Hei! Dagens leksjon vil være litt annerledes enn resten. Det vil avvike ved at det bare er indirekte relatert til Java. Når det er sagt, er dette emnet veldig viktig for enhver programmerer. Vi skal snakke om algoritmer . Hva er en algoritme? Enkelt sagt er det en rekke handlinger som må fullføres for å oppnå et ønsket resultat . Vi bruker ofte algoritmer i hverdagen. For eksempel, hver morgen har du en spesifikk oppgave: gå på skole eller jobb, og samtidig være:
Påkledd
Ren
Fed
Hvilken algoritme lar deg oppnå dette resultatet?
Våkn opp ved hjelp av en vekkerklokke.
Ta en dusj og vask deg.
Lag frokost og litt kaffe eller te.
Spise.
Hvis du ikke strøk klærne forrige kveld, så stryk dem.
Kle på seg.
Forlat huset.
Denne sekvensen av handlinger vil definitivt la deg få det ønskede resultatet. Innen programmering jobber vi hele tiden med å fullføre oppgaver. En betydelig del av disse oppgavene kan utføres ved hjelp av algoritmer som allerede er kjent. Anta for eksempel at oppgaven din er å sortere en liste med 100 navn i en matrise . Denne oppgaven er ganske enkel, men den kan løses på forskjellige måter. Her er en mulig løsning: Algoritme for å sortere navn alfabetisk:
Kjøp eller last ned 1961-utgaven av Webster's Third New International Dictionary.
Finn hvert navn fra listen vår i denne ordboken.
På et stykke papir skriver du siden i ordboken som navnet står på.
Bruk papirlappene til å sortere navnene.
Vil en slik sekvens av handlinger oppfylle vår oppgave? Ja, det vil det sikkert. Er denne løsningen effektiv ? Neppe. Her kommer vi til andre svært viktige aspekter ved algoritmer: deres effektivitet . Det er flere måter å utføre denne oppgaven på. Men både i programmering og i det vanlige livet ønsker vi å velge den mest effektive måten. Hvis oppgaven din er å lage et stykke toast med smør, kan du begynne med å så hvete og melke en ku. Men det ville vært ineffektivtløsning — det vil ta mye tid og koste mye penger. Du kan utføre din enkle oppgave ved å kjøpe brød og smør. Selv om den lar deg løse problemet, er algoritmen som involverer hvete og en ku for kompleks til å bruke i praksis. I programmering har vi spesiell notasjon kalt big O-notasjon for å vurdere kompleksiteten til algoritmer. Big O gjør det mulig å vurdere hvor mye en algoritmes utførelsestid avhenger av inndatastørrelsen . La oss se på det enkleste eksemplet: dataoverføring. Tenk deg at du må sende litt informasjon i form av en fil over en lang avstand (for eksempel 5000 miles). Hvilken algoritme vil være mest effektiv? Det avhenger av dataene du jobber med. Anta for eksempel at vi har en lydfil på 10 MB. I dette tilfellet er den mest effektive algoritmen å sende filen over Internett. Det kunne ikke ta mer enn et par minutter! La oss gjenta algoritmen vår: "Hvis du ønsker å overføre informasjon i form av filer over en avstand på 5000 miles, bør du sende dataene via Internett". Utmerket. La oss nå analysere det. Klarer det vår oppgave?Vel, ja, det gjør det. Men hva kan vi si om kompleksiteten? Hmm, nå blir ting mer interessant. Faktum er at algoritmen vår er veldig avhengig av inndataene, nemlig størrelsen på filene. Hvis vi har 10 megabyte, så er alt bra. Men hva om vi trenger å sende 500 megabyte? 20 gigabyte? 500 terabyte? 30 petabyte? Vil algoritmen vår slutte å virke? Nei, alle disse datamengdene kan faktisk overføres. Vil det ta lengre tid? Ja det vil det! Nå kjenner vi en viktig funksjon ved algoritmen vår: jo større datamengde som skal sendes, jo lengre tid vil det ta å kjøre algoritmen. Men vi vil gjerne ha en mer presis forståelse av dette forholdet (mellom størrelsen på inndatadata og tiden som kreves for å sende den). I vårt tilfelle er den algoritmiske kompleksiteten lineær . "Lineær" betyr at når mengden inndata øker, vil tiden det tar å sende den øke omtrent proporsjonalt. Hvis datamengden dobles, vil tiden som kreves for å sende den være dobbelt så mye. Hvis dataene øker med 10 ganger, vil overføringstiden øke 10 ganger. Ved å bruke stor O-notasjon uttrykkes kompleksiteten til algoritmen vår som O(n). Du bør huske denne notasjonen for fremtiden - den brukes alltid for algoritmer med lineær kompleksitet. Merk at vi ikke snakker om flere ting som kan variere her: Internett-hastighet, datamaskinens beregningskraft og så videre. Når man vurderer kompleksiteten til en algoritme, er det rett og slett ikke fornuftig å vurdere disse faktorene - i alle fall er de utenfor vår kontroll. Big O-notasjonen uttrykker kompleksiteten til selve algoritmen, ikke "miljøet" den kjører i. La oss fortsette med vårt eksempel. Anta at vi til slutt lærer at vi må sende filer på totalt 800 terabyte. Vi kan selvfølgelig utføre oppgaven vår ved å sende dem over Internett. Det er bare ett problem: ved standard husholdningsdataoverføringshastigheter (100 megabit per sekund), vil det ta omtrent 708 dager. Snart 2 år! :O Algoritmen vår passer tydeligvis ikke her. Vi trenger en annen løsning! Uventet kommer IT-giganten Amazon til unnsetning! Amazons snøscootertjeneste lar oss laste opp en stor mengde data til mobillagring og deretter levere den til ønsket adresse med lastebil! Så vi har en ny algoritme! "Hvis du ønsker å overføre informasjon i form av filer over en avstand på 5000 miles og å gjøre det vil ta mer enn 14 dager å sende via Internett, bør du sende dataene på en Amazon-lastebil." Vi valgte 14 dager vilkårlig her. La oss si at dette er den lengste perioden vi kan vente. La oss analysere algoritmen vår. Hva med hastigheten? Selv om lastebilen kjører i bare 50 mph, vil den tilbakelegge 5000 miles på bare 100 timer. Dette er litt over fire dager! Dette er mye bedre enn muligheten til å sende dataene over Internett. Og hva med kompleksiteten til denne algoritmen? Er den også lineær, altså O(n)? Nei det er ikke. Tross alt bryr ikke lastebilen seg hvor tungt du laster den – den vil fortsatt kjøre i omtrent samme hastighet og komme frem i tide. Enten vi har 800 terabyte, eller 10 ganger det, vil lastebilen fortsatt nå målet innen 5 dager. Med andre ord har den lastebilbaserte dataoverføringsalgoritmen konstant kompleksitet. Her betyr "konstant" at den ikke er avhengig av størrelsen på inngangsdataene. Sett en 1 GB flash-stasjon i lastebilen, den kommer innen 5 dager. Sett inn disker som inneholder 800 terabyte med data, den kommer innen 5 dager. Når du bruker stor O-notasjon, er konstant kompleksitet betegnet med O(1) . Vi har blitt kjent med O(n) og O(1) , så la oss nå se på flere eksempler i programmeringsverdenen :) Anta at du får en matrise med 100 tall, og oppgaven er å vise hvert av dem på konsollen. Du skriver en vanlig forloop som utfører denne oppgaven
int[] numbers =newint[100];// ...fill the array with numbersfor(int i: numbers){System.out.println(i);}
Hva er kompleksiteten til denne algoritmen? Lineær, dvs. O(n). Antall handlinger som programmet må utføre avhenger av hvor mange tall som sendes til det. Hvis det er 100 tall i matrisen, vil det være 100 handlinger (utsagn for å vise strenger på skjermen). Hvis det er 10 000 tall i matrisen, må 10 000 handlinger utføres. Kan algoritmen vår forbedres på noen måte? Nei. Uansett hva, må vi få N til å gå gjennom matrisen og utføre N setninger for å vise strenger på konsollen. Tenk på et annet eksempel.
Vi har en tom LinkedListsom vi setter inn flere tall i. Vi må evaluere den algoritmiske kompleksiteten ved å sette inn et enkelt tall i LinkedListeksemplet vårt, og hvordan det avhenger av antall elementer i listen. Svaret er O(1), altså konstant kompleksitet . Hvorfor? Merk at vi setter inn hvert tall i begynnelsen av listen. I tillegg vil du huske at når du setter inn et tall i en LinkedList, flytter ikke elementene seg noe sted. Linkene (eller referansene) er oppdatert (hvis du har glemt hvordan LinkedList fungerer, se på en av våre gamle leksjoner ). Hvis det første tallet i listen vår er x, og vi setter inn tallet y foran på listen, er alt vi trenger å gjøre dette:
x.previous = y;
y.previous =null;
y.next = x;
Når vi oppdaterer lenkene, bryr vi oss ikke om hvor mange tall som allerede er iLinkedList , om én eller én milliard. Kompleksiteten til algoritmen er konstant, dvs. O(1).
Logaritmisk kompleksitet
Ikke få panikk! :) Hvis ordet "logaritmisk" gir deg lyst til å avslutte denne leksjonen og slutte å lese, er det bare å holde på i et par minutter. Det vil ikke være noen sprø matematikk her (det er mange slike forklaringer andre steder), og vi vil plukke fra hverandre hvert eksempel. Tenk deg at oppgaven din er å finne ett spesifikt tall i en rekke med 100 tall. Mer presist må du sjekke om den er der eller ikke. Så snart det nødvendige nummeret er funnet, avsluttes søket, og du viser følgende i konsollen: "Det nødvendige nummeret ble funnet! Dets indeks i matrisen = ...." Hvordan ville du oppnå denne oppgaven? Her er løsningen åpenbar: du må iterere over elementene i matrisen én etter én, med start fra det første (eller fra det siste) og sjekke om det nåværende nummeret stemmer med det du leter etter. Tilsvarende, antall handlinger avhenger direkte av antall elementer i matrisen. Hvis vi har 100 tall, kan vi potensielt trenge å gå til neste element 100 ganger og utføre 100 sammenligninger. Hvis det er 1000 tall, kan det være 1000 sammenligninger. Dette er åpenbart lineær kompleksitet, dvsO(n) . Og nå skal vi legge til en avgrensning til eksemplet vårt: matrisen der du trenger å finne tallet er sortert i stigende rekkefølge . Forandrer dette noe i forhold til vår oppgave? Vi kunne fortsatt utføre et brute-force-søk etter ønsket nummer. Men alternativt kan vi bruke den velkjente binære søkealgoritmen . I den øverste raden i bildet ser vi en sortert matrise. Vi må finne tallet 23 i den. I stedet for å iterere over tallene deler vi bare arrayet i 2 deler og sjekker det midterste tallet i arrayet. Finn tallet som er plassert i celle 4 og sjekk det (andre rad i bildet). Dette tallet er 16, og vi ser etter 23. Det nåværende antallet er mindre enn det vi ser etter. Hva betyr det? Det betyr atalle de tidligere tallene (de som ligger før tallet 16) trenger ikke å sjekkes : de er garantert mindre enn det vi ser etter, fordi matrisen vår er sortert! Vi fortsetter søket blant de resterende 5 elementene. Merk:vi har kun utført én sammenligning, men vi har allerede eliminert halvparten av de mulige alternativene. Vi har bare 5 elementer igjen. Vi vil gjenta vårt forrige trinn ved igjen å dele den gjenværende undergruppen i to og igjen ta det midterste elementet (den tredje raden i bildet). Tallet er 56, og det er større enn det vi ser etter. Hva betyr det? Det betyr at vi har eliminert ytterligere 3 muligheter: selve tallet 56 så vel som de to tallene etter det (siden de er garantert større enn 23, fordi matrisen er sortert). Vi har bare 2 tall igjen å sjekke (den siste raden i bildet) — tallene med matriseindeksene 5 og 6. Vi sjekker det første av dem, og finner det vi lette etter — tallet 23! Indeksen er 5! La oss se på resultatene av algoritmen vår, og så vil analysere kompleksiteten. Forresten, nå forstår du hvorfor dette kalles binært søk: det er avhengig av gjentatte ganger å dele dataene i to. Resultatet er imponerende! Hvis vi brukte et lineært søk for å se etter tallet, ville vi trenge opptil 10 sammenligninger, men med et binært søk klarte vi oppgaven med bare 3! I verste fall ville det vært 4 sammenligninger (hvis tallet vi ønsket i det siste trinnet var det andre av de gjenværende mulighetene, i stedet for det første. Så hva med kompleksiteten? Dette er et veldig interessant poeng :) Den binære søkealgoritmen er mye mindre avhengig av antall elementer i matrisen enn den lineære søkealgoritmen (det vil si enkel iterasjon). Med 10 elementer i matrisen vil et lineært søk trenge maksimalt 10 sammenligninger, men et binært søk vil trenge maksimalt 4 sammenligninger. Det er en forskjell på en faktor på 2,5. Men for en matrise på 1000 elementer vil et lineært søk trenge opptil 1000 sammenligninger, men et binært søk krever bare 10 ! Forskjellen er nå 100 ganger! Merk:antall elementer i matrisen har økt 100 ganger (fra 10 til 1000), men antallet sammenligninger som kreves for et binært søk har økt med en faktor på bare 2,5 (fra 4 til 10). Hvis vi kommer til 10 000 elementer , vil forskjellen være enda mer imponerende: 10 000 sammenligninger for lineært søk, og totalt 14 sammenligninger for binært søk. Og igjen, hvis antall elementer øker med 1000 ganger (fra 10 til 10000), øker antallet sammenligninger med en faktor på bare 3,5 (fra 4 til 14). Kompleksiteten til den binære søkealgoritmen er logaritmisk , eller, hvis vi bruker stor O-notasjon, O(log n). Hvorfor heter det det? Logaritmen er som det motsatte av eksponentiering. Den binære logaritmen er potensen som tallet 2 må heves til for å få et tall. For eksempel har vi 10 000 elementer som vi trenger for å søke ved hjelp av den binære søkealgoritmen. For øyeblikket kan du se på verditabellen for å vite at å gjøre dette vil kreve maksimalt 14 sammenligninger. Men hva om ingen har gitt en slik tabell og du må beregne det nøyaktige maksimale antallet sammenligninger? Du trenger bare å svare på et enkelt spørsmål: til hvilken kraft trenger du å heve tallet 2 slik at resultatet er større enn eller lik antall elementer som skal kontrolleres? For 10 000 er det 14. potens. 2 til 13. potens er for liten (8192), men 2 til 14. potens = 16384, og dette tallet tilfredsstiller vår betingelse (det er større enn eller lik antall elementer i matrisen). Vi fant logaritmen: 14. Så mange sammenligninger kan vi trenge! :) Algoritmer og algoritmisk kompleksitet er et for bredt emne til å passe inn i én leksjon. Men å vite det er veldig viktig: mange jobbintervjuer vil involvere spørsmål som involverer algoritmer. For teorien kan jeg anbefale noen bøker for deg. Du kan starte med " Grokking Algorithms ". Eksemplene i denne boken er skrevet i Python, men boken bruker veldig enkelt språk og eksempler. Det er det beste alternativet for en nybegynner, og dessuten er det ikke veldig stort. Blant mer seriøs lesning har vi bøker av Robert Lafore og Robert Sedgewick. Begge er skrevet i Java, noe som vil gjøre læringen litt enklere for deg. Tross alt er du ganske kjent med dette språket! :) For elever med gode matematiske ferdigheter er det beste alternativet Thomas Cormens bok . Men teori alene vil ikke fylle magen din! Kunnskap != Evne . Du kan øve på å løse problemer som involverer algoritmer på HackerRank og LeetCode . Oppgaver fra disse nettsidene blir ofte brukt selv under intervjuer hos Google og Facebook, så du kommer definitivt ikke til å kjede deg :) For å forsterke dette leksjonsmaterialet anbefaler jeg at du ser denne utmerkede videoen om stor O-notasjon på YouTube. Vi sees i neste leksjoner! :)
0
Kommentarer
Populær
Ny
Gammel
Du må være pålogget for å legge igjen en kommentar
 Når det er sagt, er dette emnet veldig viktig for enhver programmerer. Vi skal snakke om algoritmer . Hva er en algoritme? Enkelt sagt er det en rekke handlinger som må fullføres for å oppnå et ønsket resultat . Vi bruker ofte algoritmer i hverdagen. For eksempel, hver morgen har du en spesifikk oppgave: gå på skole eller jobb, og samtidig være:
Når det er sagt, er dette emnet veldig viktig for enhver programmerer. Vi skal snakke om algoritmer . Hva er en algoritme? Enkelt sagt er det en rekke handlinger som må fullføres for å oppnå et ønsket resultat . Vi bruker ofte algoritmer i hverdagen. For eksempel, hver morgen har du en spesifikk oppgave: gå på skole eller jobb, og samtidig være:
 I dette tilfellet er den mest effektive algoritmen å sende filen over Internett. Det kunne ikke ta mer enn et par minutter! La oss gjenta algoritmen vår: "Hvis du ønsker å overføre informasjon i form av filer over en avstand på 5000 miles, bør du sende dataene via Internett". Utmerket. La oss nå analysere det. Klarer det vår oppgave?Vel, ja, det gjør det. Men hva kan vi si om kompleksiteten? Hmm, nå blir ting mer interessant. Faktum er at algoritmen vår er veldig avhengig av inndataene, nemlig størrelsen på filene. Hvis vi har 10 megabyte, så er alt bra. Men hva om vi trenger å sende 500 megabyte? 20 gigabyte? 500 terabyte? 30 petabyte? Vil algoritmen vår slutte å virke? Nei, alle disse datamengdene kan faktisk overføres. Vil det ta lengre tid? Ja det vil det! Nå kjenner vi en viktig funksjon ved algoritmen vår: jo større datamengde som skal sendes, jo lengre tid vil det ta å kjøre algoritmen. Men vi vil gjerne ha en mer presis forståelse av dette forholdet (mellom størrelsen på inndatadata og tiden som kreves for å sende den). I vårt tilfelle er den algoritmiske kompleksiteten lineær . "Lineær" betyr at når mengden inndata øker, vil tiden det tar å sende den øke omtrent proporsjonalt. Hvis datamengden dobles, vil tiden som kreves for å sende den være dobbelt så mye. Hvis dataene øker med 10 ganger, vil overføringstiden øke 10 ganger. Ved å bruke stor O-notasjon uttrykkes kompleksiteten til algoritmen vår som O(n). Du bør huske denne notasjonen for fremtiden - den brukes alltid for algoritmer med lineær kompleksitet. Merk at vi ikke snakker om flere ting som kan variere her: Internett-hastighet, datamaskinens beregningskraft og så videre. Når man vurderer kompleksiteten til en algoritme, er det rett og slett ikke fornuftig å vurdere disse faktorene - i alle fall er de utenfor vår kontroll. Big O-notasjonen uttrykker kompleksiteten til selve algoritmen, ikke "miljøet" den kjører i. La oss fortsette med vårt eksempel. Anta at vi til slutt lærer at vi må sende filer på totalt 800 terabyte. Vi kan selvfølgelig utføre oppgaven vår ved å sende dem over Internett. Det er bare ett problem: ved standard husholdningsdataoverføringshastigheter (100 megabit per sekund), vil det ta omtrent 708 dager. Snart 2 år! :O Algoritmen vår passer tydeligvis ikke her. Vi trenger en annen løsning! Uventet kommer IT-giganten Amazon til unnsetning! Amazons snøscootertjeneste lar oss laste opp en stor mengde data til mobillagring og deretter levere den til ønsket adresse med lastebil!
I dette tilfellet er den mest effektive algoritmen å sende filen over Internett. Det kunne ikke ta mer enn et par minutter! La oss gjenta algoritmen vår: "Hvis du ønsker å overføre informasjon i form av filer over en avstand på 5000 miles, bør du sende dataene via Internett". Utmerket. La oss nå analysere det. Klarer det vår oppgave?Vel, ja, det gjør det. Men hva kan vi si om kompleksiteten? Hmm, nå blir ting mer interessant. Faktum er at algoritmen vår er veldig avhengig av inndataene, nemlig størrelsen på filene. Hvis vi har 10 megabyte, så er alt bra. Men hva om vi trenger å sende 500 megabyte? 20 gigabyte? 500 terabyte? 30 petabyte? Vil algoritmen vår slutte å virke? Nei, alle disse datamengdene kan faktisk overføres. Vil det ta lengre tid? Ja det vil det! Nå kjenner vi en viktig funksjon ved algoritmen vår: jo større datamengde som skal sendes, jo lengre tid vil det ta å kjøre algoritmen. Men vi vil gjerne ha en mer presis forståelse av dette forholdet (mellom størrelsen på inndatadata og tiden som kreves for å sende den). I vårt tilfelle er den algoritmiske kompleksiteten lineær . "Lineær" betyr at når mengden inndata øker, vil tiden det tar å sende den øke omtrent proporsjonalt. Hvis datamengden dobles, vil tiden som kreves for å sende den være dobbelt så mye. Hvis dataene øker med 10 ganger, vil overføringstiden øke 10 ganger. Ved å bruke stor O-notasjon uttrykkes kompleksiteten til algoritmen vår som O(n). Du bør huske denne notasjonen for fremtiden - den brukes alltid for algoritmer med lineær kompleksitet. Merk at vi ikke snakker om flere ting som kan variere her: Internett-hastighet, datamaskinens beregningskraft og så videre. Når man vurderer kompleksiteten til en algoritme, er det rett og slett ikke fornuftig å vurdere disse faktorene - i alle fall er de utenfor vår kontroll. Big O-notasjonen uttrykker kompleksiteten til selve algoritmen, ikke "miljøet" den kjører i. La oss fortsette med vårt eksempel. Anta at vi til slutt lærer at vi må sende filer på totalt 800 terabyte. Vi kan selvfølgelig utføre oppgaven vår ved å sende dem over Internett. Det er bare ett problem: ved standard husholdningsdataoverføringshastigheter (100 megabit per sekund), vil det ta omtrent 708 dager. Snart 2 år! :O Algoritmen vår passer tydeligvis ikke her. Vi trenger en annen løsning! Uventet kommer IT-giganten Amazon til unnsetning! Amazons snøscootertjeneste lar oss laste opp en stor mengde data til mobillagring og deretter levere den til ønsket adresse med lastebil!  Så vi har en ny algoritme! "Hvis du ønsker å overføre informasjon i form av filer over en avstand på 5000 miles og å gjøre det vil ta mer enn 14 dager å sende via Internett, bør du sende dataene på en Amazon-lastebil." Vi valgte 14 dager vilkårlig her. La oss si at dette er den lengste perioden vi kan vente. La oss analysere algoritmen vår. Hva med hastigheten? Selv om lastebilen kjører i bare 50 mph, vil den tilbakelegge 5000 miles på bare 100 timer. Dette er litt over fire dager! Dette er mye bedre enn muligheten til å sende dataene over Internett. Og hva med kompleksiteten til denne algoritmen? Er den også lineær, altså O(n)? Nei det er ikke. Tross alt bryr ikke lastebilen seg hvor tungt du laster den – den vil fortsatt kjøre i omtrent samme hastighet og komme frem i tide. Enten vi har 800 terabyte, eller 10 ganger det, vil lastebilen fortsatt nå målet innen 5 dager. Med andre ord har den lastebilbaserte dataoverføringsalgoritmen konstant kompleksitet. Her betyr "konstant" at den ikke er avhengig av størrelsen på inngangsdataene. Sett en 1 GB flash-stasjon i lastebilen, den kommer innen 5 dager. Sett inn disker som inneholder 800 terabyte med data, den kommer innen 5 dager. Når du bruker stor O-notasjon, er konstant kompleksitet betegnet med O(1) . Vi har blitt kjent med O(n) og O(1) , så la oss nå se på flere eksempler i programmeringsverdenen :) Anta at du får en matrise med 100 tall, og oppgaven er å vise hvert av dem på konsollen. Du skriver en vanlig
Så vi har en ny algoritme! "Hvis du ønsker å overføre informasjon i form av filer over en avstand på 5000 miles og å gjøre det vil ta mer enn 14 dager å sende via Internett, bør du sende dataene på en Amazon-lastebil." Vi valgte 14 dager vilkårlig her. La oss si at dette er den lengste perioden vi kan vente. La oss analysere algoritmen vår. Hva med hastigheten? Selv om lastebilen kjører i bare 50 mph, vil den tilbakelegge 5000 miles på bare 100 timer. Dette er litt over fire dager! Dette er mye bedre enn muligheten til å sende dataene over Internett. Og hva med kompleksiteten til denne algoritmen? Er den også lineær, altså O(n)? Nei det er ikke. Tross alt bryr ikke lastebilen seg hvor tungt du laster den – den vil fortsatt kjøre i omtrent samme hastighet og komme frem i tide. Enten vi har 800 terabyte, eller 10 ganger det, vil lastebilen fortsatt nå målet innen 5 dager. Med andre ord har den lastebilbaserte dataoverføringsalgoritmen konstant kompleksitet. Her betyr "konstant" at den ikke er avhengig av størrelsen på inngangsdataene. Sett en 1 GB flash-stasjon i lastebilen, den kommer innen 5 dager. Sett inn disker som inneholder 800 terabyte med data, den kommer innen 5 dager. Når du bruker stor O-notasjon, er konstant kompleksitet betegnet med O(1) . Vi har blitt kjent med O(n) og O(1) , så la oss nå se på flere eksempler i programmeringsverdenen :) Anta at du får en matrise med 100 tall, og oppgaven er å vise hvert av dem på konsollen. Du skriver en vanlig 
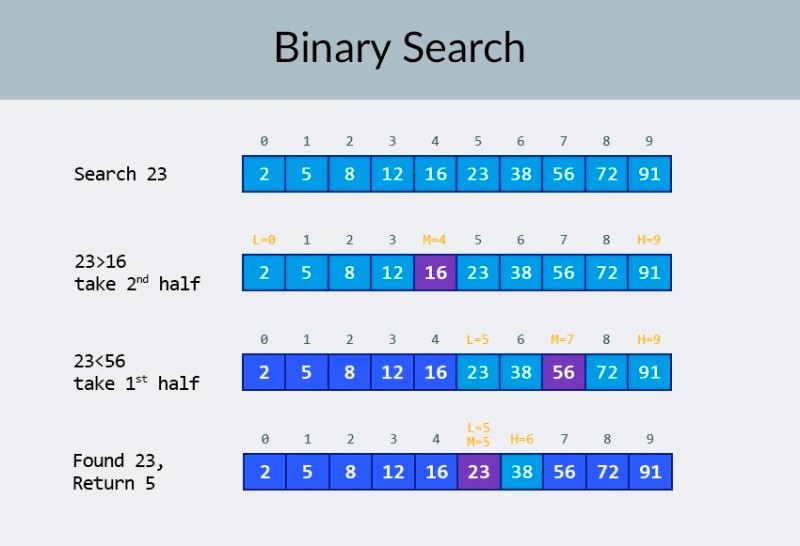 I den øverste raden i bildet ser vi en sortert matrise. Vi må finne tallet 23 i den. I stedet for å iterere over tallene deler vi bare arrayet i 2 deler og sjekker det midterste tallet i arrayet. Finn tallet som er plassert i celle 4 og sjekk det (andre rad i bildet). Dette tallet er 16, og vi ser etter 23. Det nåværende antallet er mindre enn det vi ser etter. Hva betyr det? Det betyr atalle de tidligere tallene (de som ligger før tallet 16) trenger ikke å sjekkes : de er garantert mindre enn det vi ser etter, fordi matrisen vår er sortert! Vi fortsetter søket blant de resterende 5 elementene. Merk:vi har kun utført én sammenligning, men vi har allerede eliminert halvparten av de mulige alternativene. Vi har bare 5 elementer igjen. Vi vil gjenta vårt forrige trinn ved igjen å dele den gjenværende undergruppen i to og igjen ta det midterste elementet (den tredje raden i bildet). Tallet er 56, og det er større enn det vi ser etter. Hva betyr det? Det betyr at vi har eliminert ytterligere 3 muligheter: selve tallet 56 så vel som de to tallene etter det (siden de er garantert større enn 23, fordi matrisen er sortert). Vi har bare 2 tall igjen å sjekke (den siste raden i bildet) — tallene med matriseindeksene 5 og 6. Vi sjekker det første av dem, og finner det vi lette etter — tallet 23! Indeksen er 5! La oss se på resultatene av algoritmen vår, og så vil analysere kompleksiteten. Forresten, nå forstår du hvorfor dette kalles binært søk: det er avhengig av gjentatte ganger å dele dataene i to. Resultatet er imponerende! Hvis vi brukte et lineært søk for å se etter tallet, ville vi trenge opptil 10 sammenligninger, men med et binært søk klarte vi oppgaven med bare 3! I verste fall ville det vært 4 sammenligninger (hvis tallet vi ønsket i det siste trinnet var det andre av de gjenværende mulighetene, i stedet for det første. Så hva med kompleksiteten? Dette er et veldig interessant poeng :) Den binære søkealgoritmen er mye mindre avhengig av antall elementer i matrisen enn den lineære søkealgoritmen (det vil si enkel iterasjon). Med 10 elementer i matrisen vil et lineært søk trenge maksimalt 10 sammenligninger, men et binært søk vil trenge maksimalt 4 sammenligninger. Det er en forskjell på en faktor på 2,5. Men for en matrise på 1000 elementer vil et lineært søk trenge opptil 1000 sammenligninger, men et binært søk krever bare 10 ! Forskjellen er nå 100 ganger! Merk:antall elementer i matrisen har økt 100 ganger (fra 10 til 1000), men antallet sammenligninger som kreves for et binært søk har økt med en faktor på bare 2,5 (fra 4 til 10). Hvis vi kommer til 10 000 elementer , vil forskjellen være enda mer imponerende: 10 000 sammenligninger for lineært søk, og totalt 14 sammenligninger for binært søk. Og igjen, hvis antall elementer øker med 1000 ganger (fra 10 til 10000), øker antallet sammenligninger med en faktor på bare 3,5 (fra 4 til 14). Kompleksiteten til den binære søkealgoritmen er logaritmisk , eller, hvis vi bruker stor O-notasjon, O(log n). Hvorfor heter det det? Logaritmen er som det motsatte av eksponentiering. Den binære logaritmen er potensen som tallet 2 må heves til for å få et tall. For eksempel har vi 10 000 elementer som vi trenger for å søke ved hjelp av den binære søkealgoritmen.
I den øverste raden i bildet ser vi en sortert matrise. Vi må finne tallet 23 i den. I stedet for å iterere over tallene deler vi bare arrayet i 2 deler og sjekker det midterste tallet i arrayet. Finn tallet som er plassert i celle 4 og sjekk det (andre rad i bildet). Dette tallet er 16, og vi ser etter 23. Det nåværende antallet er mindre enn det vi ser etter. Hva betyr det? Det betyr atalle de tidligere tallene (de som ligger før tallet 16) trenger ikke å sjekkes : de er garantert mindre enn det vi ser etter, fordi matrisen vår er sortert! Vi fortsetter søket blant de resterende 5 elementene. Merk:vi har kun utført én sammenligning, men vi har allerede eliminert halvparten av de mulige alternativene. Vi har bare 5 elementer igjen. Vi vil gjenta vårt forrige trinn ved igjen å dele den gjenværende undergruppen i to og igjen ta det midterste elementet (den tredje raden i bildet). Tallet er 56, og det er større enn det vi ser etter. Hva betyr det? Det betyr at vi har eliminert ytterligere 3 muligheter: selve tallet 56 så vel som de to tallene etter det (siden de er garantert større enn 23, fordi matrisen er sortert). Vi har bare 2 tall igjen å sjekke (den siste raden i bildet) — tallene med matriseindeksene 5 og 6. Vi sjekker det første av dem, og finner det vi lette etter — tallet 23! Indeksen er 5! La oss se på resultatene av algoritmen vår, og så vil analysere kompleksiteten. Forresten, nå forstår du hvorfor dette kalles binært søk: det er avhengig av gjentatte ganger å dele dataene i to. Resultatet er imponerende! Hvis vi brukte et lineært søk for å se etter tallet, ville vi trenge opptil 10 sammenligninger, men med et binært søk klarte vi oppgaven med bare 3! I verste fall ville det vært 4 sammenligninger (hvis tallet vi ønsket i det siste trinnet var det andre av de gjenværende mulighetene, i stedet for det første. Så hva med kompleksiteten? Dette er et veldig interessant poeng :) Den binære søkealgoritmen er mye mindre avhengig av antall elementer i matrisen enn den lineære søkealgoritmen (det vil si enkel iterasjon). Med 10 elementer i matrisen vil et lineært søk trenge maksimalt 10 sammenligninger, men et binært søk vil trenge maksimalt 4 sammenligninger. Det er en forskjell på en faktor på 2,5. Men for en matrise på 1000 elementer vil et lineært søk trenge opptil 1000 sammenligninger, men et binært søk krever bare 10 ! Forskjellen er nå 100 ganger! Merk:antall elementer i matrisen har økt 100 ganger (fra 10 til 1000), men antallet sammenligninger som kreves for et binært søk har økt med en faktor på bare 2,5 (fra 4 til 10). Hvis vi kommer til 10 000 elementer , vil forskjellen være enda mer imponerende: 10 000 sammenligninger for lineært søk, og totalt 14 sammenligninger for binært søk. Og igjen, hvis antall elementer øker med 1000 ganger (fra 10 til 10000), øker antallet sammenligninger med en faktor på bare 3,5 (fra 4 til 14). Kompleksiteten til den binære søkealgoritmen er logaritmisk , eller, hvis vi bruker stor O-notasjon, O(log n). Hvorfor heter det det? Logaritmen er som det motsatte av eksponentiering. Den binære logaritmen er potensen som tallet 2 må heves til for å få et tall. For eksempel har vi 10 000 elementer som vi trenger for å søke ved hjelp av den binære søkealgoritmen. 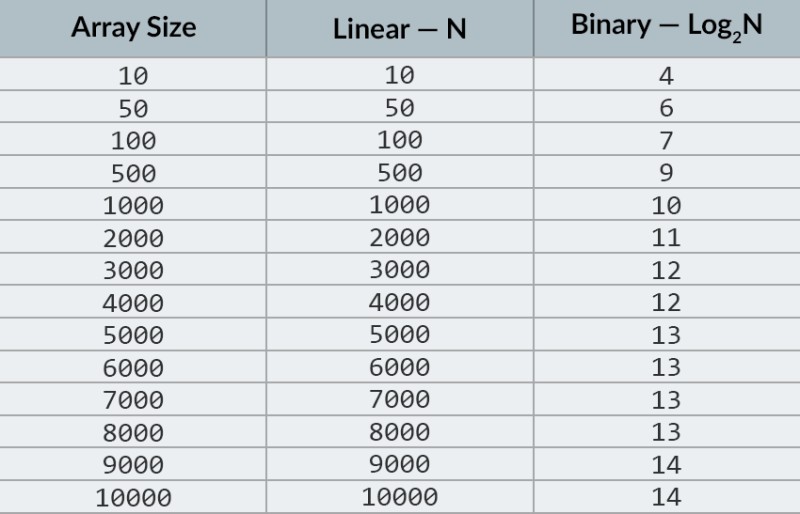 For øyeblikket kan du se på verditabellen for å vite at å gjøre dette vil kreve maksimalt 14 sammenligninger. Men hva om ingen har gitt en slik tabell og du må beregne det nøyaktige maksimale antallet sammenligninger? Du trenger bare å svare på et enkelt spørsmål: til hvilken kraft trenger du å heve tallet 2 slik at resultatet er større enn eller lik antall elementer som skal kontrolleres? For 10 000 er det 14. potens. 2 til 13. potens er for liten (8192), men 2 til 14. potens = 16384, og dette tallet tilfredsstiller vår betingelse (det er større enn eller lik antall elementer i matrisen). Vi fant logaritmen: 14. Så mange sammenligninger kan vi trenge! :) Algoritmer og algoritmisk kompleksitet er et for bredt emne til å passe inn i én leksjon. Men å vite det er veldig viktig: mange jobbintervjuer vil involvere spørsmål som involverer algoritmer. For teorien kan jeg anbefale noen bøker for deg. Du kan starte med " Grokking Algorithms ". Eksemplene i denne boken er skrevet i Python, men boken bruker veldig enkelt språk og eksempler. Det er det beste alternativet for en nybegynner, og dessuten er det ikke veldig stort. Blant mer seriøs lesning har vi bøker av Robert Lafore og Robert Sedgewick. Begge er skrevet i Java, noe som vil gjøre læringen litt enklere for deg. Tross alt er du ganske kjent med dette språket! :) For elever med gode matematiske ferdigheter er det beste alternativet Thomas Cormens bok . Men teori alene vil ikke fylle magen din! Kunnskap != Evne . Du kan øve på å løse problemer som involverer algoritmer på HackerRank og LeetCode . Oppgaver fra disse nettsidene blir ofte brukt selv under intervjuer hos Google og Facebook, så du kommer definitivt ikke til å kjede deg :) For å forsterke dette leksjonsmaterialet anbefaler jeg at du ser denne utmerkede videoen om stor O-notasjon på YouTube. Vi sees i neste leksjoner! :)
For øyeblikket kan du se på verditabellen for å vite at å gjøre dette vil kreve maksimalt 14 sammenligninger. Men hva om ingen har gitt en slik tabell og du må beregne det nøyaktige maksimale antallet sammenligninger? Du trenger bare å svare på et enkelt spørsmål: til hvilken kraft trenger du å heve tallet 2 slik at resultatet er større enn eller lik antall elementer som skal kontrolleres? For 10 000 er det 14. potens. 2 til 13. potens er for liten (8192), men 2 til 14. potens = 16384, og dette tallet tilfredsstiller vår betingelse (det er større enn eller lik antall elementer i matrisen). Vi fant logaritmen: 14. Så mange sammenligninger kan vi trenge! :) Algoritmer og algoritmisk kompleksitet er et for bredt emne til å passe inn i én leksjon. Men å vite det er veldig viktig: mange jobbintervjuer vil involvere spørsmål som involverer algoritmer. For teorien kan jeg anbefale noen bøker for deg. Du kan starte med " Grokking Algorithms ". Eksemplene i denne boken er skrevet i Python, men boken bruker veldig enkelt språk og eksempler. Det er det beste alternativet for en nybegynner, og dessuten er det ikke veldig stort. Blant mer seriøs lesning har vi bøker av Robert Lafore og Robert Sedgewick. Begge er skrevet i Java, noe som vil gjøre læringen litt enklere for deg. Tross alt er du ganske kjent med dette språket! :) For elever med gode matematiske ferdigheter er det beste alternativet Thomas Cormens bok . Men teori alene vil ikke fylle magen din! Kunnskap != Evne . Du kan øve på å løse problemer som involverer algoritmer på HackerRank og LeetCode . Oppgaver fra disse nettsidene blir ofte brukt selv under intervjuer hos Google og Facebook, så du kommer definitivt ikke til å kjede deg :) For å forsterke dette leksjonsmaterialet anbefaler jeg at du ser denne utmerkede videoen om stor O-notasjon på YouTube. Vi sees i neste leksjoner! :)
