1. Szczegółowy przewodnik po Git dla początkujących
Dzisiaj porozmawiamy o systemie kontroli wersji - Git (czytaj jako GIT).
Bez znajomości i zrozumienia tego narzędzia nie da się być programistą. Oczywiście do ciągłej pracy nie trzeba mieć w głowie wszystkich komend i możliwości. Musisz znać zestaw poleceń, które pomogą ci zrozumieć wszystko, co się dzieje.
Podstawy Gita
Git to rozproszony system kontroli wersji naszego kodu. Dlaczego ona jest u nas? Zespół potrzebuje jakiegoś systemu zarządzania pracą. Konieczne jest śledzenie zmian zachodzących w czasie.
Oznacza to, że krok po kroku widzimy, które pliki uległy zmianie iw jaki sposób. Jest to szczególnie ważne, gdy analizujesz, co zostało zrobione w ramach jednego zadania: umożliwia to cofnięcie się.
Wyobraź sobie sytuację: był działający kod, wszystko było w nim w porządku, ale postanowiliśmy coś poprawić lub poprawić. Wszystko jest w porządku, ale taka poprawa zepsuła połowę funkcjonalności, uniemożliwiła pracę. Więc co dalej? Bez Gita trzeba by godzinami siedzieć i przypominać sobie, jak wszystko było pierwotnie. A więc po prostu cofamy zatwierdzenie - i to wszystko.
A co, jeśli jest dwóch programistów, którzy jednocześnie wprowadzają własne zmiany w kodzie? Bez Gita wygląda to tak: skopiowali kod z oryginału, zrobili co trzeba. Nadchodzi ten moment i obaj chcą dodać swoje zmiany do głównego folderu. I co zrobić w tej sytuacji?
W ogóle nie będzie takich problemów, jeśli użyjesz Git.
Instalowanie Gita
Zainstaluj Gita na swoim komputerze. W przypadku różnych systemów operacyjnych ten proces jest nieco inny.
Instalacja dla systemu Windows
Jak zwykle musisz pobrać plik exe i uruchomić go. Tutaj wszystko jest proste: kliknij pierwszy link Google , zainstaluj i to wszystko. Do pracy użyjemy udostępnionej przez nich konsoli bash.
Aby pracować w systemie Windows, musisz uruchomić Git Bash. Oto jak to wygląda w menu Start:
I to jest konsola, w której możesz pracować.
Aby nie przechodzić za każdym razem do folderu projektu, aby otworzyć tam git, możesz otworzyć konsolę w folderze prawym przyciskiem myszy z potrzebną nam ścieżką:

Instalacja dla Linuksa
Zwykle git jest już zainstalowany i zawarty w dystrybucjach Linuksa, ponieważ jest to narzędzie pierwotnie napisane do rozwijania jądra Linuksa. Ale są sytuacje, kiedy tak nie jest. Aby to sprawdzić, musisz otworzyć terminal i wpisać: git --version. Jeśli istnieje zrozumiała odpowiedź, nic nie trzeba instalować.
Otwórz terminal i zainstaluj. W przypadku Ubuntu musisz napisać: sudo apt-get install git. I to wszystko: teraz możesz używać git w dowolnym terminalu.
Instalacja na macOS
Tutaj również musisz najpierw sprawdzić, czy istnieje już git (patrz wyżej, jak w Linuksie).
Jeśli nie, najprostszym sposobem jest pobranie najnowszej wersji . Jeśli XCode jest zainstalowany, git zostanie już automatycznie zainstalowany.
Konfigurowanie Gita
Git ma ustawienie użytkownika, z którego będzie wykonywana praca. Jest to rozsądna i konieczna rzecz, ponieważ podczas tworzenia zatwierdzenia git pobiera dokładnie te informacje dla pola Author.
Aby ustawić nazwę użytkownika i hasło dla wszystkich projektów, musisz napisać następujące polecenia:
Jeśli istnieje potrzeba zmiany autora dla konkretnego projektu (na przykład dla projektu osobistego), możesz usunąć --global, a okaże się to tak:
Trochę teorii
Aby być w temacie, wskazane jest dodanie kilku nowych słów i działań do swojego odwołania ... W przeciwnym razie nie będzie o czym mówić. Oczywiście jest to rodzaj żargonu i kalki z języka angielskiego, więc dodam znaczenia w języku angielskim.
Jakie są słowa i czyny?
- repozytorium git (repozytorium git);
- popełnić (zobowiązać);
- oddział
- łączyć (łączyć);
- konflikty;
- szpula (ciągnąć);
- pchaj pchaj);
- jak zignorować niektóre pliki (.gitignore).
I tak dalej.
Stany w Git
Gita ma kilka stanów do zrozumienia i zapamiętania:
- nieśledzony (nieśledzony);
- zmodyfikowany (zmodyfikowany);
- przygotowany (inscenizowany);
- zaangażowany.
Co to znaczy?
Są to stany, w których znajdują się pliki z naszego kodu. Oznacza to, że ich ścieżka życia zwykle wygląda tak:
- Plik, który został utworzony i nie został dodany do repozytorium, będzie w stanie nieśledzonym.
- Dokonujemy zmian w plikach, które zostały już dodane do repozytorium git - są one w stanie zmodyfikowanym.
- Z tych plików, które zmieniliśmy, wybieramy tylko te (lub wszystkie), które są nam potrzebne (na przykład nie potrzebujemy skompilowanych klas), a te klasy ze zmianami przechodzą w stan staged.
- Zatwierdzenie jest tworzone z przygotowanych plików ze stanu staged i trafia do repozytorium git. Następnie stan etapowy jest pusty. Ale zmodyfikowany może nadal coś zawierać.
To wygląda tak:

Co to jest zatwierdzenie
Zatwierdzenie jest głównym obiektem w kontroli źródła. Zawiera wszystkie zmiany od tego zatwierdzenia. Zatwierdzenia są połączone ze sobą jako pojedynczo połączona lista.
Mianowicie: jest pierwsze zatwierdzenie. Kiedy tworzone jest drugie zatwierdzenie, ono (drugie) wie, co następuje po pierwszym. I w ten sposób możesz śledzić informacje.
Zatwierdzenie posiada również swoje własne informacje, tzw. metadane:
- unikalny identyfikator zatwierdzenia, dzięki któremu można go znaleźć;
- nazwisko autora zatwierdzenia, który je stworzył;
- datę utworzenia zatwierdzenia;
- komentarz opisujący, co zostało zrobione podczas tego zatwierdzenia.
Oto jak to wygląda:

Co to jest oddział

Gałąź jest wskaźnikiem do zatwierdzenia. Ponieważ zatwierdzenie wie, które zatwierdzenie było przed nim, gdy gałąź wskazuje zatwierdzenie, wszystkie poprzednie zatwierdzenia są uwzględniane w tym zatwierdzeniu.
Na tej podstawie możemy powiedzieć, że może istnieć tyle gałęzi wskazujących na to samo zatwierdzenie, ile chcesz.
Praca odbywa się w gałęziach, więc kiedy tworzone jest nowe zatwierdzenie, gałąź przenosi swój wskaźnik do nowszego zatwierdzenia.

Pierwsze kroki z Gitem
Możesz pracować tylko z lokalnym repozytorium i zdalnym.
Aby opracować niezbędne polecenia, możesz użyć tylko lokalnego repozytorium. Przechowuje wszystkie informacje tylko lokalnie w projekcie w folderze .git.
Jeśli mówimy o zdalnym, to wszystkie informacje są przechowywane gdzieś na zdalnym serwerze: lokalnie przechowywana jest tylko kopia projektu, której zmiany można wypchnąć (git push) do zdalnego repozytorium.
Tutaj i poniżej omówimy pracę z gitem w konsoli. Oczywiście możesz skorzystać z niektórych rozwiązań graficznych (na przykład w Intellij IDEA), ale najpierw musisz dowiedzieć się, jakie polecenia się wydarzają i co oznaczają.
Praca z git w lokalnym repozytorium
Aby utworzyć lokalne repozytorium, musisz napisać:

Spowoduje to utworzenie ukrytego folderu .git w miejscu, w którym znajduje się konsola.
.git to folder, w którym przechowywane są wszystkie informacje o repozytorium git. Nie musisz tego usuwać ;)
Następnie pliki są dodawane do tego projektu, a ich stan zmienia się na Nieśledzone. Aby zobaczyć, jaki jest stan prac w tej chwili, piszemy:

Jesteśmy w głównej gałęzi i dopóki nie przejdziemy do innej, wszystko tak pozostanie.
W ten sposób możesz zobaczyć, które pliki zostały zmodyfikowane, ale nie zostały jeszcze dodane do stanu tymczasowego. Aby dodać je do stanu staged, musisz napisać git add. Tutaj może być kilka opcji, na przykład:
- git add -A - dodaj wszystkie pliki ze stanu do staged;
- dodaj git. - dodaj wszystkie pliki z tego folderu i wszystkie wewnętrzne. Zasadniczo taki sam jak poprzedni;
- git add <nazwa pliku> - dodaje tylko określony plik. Tutaj możesz użyć wyrażeń regularnych, aby dodać według jakiegoś wzorca. Na przykład git add *.java: oznacza to, że musisz dodać tylko pliki z rozszerzeniem java.
Oczywiste jest, że dwie pierwsze opcje są proste, ale z dodatkiem będzie ciekawiej, więc piszemy:
Aby sprawdzić status, używamy polecenia, które już znamy:

To pokazuje, że wyrażenie regularne działało poprawnie, a teraz test_resource.txt jest w stanie etapowym.
I na koniec ostatni krok (z lokalnym repozytorium, ze zdalnym będzie jeszcze jeden;)) - zatwierdzenie i utworzenie nowego zatwierdzenia:

Następnie jest świetne polecenie, aby spojrzeć na historię zatwierdzeń na gałęzi. użyjmy tego:
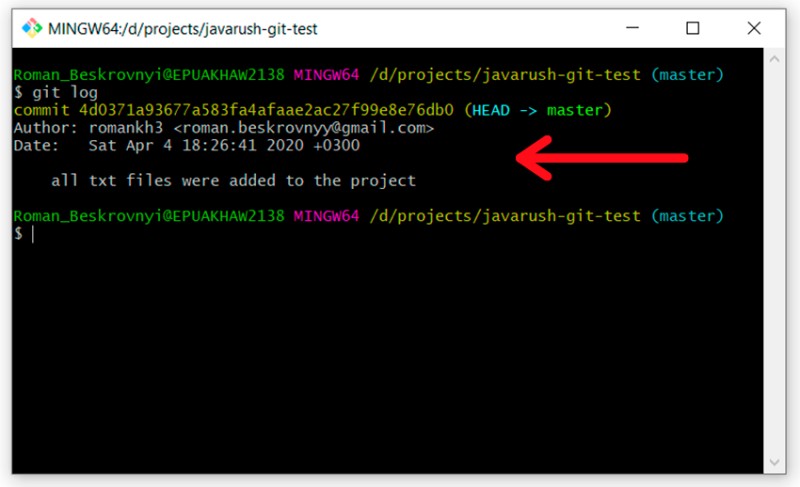
Tutaj już widać, że pojawił się nasz pierwszy commit z tekstem, który przenieśliśmy. Bardzo ważne jest, aby zrozumieć, że tekst, który przekazujemy, powinien jak najdokładniej określać, co zostało zrobione dla tego zatwierdzenia. Pomoże to wiele razy w przyszłości.
Dociekliwy czytelnik, który jeszcze nie zasnął, może zapytać: co się stało z plikiem GitTest.java? Teraz się uczymy, używamy do tego:

Jak widać, pozostał w stanie nieśledzonym i czeka za kulisami. A może w ogóle nie chcemy go dodawać do projektu? Czasami tak bywa.
Następnie, aby było ciekawiej, spróbujmy zmienić nasz plik tekstowy test_resource.txt. Dodajmy tam trochę tekstu i sprawdźmy status:

Tutaj wyraźnie widać różnicę między dwoma stanami – nieśledzonym i zmodyfikowanym.
GitTest.java jest w stanie nieśledzonym, a plik test_resource.txt jest w stanie zmodyfikowanym.
Teraz, gdy mamy już pliki w stanie zmodyfikowanym, możemy przyjrzeć się zmianom, które zostały w nich wprowadzone. Możesz to zrobić za pomocą polecenia:

Oznacza to, że tutaj możesz wyraźnie zobaczyć, co dodałem do naszego pliku tekstowego hello world!
Dodaj zmiany do pliku tekstowego i zatwierdź:
Aby zobaczyć wszystkie zatwierdzenia, piszemy:

Jak widać, są już dwa zatwierdzenia.
W ten sam sposób dodajemy GitTest.java. Teraz bez komentarzy, same komendy:

Praca z .gitignore
Oczywiście chcemy tylko zachować kod źródłowy i nic więcej w repozytorium. Co jeszcze może być? Jako minimum skompilowane klasy i/lub pliki tworzące środowiska programistyczne.
Aby git je zignorował, należy utworzyć specjalny plik. Robimy tak: tworzymy plik w katalogu głównym projektu o nazwie .gitignore iw tym pliku każda linia będzie wzorcem do zignorowania.
W tym przykładzie polecenie git ignorowanie wyglądałoby tak:
cel/
*.iml
.idea/
Spójrzmy teraz:
- pierwsza linia to ignorowanie wszystkich plików z rozszerzeniem .class;
- druga linia ignoruje folder docelowy i wszystko, co zawiera;
- trzecia linia to ignorowanie wszystkich plików z rozszerzeniem .iml;
- czwarta linia ignoruje folder .idea.
Spróbujmy na przykładzie. Aby zobaczyć jak to działa, dodajmy skompilowaną GitTest.class do projektu i sprawdźmy status projektu:

Oczywiście nie chcemy przypadkowo (używając git add -A) dodać skompilowanej klasy do projektu. Aby to zrobić, utwórz plik .gitignore i dodaj wszystko, co zostało opisane wcześniej:

Teraz dodajmy do projektu nowe ignorowanie git zatwierdzenia:
A teraz chwila prawdy: mamy nieśledzoną, skompilowaną klasę GitTest.class, której nie chcieliśmy dodawać do repozytorium git.
W tym miejscu powinno działać git ignorowanie:

Wszystko jest czyste) Git ignoruje +1).
Praca z gałęziami
Oczywiście praca w jednym oddziale jest niewygodna i niemożliwa, gdy w zespole jest więcej niż jedna osoba. Do tego służy rozgałęzienie.
Gałąź to tylko ruchomy wskaźnik do zatwierdzeń.
W tej części przyjrzymy się pracy w różnych gałęziach: jak łączyć zmiany z jednej gałęzi w drugą, jakie mogą wystąpić konflikty i wiele więcej.
Aby zobaczyć listę wszystkich oddziałów w repozytorium i zrozumieć, na którym się znajdujesz, musisz napisać:

Widać, że mamy tylko jedną gałąź główną, a gwiazdka przed nią mówi, że na niej jesteśmy. Przy okazji, aby dowiedzieć się, na którym branchu się znajdujemy, możesz też skorzystać ze sprawdzania statusu (git status).
Następnie istnieje kilka opcji tworzenia oddziałów (może być więcej, używam tych):
- utworzyć nowy oddział na podstawie tego, na którym jesteśmy (99% przypadków);
- utwórz gałąź na podstawie konkretnego zatwierdzenia (1%).
Utwórz gałąź na podstawie określonego zatwierdzenia
Będziemy polegać na unikalnym identyfikatorze zatwierdzenia. Aby go znaleźć, piszemy:

Podkreślmy zatwierdzenie komentarzem „dodano hello world…”. Ma unikalny identyfikator - „6c44e53d06228f888f2f454d3cb8c1c976dd73f8”. Chcemy stworzyć gałąź programistyczną zaczynając od tego zatwierdzenia. W tym celu piszemy:
Tworzona jest gałąź, która będzie miała tylko dwa pierwsze zatwierdzenia z gałęzi głównej. Aby to przetestować, najpierw upewniamy się, że przenieśliśmy się do innej gałęzi i patrzymy na liczbę zatwierdzeń w tej gałęzi:

I to prawda: okazało się, że mamy dwa commity. Nawiasem mówiąc, ciekawy punkt: ta gałąź nie ma jeszcze pliku .gitignore, więc nasz skompilowany plik (GitTest.class) jest teraz podświetlony w stanie nieśledzonym.
Teraz możemy ponownie zrewidować nasze gałęzie, pisząc:

Widać, że są dwie gałęzie – master i development – i teraz stoimy na development.
Utwórz oddział na podstawie bieżącego
Drugim sposobem na utworzenie gałęzi jest utworzenie z innej. Stwórzmy gałąź opartą na gałęzi master: aby to zrobić, najpierw musisz się do niej przełączyć, a kolejnym krokiem jest utworzenie nowej. Patrzymy:
- git checkout master - przejdź do gałęzi master;
- git status - sprawdź, czy jest na masterze.

Tutaj widać, że przeszliśmy na gałąź master, tutaj już działa git ignorowanie, a skompilowana klasa nie świeci już jako nieśledzona.
Teraz utwórz nową gałąź opartą na gałęzi głównej:

Jeśli masz jakiekolwiek wątpliwości, że ta gałąź nie będzie taka sama jak master, możesz to łatwo sprawdzić, pisząc git log i przeglądając wszystkie rewizje. Powinno być ich czterech.
Rozwiązywanie konfliktów
Zanim zajmiemy się tym, czym jest konflikt, musimy porozmawiać o scalaniu (scalaniu) jednej gałęzi w drugą.
Oto zdjęcie, które może pokazać proces, gdy jedna gałąź jest łączona z drugą:

Oznacza to, że istnieje gałąź główna. W pewnym momencie powstaje z niego wtórny, w którym zachodzą zmiany. Po zakończeniu pracy musisz scalić jedną gałąź w drugą.
W naszym przykładzie utworzyliśmy gałąź Feature/update-txt-files. Zgodnie z nazwą oddziału zaktualizuj tekst.

Teraz musisz utworzyć nowe zatwierdzenie dla tej sprawy:

Teraz, jeśli chcemy scalić gałąź feature/update-txt-files w master, musimy przejść do master i napisać git merge feature/update-txt-files:

W rezultacie gałąź główna ma teraz również zatwierdzenie, które zostało dodane do plików funkcji/aktualizacji-txt.
Ta funkcja została dodana, więc możesz usunąć gałąź funkcji. W tym celu piszemy:
Komplikujemy sytuację: teraz powiedzmy, że ponownie musimy zmienić plik txt. Ale teraz również w kreatorze ten plik również zostanie zmieniony. Oznacza to, że będzie się zmieniał równolegle, a git nie będzie w stanie zrozumieć, co należy zrobić w sytuacji, gdy chcemy scalić nowy kod w gałąź master.
Tworzymy nowy branch na podstawie mastera, dokonujemy zmian w text_resource.txt i tworzymy zatwierdzenie dla tej sprawy:
... dokonaj zmian w pliku


Przejdź do gałęzi głównej i zaktualizuj ten plik tekstowy w tym samym wierszu co gałąź funkcji:
… zaktualizowano plik test_resource.txt
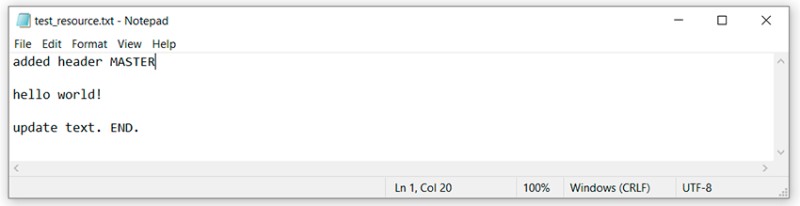
A teraz najciekawszy punkt: musisz scalić zmiany z gałęzi feature/add-header do master. Jesteśmy na gałęzi master, więc wystarczy napisać:
Ale otrzymamy wynik z konfliktem w pliku test_resource.txt:

I tutaj widzimy, że git nie mógł sam zdecydować, jak scalić ten kod i mówi, że trzeba najpierw rozwiązać konflikt, a dopiero potem dokonać zatwierdzenia.
Ok, otwórz plik, w którym występuje konflikt w edytorze tekstu i zobacz:

Aby zrozumieć, co zrobił tutaj git, musisz pamiętać, co gdzie napisaliśmy i porównać:
- Pomiędzy „<<<<<<< HEAD” i „=======” znajdują się główne zmiany, które były w tej linii w gałęzi głównej.
- Pomiędzy „=======” a „>>>>>>> feature/add-header” znajdują się zmiany, które były w gałęzi feature/add-header.
W ten sposób git pokazuje, że w tym momencie nie mógł wymyślić, jak połączyć ten plik w całość, podzielił tę sekcję na dwie części z różnych gałęzi i zasugerował, abyśmy sami zdecydowali.
Cóż, mocną wolą postanawiam usunąć wszystko, pozostawiając tylko nagłówek słowa:

Przyjrzyjmy się statusowi zmian, opis będzie nieco inny. Stan nie zostanie zmodyfikowany, ale rozłączony. Można było więc bezpiecznie dodać piąty stan… Ale myślę, że jest zbędny, zobaczmy:

Przekonany, że to inny przypadek, niezwykły. Kontynuujemy:

W opisie widać, że sugerują napisanie tylko git commit. Słuchanie i pisanie:

I to wszystko: tak to zrobiliśmy - rozwiązaliśmy konflikt w konsoli.
Oczywiście w środowiskach deweloperskich można to zrobić trochę prościej, na przykład w Intellij IDEA wszystko jest ustawione tak dobrze, że można w nim wykonać wszystkie niezbędne czynności. Ale środowisko programistyczne robi wiele rzeczy „pod maską” i często nie rozumiemy, co dokładnie się tam wydarzyło. A kiedy nie ma zrozumienia, mogą pojawić się problemy.
Praca ze zdalnymi repozytoriami
Ostatnim krokiem jest zajęcie się kilkoma dodatkowymi poleceniami, które są potrzebne do pracy ze zdalnym repozytorium.
Jak powiedziałem, zdalne repozytorium to miejsce, w którym repozytorium jest przechowywane i skąd można je sklonować.
Czym są zdalne repozytoria? Przykłady ciemności:
- GitHub to największe repozytorium dla repozytoriów i wspólnego programowania.
- GitLab to internetowe narzędzie cyklu życia DevOps oparte na otwartym kodzie źródłowym, które zapewnia system zarządzania repozytorium kodu dla Git z własną wiki, narzędziem do śledzenia błędów, potokiem CI/CD i nie tylko.
- BitBucket to hosting projektów i usługa sieciowa do współpracy oparta na kontroli wersji Mercurial i Git. Kiedyś miał dużą przewagę nad GitHubem, ponieważ miał darmowe prywatne repozytoria. W zeszłym roku GitHub udostępnił tę funkcję wszystkim za darmo.
- I tak dalej…
Pierwszą rzeczą do zrobienia podczas pracy ze zdalnym repozytorium jest sklonowanie projektu do lokalnego.
W tym celu eksportujemy projekt, który wykonaliśmy lokalnie. Teraz każdy może sklonować go dla siebie, pisząc:
Masz teraz pełną kopię projektu lokalnie. Aby mieć pewność, że najnowsza kopia projektu jest lokalna, trzeba, jak to mówią, buforować dane, pisząc:

W naszym przypadku zdalnie nic się nie zmieniło, więc odpowiedź brzmi: Już aktualne.
Ale jeśli dokonamy jakichkolwiek zmian w zdalnym repozytorium, lokalne zostanie zaktualizowane po ich zbuforowaniu.
I wreszcie ostatnie polecenie to przekazanie danych do zdalnego repozytorium. Kiedy zrobiliśmy coś lokalnie i chcemy zatwierdzić to w zdalnym repozytorium, najpierw musimy lokalnie utworzyć nowe zatwierdzenie. Aby to zrobić, dodaj coś jeszcze do naszego pliku tekstowego:

Teraz rzeczą, która jest już dla nas powszechna, jest utworzenie zatwierdzenia dla tej sprawy:
A teraz polecenie wypchnięcia tego do zdalnego repozytorium:
To wszystko!
| Przydatne linki |
|---|
|
2. Jak pracować z Gitem w IntelliJ IDEA
W tej części dowiesz się jak pracować z Gitem w Intellij IDEA.
Wymagane dane wejściowe:
- Przeczytaj, powtórz i zrozum poprzednią część. Pomoże to upewnić się, że wszystko jest już skonfigurowane i gotowe do pracy.
- Zainstaluj Intellij IDEA. To powinno być ok :)
- Przeznacz godzinę czasu na pełną asymilację.
Do pracy weźmy projekt demonstracyjny , który został użyty w wykładzie o Gicie.
Klonowanie projektu lokalnie
Istnieją dwie opcje.
- Jeśli masz już konto na githubie i chcesz coś później wypchnąć, lepiej rozwidlić projekt dla siebie i sklonować swoją kopię. Jak forkować - przeczytasz w tym artykule, w rozdziale przykładowy workflow forka .
- Sklonuj z repozytorium i rób wszystko lokalnie bez możliwości wypychania wszystkiego na serwer.
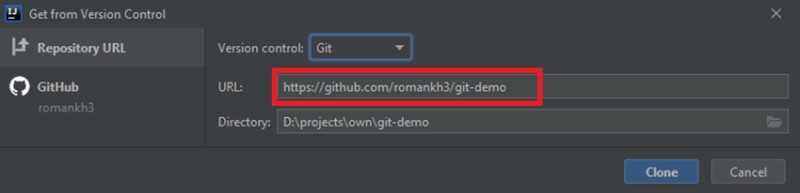
Aby sklonować projekt z githuba, musisz skopiować link do projektu i przenieść go do IntelliJ IDEA:
-
Skopiuj adres projektu:
![]()
-
Otwórz Intellij IDEA i wybierz Pobierz z kontroli wersji:
![]()
-
Kopiuj wklej adres w projekcie:
![]()
-
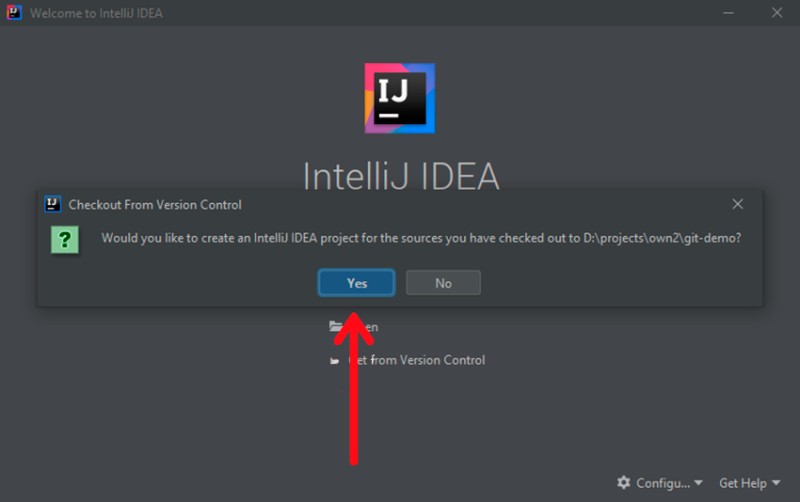
Zostaniesz poproszony o utworzenie projektu Intellij IDEA. Przyjmujemy ofertę:
![]()
-
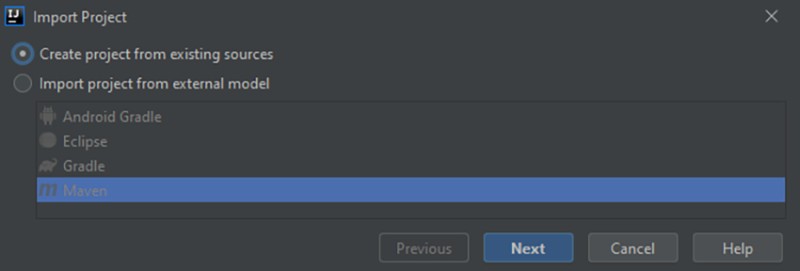
Ponieważ nie ma systemu kompilacji, wybierz Utwórz projekt z istniejących źródeł:
![]()
-
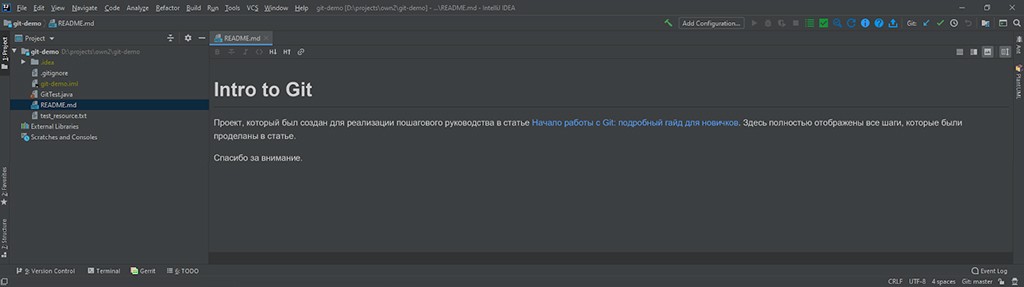
Poniżej obraz olejny:
![]()

Wymyśliliśmy klonowanie, teraz możesz się rozejrzeć.
Najpierw spójrz na Intellij IDEA jako git UI
Przyjrzyj się jeszcze raz sklonowanemu projektowi: można tam uzyskać wiele informacji o systemie kontroli wersji.
Pierwszym z nich jest panel kontroli wersji w lewym dolnym rogu. Możesz w nim znaleźć wszystkie lokalne zmiany i uzyskać listę zatwierdzeń (podobnie jak git log).
Przejdźmy do wykładu z dziennika. Istnieje pewien element wizualny, który pomaga dokładnie zrozumieć, jak przebiegał proces tworzenia. Na przykład możesz zobaczyć, że utworzono nową gałąź z dodanym nagłówkiem do zatwierdzenia txt, która następnie została połączona z gałęzią główną. Jeśli klikniesz na zatwierdzenie, w prawym rogu zobaczysz wszystkie informacje o zatwierdzeniu: wszystkie zmiany i ich metadane.

Ponadto możesz zobaczyć, jakie zmiany zostały wprowadzone. Co więcej, konflikt został tam rozwiązany. Ten IDEA też się świetnie prezentuje.
Jeśli dwukrotnie klikniesz plik, który został zmieniony podczas tego zatwierdzenia, zobaczymy, jak konflikt został rozwiązany:

Można zauważyć, że po prawej i po lewej stronie znajdowały się dwie wersje jednego pliku, które należało scalić w jedną. A w środku - wynik, który ostatecznie się okazał.
Gdy projekt ma wiele oddziałów, zatwierdzeń i użytkowników, którzy pracują w projekcie, musisz wyszukiwać osobno według oddziału (branch), użytkownika (użytkownika) i daty (daty):

Również przed przystąpieniem do pracy warto wyjaśnić, jak rozumieć, w której branży się znajdujemy.
W prawym dolnym rogu znajduje się przycisk Git: master, gdzie za Git: pokazuje, w której gałęzi aktualnie znajduje się projekt. Jeśli klikniesz przycisk, możesz zrobić wiele przydatnych rzeczy: przenieść się do innej gałęzi, utworzyć nową, zmienić nazwę istniejącej i tak dalej.

Praca z repozytorium
Przydatne skróty klawiszowe
Aby kontynuować pracę, musisz zapamiętać kilka bardzo przydatnych skrótów klawiszowych:
- ctrl + t - pobierz najnowsze zmiany ze zdalnego repozytorium (git pull).
- ctrl + k - zatwierdź / zobacz wszystkie zmiany, które są obecnie. Obejmuje to zarówno pliki nieśledzone, jak i zmodyfikowane (git commit).
- ctrl + shift + k to polecenie do wypychania zmian do zdalnego repozytorium. Wszystkie zatwierdzenia, które zostały utworzone lokalnie i nie są jeszcze na zdalnym komputerze, będą oferowane do wypychania (git push).
- alt + ctrl + z - cofnij zmiany w określonym pliku do stanu ostatniego utworzonego zatwierdzenia w lokalnym repozytorium. Jeśli wybierzesz cały projekt w lewym górnym rogu, możesz cofnąć zmiany we wszystkich plikach.
Czego chcemy?
Aby pracować, musimy opanować podstawowy skrypt, który jest używany wszędzie.
Zadanie polega na zaimplementowaniu nowej funkcjonalności w osobnej gałęzi i wypchnięciu jej do zdalnego repozytorium (wtedy trzeba stworzyć kolejne pull request dla gałęzi głównej, ale to wykracza poza zakres naszego wykładu).
Co muszę zrobić?
-
Pobierz wszystkie dotychczasowe zmiany w gałęzi master (na przykład master).
-
Na podstawie tego głównego utwórz osobny do swojej pracy.
-
Wdrażaj nową funkcjonalność.
-
Przełącz się na gałąź główną i sprawdź, czy podczas pracy nie pojawiły się jakieś nowe zmiany. Jeśli nie, to wszystko jest w porządku, ale jeśli tak, to wykonujemy następujące czynności: przechodzimy do działającej gałęzi i przestawiamy zmiany z głównej gałęzi na naszą. Jeśli wszystko poszło dobrze, to świetnie. Ale równie dobrze mogą wystąpić konflikty. I można je po prostu rozwiązać z wyprzedzeniem, bez marnowania czasu na zdalne repozytorium.
Wydawałoby się, po co to robić? Jest to zasada dobrego smaku, która zapobiega pojawianiu się konfliktów po wypchnięciu twojego oddziału do lokalnego repozytorium (jest oczywiście szansa, że nadal będą, ale staje się znacznie mniejsza ) .
-
Wypchnij zmiany do zdalnego repozytorium.
Jak uzyskać zmiany ze zdalnego serwera
Dodaliśmy opis do pliku README z nowym zatwierdzeniem i chcemy uzyskać te zmiany. Możliwy jest wybór pomiędzy scalaniem a rebase w przypadku, gdy zmiany zostały wprowadzone zarówno w repozytorium lokalnym, jak i zdalnym. Wybierz fuzję.
Wpisz ctrl + t :

W rezultacie możesz zobaczyć, jak zmienił się plik README, tj. zmiany ze zdalnego repozytorium zostały pobrane, aw prawym dolnym rogu widać wszystkie szczegóły tych zmian, które nadeszły z serwera.

Utwórz nową gałąź opartą na master
Tutaj wszystko jest proste.
Przejdź do prawego dolnego rogu i kliknij Git: master , wybierz + New Branch .
 Zostawiamy znacznik wyboru Oddział kasy i wpisujemy nazwę nowego oddziału. W naszym przypadku będzie to readme-improver .
Zostawiamy znacznik wyboru Oddział kasy i wpisujemy nazwę nowego oddziału. W naszym przypadku będzie to readme-improver . 
Następnie Git: master zmieni się na Git: readme-improver .
Symulacja pracy równoległej
Aby pojawiły się konflikty, ktoś musi je stworzyć.
Edytujmy plik README przez przeglądarkę z nowym zatwierdzeniem iw ten sposób zasymulujmy pracę równoległą. Na przykład ktoś podczas pracy dokonał zmian w tym samym pliku co my, co doprowadzi do konfliktu. Usuńmy słowo „całkowicie” z wiersza 10.
Zaimplementuj swoją funkcjonalność
Zadanie polega na zmianie README i dodaniu opisu do nowego artykułu, czyli aby praca w git przechodziła przez Intellij IDEA. Dodajemy to:

Zmiany zostały wprowadzone, teraz możesz utworzyć zatwierdzenie. Naciśnij klawisz skrótu ctrl + k , otrzymamy:

Zanim utworzysz zatwierdzenie, musisz uważnie przyjrzeć się temu, co jest oferowane w tym oknie.
W sekcji Commit Message wpisujemy tekst commita i aby został utworzony należy kliknąć przycisk Commit .
Piszemy, że zmienił się plik README i tworzymy zatwierdzenie. W rezultacie w lewym dolnym rogu wyskakuje alert, w którym nazwą zatwierdzenia będzie:

Sprawdź, czy gałąź główna uległa zmianie
Wykonaliśmy zadanie, działa, testy zostały napisane, wszystko jest w porządku. Ale zanim wypchniesz na serwer, musisz jeszcze sprawdzić, czy w tym czasie nastąpiły jakieś zmiany w gałęzi głównej. Jak to mogło się stać? Bardzo proste: ktoś otrzymał zadanie po tobie i ten ktoś zrobił to szybciej niż ty.
Dlatego przechodzimy do gałęzi master. Aby to zrobić, w prawym dolnym rogu zrób to, co pokazano na poniższym rysunku:

W gałęzi głównej naciśnij ctrl + t , aby pobrać najnowsze zmiany ze zdalnego serwera. Jeśli spojrzysz na to, jakie były zmiany, możesz łatwo zobaczyć, co się stało:

Jak widać, słowo „całkowicie” zostało usunięte. Być może to ktoś z marketingu uznał, że nie tak się pisze i dał deweloperom zadanie aktualizacji.
Mamy teraz lokalnie najnowszą wersję gałęzi głównej. Powrót do programu Readme-improver .
Teraz musimy zmienić bazę zmian z gałęzi master na naszą. My robimy: 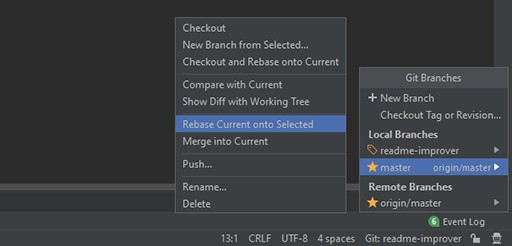
Jeśli zrobiłeś wszystko dobrze ze mną, wynikiem powinien być konflikt w pliku README:

Jest tu również wiele informacji, które należy zrozumieć i przyswoić. To pokazuje listę (jeden element w naszym przypadku) plików, które mają konflikty. Możemy wybrać trzy opcje:
- zaakceptuj swoje - zaakceptuj tylko zmiany z readme-improver.
- akceptuj ich - akceptuj tylko zmiany od mistrza.
- scalaj - wybierz, co zostawić, a co usunąć.
Nie jest jasne, co się tam zmieniło, a jeśli zmiany są już w masterze, to są tam potrzebne i nie można po prostu zaakceptować naszych zmian, więc wybieramy merge : 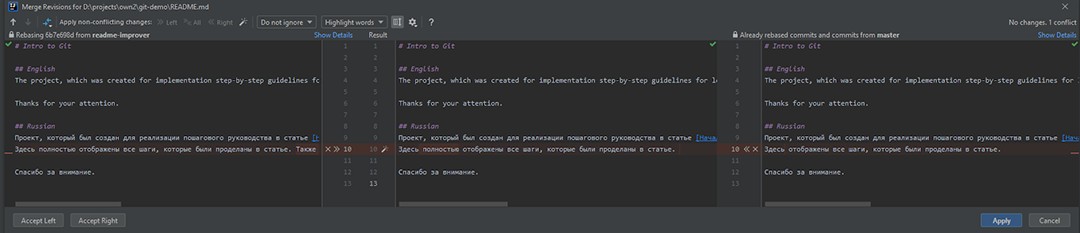
Tutaj możesz zobaczyć, że istnieją trzy części:
- To są zmiany z pliku readme-improver.
- Wynik. Na razie jest tak jak przed zmianami.
- Zmiany z gałęzi głównej.
Musimy zebrać wynik w taki sposób, aby zadowolił wszystkich. Dlatego zbadaliśmy, co zrobili PRZED nami, zdaliśmy sobie sprawę, że po prostu usunęli słowo „całkowicie”. No dobrze, nie ma problemu. W rezultacie usuniemy go i dodamy nasze zmiany. Jak tylko naprawimy wynik, możesz kliknąć Zastosuj .
Następnie pojawi się powiadomienie, że rebase się powiódł:
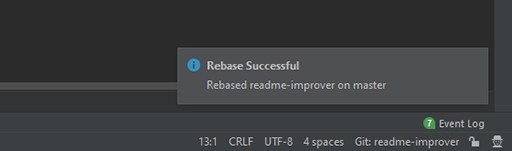
W ten sposób rozwiązaliśmy nasz pierwszy konflikt za pośrednictwem Intellij IDEA.
Wypchnij zmiany na zdalny serwer
Następnym krokiem jest wypchnięcie zmian na zdalny serwer i utworzenie żądania ściągnięcia. Aby to zrobić wystarczy nacisnąć ctrl + shift + k , po czym otrzymamy:

Po lewej stronie pojawi się lista zatwierdzeń, które nie zostały wypchnięte do zdalnego repozytorium, a po prawej wszystkie pliki, które uległy zmianie. I to wszystko: naciśnij Push , a będziesz szczęśliwy :)
Jeśli push się powiedzie, w prawym dolnym rogu pojawi się takie powiadomienie:

Bonus: utworzenie żądania ściągnięcia
Wchodzimy do repozytorium github i widzimy, że github już wie co nam zaoferować:

Kliknij Porównaj i ściągnij żądanie , a następnie kliknij Utwórz żądanie ściągnięcia . Ze względu na to, że wcześniej rozwiązaliśmy konflikty, teraz podczas tworzenia pull requesta możesz go natychmiast scalić: 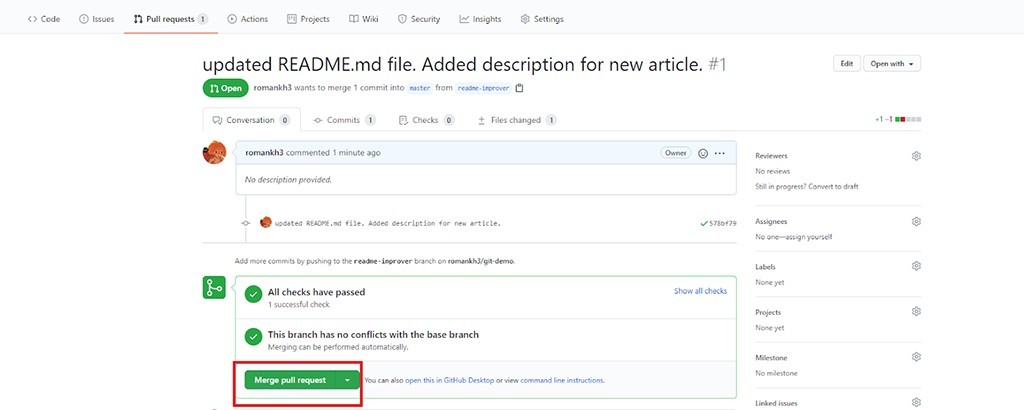
To wszystko!
GO TO FULL VERSION