alatt 5000 mérföldet tesz meg. Ez kicsit több, mint négy nap! Ez sokkal jobb, mint az adatok interneten keresztüli küldése. És mi a helyzet ennek az algoritmusnak a bonyolultságával? Lineáris is, azaz O(n)? Nem, ez nem. Végtére is, a teherautónak nem mindegy, milyen erősen rakod fel – továbbra is nagyjából ugyanolyan sebességgel fog haladni, és időben megérkezik. Akár 800 terabájtunk van, akár ennek 10-szerese, a kamion 5 napon belül mégis célba ér. Más szóval, a teherautó-alapú adatátviteli algoritmus állandó bonyolultságú. Itt az "állandó" azt jelenti, hogy nem függ a bemeneti adat méretétől. Tegyél a kamionba egy 1GB-os pendrive-ot, 5 napon belül megérkezik. Tedd be a 800 terabájtnyi adatot tartalmazó lemezeket, 5 napon belül megérkezik. Ha nagy O jelölést használunk, az állandó komplexitást O(1) jelöli . Megismerkedtünk az O(n) és az O(1) -vel, így most nézzünk még több példát a programozás világából :) Tegyük fel, hogy kapsz egy 100 számból álló tömböt, és a feladat az, hogy mindegyiket megjelenítsd a konzolt. Írsz egy közönséges 
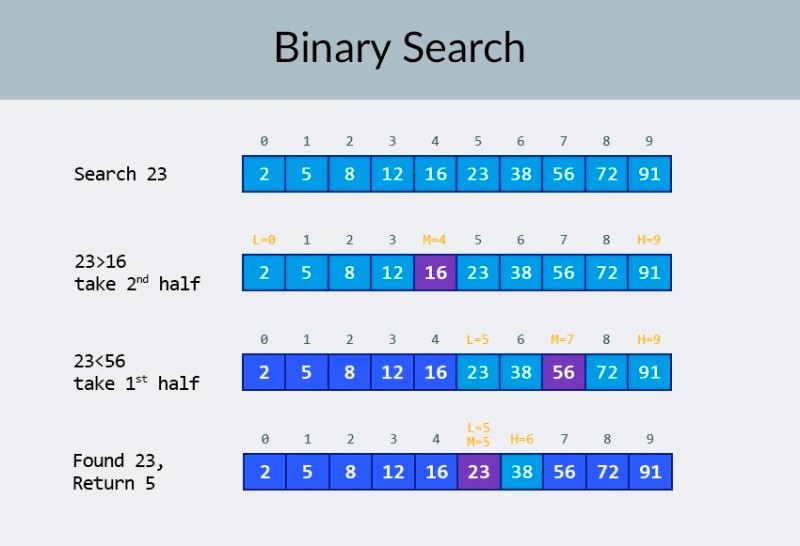 A kép felső sorában egy rendezett tömböt látunk. Meg kell találnunk benne a 23-as számot. A számok iterációja helyett egyszerűen 2 részre osztjuk a tömböt, és ellenőrizzük a tömb középső számát. Keresse meg a 4-es cellában található számot, és jelölje be (a képen a második sor). Ez a szám 16, mi pedig 23-at keresünk. A jelenlegi szám kevesebb, mint amit keresünk. Az mit jelent? Ez azt jelentiaz összes korábbi számot (a 16-os előtti számot) nem kell ellenőrizni : garantáltan kevesebb lesz, mint amit keresünk, mert a tömbünk rendezett! Folytatjuk a keresést a maradék 5 elem között. Jegyzet:csak egy összehasonlítást végeztünk, de a lehetséges lehetőségek felét már kiiktattuk. Már csak 5 elemünk maradt. Megismételjük az előző lépést úgy, hogy még egyszer kettéosztjuk a fennmaradó altömböt, és ismét vesszük a középső elemet (a képen a 3. sor). A szám 56, és nagyobb, mint a keresett. Az mit jelent? Ez azt jelenti, hogy további 3 lehetőséget kiszűrtünk: magát az 56-os számot, valamint az utána lévő két számot (hiszen ezek garantáltan nagyobbak, mint 23, mert a tömb rendezett). Már csak 2 számot kell ellenőriznünk (a képen az utolsó sor) – az 5-ös és 6-os tömbindexű számokat. Ellenőrizzük az elsőt, és megtaláljuk, amit kerestünk – a 23-as számot! Az indexe 5! Nézzük meg az algoritmusunk eredményeit, majd elemezni fogom a bonyolultságát. Egyébként most már megérted, miért hívják ezt bináris keresésnek: az adatok többszöri felezésén alapul. Az eredmény lenyűgöző! Ha lineáris kereséssel keresnénk a számot, akkor akár 10 összehasonlításra lenne szükségünk, de bináris kereséssel csak 3-mal teljesítettük a feladatot! A legrosszabb esetben 4 összehasonlítás lenne (ha az utolsó lépésben a kívánt szám a fennmaradó lehetőségek közül a második lenne, nem pedig az első. Na és mi van a bonyolultságával? Ez egy nagyon érdekes pont :) A bináris keresési algoritmus sokkal kevésbé függ a tömb elemeinek számától, mint a lineáris keresési algoritmus (vagyis az egyszerű iteráció). Ha a tömbben 10 elem van , a lineáris kereséshez legfeljebb 10, a bináris kereséshez viszont legfeljebb 4 összehasonlításra lesz szükség. Ez 2,5-szeres különbség. De egy 1000 elemből álló tömb esetén a lineáris kereséshez legfeljebb 1000 összehasonlításra van szükség, a bináris kereséshez viszont csak 10- re ! A különbség most 100-szoros! Jegyzet:a tömb elemeinek száma 100-szorosára nőtt (10-ről 1000-re), de a bináris kereséshez szükséges összehasonlítások száma mindössze 2,5-szeresére nőtt (4-ről 10-re). Ha elérjük a 10 000 elemet , a különbség még lenyűgözőbb lesz: 10 000 összehasonlítás a lineáris keresésnél, és összesen 14 összehasonlítás a bináris keresésnél. És ismét, ha az elemek száma 1000-szeresére nő (10-ről 10 000-re), akkor az összehasonlítások száma csak 3,5-szeresére nő (4-ről 14-re). A bináris keresési algoritmus bonyolultsága logaritmikus , vagy ha nagy O jelölést használunk, akkor O(log n). Miért hívják így? A logaritmus a hatványozás ellentéte. A bináris logaritmus az a hatvány, amelyre a 2-t fel kell emelni, hogy számot kapjunk. Például 10 000 elemet kell keresnünk a bináris keresési algoritmus segítségével.
A kép felső sorában egy rendezett tömböt látunk. Meg kell találnunk benne a 23-as számot. A számok iterációja helyett egyszerűen 2 részre osztjuk a tömböt, és ellenőrizzük a tömb középső számát. Keresse meg a 4-es cellában található számot, és jelölje be (a képen a második sor). Ez a szám 16, mi pedig 23-at keresünk. A jelenlegi szám kevesebb, mint amit keresünk. Az mit jelent? Ez azt jelentiaz összes korábbi számot (a 16-os előtti számot) nem kell ellenőrizni : garantáltan kevesebb lesz, mint amit keresünk, mert a tömbünk rendezett! Folytatjuk a keresést a maradék 5 elem között. Jegyzet:csak egy összehasonlítást végeztünk, de a lehetséges lehetőségek felét már kiiktattuk. Már csak 5 elemünk maradt. Megismételjük az előző lépést úgy, hogy még egyszer kettéosztjuk a fennmaradó altömböt, és ismét vesszük a középső elemet (a képen a 3. sor). A szám 56, és nagyobb, mint a keresett. Az mit jelent? Ez azt jelenti, hogy további 3 lehetőséget kiszűrtünk: magát az 56-os számot, valamint az utána lévő két számot (hiszen ezek garantáltan nagyobbak, mint 23, mert a tömb rendezett). Már csak 2 számot kell ellenőriznünk (a képen az utolsó sor) – az 5-ös és 6-os tömbindexű számokat. Ellenőrizzük az elsőt, és megtaláljuk, amit kerestünk – a 23-as számot! Az indexe 5! Nézzük meg az algoritmusunk eredményeit, majd elemezni fogom a bonyolultságát. Egyébként most már megérted, miért hívják ezt bináris keresésnek: az adatok többszöri felezésén alapul. Az eredmény lenyűgöző! Ha lineáris kereséssel keresnénk a számot, akkor akár 10 összehasonlításra lenne szükségünk, de bináris kereséssel csak 3-mal teljesítettük a feladatot! A legrosszabb esetben 4 összehasonlítás lenne (ha az utolsó lépésben a kívánt szám a fennmaradó lehetőségek közül a második lenne, nem pedig az első. Na és mi van a bonyolultságával? Ez egy nagyon érdekes pont :) A bináris keresési algoritmus sokkal kevésbé függ a tömb elemeinek számától, mint a lineáris keresési algoritmus (vagyis az egyszerű iteráció). Ha a tömbben 10 elem van , a lineáris kereséshez legfeljebb 10, a bináris kereséshez viszont legfeljebb 4 összehasonlításra lesz szükség. Ez 2,5-szeres különbség. De egy 1000 elemből álló tömb esetén a lineáris kereséshez legfeljebb 1000 összehasonlításra van szükség, a bináris kereséshez viszont csak 10- re ! A különbség most 100-szoros! Jegyzet:a tömb elemeinek száma 100-szorosára nőtt (10-ről 1000-re), de a bináris kereséshez szükséges összehasonlítások száma mindössze 2,5-szeresére nőtt (4-ről 10-re). Ha elérjük a 10 000 elemet , a különbség még lenyűgözőbb lesz: 10 000 összehasonlítás a lineáris keresésnél, és összesen 14 összehasonlítás a bináris keresésnél. És ismét, ha az elemek száma 1000-szeresére nő (10-ről 10 000-re), akkor az összehasonlítások száma csak 3,5-szeresére nő (4-ről 14-re). A bináris keresési algoritmus bonyolultsága logaritmikus , vagy ha nagy O jelölést használunk, akkor O(log n). Miért hívják így? A logaritmus a hatványozás ellentéte. A bináris logaritmus az a hatvány, amelyre a 2-t fel kell emelni, hogy számot kapjunk. Például 10 000 elemet kell keresnünk a bináris keresési algoritmus segítségével. 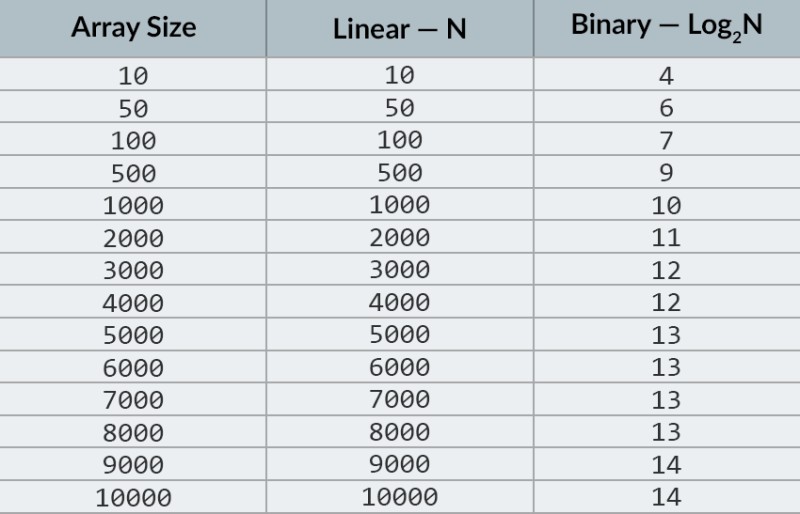 Jelenleg az értéktáblázatból megtudhatja, hogy ehhez legfeljebb 14 összehasonlításra lesz szükség. De mi van akkor, ha senki sem adott ilyen táblázatot, és ki kell számítania az összehasonlítások pontos maximális számát? Csak egy egyszerű kérdésre kell válaszolni: milyen hatványra kell emelni a 2-es számot, hogy az eredmény nagyobb vagy egyenlő legyen, mint az ellenőrizendő elemek száma? 10 000-ért ez a 14. hatvány. A 2 a 13. hatványhoz túl kicsi (8192), de a 2 a 14. hatványhoz = 16384, és ez a szám kielégíti a feltételünket (nagyobb vagy egyenlő, mint a tömb elemeinek száma). Megtaláltuk a logaritmust: 14. Ennyi összehasonlításra lehet szükségünk! :) Az algoritmusok és az algoritmusok bonyolultsága túl tág téma ahhoz, hogy egy leckébe beleférjen. De ennek ismerete nagyon fontos: sok állásinterjún algoritmusokat tartalmazó kérdések merülnek fel. Elméleti szempontból tudok ajánlani néhány könyvet. Kezdheti a " Grokking algoritmusokkal ". A könyvben található példák Python nyelven készültek, de a könyv nagyon egyszerű nyelvezetet és példákat használ. Kezdőknek a legjobb választás, ráadásul nem is túl nagy. A komolyabb olvasmányok között vannak Robert Lafore és Robert Sedgewick könyvei. Mindkettő Java nyelven íródott, ami egy kicsit megkönnyíti a tanulást. Hiszen jól ismeri ezt a nyelvet! :) A jó matematikai készséggel rendelkező tanulók számára a legjobb választás Thomas Cormen könyve . De az elmélet önmagában nem tölti meg a hasát! Tudás != Képesség . A HackerRank és a LeetCode algoritmusokkal kapcsolatos problémák megoldását gyakorolhatja . Az ezekről az oldalakról származó feladatokat gyakran használják még a Google és a Facebook interjúi során is, így biztosan nem fogtok unatkozni :) A tananyag megerősítéseként javaslom, hogy nézze meg ezt a kiváló videót a nagy O jelölésről a YouTube-on. Találkozunk a következő leckéken! :)
Jelenleg az értéktáblázatból megtudhatja, hogy ehhez legfeljebb 14 összehasonlításra lesz szükség. De mi van akkor, ha senki sem adott ilyen táblázatot, és ki kell számítania az összehasonlítások pontos maximális számát? Csak egy egyszerű kérdésre kell válaszolni: milyen hatványra kell emelni a 2-es számot, hogy az eredmény nagyobb vagy egyenlő legyen, mint az ellenőrizendő elemek száma? 10 000-ért ez a 14. hatvány. A 2 a 13. hatványhoz túl kicsi (8192), de a 2 a 14. hatványhoz = 16384, és ez a szám kielégíti a feltételünket (nagyobb vagy egyenlő, mint a tömb elemeinek száma). Megtaláltuk a logaritmust: 14. Ennyi összehasonlításra lehet szükségünk! :) Az algoritmusok és az algoritmusok bonyolultsága túl tág téma ahhoz, hogy egy leckébe beleférjen. De ennek ismerete nagyon fontos: sok állásinterjún algoritmusokat tartalmazó kérdések merülnek fel. Elméleti szempontból tudok ajánlani néhány könyvet. Kezdheti a " Grokking algoritmusokkal ". A könyvben található példák Python nyelven készültek, de a könyv nagyon egyszerű nyelvezetet és példákat használ. Kezdőknek a legjobb választás, ráadásul nem is túl nagy. A komolyabb olvasmányok között vannak Robert Lafore és Robert Sedgewick könyvei. Mindkettő Java nyelven íródott, ami egy kicsit megkönnyíti a tanulást. Hiszen jól ismeri ezt a nyelvet! :) A jó matematikai készséggel rendelkező tanulók számára a legjobb választás Thomas Cormen könyve . De az elmélet önmagában nem tölti meg a hasát! Tudás != Képesség . A HackerRank és a LeetCode algoritmusokkal kapcsolatos problémák megoldását gyakorolhatja . Az ezekről az oldalakról származó feladatokat gyakran használják még a Google és a Facebook interjúi során is, így biztosan nem fogtok unatkozni :) A tananyag megerősítéseként javaslom, hogy nézze meg ezt a kiváló videót a nagy O jelölésről a YouTube-on. Találkozunk a következő leckéken! :)
