CHÀO! Bài học hôm nay sẽ hơi khác so với các bài còn lại. Nó sẽ khác ở chỗ nó chỉ liên quan gián tiếp đến Java. Điều đó nói rằng, chủ đề này rất quan trọng đối với mọi lập trình viên. Chúng ta sẽ nói về các thuật toán . Thuật toán là gì? Nói một cách đơn giản, đó là một số chuỗi hành động phải được hoàn thành để đạt được kết quả mong muốn . Chúng tôi sử dụng các thuật toán thường xuyên trong cuộc sống hàng ngày. Ví dụ, mỗi sáng bạn có một nhiệm vụ cụ thể: đi học hoặc đi làm, đồng thời phải:
mặc quần áo
Lau dọn
đã nuôi
Thuật toán nào cho phép bạn đạt được kết quả này?
Thức dậy bằng đồng hồ báo thức.
Đi tắm và tắm rửa sạch sẽ.
Làm bữa sáng và một ít cà phê hoặc trà.
Ăn.
Nếu bạn không ủi quần áo vào buổi tối hôm trước, thì hãy ủi chúng.
Mặc quần áo.
Rời khỏi nhà.
Chuỗi hành động này chắc chắn sẽ cho phép bạn đạt được kết quả mong muốn. Trong lập trình, chúng tôi liên tục làm việc để hoàn thành nhiệm vụ. Một phần quan trọng của các tác vụ này có thể được thực hiện bằng các thuật toán đã biết. Ví dụ: giả sử nhiệm vụ của bạn là: sắp xếp danh sách 100 tên trong một mảng . Nhiệm vụ này khá đơn giản, nhưng nó có thể được giải quyết theo nhiều cách khác nhau. Đây là một giải pháp khả thi: Thuật toán sắp xếp tên theo thứ tự bảng chữ cái:
Mua hoặc tải xuống phiên bản 1961 của Từ điển quốc tế mới thứ ba của Webster.
Tìm mọi tên từ danh sách của chúng tôi trong từ điển này.
Trên một tờ giấy, viết trang từ điển có tên.
Sử dụng các mảnh giấy để sắp xếp tên.
Liệu một chuỗi các hành động như vậy có hoàn thành nhiệm vụ của chúng ta không? Vâng, nó chắc chắn sẽ. Giải pháp này có hiệu quả không ? Khắc nghiệt. Ở đây chúng ta đến với một khía cạnh rất quan trọng khác của thuật toán: hiệu quả của chúng . Có một số cách để hoàn thành nhiệm vụ này. Nhưng cả trong lập trình lẫn cuộc sống đời thường, chúng ta đều muốn chọn cách hiệu quả nhất. Nếu nhiệm vụ của bạn là làm một miếng bánh mì nướng phết bơ, bạn có thể bắt đầu bằng cách gieo lúa mì và vắt sữa bò. Nhưng đó sẽ là một cách không hiệu quảgiải pháp — sẽ mất rất nhiều thời gian và sẽ tốn rất nhiều tiền. Bạn có thể hoàn thành nhiệm vụ đơn giản của mình bằng cách mua bánh mì và bơ. Mặc dù nó cho phép bạn giải quyết vấn đề, nhưng thuật toán liên quan đến lúa mì và con bò quá phức tạp để sử dụng trong thực tế. Trong lập trình, chúng ta có ký hiệu đặc biệt gọi là ký hiệu O lớn để đánh giá độ phức tạp của thuật toán. Big O cho phép đánh giá thời gian thực hiện thuật toán phụ thuộc vào kích thước dữ liệu đầu vào . Hãy xem ví dụ đơn giản nhất: truyền dữ liệu. Hãy tưởng tượng rằng bạn cần gửi một số thông tin dưới dạng tệp qua một khoảng cách dài (ví dụ: 5000 dặm). Thuật toán nào sẽ hiệu quả nhất? Nó phụ thuộc vào dữ liệu bạn đang làm việc. Ví dụ: giả sử chúng tôi có tệp âm thanh có dung lượng 10 MB. Trong trường hợp này, thuật toán hiệu quả nhất là gửi tệp qua Internet. Nó không thể mất nhiều hơn một vài phút! Hãy trình bày lại thuật toán của chúng ta: "Nếu bạn muốn truyền thông tin dưới dạng các tệp trong khoảng cách 5000 dặm, bạn nên gửi dữ liệu qua Internet". Xuất sắc. Bây giờ chúng ta hãy phân tích nó. Nó có hoàn thành nhiệm vụ của chúng ta không?Vâng, vâng, nó làm. Nhưng chúng ta có thể nói gì về sự phức tạp của nó? Hmm, bây giờ mọi thứ đang trở nên thú vị hơn. Thực tế là thuật toán của chúng tôi phụ thuộc rất nhiều vào dữ liệu đầu vào, cụ thể là kích thước của tệp. Nếu chúng ta có 10 megabyte, thì mọi thứ đều ổn. Nhưng nếu chúng ta cần gửi 500 megabyte thì sao? 20 gigabyte? 500 terabyte? 30 petabyte? Thuật toán của chúng tôi sẽ ngừng hoạt động? Không, tất cả lượng dữ liệu này thực sự có thể được chuyển. Nó sẽ mất nhiều thời gian hơn? Nó sẽ được thôi! Bây giờ chúng ta đã biết một tính năng quan trọng trong thuật toán của mình: lượng dữ liệu cần gửi càng lớn thì thời gian chạy thuật toán càng lâu. Nhưng chúng tôi muốn hiểu chính xác hơn về mối quan hệ này (giữa kích thước dữ liệu đầu vào và thời gian cần thiết để gửi nó). Trong trường hợp của chúng tôi, độ phức tạp của thuật toán là tuyến tính . "Tuyến tính" có nghĩa là khi lượng dữ liệu đầu vào tăng lên, thời gian cần thiết để gửi dữ liệu đó sẽ tăng theo tỷ lệ thuận. Nếu lượng dữ liệu tăng gấp đôi, thì thời gian cần thiết để gửi nó sẽ gấp đôi. Nếu dữ liệu tăng 10 lần thì thời gian truyền sẽ tăng 10 lần. Sử dụng ký hiệu O lớn, độ phức tạp của thuật toán của chúng tôi được biểu thị bằng O(n). Bạn nên ghi nhớ ký hiệu này cho tương lai — nó luôn được sử dụng cho các thuật toán có độ phức tạp tuyến tính. Lưu ý rằng chúng tôi không nói về một số thứ có thể thay đổi ở đây: tốc độ Internet, sức mạnh tính toán của máy tính, v.v. Khi đánh giá mức độ phức tạp của một thuật toán, việc xem xét các yếu tố này đơn giản là không hợp lý — trong mọi trường hợp, chúng nằm ngoài tầm kiểm soát của chúng tôi. Ký hiệu Big O thể hiện độ phức tạp của chính thuật toán chứ không phải "môi trường" mà nó chạy trong đó. Hãy tiếp tục với ví dụ của chúng tôi. Giả sử rằng cuối cùng chúng tôi biết rằng chúng tôi cần gửi các tệp có tổng dung lượng 800 terabyte. Tất nhiên, chúng ta có thể hoàn thành nhiệm vụ của mình bằng cách gửi chúng qua Internet. Chỉ có một vấn đề: ở tốc độ truyền dữ liệu hộ gia đình tiêu chuẩn (100 megabit/giây), sẽ mất khoảng 708 ngày. Gần 2 năm! :O Thuật toán của chúng tôi rõ ràng là không phù hợp ở đây. Chúng ta cần một số giải pháp khác! Thật bất ngờ, gã khổng lồ CNTT Amazon đến giải cứu chúng ta! Dịch vụ Xe trượt tuyết của Amazon cho phép chúng tôi tải một lượng lớn dữ liệu lên bộ lưu trữ di động và sau đó vận chuyển đến địa chỉ mong muốn bằng xe tải! Vì vậy, chúng tôi có một thuật toán mới! "Nếu bạn muốn chuyển thông tin dưới dạng các tập tin qua khoảng cách 5000 dặm và làm như vậy sẽ mất hơn 14 ngày để gửi qua Internet, bạn nên gửi dữ liệu trên một chiếc xe tải của Amazon." Chúng tôi đã chọn 14 ngày tùy ý ở đây. Giả sử đây là khoảng thời gian dài nhất mà chúng ta có thể chờ đợi. Hãy phân tích thuật toán của chúng tôi. Còn tốc độ của nó thì sao? Ngay cả khi chiếc xe tải chỉ di chuyển với tốc độ 50 dặm/giờ, nó sẽ đi được 5000 dặm chỉ trong 100 giờ. Đây là hơn bốn ngày một chút! Điều này tốt hơn nhiều so với tùy chọn gửi dữ liệu qua Internet. Và những gì về sự phức tạp của thuật toán này? Nó cũng tuyến tính, tức là O(n)? Không có nó không phải là. Xét cho cùng, chiếc xe tải không quan tâm đến việc bạn chở nó nặng đến mức nào — nó vẫn sẽ chạy với tốc độ như cũ và đến đúng giờ. Cho dù chúng ta có 800 terabyte hay gấp 10 lần, chiếc xe tải vẫn sẽ đến đích trong vòng 5 ngày. Nói cách khác, thuật toán truyền dữ liệu dựa trên xe tải có độ phức tạp không đổi. Ở đây, "hằng số" có nghĩa là nó không phụ thuộc vào kích thước dữ liệu đầu vào. Đặt ổ đĩa flash 1GB vào xe tải, nó sẽ đến trong vòng 5 ngày. Đặt vào đĩa chứa 800 terabyte dữ liệu, nó sẽ đến trong vòng 5 ngày. Khi sử dụng ký hiệu O lớn, độ phức tạp không đổi được ký hiệu là O(1) . Chúng ta đã trở nên quen thuộc với O(n) và O(1) , vì vậy bây giờ hãy xem thêm các ví dụ khác trong thế giới lập trình :) Giả sử bạn được cung cấp một mảng gồm 100 số và nhiệm vụ là hiển thị từng số đó trên Bàn điều khiển. Bạn viết một forvòng lặp thông thường thực hiện nhiệm vụ này
int[] numbers =newint[100];// ...fill the array with numbersfor(int i: numbers){System.out.println(i);}
Độ phức tạp của thuật toán này là gì? Tuyến tính, tức là O(n). Số lượng hành động mà chương trình phải thực hiện phụ thuộc vào số lượng số được truyền cho nó. Nếu trong mảng có 100 số thì sẽ có 100 hành động (câu lệnh để hiển thị chuỗi trên màn hình). Nếu có 10.000 số trong mảng thì phải thực hiện 10.000 thao tác. Thuật toán của chúng tôi có thể được cải thiện theo bất kỳ cách nào không? Không. Dù thế nào đi chăng nữa, chúng ta sẽ phải thực hiện N lượt đi qua mảng và thực hiện N câu lệnh để hiển thị các chuỗi trên bàn điều khiển. Hãy xem xét một ví dụ khác.
Chúng tôi có một khoảng trống LinkedListđể chèn một số số. Chúng ta cần đánh giá độ phức tạp của thuật toán khi chèn một số vào LinkedListví dụ của chúng ta và mức độ phụ thuộc của nó vào số lượng phần tử trong danh sách. Câu trả lời là O(1), tức là độ phức tạp không đổi . Tại sao? Lưu ý rằng chúng tôi chèn từng số vào đầu danh sách. Ngoài ra, bạn sẽ nhớ lại rằng khi bạn chèn một số vào một LinkedList, các phần tử không di chuyển đi đâu cả. Các liên kết (hoặc tài liệu tham khảo) được cập nhật (nếu bạn quên cách LinkedList hoạt động, hãy xem một trong những bài học cũ của chúng tôi ). Nếu số đầu tiên trong danh sách của chúng ta là x, và chúng ta chèn số y vào đầu danh sách, thì tất cả những gì chúng ta cần làm là:
x.previous = y;
y.previous =null;
y.next = x;
Khi chúng tôi cập nhật các liên kết, chúng tôi không quan tâm có bao nhiêu số đã có trongLinkedList , dù là một hay một tỷ. Độ phức tạp của thuật toán là hằng số, tức là O(1).
độ phức tạp logarit
Không hoảng loạn! :) Nếu từ "logarit" khiến bạn muốn đóng bài học này lại và ngừng đọc, hãy đợi vài phút. Sẽ không có bất kỳ phép toán điên rồ nào ở đây (có rất nhiều cách giải thích tương tự ở nơi khác), và chúng tôi sẽ chọn ra từng ví dụ. Hãy tưởng tượng rằng nhiệm vụ của bạn là tìm một số cụ thể trong một dãy 100 số. Chính xác hơn, bạn cần kiểm tra xem nó có ở đó hay không. Ngay sau khi tìm thấy số cần thiết, quá trình tìm kiếm kết thúc và bạn hiển thị thông tin sau trong bảng điều khiển: "Đã tìm thấy số cần thiết! Chỉ mục của nó trong mảng = ...." Bạn sẽ hoàn thành nhiệm vụ này như thế nào? Ở đây, giải pháp rất rõ ràng: bạn cần lặp lại từng phần tử của mảng, bắt đầu từ phần tử đầu tiên (hoặc từ phần tử cuối cùng) và kiểm tra xem số hiện tại có khớp với số bạn đang tìm hay không. Theo đó, số lượng hành động trực tiếp phụ thuộc vào số lượng phần tử trong mảng. Nếu chúng ta có 100 số, thì chúng ta có khả năng cần phải chuyển đến phần tử tiếp theo 100 lần và thực hiện 100 phép so sánh. Nếu có 1000 số thì có thể có 1000 phép so sánh. Đây rõ ràng là độ phức tạp tuyến tính, tức làO(n) . Và bây giờ chúng ta sẽ thêm một sàng lọc vào ví dụ của mình: mảng nơi bạn cần tìm số được sắp xếp theo thứ tự tăng dần . Điều này có thay đổi bất cứ điều gì liên quan đến nhiệm vụ của chúng tôi không? Chúng tôi vẫn có thể thực hiện tìm kiếm thô bạo cho số mong muốn. Nhưng cách khác, chúng ta có thể sử dụng thuật toán tìm kiếm nhị phân nổi tiếng . Ở hàng trên cùng của hình ảnh, chúng ta thấy một mảng được sắp xếp. Chúng ta cần tìm số 23 trong đó. Thay vì lặp lại các số, chúng ta chỉ cần chia mảng thành 2 phần và kiểm tra số ở giữa trong mảng. Tìm số nằm trong ô 4 và kiểm tra nó (hàng thứ hai trong hình). Con số này là 16 và chúng tôi đang tìm kiếm 23. Con số hiện tại ít hơn số mà chúng tôi đang tìm kiếm. Điều đó nghĩa là gì? Nó có nghĩa làtất cả các số trước đó (những số nằm trước số 16) không cần phải kiểm tra : chúng được đảm bảo nhỏ hơn số chúng tôi đang tìm kiếm, vì mảng của chúng tôi đã được sắp xếp! Chúng tôi tiếp tục tìm kiếm trong số 5 yếu tố còn lại. Ghi chú:chúng tôi chỉ thực hiện một so sánh, nhưng chúng tôi đã loại bỏ một nửa số tùy chọn có thể. Chúng ta chỉ còn lại 5 yếu tố. Chúng tôi sẽ lặp lại bước trước đó bằng cách một lần nữa chia mảng con còn lại thành một nửa và một lần nữa lấy phần tử ở giữa (hàng thứ 3 trong hình ảnh). Con số này là 56, và nó lớn hơn số chúng ta đang tìm. Điều đó nghĩa là gì? Điều đó có nghĩa là chúng ta đã loại bỏ 3 khả năng khác: chính số 56 cũng như hai số sau nó (vì chúng được đảm bảo lớn hơn 23, vì mảng đã được sắp xếp). Chúng tôi chỉ còn 2 số để kiểm tra (hàng cuối cùng trong hình ảnh) — các số có chỉ số mảng 5 và 6. Chúng tôi kiểm tra số đầu tiên và tìm thấy thứ chúng tôi đang tìm kiếm — số 23! Chỉ số của nó là 5! Hãy xem kết quả của thuật toán của chúng tôi, và sau đó chúng tôi' sẽ phân tích sự phức tạp của nó. Nhân tiện, bây giờ bạn đã hiểu tại sao điều này được gọi là tìm kiếm nhị phân: nó dựa vào việc chia đôi dữ liệu nhiều lần. Kết quả thật ấn tượng! Nếu chúng tôi sử dụng tìm kiếm tuyến tính để tìm số, chúng tôi sẽ cần tới 10 phép so sánh, nhưng với tìm kiếm nhị phân, chúng tôi đã hoàn thành nhiệm vụ chỉ với 3! Trong trường hợp xấu nhất, sẽ có 4 phép so sánh (nếu ở bước cuối cùng, số chúng ta muốn là khả năng thứ hai trong số các khả năng còn lại, chứ không phải là khả năng đầu tiên. Vậy còn độ phức tạp của nó thì sao? Đây là một điểm rất thú vị :) Thuật toán tìm kiếm nhị phân ít phụ thuộc vào số phần tử trong mảng hơn nhiều so với thuật toán tìm kiếm tuyến tính (nghĩa là phép lặp đơn giản). Với 10 phần tử trong mảng, tìm kiếm tuyến tính sẽ cần tối đa 10 phép so sánh, nhưng tìm kiếm nhị phân sẽ cần tối đa 4 phép so sánh. Đó là một sự khác biệt theo hệ số 2,5. Nhưng đối với một mảng gồm 1000 phần tử , tìm kiếm tuyến tính sẽ cần tới 1000 phép so sánh, nhưng tìm kiếm nhị phân sẽ chỉ cần 10 phép so sánh ! Sự khác biệt bây giờ là 100 lần! Ghi chú:số lượng phần tử trong mảng đã tăng 100 lần (từ 10 lên 1000), nhưng số phép so sánh cần thiết cho tìm kiếm nhị phân chỉ tăng theo hệ số 2,5 (từ 4 lên 10). Nếu chúng ta có tới 10.000 phần tử , sự khác biệt sẽ còn ấn tượng hơn: 10.000 phép so sánh cho tìm kiếm tuyến tính và tổng cộng 14 phép so sánh cho tìm kiếm nhị phân. Và một lần nữa, nếu số phần tử tăng 1000 lần (từ 10 lên 10000), thì số phép so sánh chỉ tăng theo hệ số 3,5 (từ 4 lên 14). Độ phức tạp của thuật toán tìm kiếm nhị phân là logarit hoặc, nếu chúng ta sử dụng ký hiệu O lớn, O(log n). Tại sao nó được gọi như vậy? Logarit giống như đối lập với lũy thừa. Logarit nhị phân là lũy thừa mà số 2 phải tăng lên để có được một số. Ví dụ: chúng tôi có 10.000 phần tử cần tìm kiếm bằng thuật toán tìm kiếm nhị phân. Hiện tại, bạn có thể nhìn vào bảng giá trị để biết rằng làm điều này sẽ yêu cầu tối đa 14 phép so sánh. Nhưng điều gì sẽ xảy ra nếu không ai cung cấp một bảng như vậy và bạn cần tính toán chính xác số lần so sánh tối đa? Bạn chỉ cần trả lời một câu hỏi đơn giản: bạn cần nâng số 2 lên lũy thừa nào để kết quả lớn hơn hoặc bằng số phần tử cần kiểm tra? Đối với 10.000, nó là sức mạnh thứ 14. 2 mũ 13 quá nhỏ (8192), nhưng 2 mũ 14 = 16384, và con số này thỏa mãn điều kiện của chúng ta (nó lớn hơn hoặc bằng số phần tử trong mảng). Chúng tôi đã tìm thấy logarit: 14. Đó là số phép so sánh mà chúng tôi có thể cần! :) Các thuật toán và độ phức tạp của thuật toán là một chủ đề quá rộng để phù hợp với một bài học. Nhưng biết điều đó là rất quan trọng: nhiều cuộc phỏng vấn việc làm sẽ liên quan đến các câu hỏi liên quan đến thuật toán. Đối với lý thuyết, tôi có thể giới thiệu một số cuốn sách cho bạn. Bạn có thể bắt đầu với " Grokking Algorithms ". Các ví dụ trong cuốn sách này được viết bằng Python, nhưng cuốn sách sử dụng ngôn ngữ và các ví dụ rất đơn giản. Đó là lựa chọn tốt nhất cho người mới bắt đầu và hơn nữa, nó không lớn lắm. Trong số những cách đọc nghiêm túc hơn, chúng tôi có sách của Robert Lafore và Robert Sedgewick. Cả hai đều được viết bằng Java, điều này sẽ giúp bạn học dễ dàng hơn một chút. Rốt cuộc, bạn đã khá quen thuộc với ngôn ngữ này! :) Đối với học sinh giỏi toán thì lựa chọn tốt nhất là sách của Thomas Cormen . Nhưng lý thuyết một mình sẽ không lấp đầy bụng của bạn! Kiến thức != Khả năng . Bạn có thể thực hành giải các bài toán liên quan đến thuật toán trên HackerRank và LeetCode . Các nhiệm vụ từ các trang web này thường được sử dụng ngay cả trong các cuộc phỏng vấn tại Google và Facebook, vì vậy bạn chắc chắn sẽ không cảm thấy nhàm chán :) Để củng cố tài liệu bài học này, tôi khuyên bạn nên xem video tuyệt vời này về ký hiệu O lớn trên YouTube. Hẹn gặp lại các bạn trong các bài học tiếp theo! :)
Artem is a programmer-switcher. His first profession was rehabilitation specialist. Previously, he helped people restore their hea ... [Đọc toàn bộ tiểu sử]
 Điều đó nói rằng, chủ đề này rất quan trọng đối với mọi lập trình viên. Chúng ta sẽ nói về các thuật toán . Thuật toán là gì? Nói một cách đơn giản, đó là một số chuỗi hành động phải được hoàn thành để đạt được kết quả mong muốn . Chúng tôi sử dụng các thuật toán thường xuyên trong cuộc sống hàng ngày. Ví dụ, mỗi sáng bạn có một nhiệm vụ cụ thể: đi học hoặc đi làm, đồng thời phải:
Điều đó nói rằng, chủ đề này rất quan trọng đối với mọi lập trình viên. Chúng ta sẽ nói về các thuật toán . Thuật toán là gì? Nói một cách đơn giản, đó là một số chuỗi hành động phải được hoàn thành để đạt được kết quả mong muốn . Chúng tôi sử dụng các thuật toán thường xuyên trong cuộc sống hàng ngày. Ví dụ, mỗi sáng bạn có một nhiệm vụ cụ thể: đi học hoặc đi làm, đồng thời phải:
 Trong trường hợp này, thuật toán hiệu quả nhất là gửi tệp qua Internet. Nó không thể mất nhiều hơn một vài phút! Hãy trình bày lại thuật toán của chúng ta: "Nếu bạn muốn truyền thông tin dưới dạng các tệp trong khoảng cách 5000 dặm, bạn nên gửi dữ liệu qua Internet". Xuất sắc. Bây giờ chúng ta hãy phân tích nó. Nó có hoàn thành nhiệm vụ của chúng ta không?Vâng, vâng, nó làm. Nhưng chúng ta có thể nói gì về sự phức tạp của nó? Hmm, bây giờ mọi thứ đang trở nên thú vị hơn. Thực tế là thuật toán của chúng tôi phụ thuộc rất nhiều vào dữ liệu đầu vào, cụ thể là kích thước của tệp. Nếu chúng ta có 10 megabyte, thì mọi thứ đều ổn. Nhưng nếu chúng ta cần gửi 500 megabyte thì sao? 20 gigabyte? 500 terabyte? 30 petabyte? Thuật toán của chúng tôi sẽ ngừng hoạt động? Không, tất cả lượng dữ liệu này thực sự có thể được chuyển. Nó sẽ mất nhiều thời gian hơn? Nó sẽ được thôi! Bây giờ chúng ta đã biết một tính năng quan trọng trong thuật toán của mình: lượng dữ liệu cần gửi càng lớn thì thời gian chạy thuật toán càng lâu. Nhưng chúng tôi muốn hiểu chính xác hơn về mối quan hệ này (giữa kích thước dữ liệu đầu vào và thời gian cần thiết để gửi nó). Trong trường hợp của chúng tôi, độ phức tạp của thuật toán là tuyến tính . "Tuyến tính" có nghĩa là khi lượng dữ liệu đầu vào tăng lên, thời gian cần thiết để gửi dữ liệu đó sẽ tăng theo tỷ lệ thuận. Nếu lượng dữ liệu tăng gấp đôi, thì thời gian cần thiết để gửi nó sẽ gấp đôi. Nếu dữ liệu tăng 10 lần thì thời gian truyền sẽ tăng 10 lần. Sử dụng ký hiệu O lớn, độ phức tạp của thuật toán của chúng tôi được biểu thị bằng O(n). Bạn nên ghi nhớ ký hiệu này cho tương lai — nó luôn được sử dụng cho các thuật toán có độ phức tạp tuyến tính. Lưu ý rằng chúng tôi không nói về một số thứ có thể thay đổi ở đây: tốc độ Internet, sức mạnh tính toán của máy tính, v.v. Khi đánh giá mức độ phức tạp của một thuật toán, việc xem xét các yếu tố này đơn giản là không hợp lý — trong mọi trường hợp, chúng nằm ngoài tầm kiểm soát của chúng tôi. Ký hiệu Big O thể hiện độ phức tạp của chính thuật toán chứ không phải "môi trường" mà nó chạy trong đó. Hãy tiếp tục với ví dụ của chúng tôi. Giả sử rằng cuối cùng chúng tôi biết rằng chúng tôi cần gửi các tệp có tổng dung lượng 800 terabyte. Tất nhiên, chúng ta có thể hoàn thành nhiệm vụ của mình bằng cách gửi chúng qua Internet. Chỉ có một vấn đề: ở tốc độ truyền dữ liệu hộ gia đình tiêu chuẩn (100 megabit/giây), sẽ mất khoảng 708 ngày. Gần 2 năm! :O Thuật toán của chúng tôi rõ ràng là không phù hợp ở đây. Chúng ta cần một số giải pháp khác! Thật bất ngờ, gã khổng lồ CNTT Amazon đến giải cứu chúng ta! Dịch vụ Xe trượt tuyết của Amazon cho phép chúng tôi tải một lượng lớn dữ liệu lên bộ lưu trữ di động và sau đó vận chuyển đến địa chỉ mong muốn bằng xe tải!
Trong trường hợp này, thuật toán hiệu quả nhất là gửi tệp qua Internet. Nó không thể mất nhiều hơn một vài phút! Hãy trình bày lại thuật toán của chúng ta: "Nếu bạn muốn truyền thông tin dưới dạng các tệp trong khoảng cách 5000 dặm, bạn nên gửi dữ liệu qua Internet". Xuất sắc. Bây giờ chúng ta hãy phân tích nó. Nó có hoàn thành nhiệm vụ của chúng ta không?Vâng, vâng, nó làm. Nhưng chúng ta có thể nói gì về sự phức tạp của nó? Hmm, bây giờ mọi thứ đang trở nên thú vị hơn. Thực tế là thuật toán của chúng tôi phụ thuộc rất nhiều vào dữ liệu đầu vào, cụ thể là kích thước của tệp. Nếu chúng ta có 10 megabyte, thì mọi thứ đều ổn. Nhưng nếu chúng ta cần gửi 500 megabyte thì sao? 20 gigabyte? 500 terabyte? 30 petabyte? Thuật toán của chúng tôi sẽ ngừng hoạt động? Không, tất cả lượng dữ liệu này thực sự có thể được chuyển. Nó sẽ mất nhiều thời gian hơn? Nó sẽ được thôi! Bây giờ chúng ta đã biết một tính năng quan trọng trong thuật toán của mình: lượng dữ liệu cần gửi càng lớn thì thời gian chạy thuật toán càng lâu. Nhưng chúng tôi muốn hiểu chính xác hơn về mối quan hệ này (giữa kích thước dữ liệu đầu vào và thời gian cần thiết để gửi nó). Trong trường hợp của chúng tôi, độ phức tạp của thuật toán là tuyến tính . "Tuyến tính" có nghĩa là khi lượng dữ liệu đầu vào tăng lên, thời gian cần thiết để gửi dữ liệu đó sẽ tăng theo tỷ lệ thuận. Nếu lượng dữ liệu tăng gấp đôi, thì thời gian cần thiết để gửi nó sẽ gấp đôi. Nếu dữ liệu tăng 10 lần thì thời gian truyền sẽ tăng 10 lần. Sử dụng ký hiệu O lớn, độ phức tạp của thuật toán của chúng tôi được biểu thị bằng O(n). Bạn nên ghi nhớ ký hiệu này cho tương lai — nó luôn được sử dụng cho các thuật toán có độ phức tạp tuyến tính. Lưu ý rằng chúng tôi không nói về một số thứ có thể thay đổi ở đây: tốc độ Internet, sức mạnh tính toán của máy tính, v.v. Khi đánh giá mức độ phức tạp của một thuật toán, việc xem xét các yếu tố này đơn giản là không hợp lý — trong mọi trường hợp, chúng nằm ngoài tầm kiểm soát của chúng tôi. Ký hiệu Big O thể hiện độ phức tạp của chính thuật toán chứ không phải "môi trường" mà nó chạy trong đó. Hãy tiếp tục với ví dụ của chúng tôi. Giả sử rằng cuối cùng chúng tôi biết rằng chúng tôi cần gửi các tệp có tổng dung lượng 800 terabyte. Tất nhiên, chúng ta có thể hoàn thành nhiệm vụ của mình bằng cách gửi chúng qua Internet. Chỉ có một vấn đề: ở tốc độ truyền dữ liệu hộ gia đình tiêu chuẩn (100 megabit/giây), sẽ mất khoảng 708 ngày. Gần 2 năm! :O Thuật toán của chúng tôi rõ ràng là không phù hợp ở đây. Chúng ta cần một số giải pháp khác! Thật bất ngờ, gã khổng lồ CNTT Amazon đến giải cứu chúng ta! Dịch vụ Xe trượt tuyết của Amazon cho phép chúng tôi tải một lượng lớn dữ liệu lên bộ lưu trữ di động và sau đó vận chuyển đến địa chỉ mong muốn bằng xe tải!  Vì vậy, chúng tôi có một thuật toán mới! "Nếu bạn muốn chuyển thông tin dưới dạng các tập tin qua khoảng cách 5000 dặm và làm như vậy sẽ mất hơn 14 ngày để gửi qua Internet, bạn nên gửi dữ liệu trên một chiếc xe tải của Amazon." Chúng tôi đã chọn 14 ngày tùy ý ở đây. Giả sử đây là khoảng thời gian dài nhất mà chúng ta có thể chờ đợi. Hãy phân tích thuật toán của chúng tôi. Còn tốc độ của nó thì sao? Ngay cả khi chiếc xe tải chỉ di chuyển với tốc độ 50 dặm/giờ, nó sẽ đi được 5000 dặm chỉ trong 100 giờ. Đây là hơn bốn ngày một chút! Điều này tốt hơn nhiều so với tùy chọn gửi dữ liệu qua Internet. Và những gì về sự phức tạp của thuật toán này? Nó cũng tuyến tính, tức là O(n)? Không có nó không phải là. Xét cho cùng, chiếc xe tải không quan tâm đến việc bạn chở nó nặng đến mức nào — nó vẫn sẽ chạy với tốc độ như cũ và đến đúng giờ. Cho dù chúng ta có 800 terabyte hay gấp 10 lần, chiếc xe tải vẫn sẽ đến đích trong vòng 5 ngày. Nói cách khác, thuật toán truyền dữ liệu dựa trên xe tải có độ phức tạp không đổi. Ở đây, "hằng số" có nghĩa là nó không phụ thuộc vào kích thước dữ liệu đầu vào. Đặt ổ đĩa flash 1GB vào xe tải, nó sẽ đến trong vòng 5 ngày. Đặt vào đĩa chứa 800 terabyte dữ liệu, nó sẽ đến trong vòng 5 ngày. Khi sử dụng ký hiệu O lớn, độ phức tạp không đổi được ký hiệu là O(1) . Chúng ta đã trở nên quen thuộc với O(n) và O(1) , vì vậy bây giờ hãy xem thêm các ví dụ khác trong thế giới lập trình :) Giả sử bạn được cung cấp một mảng gồm 100 số và nhiệm vụ là hiển thị từng số đó trên Bàn điều khiển. Bạn viết một
Vì vậy, chúng tôi có một thuật toán mới! "Nếu bạn muốn chuyển thông tin dưới dạng các tập tin qua khoảng cách 5000 dặm và làm như vậy sẽ mất hơn 14 ngày để gửi qua Internet, bạn nên gửi dữ liệu trên một chiếc xe tải của Amazon." Chúng tôi đã chọn 14 ngày tùy ý ở đây. Giả sử đây là khoảng thời gian dài nhất mà chúng ta có thể chờ đợi. Hãy phân tích thuật toán của chúng tôi. Còn tốc độ của nó thì sao? Ngay cả khi chiếc xe tải chỉ di chuyển với tốc độ 50 dặm/giờ, nó sẽ đi được 5000 dặm chỉ trong 100 giờ. Đây là hơn bốn ngày một chút! Điều này tốt hơn nhiều so với tùy chọn gửi dữ liệu qua Internet. Và những gì về sự phức tạp của thuật toán này? Nó cũng tuyến tính, tức là O(n)? Không có nó không phải là. Xét cho cùng, chiếc xe tải không quan tâm đến việc bạn chở nó nặng đến mức nào — nó vẫn sẽ chạy với tốc độ như cũ và đến đúng giờ. Cho dù chúng ta có 800 terabyte hay gấp 10 lần, chiếc xe tải vẫn sẽ đến đích trong vòng 5 ngày. Nói cách khác, thuật toán truyền dữ liệu dựa trên xe tải có độ phức tạp không đổi. Ở đây, "hằng số" có nghĩa là nó không phụ thuộc vào kích thước dữ liệu đầu vào. Đặt ổ đĩa flash 1GB vào xe tải, nó sẽ đến trong vòng 5 ngày. Đặt vào đĩa chứa 800 terabyte dữ liệu, nó sẽ đến trong vòng 5 ngày. Khi sử dụng ký hiệu O lớn, độ phức tạp không đổi được ký hiệu là O(1) . Chúng ta đã trở nên quen thuộc với O(n) và O(1) , vì vậy bây giờ hãy xem thêm các ví dụ khác trong thế giới lập trình :) Giả sử bạn được cung cấp một mảng gồm 100 số và nhiệm vụ là hiển thị từng số đó trên Bàn điều khiển. Bạn viết một 
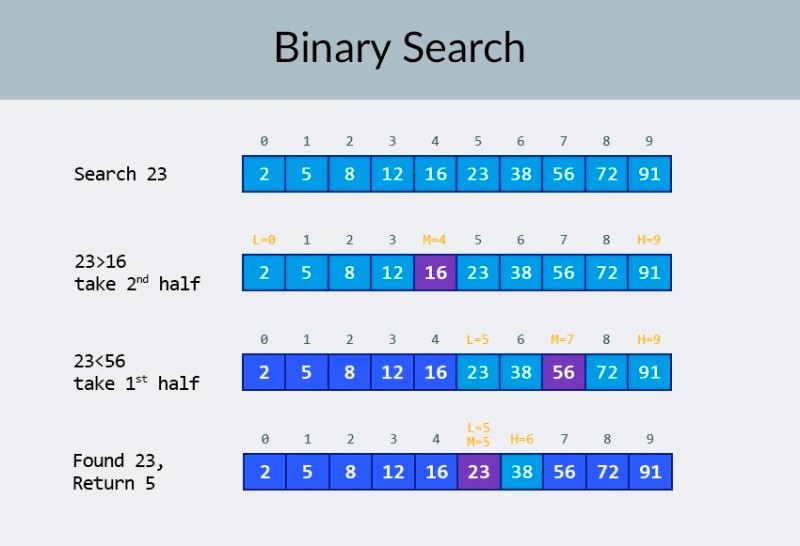 Ở hàng trên cùng của hình ảnh, chúng ta thấy một mảng được sắp xếp. Chúng ta cần tìm số 23 trong đó. Thay vì lặp lại các số, chúng ta chỉ cần chia mảng thành 2 phần và kiểm tra số ở giữa trong mảng. Tìm số nằm trong ô 4 và kiểm tra nó (hàng thứ hai trong hình). Con số này là 16 và chúng tôi đang tìm kiếm 23. Con số hiện tại ít hơn số mà chúng tôi đang tìm kiếm. Điều đó nghĩa là gì? Nó có nghĩa làtất cả các số trước đó (những số nằm trước số 16) không cần phải kiểm tra : chúng được đảm bảo nhỏ hơn số chúng tôi đang tìm kiếm, vì mảng của chúng tôi đã được sắp xếp! Chúng tôi tiếp tục tìm kiếm trong số 5 yếu tố còn lại. Ghi chú:chúng tôi chỉ thực hiện một so sánh, nhưng chúng tôi đã loại bỏ một nửa số tùy chọn có thể. Chúng ta chỉ còn lại 5 yếu tố. Chúng tôi sẽ lặp lại bước trước đó bằng cách một lần nữa chia mảng con còn lại thành một nửa và một lần nữa lấy phần tử ở giữa (hàng thứ 3 trong hình ảnh). Con số này là 56, và nó lớn hơn số chúng ta đang tìm. Điều đó nghĩa là gì? Điều đó có nghĩa là chúng ta đã loại bỏ 3 khả năng khác: chính số 56 cũng như hai số sau nó (vì chúng được đảm bảo lớn hơn 23, vì mảng đã được sắp xếp). Chúng tôi chỉ còn 2 số để kiểm tra (hàng cuối cùng trong hình ảnh) — các số có chỉ số mảng 5 và 6. Chúng tôi kiểm tra số đầu tiên và tìm thấy thứ chúng tôi đang tìm kiếm — số 23! Chỉ số của nó là 5! Hãy xem kết quả của thuật toán của chúng tôi, và sau đó chúng tôi' sẽ phân tích sự phức tạp của nó. Nhân tiện, bây giờ bạn đã hiểu tại sao điều này được gọi là tìm kiếm nhị phân: nó dựa vào việc chia đôi dữ liệu nhiều lần. Kết quả thật ấn tượng! Nếu chúng tôi sử dụng tìm kiếm tuyến tính để tìm số, chúng tôi sẽ cần tới 10 phép so sánh, nhưng với tìm kiếm nhị phân, chúng tôi đã hoàn thành nhiệm vụ chỉ với 3! Trong trường hợp xấu nhất, sẽ có 4 phép so sánh (nếu ở bước cuối cùng, số chúng ta muốn là khả năng thứ hai trong số các khả năng còn lại, chứ không phải là khả năng đầu tiên. Vậy còn độ phức tạp của nó thì sao? Đây là một điểm rất thú vị :) Thuật toán tìm kiếm nhị phân ít phụ thuộc vào số phần tử trong mảng hơn nhiều so với thuật toán tìm kiếm tuyến tính (nghĩa là phép lặp đơn giản). Với 10 phần tử trong mảng, tìm kiếm tuyến tính sẽ cần tối đa 10 phép so sánh, nhưng tìm kiếm nhị phân sẽ cần tối đa 4 phép so sánh. Đó là một sự khác biệt theo hệ số 2,5. Nhưng đối với một mảng gồm 1000 phần tử , tìm kiếm tuyến tính sẽ cần tới 1000 phép so sánh, nhưng tìm kiếm nhị phân sẽ chỉ cần 10 phép so sánh ! Sự khác biệt bây giờ là 100 lần! Ghi chú:số lượng phần tử trong mảng đã tăng 100 lần (từ 10 lên 1000), nhưng số phép so sánh cần thiết cho tìm kiếm nhị phân chỉ tăng theo hệ số 2,5 (từ 4 lên 10). Nếu chúng ta có tới 10.000 phần tử , sự khác biệt sẽ còn ấn tượng hơn: 10.000 phép so sánh cho tìm kiếm tuyến tính và tổng cộng 14 phép so sánh cho tìm kiếm nhị phân. Và một lần nữa, nếu số phần tử tăng 1000 lần (từ 10 lên 10000), thì số phép so sánh chỉ tăng theo hệ số 3,5 (từ 4 lên 14). Độ phức tạp của thuật toán tìm kiếm nhị phân là logarit hoặc, nếu chúng ta sử dụng ký hiệu O lớn, O(log n). Tại sao nó được gọi như vậy? Logarit giống như đối lập với lũy thừa. Logarit nhị phân là lũy thừa mà số 2 phải tăng lên để có được một số. Ví dụ: chúng tôi có 10.000 phần tử cần tìm kiếm bằng thuật toán tìm kiếm nhị phân.
Ở hàng trên cùng của hình ảnh, chúng ta thấy một mảng được sắp xếp. Chúng ta cần tìm số 23 trong đó. Thay vì lặp lại các số, chúng ta chỉ cần chia mảng thành 2 phần và kiểm tra số ở giữa trong mảng. Tìm số nằm trong ô 4 và kiểm tra nó (hàng thứ hai trong hình). Con số này là 16 và chúng tôi đang tìm kiếm 23. Con số hiện tại ít hơn số mà chúng tôi đang tìm kiếm. Điều đó nghĩa là gì? Nó có nghĩa làtất cả các số trước đó (những số nằm trước số 16) không cần phải kiểm tra : chúng được đảm bảo nhỏ hơn số chúng tôi đang tìm kiếm, vì mảng của chúng tôi đã được sắp xếp! Chúng tôi tiếp tục tìm kiếm trong số 5 yếu tố còn lại. Ghi chú:chúng tôi chỉ thực hiện một so sánh, nhưng chúng tôi đã loại bỏ một nửa số tùy chọn có thể. Chúng ta chỉ còn lại 5 yếu tố. Chúng tôi sẽ lặp lại bước trước đó bằng cách một lần nữa chia mảng con còn lại thành một nửa và một lần nữa lấy phần tử ở giữa (hàng thứ 3 trong hình ảnh). Con số này là 56, và nó lớn hơn số chúng ta đang tìm. Điều đó nghĩa là gì? Điều đó có nghĩa là chúng ta đã loại bỏ 3 khả năng khác: chính số 56 cũng như hai số sau nó (vì chúng được đảm bảo lớn hơn 23, vì mảng đã được sắp xếp). Chúng tôi chỉ còn 2 số để kiểm tra (hàng cuối cùng trong hình ảnh) — các số có chỉ số mảng 5 và 6. Chúng tôi kiểm tra số đầu tiên và tìm thấy thứ chúng tôi đang tìm kiếm — số 23! Chỉ số của nó là 5! Hãy xem kết quả của thuật toán của chúng tôi, và sau đó chúng tôi' sẽ phân tích sự phức tạp của nó. Nhân tiện, bây giờ bạn đã hiểu tại sao điều này được gọi là tìm kiếm nhị phân: nó dựa vào việc chia đôi dữ liệu nhiều lần. Kết quả thật ấn tượng! Nếu chúng tôi sử dụng tìm kiếm tuyến tính để tìm số, chúng tôi sẽ cần tới 10 phép so sánh, nhưng với tìm kiếm nhị phân, chúng tôi đã hoàn thành nhiệm vụ chỉ với 3! Trong trường hợp xấu nhất, sẽ có 4 phép so sánh (nếu ở bước cuối cùng, số chúng ta muốn là khả năng thứ hai trong số các khả năng còn lại, chứ không phải là khả năng đầu tiên. Vậy còn độ phức tạp của nó thì sao? Đây là một điểm rất thú vị :) Thuật toán tìm kiếm nhị phân ít phụ thuộc vào số phần tử trong mảng hơn nhiều so với thuật toán tìm kiếm tuyến tính (nghĩa là phép lặp đơn giản). Với 10 phần tử trong mảng, tìm kiếm tuyến tính sẽ cần tối đa 10 phép so sánh, nhưng tìm kiếm nhị phân sẽ cần tối đa 4 phép so sánh. Đó là một sự khác biệt theo hệ số 2,5. Nhưng đối với một mảng gồm 1000 phần tử , tìm kiếm tuyến tính sẽ cần tới 1000 phép so sánh, nhưng tìm kiếm nhị phân sẽ chỉ cần 10 phép so sánh ! Sự khác biệt bây giờ là 100 lần! Ghi chú:số lượng phần tử trong mảng đã tăng 100 lần (từ 10 lên 1000), nhưng số phép so sánh cần thiết cho tìm kiếm nhị phân chỉ tăng theo hệ số 2,5 (từ 4 lên 10). Nếu chúng ta có tới 10.000 phần tử , sự khác biệt sẽ còn ấn tượng hơn: 10.000 phép so sánh cho tìm kiếm tuyến tính và tổng cộng 14 phép so sánh cho tìm kiếm nhị phân. Và một lần nữa, nếu số phần tử tăng 1000 lần (từ 10 lên 10000), thì số phép so sánh chỉ tăng theo hệ số 3,5 (từ 4 lên 14). Độ phức tạp của thuật toán tìm kiếm nhị phân là logarit hoặc, nếu chúng ta sử dụng ký hiệu O lớn, O(log n). Tại sao nó được gọi như vậy? Logarit giống như đối lập với lũy thừa. Logarit nhị phân là lũy thừa mà số 2 phải tăng lên để có được một số. Ví dụ: chúng tôi có 10.000 phần tử cần tìm kiếm bằng thuật toán tìm kiếm nhị phân. 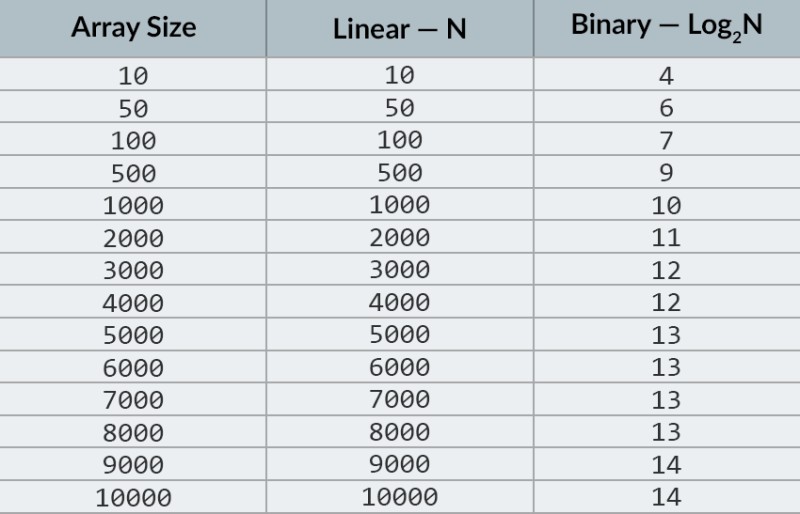 Hiện tại, bạn có thể nhìn vào bảng giá trị để biết rằng làm điều này sẽ yêu cầu tối đa 14 phép so sánh. Nhưng điều gì sẽ xảy ra nếu không ai cung cấp một bảng như vậy và bạn cần tính toán chính xác số lần so sánh tối đa? Bạn chỉ cần trả lời một câu hỏi đơn giản: bạn cần nâng số 2 lên lũy thừa nào để kết quả lớn hơn hoặc bằng số phần tử cần kiểm tra? Đối với 10.000, nó là sức mạnh thứ 14. 2 mũ 13 quá nhỏ (8192), nhưng 2 mũ 14 = 16384, và con số này thỏa mãn điều kiện của chúng ta (nó lớn hơn hoặc bằng số phần tử trong mảng). Chúng tôi đã tìm thấy logarit: 14. Đó là số phép so sánh mà chúng tôi có thể cần! :) Các thuật toán và độ phức tạp của thuật toán là một chủ đề quá rộng để phù hợp với một bài học. Nhưng biết điều đó là rất quan trọng: nhiều cuộc phỏng vấn việc làm sẽ liên quan đến các câu hỏi liên quan đến thuật toán. Đối với lý thuyết, tôi có thể giới thiệu một số cuốn sách cho bạn. Bạn có thể bắt đầu với " Grokking Algorithms ". Các ví dụ trong cuốn sách này được viết bằng Python, nhưng cuốn sách sử dụng ngôn ngữ và các ví dụ rất đơn giản. Đó là lựa chọn tốt nhất cho người mới bắt đầu và hơn nữa, nó không lớn lắm. Trong số những cách đọc nghiêm túc hơn, chúng tôi có sách của Robert Lafore và Robert Sedgewick. Cả hai đều được viết bằng Java, điều này sẽ giúp bạn học dễ dàng hơn một chút. Rốt cuộc, bạn đã khá quen thuộc với ngôn ngữ này! :) Đối với học sinh giỏi toán thì lựa chọn tốt nhất là sách của Thomas Cormen . Nhưng lý thuyết một mình sẽ không lấp đầy bụng của bạn! Kiến thức != Khả năng . Bạn có thể thực hành giải các bài toán liên quan đến thuật toán trên HackerRank và LeetCode . Các nhiệm vụ từ các trang web này thường được sử dụng ngay cả trong các cuộc phỏng vấn tại Google và Facebook, vì vậy bạn chắc chắn sẽ không cảm thấy nhàm chán :) Để củng cố tài liệu bài học này, tôi khuyên bạn nên xem video tuyệt vời này về ký hiệu O lớn trên YouTube. Hẹn gặp lại các bạn trong các bài học tiếp theo! :)
Hiện tại, bạn có thể nhìn vào bảng giá trị để biết rằng làm điều này sẽ yêu cầu tối đa 14 phép so sánh. Nhưng điều gì sẽ xảy ra nếu không ai cung cấp một bảng như vậy và bạn cần tính toán chính xác số lần so sánh tối đa? Bạn chỉ cần trả lời một câu hỏi đơn giản: bạn cần nâng số 2 lên lũy thừa nào để kết quả lớn hơn hoặc bằng số phần tử cần kiểm tra? Đối với 10.000, nó là sức mạnh thứ 14. 2 mũ 13 quá nhỏ (8192), nhưng 2 mũ 14 = 16384, và con số này thỏa mãn điều kiện của chúng ta (nó lớn hơn hoặc bằng số phần tử trong mảng). Chúng tôi đã tìm thấy logarit: 14. Đó là số phép so sánh mà chúng tôi có thể cần! :) Các thuật toán và độ phức tạp của thuật toán là một chủ đề quá rộng để phù hợp với một bài học. Nhưng biết điều đó là rất quan trọng: nhiều cuộc phỏng vấn việc làm sẽ liên quan đến các câu hỏi liên quan đến thuật toán. Đối với lý thuyết, tôi có thể giới thiệu một số cuốn sách cho bạn. Bạn có thể bắt đầu với " Grokking Algorithms ". Các ví dụ trong cuốn sách này được viết bằng Python, nhưng cuốn sách sử dụng ngôn ngữ và các ví dụ rất đơn giản. Đó là lựa chọn tốt nhất cho người mới bắt đầu và hơn nữa, nó không lớn lắm. Trong số những cách đọc nghiêm túc hơn, chúng tôi có sách của Robert Lafore và Robert Sedgewick. Cả hai đều được viết bằng Java, điều này sẽ giúp bạn học dễ dàng hơn một chút. Rốt cuộc, bạn đã khá quen thuộc với ngôn ngữ này! :) Đối với học sinh giỏi toán thì lựa chọn tốt nhất là sách của Thomas Cormen . Nhưng lý thuyết một mình sẽ không lấp đầy bụng của bạn! Kiến thức != Khả năng . Bạn có thể thực hành giải các bài toán liên quan đến thuật toán trên HackerRank và LeetCode . Các nhiệm vụ từ các trang web này thường được sử dụng ngay cả trong các cuộc phỏng vấn tại Google và Facebook, vì vậy bạn chắc chắn sẽ không cảm thấy nhàm chán :) Để củng cố tài liệu bài học này, tôi khuyên bạn nên xem video tuyệt vời này về ký hiệu O lớn trên YouTube. Hẹn gặp lại các bạn trong các bài học tiếp theo! :)
