やあ!今日のレッスンは他のレッスンとは少し異なります。Java に間接的にのみ関連するという点で異なります。 ![アルゴリズムの複雑さ - 1]() とはいえ、このトピックはすべてのプログラマーにとって非常に重要です。アルゴリズムについて話します。アルゴリズムとは何ですか? 簡単に言えば、これは、望ましい結果を達成するために完了する必要がある一連のアクションです。私たちは日常生活でアルゴリズムを頻繁に使用します。たとえば、毎朝、学校または職場に行き、同時に次のことを行うという特定のタスクがあります。
とはいえ、このトピックはすべてのプログラマーにとって非常に重要です。アルゴリズムについて話します。アルゴリズムとは何ですか? 簡単に言えば、これは、望ましい結果を達成するために完了する必要がある一連のアクションです。私たちは日常生活でアルゴリズムを頻繁に使用します。たとえば、毎朝、学校または職場に行き、同時に次のことを行うという特定のタスクがあります。
![アルゴリズムの複雑さ - 2]() この場合、最も効率的なアルゴリズムは、インターネット経由でファイルを送信することです。数分もかからないでしょう!私たちのアルゴリズムを言い換えましょう。 「5000 マイルの距離を越えて情報をファイル形式で転送したい場合は、インターネット経由でデータを送信する必要があります。」 素晴らしい。それでは分析してみましょう。 それは私たちの任務を達成するでしょうか?そうですね、そうです。しかし、その複雑さについては何が言えるでしょうか? うーん、物事はさらに面白くなってきました。実際のところ、私たちのアルゴリズムは入力データ、つまりファイルのサイズに大きく依存しています。10 メガバイトあれば、すべて問題ありません。しかし、500 メガバイトを送信する必要がある場合はどうすればよいでしょうか? 20ギガバイト?500テラバイト?30ペタバイト?私たちのアルゴリズムは機能しなくなりますか? いいえ、これらの量のデータはすべて実際に転送できます。 もっと時間がかかりますか?はい、そうなります!これで、アルゴリズムの重要な特徴がわかりました。送信するデータの量が多いほど、アルゴリズムの実行にかかる時間が長くなります。。しかし、この関係 (入力データのサイズと送信に必要な時間の間) をより正確に理解したいと考えています。私たちの場合、アルゴリズムの複雑さは線形です。「線形」とは、入力データの量が増加すると、送信にかかる時間がほぼ比例して増加することを意味します。データ量が 2 倍になれば、送信にかかる時間も 2 倍になります。データが 10 倍に増加すると、送信時間も 10 倍になります。ビッグ O 表記を使用すると、アルゴリズムの複雑さはO(n)として表されます。。この表記法は将来のために覚えておくべきです。線形複雑さを持つアルゴリズムには常に使用されます。ここでは、インターネット速度やコンピューターの計算能力など、異なる可能性のあるいくつかの事柄について話しているわけではないことに注意してください。アルゴリズムの複雑さを評価するときに、これらの要素を考慮することはまったく意味がありません。いずれにせよ、それらは私たちの制御の外です。Big O 表記は、アルゴリズムが実行される「環境」ではなく、アルゴリズム自体の複雑さを表します。 例を続けてみましょう。最終的に、合計 800 テラバイトのファイルを送信する必要があることがわかったとします。もちろん、インターネット経由で送信することでタスクを達成できます。問題が 1 つだけあります。標準的な家庭用データ伝送速度 (100 メガビット/秒) では、約 708 日かかります。 ほぼ2年ぶり!:O 私たちのアルゴリズムは明らかにここでは適切ではありません。他の解決策が必要です! 思いがけず、IT 大手の Amazon が私たちを助けてくれました。Amazon の Snowmobile サービスを使用すると、大量のデータをモバイル ストレージにアップロードし、トラックで目的の住所に配送できます。
この場合、最も効率的なアルゴリズムは、インターネット経由でファイルを送信することです。数分もかからないでしょう!私たちのアルゴリズムを言い換えましょう。 「5000 マイルの距離を越えて情報をファイル形式で転送したい場合は、インターネット経由でデータを送信する必要があります。」 素晴らしい。それでは分析してみましょう。 それは私たちの任務を達成するでしょうか?そうですね、そうです。しかし、その複雑さについては何が言えるでしょうか? うーん、物事はさらに面白くなってきました。実際のところ、私たちのアルゴリズムは入力データ、つまりファイルのサイズに大きく依存しています。10 メガバイトあれば、すべて問題ありません。しかし、500 メガバイトを送信する必要がある場合はどうすればよいでしょうか? 20ギガバイト?500テラバイト?30ペタバイト?私たちのアルゴリズムは機能しなくなりますか? いいえ、これらの量のデータはすべて実際に転送できます。 もっと時間がかかりますか?はい、そうなります!これで、アルゴリズムの重要な特徴がわかりました。送信するデータの量が多いほど、アルゴリズムの実行にかかる時間が長くなります。。しかし、この関係 (入力データのサイズと送信に必要な時間の間) をより正確に理解したいと考えています。私たちの場合、アルゴリズムの複雑さは線形です。「線形」とは、入力データの量が増加すると、送信にかかる時間がほぼ比例して増加することを意味します。データ量が 2 倍になれば、送信にかかる時間も 2 倍になります。データが 10 倍に増加すると、送信時間も 10 倍になります。ビッグ O 表記を使用すると、アルゴリズムの複雑さはO(n)として表されます。。この表記法は将来のために覚えておくべきです。線形複雑さを持つアルゴリズムには常に使用されます。ここでは、インターネット速度やコンピューターの計算能力など、異なる可能性のあるいくつかの事柄について話しているわけではないことに注意してください。アルゴリズムの複雑さを評価するときに、これらの要素を考慮することはまったく意味がありません。いずれにせよ、それらは私たちの制御の外です。Big O 表記は、アルゴリズムが実行される「環境」ではなく、アルゴリズム自体の複雑さを表します。 例を続けてみましょう。最終的に、合計 800 テラバイトのファイルを送信する必要があることがわかったとします。もちろん、インターネット経由で送信することでタスクを達成できます。問題が 1 つだけあります。標準的な家庭用データ伝送速度 (100 メガビット/秒) では、約 708 日かかります。 ほぼ2年ぶり!:O 私たちのアルゴリズムは明らかにここでは適切ではありません。他の解決策が必要です! 思いがけず、IT 大手の Amazon が私たちを助けてくれました。Amazon の Snowmobile サービスを使用すると、大量のデータをモバイル ストレージにアップロードし、トラックで目的の住所に配送できます。 ![アルゴリズムの複雑さ - 3]() そこで、新しいアルゴリズムを導入しました。 「ファイル形式で情報を 5000 マイルの距離を越えて転送したい場合、インターネット経由で送信するには 14 日以上かかる場合は、Amazon のトラックでデータを送信する必要があります。」 ここでは任意に 14 日間を選択しました。これが待つことができる最長の期間だとしましょう。アルゴリズムを分析してみましょう。そのスピードはどうでしょうか?たとえトラックが時速 80 マイルで走行したとしても、わずか 100 時間で 5,000 マイルを走行することになります。ここまであと4日ちょっとです!これは、インターネット経由でデータを送信するオプションよりもはるかに優れています。そして、このアルゴリズムの複雑さについてはどうでしょうか? これも線形ですか、つまり O(n) ですか? いいえそうではありません。結局のところ、トラックはあなたがどれだけ荷物を積んでいるかを気にしません。それでもほぼ同じ速度で走行し、時間通りに到着します。800 テラバイトであっても、その 10 倍であっても、トラックは 5 日以内に目的地に到着します。言い換えれば、トラックベースのデータ転送アルゴリズムは一定の複雑さを持っています。。ここで「一定」とは、入力データのサイズに依存しないことを意味します。1GBのフラッシュドライブをトラックに積めば、5日以内に到着します。800 テラバイトのデータを含むディスクを入れると、5 日以内に到着します。big O 表記を使用する場合、一定の複雑さはO(1)で表されます。O(n)とO(1)には慣れてきたので、プログラミングの世界でさらに例を見てみましょう :) 100 個の数値の配列が与えられ、それらのそれぞれを表示するというタスクがあるとします。コンソール。
そこで、新しいアルゴリズムを導入しました。 「ファイル形式で情報を 5000 マイルの距離を越えて転送したい場合、インターネット経由で送信するには 14 日以上かかる場合は、Amazon のトラックでデータを送信する必要があります。」 ここでは任意に 14 日間を選択しました。これが待つことができる最長の期間だとしましょう。アルゴリズムを分析してみましょう。そのスピードはどうでしょうか?たとえトラックが時速 80 マイルで走行したとしても、わずか 100 時間で 5,000 マイルを走行することになります。ここまであと4日ちょっとです!これは、インターネット経由でデータを送信するオプションよりもはるかに優れています。そして、このアルゴリズムの複雑さについてはどうでしょうか? これも線形ですか、つまり O(n) ですか? いいえそうではありません。結局のところ、トラックはあなたがどれだけ荷物を積んでいるかを気にしません。それでもほぼ同じ速度で走行し、時間通りに到着します。800 テラバイトであっても、その 10 倍であっても、トラックは 5 日以内に目的地に到着します。言い換えれば、トラックベースのデータ転送アルゴリズムは一定の複雑さを持っています。。ここで「一定」とは、入力データのサイズに依存しないことを意味します。1GBのフラッシュドライブをトラックに積めば、5日以内に到着します。800 テラバイトのデータを含むディスクを入れると、5 日以内に到着します。big O 表記を使用する場合、一定の複雑さはO(1)で表されます。O(n)とO(1)には慣れてきたので、プログラミングの世界でさらに例を見てみましょう :) 100 個の数値の配列が与えられ、それらのそれぞれを表示するというタスクがあるとします。コンソール。
![Java webinar]()
![アルゴリズムの複雑さ - 5]() 画像の一番上の行には、ソートされた配列が表示されます。この中から 23 という数字を見つける必要があります。数値を反復処理する代わりに、単純に配列を 2 つの部分に分割し、配列内の中央の数値をチェックします。セル 4 にある数字を見つけて確認します (画像の 2 行目)。この数は 16 で、私たちは 23 を探しています。現在の数は私たちが探している数よりも少ないです。どういう意味ですか?だということだ以前のすべての数値 (数値 16 より前にある数値) をチェックする必要はありません。配列はソートされているため、それらは探している数値よりも小さいことが保証されています。残りの 5 つの要素の間で検索を続けます。 ノート:比較は 1 回だけ実行しましたが、考えられる選択肢の半分はすでに除外されています。残っている要素は 5 つだけです。残りのサブ配列をもう一度半分に分割し、再び中央の要素 (画像の 3 行目) を取得することで、前のステップを繰り返します。その数は 56 で、探しているものよりも大きいです。どういう意味ですか?これは、さらに 3 つの可能性を排除したことを意味します。数値 56 自体とその後の 2 つの数値 (配列がソートされているため、これらの数値は 23 より大きいことが保証されているため)。チェックすべき数値は 2 つだけ残っています (画像の最後の行)、配列インデックス 5 と 6 の数値です。それらの最初の数値をチェックすると、探していた数値である 23 が見つかります。その指数は5です!アルゴリズムの結果を見てみましょう。その複雑さを分析します。ところで、これがなぜ二分探索と呼ばれるか理解できたでしょう。それはデータを繰り返し半分に分割することに依存しています。結果は素晴らしいものでした!線形検索を使用して数値を検索すると、最大 10 回の比較が必要になりますが、二分検索を使用すると、わずか 3 回の比較でタスクを完了できました。最悪の場合、4 つの比較が行われることになります (最後のステップで、必要な数値が残りの可能性の最初ではなく 2 番目だった場合。では、その複雑さはどうなのでしょうか? これは非常に興味深い点です :) 二分探索アルゴリズムは、線形探索アルゴリズム (つまり、単純な反復) よりも配列内の要素の数にあまり依存しません。配列内の要素が10 個 の場合、線形検索では最大 10 回の比較が必要ですが、二分検索では最大 4 回の比較が必要になります。それは2.5倍の差です。ただし、要素が 1000 個ある配列の場合、線形検索では最大 1000 回の比較が必要ですが、二分検索では10 回だけ必要になります。その差はなんと100倍! ノート:配列内の要素の数は 100 倍 (10 から 1000) に増加しましたが、二分探索に必要な比較の数は 2.5 倍 (4 から 10) しか増加しませんでした。要素が 10,000 個に達すると、その差はさらに顕著になります。線形検索では 10,000 回の比較が行われ、二分検索では合計 14 回の比較が行われます。また、要素の数が 1000 倍 (10 から 10000) に増加した場合、比較の数は 3.5 倍 (4 から 14) だけ増加します。 二分探索アルゴリズムの複雑さは対数、つまりビッグ O 表記を使用する場合はO(log n)です。。なぜそう呼ばれるのでしょうか?対数は累乗の逆のようなものです。2 進対数は、数値を得るために数値 2 を累乗する必要があります。たとえば、二分探索アルゴリズムを使用して検索する必要がある要素が 10,000 個あります。
画像の一番上の行には、ソートされた配列が表示されます。この中から 23 という数字を見つける必要があります。数値を反復処理する代わりに、単純に配列を 2 つの部分に分割し、配列内の中央の数値をチェックします。セル 4 にある数字を見つけて確認します (画像の 2 行目)。この数は 16 で、私たちは 23 を探しています。現在の数は私たちが探している数よりも少ないです。どういう意味ですか?だということだ以前のすべての数値 (数値 16 より前にある数値) をチェックする必要はありません。配列はソートされているため、それらは探している数値よりも小さいことが保証されています。残りの 5 つの要素の間で検索を続けます。 ノート:比較は 1 回だけ実行しましたが、考えられる選択肢の半分はすでに除外されています。残っている要素は 5 つだけです。残りのサブ配列をもう一度半分に分割し、再び中央の要素 (画像の 3 行目) を取得することで、前のステップを繰り返します。その数は 56 で、探しているものよりも大きいです。どういう意味ですか?これは、さらに 3 つの可能性を排除したことを意味します。数値 56 自体とその後の 2 つの数値 (配列がソートされているため、これらの数値は 23 より大きいことが保証されているため)。チェックすべき数値は 2 つだけ残っています (画像の最後の行)、配列インデックス 5 と 6 の数値です。それらの最初の数値をチェックすると、探していた数値である 23 が見つかります。その指数は5です!アルゴリズムの結果を見てみましょう。その複雑さを分析します。ところで、これがなぜ二分探索と呼ばれるか理解できたでしょう。それはデータを繰り返し半分に分割することに依存しています。結果は素晴らしいものでした!線形検索を使用して数値を検索すると、最大 10 回の比較が必要になりますが、二分検索を使用すると、わずか 3 回の比較でタスクを完了できました。最悪の場合、4 つの比較が行われることになります (最後のステップで、必要な数値が残りの可能性の最初ではなく 2 番目だった場合。では、その複雑さはどうなのでしょうか? これは非常に興味深い点です :) 二分探索アルゴリズムは、線形探索アルゴリズム (つまり、単純な反復) よりも配列内の要素の数にあまり依存しません。配列内の要素が10 個 の場合、線形検索では最大 10 回の比較が必要ですが、二分検索では最大 4 回の比較が必要になります。それは2.5倍の差です。ただし、要素が 1000 個ある配列の場合、線形検索では最大 1000 回の比較が必要ですが、二分検索では10 回だけ必要になります。その差はなんと100倍! ノート:配列内の要素の数は 100 倍 (10 から 1000) に増加しましたが、二分探索に必要な比較の数は 2.5 倍 (4 から 10) しか増加しませんでした。要素が 10,000 個に達すると、その差はさらに顕著になります。線形検索では 10,000 回の比較が行われ、二分検索では合計 14 回の比較が行われます。また、要素の数が 1000 倍 (10 から 10000) に増加した場合、比較の数は 3.5 倍 (4 から 14) だけ増加します。 二分探索アルゴリズムの複雑さは対数、つまりビッグ O 表記を使用する場合はO(log n)です。。なぜそう呼ばれるのでしょうか?対数は累乗の逆のようなものです。2 進対数は、数値を得るために数値 2 を累乗する必要があります。たとえば、二分探索アルゴリズムを使用して検索する必要がある要素が 10,000 個あります。 ![アルゴリズムの複雑さ - 6]() 現時点では、値の表を見ると、これを行うには最大 14 回の比較が必要であることがわかります。しかし、誰もそのようなテーブルを提供しておらず、正確な最大比較数を計算する必要がある場合はどうすればよいでしょうか? 単純な質問に答えるだけで済みます。結果がチェックされる要素の数以上になるように、数値 2 を何乗する必要がありますか? 10,000 の場合、14 乗になります。2 の 13 乗 (8192) は小さすぎますが、2 の 14 乗 = 16384、この数は条件を満たします (配列内の要素の数以上です)。対数は 14 でした。必要な比較の数はこれだけです。:) アルゴリズムとアルゴリズムの複雑さは、1 つのレッスンに収めるには広すぎるトピックです。しかし、それを知っておくことは非常に重要です。多くの就職面接では、アルゴリズムに関する質問が行われます。理論については、いくつかの本をお勧めします。「Grokking アルゴリズム」から始めることができます。この本の例は Python で書かれていますが、非常に単純な言語と例が使用されています。初心者にとっては最良の選択肢であり、さらに、それほど大きくありません。より本格的な読書としては、ロバート ラフォアとロバート セジウィックの本があります。。どちらも Java で書かれているため、学習が少し簡単になります。結局のところ、あなたはこの言語にかなり精通しています。:) 優れた数学スキルを持つ学生にとって、最良の選択肢はThomas Cormen の本です。しかし、理論だけではお腹は満たされません。 知識!= 能力。HackerRankとLeetCodeのアルゴリズムに関連する問題を解く練習をすることができます。これらの Web サイトのタスクは、Google や Facebook での面接中にも頻繁に使用されるため、絶対に退屈することはありません :) このレッスンの内容を強化するために、 YouTube でBig O 記法に関するこの優れたビデオを視聴することをお勧めします。次のレッスンでお会いしましょう!:)
現時点では、値の表を見ると、これを行うには最大 14 回の比較が必要であることがわかります。しかし、誰もそのようなテーブルを提供しておらず、正確な最大比較数を計算する必要がある場合はどうすればよいでしょうか? 単純な質問に答えるだけで済みます。結果がチェックされる要素の数以上になるように、数値 2 を何乗する必要がありますか? 10,000 の場合、14 乗になります。2 の 13 乗 (8192) は小さすぎますが、2 の 14 乗 = 16384、この数は条件を満たします (配列内の要素の数以上です)。対数は 14 でした。必要な比較の数はこれだけです。:) アルゴリズムとアルゴリズムの複雑さは、1 つのレッスンに収めるには広すぎるトピックです。しかし、それを知っておくことは非常に重要です。多くの就職面接では、アルゴリズムに関する質問が行われます。理論については、いくつかの本をお勧めします。「Grokking アルゴリズム」から始めることができます。この本の例は Python で書かれていますが、非常に単純な言語と例が使用されています。初心者にとっては最良の選択肢であり、さらに、それほど大きくありません。より本格的な読書としては、ロバート ラフォアとロバート セジウィックの本があります。。どちらも Java で書かれているため、学習が少し簡単になります。結局のところ、あなたはこの言語にかなり精通しています。:) 優れた数学スキルを持つ学生にとって、最良の選択肢はThomas Cormen の本です。しかし、理論だけではお腹は満たされません。 知識!= 能力。HackerRankとLeetCodeのアルゴリズムに関連する問題を解く練習をすることができます。これらの Web サイトのタスクは、Google や Facebook での面接中にも頻繁に使用されるため、絶対に退屈することはありません :) このレッスンの内容を強化するために、 YouTube でBig O 記法に関するこの優れたビデオを視聴することをお勧めします。次のレッスンでお会いしましょう!:)
![Java university]()
 とはいえ、このトピックはすべてのプログラマーにとって非常に重要です。アルゴリズムについて話します。アルゴリズムとは何ですか? 簡単に言えば、これは、望ましい結果を達成するために完了する必要がある一連のアクションです。私たちは日常生活でアルゴリズムを頻繁に使用します。たとえば、毎朝、学校または職場に行き、同時に次のことを行うという特定のタスクがあります。
とはいえ、このトピックはすべてのプログラマーにとって非常に重要です。アルゴリズムについて話します。アルゴリズムとは何ですか? 簡単に言えば、これは、望ましい結果を達成するために完了する必要がある一連のアクションです。私たちは日常生活でアルゴリズムを頻繁に使用します。たとえば、毎朝、学校または職場に行き、同時に次のことを行うという特定のタスクがあります。
- 着衣
- 綺麗
- FRB
- 目覚まし時計を使って起きます。
- シャワーを浴びて体を洗います。
- 朝食とコーヒーか紅茶を作ります。
- 食べる。
- 前の晩にアイロンをかけなかった場合は、アイロンをかけます。
- 服を着てください。
- 家を出ます。
- Webster's Third New International Dictionary の 1961 年版を購入またはダウンロードします。
- この辞書のリストからすべての名前を見つけてください。
- 紙にその名前が載っている辞書のページを書きます。
- 紙を使って名前を並べ替えます。
 この場合、最も効率的なアルゴリズムは、インターネット経由でファイルを送信することです。数分もかからないでしょう!私たちのアルゴリズムを言い換えましょう。 「5000 マイルの距離を越えて情報をファイル形式で転送したい場合は、インターネット経由でデータを送信する必要があります。」 素晴らしい。それでは分析してみましょう。 それは私たちの任務を達成するでしょうか?そうですね、そうです。しかし、その複雑さについては何が言えるでしょうか? うーん、物事はさらに面白くなってきました。実際のところ、私たちのアルゴリズムは入力データ、つまりファイルのサイズに大きく依存しています。10 メガバイトあれば、すべて問題ありません。しかし、500 メガバイトを送信する必要がある場合はどうすればよいでしょうか? 20ギガバイト?500テラバイト?30ペタバイト?私たちのアルゴリズムは機能しなくなりますか? いいえ、これらの量のデータはすべて実際に転送できます。 もっと時間がかかりますか?はい、そうなります!これで、アルゴリズムの重要な特徴がわかりました。送信するデータの量が多いほど、アルゴリズムの実行にかかる時間が長くなります。。しかし、この関係 (入力データのサイズと送信に必要な時間の間) をより正確に理解したいと考えています。私たちの場合、アルゴリズムの複雑さは線形です。「線形」とは、入力データの量が増加すると、送信にかかる時間がほぼ比例して増加することを意味します。データ量が 2 倍になれば、送信にかかる時間も 2 倍になります。データが 10 倍に増加すると、送信時間も 10 倍になります。ビッグ O 表記を使用すると、アルゴリズムの複雑さはO(n)として表されます。。この表記法は将来のために覚えておくべきです。線形複雑さを持つアルゴリズムには常に使用されます。ここでは、インターネット速度やコンピューターの計算能力など、異なる可能性のあるいくつかの事柄について話しているわけではないことに注意してください。アルゴリズムの複雑さを評価するときに、これらの要素を考慮することはまったく意味がありません。いずれにせよ、それらは私たちの制御の外です。Big O 表記は、アルゴリズムが実行される「環境」ではなく、アルゴリズム自体の複雑さを表します。 例を続けてみましょう。最終的に、合計 800 テラバイトのファイルを送信する必要があることがわかったとします。もちろん、インターネット経由で送信することでタスクを達成できます。問題が 1 つだけあります。標準的な家庭用データ伝送速度 (100 メガビット/秒) では、約 708 日かかります。 ほぼ2年ぶり!:O 私たちのアルゴリズムは明らかにここでは適切ではありません。他の解決策が必要です! 思いがけず、IT 大手の Amazon が私たちを助けてくれました。Amazon の Snowmobile サービスを使用すると、大量のデータをモバイル ストレージにアップロードし、トラックで目的の住所に配送できます。
この場合、最も効率的なアルゴリズムは、インターネット経由でファイルを送信することです。数分もかからないでしょう!私たちのアルゴリズムを言い換えましょう。 「5000 マイルの距離を越えて情報をファイル形式で転送したい場合は、インターネット経由でデータを送信する必要があります。」 素晴らしい。それでは分析してみましょう。 それは私たちの任務を達成するでしょうか?そうですね、そうです。しかし、その複雑さについては何が言えるでしょうか? うーん、物事はさらに面白くなってきました。実際のところ、私たちのアルゴリズムは入力データ、つまりファイルのサイズに大きく依存しています。10 メガバイトあれば、すべて問題ありません。しかし、500 メガバイトを送信する必要がある場合はどうすればよいでしょうか? 20ギガバイト?500テラバイト?30ペタバイト?私たちのアルゴリズムは機能しなくなりますか? いいえ、これらの量のデータはすべて実際に転送できます。 もっと時間がかかりますか?はい、そうなります!これで、アルゴリズムの重要な特徴がわかりました。送信するデータの量が多いほど、アルゴリズムの実行にかかる時間が長くなります。。しかし、この関係 (入力データのサイズと送信に必要な時間の間) をより正確に理解したいと考えています。私たちの場合、アルゴリズムの複雑さは線形です。「線形」とは、入力データの量が増加すると、送信にかかる時間がほぼ比例して増加することを意味します。データ量が 2 倍になれば、送信にかかる時間も 2 倍になります。データが 10 倍に増加すると、送信時間も 10 倍になります。ビッグ O 表記を使用すると、アルゴリズムの複雑さはO(n)として表されます。。この表記法は将来のために覚えておくべきです。線形複雑さを持つアルゴリズムには常に使用されます。ここでは、インターネット速度やコンピューターの計算能力など、異なる可能性のあるいくつかの事柄について話しているわけではないことに注意してください。アルゴリズムの複雑さを評価するときに、これらの要素を考慮することはまったく意味がありません。いずれにせよ、それらは私たちの制御の外です。Big O 表記は、アルゴリズムが実行される「環境」ではなく、アルゴリズム自体の複雑さを表します。 例を続けてみましょう。最終的に、合計 800 テラバイトのファイルを送信する必要があることがわかったとします。もちろん、インターネット経由で送信することでタスクを達成できます。問題が 1 つだけあります。標準的な家庭用データ伝送速度 (100 メガビット/秒) では、約 708 日かかります。 ほぼ2年ぶり!:O 私たちのアルゴリズムは明らかにここでは適切ではありません。他の解決策が必要です! 思いがけず、IT 大手の Amazon が私たちを助けてくれました。Amazon の Snowmobile サービスを使用すると、大量のデータをモバイル ストレージにアップロードし、トラックで目的の住所に配送できます。  そこで、新しいアルゴリズムを導入しました。 「ファイル形式で情報を 5000 マイルの距離を越えて転送したい場合、インターネット経由で送信するには 14 日以上かかる場合は、Amazon のトラックでデータを送信する必要があります。」 ここでは任意に 14 日間を選択しました。これが待つことができる最長の期間だとしましょう。アルゴリズムを分析してみましょう。そのスピードはどうでしょうか?たとえトラックが時速 80 マイルで走行したとしても、わずか 100 時間で 5,000 マイルを走行することになります。ここまであと4日ちょっとです!これは、インターネット経由でデータを送信するオプションよりもはるかに優れています。そして、このアルゴリズムの複雑さについてはどうでしょうか? これも線形ですか、つまり O(n) ですか? いいえそうではありません。結局のところ、トラックはあなたがどれだけ荷物を積んでいるかを気にしません。それでもほぼ同じ速度で走行し、時間通りに到着します。800 テラバイトであっても、その 10 倍であっても、トラックは 5 日以内に目的地に到着します。言い換えれば、トラックベースのデータ転送アルゴリズムは一定の複雑さを持っています。。ここで「一定」とは、入力データのサイズに依存しないことを意味します。1GBのフラッシュドライブをトラックに積めば、5日以内に到着します。800 テラバイトのデータを含むディスクを入れると、5 日以内に到着します。big O 表記を使用する場合、一定の複雑さはO(1)で表されます。O(n)とO(1)には慣れてきたので、プログラミングの世界でさらに例を見てみましょう :) 100 個の数値の配列が与えられ、それらのそれぞれを表示するというタスクがあるとします。コンソール。
そこで、新しいアルゴリズムを導入しました。 「ファイル形式で情報を 5000 マイルの距離を越えて転送したい場合、インターネット経由で送信するには 14 日以上かかる場合は、Amazon のトラックでデータを送信する必要があります。」 ここでは任意に 14 日間を選択しました。これが待つことができる最長の期間だとしましょう。アルゴリズムを分析してみましょう。そのスピードはどうでしょうか?たとえトラックが時速 80 マイルで走行したとしても、わずか 100 時間で 5,000 マイルを走行することになります。ここまであと4日ちょっとです!これは、インターネット経由でデータを送信するオプションよりもはるかに優れています。そして、このアルゴリズムの複雑さについてはどうでしょうか? これも線形ですか、つまり O(n) ですか? いいえそうではありません。結局のところ、トラックはあなたがどれだけ荷物を積んでいるかを気にしません。それでもほぼ同じ速度で走行し、時間通りに到着します。800 テラバイトであっても、その 10 倍であっても、トラックは 5 日以内に目的地に到着します。言い換えれば、トラックベースのデータ転送アルゴリズムは一定の複雑さを持っています。。ここで「一定」とは、入力データのサイズに依存しないことを意味します。1GBのフラッシュドライブをトラックに積めば、5日以内に到着します。800 テラバイトのデータを含むディスクを入れると、5 日以内に到着します。big O 表記を使用する場合、一定の複雑さはO(1)で表されます。O(n)とO(1)には慣れてきたので、プログラミングの世界でさらに例を見てみましょう :) 100 個の数値の配列が与えられ、それらのそれぞれを表示するというタスクがあるとします。コンソール。forこのタスクを実行する 通常のループを作成します。

int[] numbers = new int[100];
// ...fill the array with numbers
for (int i: numbers) {
System.out.println(i);
}public static void main(String[] args) {
LinkedList<Integer> numbers = new LinkedList<>();
numbers.add(0, 20202);
numbers.add(0, 123);
numbers.add(0, 8283);
}LinkedList。LinkedListこの例では、単一の数値を に挿入するアルゴリズムの複雑さと、それがリスト内の要素の数にどのように依存するかを評価する必要があります。答えはO(1)、つまり一定の複雑さです。なぜ?各番号をリストの先頭に挿入していることに注意してください。さらに、 に数値を挿入してもLinkedList、要素はどこにも移動しないことを思い出してください。リンク (または参照) が更新されます (LinkedList がどのように機能するかを忘れた場合は、古いレッスンを参照してください)。リストの最初の数値が でx、リストの先頭に数値 y を挿入する場合、必要なのはこれだけです。
x.previous = y;
y.previous = null;
y.next = x;LinkedListアルゴリズムの複雑さは一定、つまり O(1) です。
対数複雑度
パニックにならない!:) 「対数」という言葉を聞いてこのレッスンを閉じて読むのをやめたくなった場合は、数分間待ってください。ここではおかしな計算は行いません (そのような説明は他の場所にたくさんあります)。それぞれの例を取り上げていきます。あなたのタスクは、100 個の数値の配列の中から特定の 1 つの数値を見つけることであると想像してください。より正確には、それが存在するかどうかを確認する必要があります。必要な番号が見つかるとすぐに検索が終了し、コンソールに「必要な番号が見つかりました! 配列内のインデックス = ....」というメッセージが表示されます。このタスクをどのように実行しますか? ここでの解決策は明白です。配列の要素を最初 (または最後) から 1 つずつ繰り返して、現在の数値が探している数値と一致するかどうかを確認する必要があります。によると、アクションの数は配列内の要素の数に直接依存します。100 個の数値がある場合、次の要素に 100 回移動して 100 回の比較を実行する必要がある可能性があります。1000 個の数値がある場合、1000 回の比較が行われる可能性があります。これは明らかに線形複雑さです。O(n)。ここで、この例に 1 つの改良を加えます。数値を見つける必要がある配列は昇順で並べ替えられます。これにより、私たちのタスクに関して何か変わりますか? 希望する番号をブルートフォース検索することもできます。しかし、代わりに、よく知られた二分探索アルゴリズムを使用することもできます。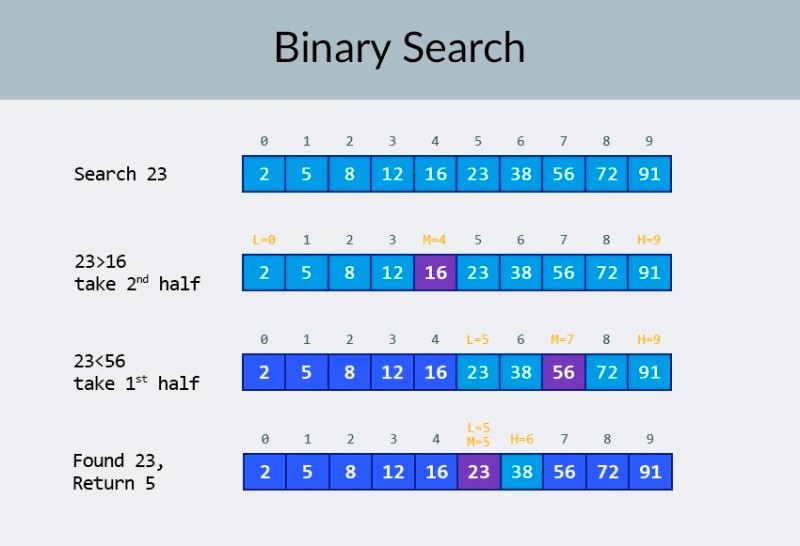 画像の一番上の行には、ソートされた配列が表示されます。この中から 23 という数字を見つける必要があります。数値を反復処理する代わりに、単純に配列を 2 つの部分に分割し、配列内の中央の数値をチェックします。セル 4 にある数字を見つけて確認します (画像の 2 行目)。この数は 16 で、私たちは 23 を探しています。現在の数は私たちが探している数よりも少ないです。どういう意味ですか?だということだ以前のすべての数値 (数値 16 より前にある数値) をチェックする必要はありません。配列はソートされているため、それらは探している数値よりも小さいことが保証されています。残りの 5 つの要素の間で検索を続けます。 ノート:比較は 1 回だけ実行しましたが、考えられる選択肢の半分はすでに除外されています。残っている要素は 5 つだけです。残りのサブ配列をもう一度半分に分割し、再び中央の要素 (画像の 3 行目) を取得することで、前のステップを繰り返します。その数は 56 で、探しているものよりも大きいです。どういう意味ですか?これは、さらに 3 つの可能性を排除したことを意味します。数値 56 自体とその後の 2 つの数値 (配列がソートされているため、これらの数値は 23 より大きいことが保証されているため)。チェックすべき数値は 2 つだけ残っています (画像の最後の行)、配列インデックス 5 と 6 の数値です。それらの最初の数値をチェックすると、探していた数値である 23 が見つかります。その指数は5です!アルゴリズムの結果を見てみましょう。その複雑さを分析します。ところで、これがなぜ二分探索と呼ばれるか理解できたでしょう。それはデータを繰り返し半分に分割することに依存しています。結果は素晴らしいものでした!線形検索を使用して数値を検索すると、最大 10 回の比較が必要になりますが、二分検索を使用すると、わずか 3 回の比較でタスクを完了できました。最悪の場合、4 つの比較が行われることになります (最後のステップで、必要な数値が残りの可能性の最初ではなく 2 番目だった場合。では、その複雑さはどうなのでしょうか? これは非常に興味深い点です :) 二分探索アルゴリズムは、線形探索アルゴリズム (つまり、単純な反復) よりも配列内の要素の数にあまり依存しません。配列内の要素が10 個 の場合、線形検索では最大 10 回の比較が必要ですが、二分検索では最大 4 回の比較が必要になります。それは2.5倍の差です。ただし、要素が 1000 個ある配列の場合、線形検索では最大 1000 回の比較が必要ですが、二分検索では10 回だけ必要になります。その差はなんと100倍! ノート:配列内の要素の数は 100 倍 (10 から 1000) に増加しましたが、二分探索に必要な比較の数は 2.5 倍 (4 から 10) しか増加しませんでした。要素が 10,000 個に達すると、その差はさらに顕著になります。線形検索では 10,000 回の比較が行われ、二分検索では合計 14 回の比較が行われます。また、要素の数が 1000 倍 (10 から 10000) に増加した場合、比較の数は 3.5 倍 (4 から 14) だけ増加します。 二分探索アルゴリズムの複雑さは対数、つまりビッグ O 表記を使用する場合はO(log n)です。。なぜそう呼ばれるのでしょうか?対数は累乗の逆のようなものです。2 進対数は、数値を得るために数値 2 を累乗する必要があります。たとえば、二分探索アルゴリズムを使用して検索する必要がある要素が 10,000 個あります。
画像の一番上の行には、ソートされた配列が表示されます。この中から 23 という数字を見つける必要があります。数値を反復処理する代わりに、単純に配列を 2 つの部分に分割し、配列内の中央の数値をチェックします。セル 4 にある数字を見つけて確認します (画像の 2 行目)。この数は 16 で、私たちは 23 を探しています。現在の数は私たちが探している数よりも少ないです。どういう意味ですか?だということだ以前のすべての数値 (数値 16 より前にある数値) をチェックする必要はありません。配列はソートされているため、それらは探している数値よりも小さいことが保証されています。残りの 5 つの要素の間で検索を続けます。 ノート:比較は 1 回だけ実行しましたが、考えられる選択肢の半分はすでに除外されています。残っている要素は 5 つだけです。残りのサブ配列をもう一度半分に分割し、再び中央の要素 (画像の 3 行目) を取得することで、前のステップを繰り返します。その数は 56 で、探しているものよりも大きいです。どういう意味ですか?これは、さらに 3 つの可能性を排除したことを意味します。数値 56 自体とその後の 2 つの数値 (配列がソートされているため、これらの数値は 23 より大きいことが保証されているため)。チェックすべき数値は 2 つだけ残っています (画像の最後の行)、配列インデックス 5 と 6 の数値です。それらの最初の数値をチェックすると、探していた数値である 23 が見つかります。その指数は5です!アルゴリズムの結果を見てみましょう。その複雑さを分析します。ところで、これがなぜ二分探索と呼ばれるか理解できたでしょう。それはデータを繰り返し半分に分割することに依存しています。結果は素晴らしいものでした!線形検索を使用して数値を検索すると、最大 10 回の比較が必要になりますが、二分検索を使用すると、わずか 3 回の比較でタスクを完了できました。最悪の場合、4 つの比較が行われることになります (最後のステップで、必要な数値が残りの可能性の最初ではなく 2 番目だった場合。では、その複雑さはどうなのでしょうか? これは非常に興味深い点です :) 二分探索アルゴリズムは、線形探索アルゴリズム (つまり、単純な反復) よりも配列内の要素の数にあまり依存しません。配列内の要素が10 個 の場合、線形検索では最大 10 回の比較が必要ですが、二分検索では最大 4 回の比較が必要になります。それは2.5倍の差です。ただし、要素が 1000 個ある配列の場合、線形検索では最大 1000 回の比較が必要ですが、二分検索では10 回だけ必要になります。その差はなんと100倍! ノート:配列内の要素の数は 100 倍 (10 から 1000) に増加しましたが、二分探索に必要な比較の数は 2.5 倍 (4 から 10) しか増加しませんでした。要素が 10,000 個に達すると、その差はさらに顕著になります。線形検索では 10,000 回の比較が行われ、二分検索では合計 14 回の比較が行われます。また、要素の数が 1000 倍 (10 から 10000) に増加した場合、比較の数は 3.5 倍 (4 から 14) だけ増加します。 二分探索アルゴリズムの複雑さは対数、つまりビッグ O 表記を使用する場合はO(log n)です。。なぜそう呼ばれるのでしょうか?対数は累乗の逆のようなものです。2 進対数は、数値を得るために数値 2 を累乗する必要があります。たとえば、二分探索アルゴリズムを使用して検索する必要がある要素が 10,000 個あります。 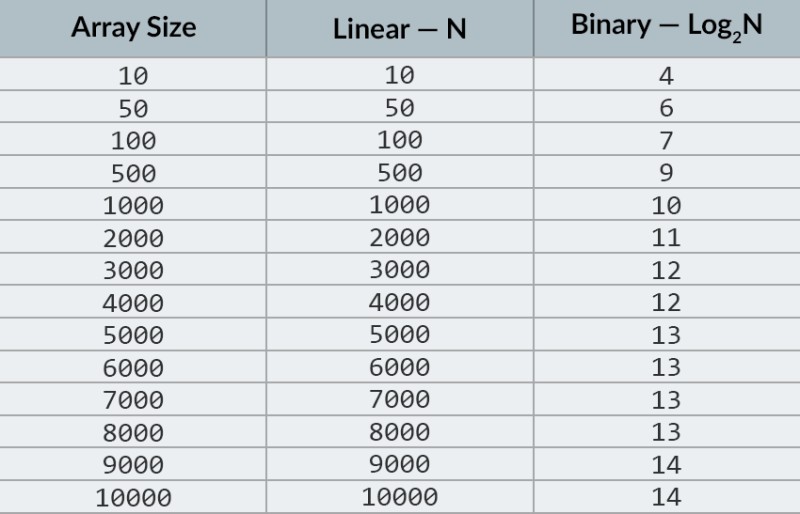 現時点では、値の表を見ると、これを行うには最大 14 回の比較が必要であることがわかります。しかし、誰もそのようなテーブルを提供しておらず、正確な最大比較数を計算する必要がある場合はどうすればよいでしょうか? 単純な質問に答えるだけで済みます。結果がチェックされる要素の数以上になるように、数値 2 を何乗する必要がありますか? 10,000 の場合、14 乗になります。2 の 13 乗 (8192) は小さすぎますが、2 の 14 乗 = 16384、この数は条件を満たします (配列内の要素の数以上です)。対数は 14 でした。必要な比較の数はこれだけです。:) アルゴリズムとアルゴリズムの複雑さは、1 つのレッスンに収めるには広すぎるトピックです。しかし、それを知っておくことは非常に重要です。多くの就職面接では、アルゴリズムに関する質問が行われます。理論については、いくつかの本をお勧めします。「Grokking アルゴリズム」から始めることができます。この本の例は Python で書かれていますが、非常に単純な言語と例が使用されています。初心者にとっては最良の選択肢であり、さらに、それほど大きくありません。より本格的な読書としては、ロバート ラフォアとロバート セジウィックの本があります。。どちらも Java で書かれているため、学習が少し簡単になります。結局のところ、あなたはこの言語にかなり精通しています。:) 優れた数学スキルを持つ学生にとって、最良の選択肢はThomas Cormen の本です。しかし、理論だけではお腹は満たされません。 知識!= 能力。HackerRankとLeetCodeのアルゴリズムに関連する問題を解く練習をすることができます。これらの Web サイトのタスクは、Google や Facebook での面接中にも頻繁に使用されるため、絶対に退屈することはありません :) このレッスンの内容を強化するために、 YouTube でBig O 記法に関するこの優れたビデオを視聴することをお勧めします。次のレッスンでお会いしましょう!:)
現時点では、値の表を見ると、これを行うには最大 14 回の比較が必要であることがわかります。しかし、誰もそのようなテーブルを提供しておらず、正確な最大比較数を計算する必要がある場合はどうすればよいでしょうか? 単純な質問に答えるだけで済みます。結果がチェックされる要素の数以上になるように、数値 2 を何乗する必要がありますか? 10,000 の場合、14 乗になります。2 の 13 乗 (8192) は小さすぎますが、2 の 14 乗 = 16384、この数は条件を満たします (配列内の要素の数以上です)。対数は 14 でした。必要な比較の数はこれだけです。:) アルゴリズムとアルゴリズムの複雑さは、1 つのレッスンに収めるには広すぎるトピックです。しかし、それを知っておくことは非常に重要です。多くの就職面接では、アルゴリズムに関する質問が行われます。理論については、いくつかの本をお勧めします。「Grokking アルゴリズム」から始めることができます。この本の例は Python で書かれていますが、非常に単純な言語と例が使用されています。初心者にとっては最良の選択肢であり、さらに、それほど大きくありません。より本格的な読書としては、ロバート ラフォアとロバート セジウィックの本があります。。どちらも Java で書かれているため、学習が少し簡単になります。結局のところ、あなたはこの言語にかなり精通しています。:) 優れた数学スキルを持つ学生にとって、最良の選択肢はThomas Cormen の本です。しかし、理論だけではお腹は満たされません。 知識!= 能力。HackerRankとLeetCodeのアルゴリズムに関連する問題を解く練習をすることができます。これらの Web サイトのタスクは、Google や Facebook での面接中にも頻繁に使用されるため、絶対に退屈することはありません :) このレッスンの内容を強化するために、 YouTube でBig O 記法に関するこの優れたビデオを視聴することをお勧めします。次のレッスンでお会いしましょう!:)
