1. Um guia detalhado do Git para iniciantes
Hoje vamos falar sobre um sistema de controle de versão, chamado Git.
Você realmente não pode ser um programador completo sem conhecer e entender esta ferramenta. Claro, você não precisa manter todos os comandos e recursos do Git em sua cabeça para ser empregado continuamente. Você precisa conhecer um conjunto de comandos que o ajudarão a entender tudo o que está acontecendo.
Noções básicas do Git
Git é um sistema de controle de versão distribuído para nosso código. Por que precisamos disso? As equipes precisam de algum tipo de sistema para gerenciar seu trabalho. É necessário rastrear as mudanças que ocorrem ao longo do tempo.
Ou seja, precisamos conseguir ver passo a passo quais arquivos foram alterados e como. Isso é especialmente importante quando você está investigando o que mudou no contexto de uma única tarefa, possibilitando a reversão das alterações.
Vamos imaginar a seguinte situação: temos um código funcionando, tudo nele está bom, mas aí resolvemos melhorar ou mexer em alguma coisa. Não é grande coisa, mas nossa "melhoria" quebrou metade dos recursos do programa e o impossibilitou de funcionar. E agora? Sem o Git, você teria que sentar e pensar por horas, tentando lembrar como tudo era originalmente. Mas com o Git, apenas revertemos o commit — e é isso.
Ou se houver dois desenvolvedores fazendo suas próprias alterações de código ao mesmo tempo? Sem o Git, eles copiam os arquivos de código originais e os modificam separadamente. Chega um momento em que ambos desejam adicionar suas alterações ao diretório principal. O que você faz neste caso?
Não haverá tais problemas se você usar o Git.
Instalando o Git
Vamos instalar o Java em seu computador Este processo difere ligeiramente para diferentes sistemas operacionais.
Instalando no Windows
Como de costume, você precisa baixar e executar um arquivo exe. Tudo é simples aqui: clique no primeiro link do Google , faça a instalação e pronto. Para fazer isso, usaremos o console bash fornecido pelo Windows.
No Windows, você precisa executar o Git Bash. Veja como fica no menu Iniciar:

Agora, este é um prompt de comando com o qual você pode trabalhar.
Para evitar ter que ir para a pasta com o projeto toda vez para abrir o Git lá, você pode abrir o prompt de comando na pasta do projeto com o botão direito do mouse com o caminho que precisamos:

Instalando no Linux
Normalmente, o Git faz parte das distribuições do Linux e já vem instalado, pois é uma ferramenta originalmente escrita para o desenvolvimento do kernel do Linux. Mas há situações em que não. Para verificar, você precisa abrir um terminal e escrever: git --version. Se você obtiver uma resposta inteligível, nada precisará ser instalado.
Abra um terminal e instale. Para o Ubuntu, você precisa escrever: sudo apt-get install git. E pronto: agora você pode usar o Git em qualquer terminal.
Instalando no macOS
Aqui, também, primeiro você precisa verificar se o Git já está lá (veja acima, o mesmo que no Linux).
Se você não o possui, a maneira mais fácil de obtê-lo é fazer o download da versão mais recente . Se o Xcode estiver instalado, o Git definitivamente será instalado automaticamente.
Configurações do Git
O Git possui configurações de usuário para o usuário que enviará o trabalho. Isso faz sentido e é necessário, porque o Git leva essas informações para o campo Autor quando um commit é criado.
Configure um nome de usuário e senha para todos os seus projetos executando os seguintes comandos:
Se você precisar alterar o autor de um projeto específico (para um projeto pessoal, por exemplo), poderá remover "--global". Isso nos dará o seguinte:
Um pouco de teoria
Para mergulhar no assunto, devemos apresentá-lo a algumas novas palavras e ações... Caso contrário, não haverá nada para falar. Claro, isso é um jargão que vem do inglês, então adicionarei as traduções entre parênteses.
Que palavras e ações?
- repositório git
- comprometer-se
- filial
- fundir
- conflitos
- puxar
- empurrar
- como ignorar alguns arquivos (.gitignore)
E assim por diante.
Status no Git
O Git possui várias estátuas que precisam ser compreendidas e lembradas:
- não rastreado
- modificado
- encenado
- empenhado
Como você deve entender isso?
Esses são os status que se aplicam aos arquivos que contêm nosso código. Em outras palavras, seu ciclo de vida geralmente se parece com isso:
- Um arquivo criado, mas ainda não adicionado ao repositório, tem o status "não rastreado".
- Quando fazemos alterações em arquivos que já foram adicionados ao repositório Git, seu status é "modificado".
- Entre os arquivos que alteramos, selecionamos aqueles de que precisamos (por exemplo, não precisamos de classes compiladas), e essas classes são alteradas para o status "encenado".
- Um commit é criado a partir de arquivos preparados no estado preparado e vai para o repositório Git. Depois disso, não há arquivos com o status "encenado". Mas ainda pode haver arquivos cujo status é "modificado".
Isto é o que parece:

O que é um commit?
Um commit é o evento principal quando se trata de controle de versão. Ele contém todas as alterações feitas desde o início do commit. Os commits são vinculados como uma lista vinculada individualmente.
Especificamente, há um primeiro commit. Quando o segundo commit é criado, ele (o segundo) sabe o que vem depois do primeiro. E desta forma, as informações podem ser rastreadas.
Um commit também tem suas próprias informações, os chamados metadados:
- o identificador exclusivo do commit, que pode ser usado para encontrá-lo
- o nome do autor do commit, que o criou
- a data em que o commit foi criado
- um comentário que descreve o que foi feito durante o commit
Veja como fica:

O que é um ramo?

Um branch é um ponteiro para algum commit. Como um commit sabe qual commit o precede, quando um branch aponta para um commit, todos os commits anteriores também se aplicam a ele.
Assim, podemos dizer que você pode ter quantas ramificações quiser apontando para o mesmo commit.
O trabalho acontece em branches, então quando um novo commit é criado, o branch move seu ponteiro para o commit mais recente.

Introdução ao Git
Você pode trabalhar apenas com um repositório local ou remoto.
Para praticar os comandos necessários, você pode limitar-se ao repositório local. Ele apenas armazena todas as informações do projeto localmente na pasta .git.
Se estivermos falando sobre o repositório remoto, todas as informações são armazenadas em algum lugar no servidor remoto: apenas uma cópia do projeto é armazenada localmente. As alterações feitas em sua cópia local podem ser enviadas (git push) para o repositório remoto.
Em nossa discussão aqui e abaixo, estamos falando sobre como trabalhar com o Git no console. Claro, você pode usar algum tipo de solução baseada em GUI (por exemplo, IntelliJ IDEA), mas primeiro você deve descobrir quais comandos estão sendo executados e o que eles significam.
Trabalhando com Git em um repositório local
Para criar um repositório local, você precisa escrever:

Isso criará uma pasta .git oculta no diretório atual do console.
A pasta .git armazena todas as informações sobre o repositório Git. Não apague ;)
Em seguida, os arquivos são adicionados ao projeto e recebem o status "Não rastreado". Para verificar o status atual do seu trabalho, escreva isto:
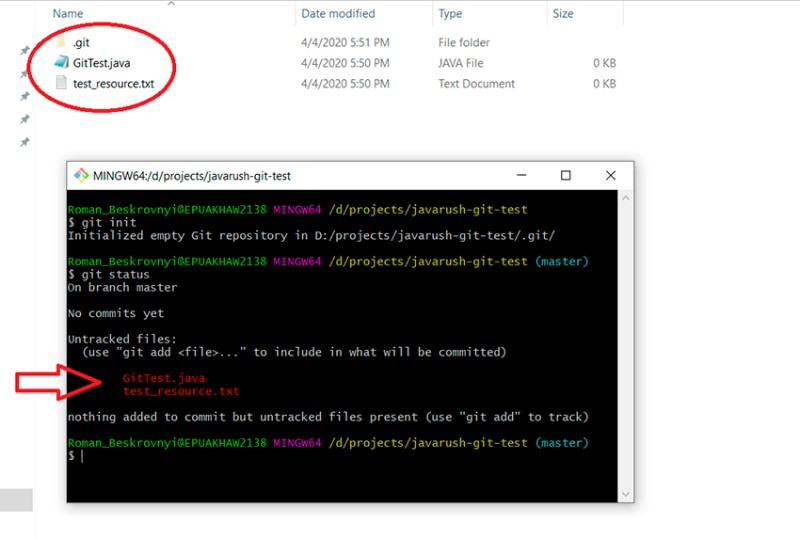
Estamos no branch master, e aqui permaneceremos até mudarmos para outro branch.
Isso mostra quais arquivos foram alterados, mas ainda não foram adicionados ao status "preparado". Para adicioná-los ao status "encenado", você precisa escrever "git add". Temos algumas opções aqui, por exemplo:
- git add -A — adiciona todos os arquivos ao status "encenado"
- adicionar git. — adicione todos os arquivos desta pasta e todas as subpastas. Essencialmente igual ao anterior;
- git add <file name> — adiciona um arquivo específico. Aqui você pode usar expressões regulares para adicionar arquivos de acordo com algum padrão. Por exemplo, git add *.java: Isso significa que você só deseja adicionar arquivos com a extensão java.
As duas primeiras opções são claramente simples. As coisas ficam mais interessantes com a última adição, então vamos escrever:
Para verificar o status, usamos o comando já conhecido por nós:

Aqui você pode ver que a expressão regular funcionou corretamente: test_resource.txt agora tem o status "staged".
E, finalmente, a última etapa para trabalhar com um repositório local (há mais uma ao trabalhar com o repositório remoto ;)) — criar um novo commit:

O próximo é um ótimo comando para olhar o histórico de commits em um branch. Vamos aproveitá-lo:

Aqui você pode ver que criamos nosso primeiro commit e inclui o texto que fornecemos na linha de comando. É muito importante entender que este texto deve explicar com a maior precisão possível o que foi feito durante este commit. Isso nos ajudará muitas vezes no futuro.
Um leitor curioso que ainda não dormiu pode estar se perguntando o que aconteceu com o arquivo GitTest.java. Vamos descobrir agora. Para fazer isso, usamos:

Como você pode ver, ainda está "não rastreado" e está esperando nos bastidores. Mas e se não quisermos adicioná-lo ao projeto? Às vezes isso acontece.
Para tornar as coisas mais interessantes, vamos agora tentar alterar nosso arquivo test_resource.txt. Vamos adicionar algum texto lá e verificar o status:

Aqui você pode ver claramente a diferença entre os status "não rastreado" e "modificado".
GitTest.java é "não rastreado", enquanto test_resource.txt é "modificado".
Agora que temos os arquivos no estado modificado, podemos examinar as alterações feitas neles. Isso pode ser feito usando o seguinte comando:

Ou seja, você pode ver claramente aqui o que adicionei ao nosso arquivo de texto: hello world!
Vamos adicionar nossas alterações ao arquivo de texto e criar um commit:
Para ver todos os commits, escreva:

Como você pode ver, agora temos dois commits.
Adicionaremos GitTest.java da mesma maneira. Sem comentários aqui, apenas comandos:

Trabalhando com .gitignore
Claramente, queremos apenas manter o código-fonte sozinho, e nada mais, no repositório. Então, o que mais poderia haver? No mínimo, classes compiladas e/ou arquivos gerados por ambientes de desenvolvimento.
Para dizer ao Git para ignorá-los, precisamos criar um arquivo especial. Faça o seguinte: crie um arquivo chamado .gitignore na raiz do projeto. Cada linha neste arquivo representa um padrão a ser ignorado.
Neste exemplo, o arquivo .gitignore ficará assim:
target/
*.iml
.idea/
Vamos dar uma olhada:
- A primeira linha é ignorar todos os arquivos com a extensão .class
- A segunda linha é ignorar a pasta "target" e tudo o que ela contém
- A terceira linha é ignorar todos os arquivos com a extensão .iml
- A quarta linha é ignorar a pasta .idea
Vamos tentar usar um exemplo. Para ver como funciona, vamos adicionar o GitTest.class compilado ao projeto e verificar o status do projeto:

Claramente, não queremos adicionar acidentalmente a classe compilada ao projeto (usando git add -A). Para fazer isso, crie um arquivo .gitignore e adicione tudo o que foi descrito anteriormente:

Agora vamos usar um commit para adicionar o arquivo .gitignore ao projeto:
E agora a hora da verdade: temos uma classe compilada GitTest.class que é "não rastreada", que não queremos adicionar ao repositório Git.
Agora devemos ver os efeitos do arquivo .gitignore:

Perfeito! .gitignore +1 :)
Trabalhando com filiais
Naturalmente, trabalhar em apenas uma ramificação é inconveniente para desenvolvedores solitários e é impossível quando há mais de uma pessoa em uma equipe. É por isso que temos filiais.
Um branch é apenas um ponteiro móvel para commits.
Nesta parte, exploraremos o trabalho em diferentes branches: como mesclar alterações de um branch em outro, quais conflitos podem surgir e muito mais.
Para ver uma lista de todos os branches no repositório e entender em qual deles você está, você precisa escrever:

Você pode ver que temos apenas um branch master. O asterisco na frente indica que estamos nele. A propósito, você também pode usar o comando "git status" para descobrir em qual ramificação estamos.
Então existem várias opções para criar branches (pode haver mais — essas são as que eu uso):
- criar um novo ramo baseado naquele em que estamos (99% dos casos)
- criar uma ramificação com base em um commit específico (1% dos casos)
Vamos criar um branch baseado em um commit específico
Contaremos com o identificador exclusivo do commit. Para encontrá-lo, escrevemos:

Destacamos o commit com o comentário "added hello world..." Seu identificador único é 6c44e53d06228f888f2f454d3cb8c1c976dd73f8. Queremos criar uma ramificação de "desenvolvimento" que comece a partir deste commit. Para isso, escrevemos:
Um branch é criado apenas com os dois primeiros commits do branch master. Para verificar isso, primeiro nos certificamos de mudar para um branch diferente e olhar o número de commits lá:

E como esperado, temos dois commits. A propósito, aqui está um ponto interessante: ainda não há nenhum arquivo .gitignore neste branch, então nosso arquivo compilado (GitTest.class) agora está destacado com o status "untracked".
Agora podemos revisar nossos ramos novamente escrevendo isto:
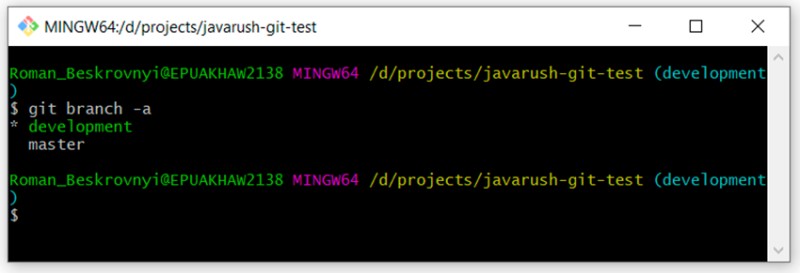
Você pode ver que existem duas ramificações: "mestre" e "desenvolvimento". Estamos atualmente em desenvolvimento.
Vamos criar um branch baseado no atual
A segunda maneira de criar uma ramificação é criá-la a partir de outra. Queremos criar um branch baseado no branch master. Primeiro, precisamos mudar para ele e o próximo passo é criar um novo. Vamos dar uma olhada:
- git checkout master — mude para o branch master
- git status — verifique se estamos realmente na ramificação master

Aqui você pode ver que mudamos para a ramificação master, o arquivo .gitignore está em vigor e a classe compilada não está mais destacada como "não rastreada".
Agora criamos um novo branch baseado no branch master:

Se você não tem certeza se este branch é o mesmo que "master", você pode verificar facilmente executando "git log" e observando todos os commits. Deve haver quatro deles.
Resolução de conflitos
Antes de explorarmos o que é um conflito, precisamos falar sobre a fusão de um ramo em outro.
Esta imagem descreve o processo de fusão de um ramo em outro:

Aqui, temos um ramo principal. Em algum momento, uma ramificação secundária é criada a partir da ramificação principal e depois modificada. Depois que o trabalho estiver concluído, precisamos mesclar um ramo no outro.
Em nosso exemplo, criamos o branch feature/update-txt-files. Conforme indicado pelo nome da ramificação, estamos atualizando o texto.

Agora precisamos criar um novo commit para este trabalho:

Agora, se quisermos mesclar o branch feature/update-txt-files no master, precisamos ir para master e escrever "git merge feature/update-txt-files":

Como resultado, o branch master agora também inclui o commit que foi adicionado aos arquivos feature/update-txt.
Essa funcionalidade foi adicionada para que você possa excluir uma ramificação de recurso. Para isso, escrevemos:
Vamos complicar a situação: agora digamos que você precise alterar o arquivo txt novamente. Mas agora esse arquivo também será alterado na ramificação master. Em outras palavras, ele mudará em paralelo. O Git não será capaz de descobrir o que fazer quando quisermos mesclar nosso novo código no branch master.
Criaremos um novo branch baseado no master, faremos alterações em text_resource.txt e criaremos um commit para este trabalho:
... fazemos alterações no arquivo


Vá para o branch master e também atualize este arquivo de texto na mesma linha do branch do recurso:
… atualizamos test_resource.txt

E agora o ponto mais interessante: precisamos mesclar as alterações do branch feature/add-header para master. Estamos no branch master, então só precisamos escrever:
Mas o resultado será um conflito no arquivo test_resource.txt:

Aqui podemos ver que o Git não conseguiu decidir sozinho como mesclar esse código. Ele nos diz que precisamos resolver o conflito primeiro e só então realizar o commit.
OK. Abrimos o arquivo com o conflito em um editor de texto e vemos:

Para entender o que o Git fez aqui, precisamos lembrar quais mudanças fizemos e onde, e então comparar:
- As alterações que estavam nesta linha no branch master são encontradas entre "<<<<<<< HEAD" e "=======".
- As mudanças que estavam na ramificação feature/add-header são encontradas entre "=======" e ">>>>>>> feature/add-header".
É assim que o Git nos informa que não conseguiu descobrir como realizar a mesclagem neste local do arquivo. Ele dividiu esta seção em duas partes dos diferentes ramos e nos convida a resolver o conflito de mesclagem por conta própria.
Justo. Decido remover tudo com ousadia, deixando apenas a palavra "cabeçalho":

Vejamos o status das alterações. A descrição será um pouco diferente. Em vez de um status "modificado", temos "não mesclado". Então, poderíamos ter mencionado um quinto status? Eu não acho que isso seja necessário. Vamos ver:

Podemos nos convencer de que este é um caso especial e incomum. Vamos continuar:

Você pode notar que a descrição sugere escrever apenas "git commit". Vamos tentar escrever isso:

E assim fizemos - resolvemos o conflito no console.
Claro, isso pode ser feito um pouco mais facilmente em ambientes de desenvolvimento integrado. Por exemplo, no IntelliJ IDEA, tudo é configurado tão bem que você pode realizar todas as ações necessárias dentro dele. Mas os IDEs fazem muitas coisas "sob o capô" e muitas vezes não entendemos exatamente o que está acontecendo lá. E quando não há compreensão, podem surgir problemas.
Trabalhando com repositórios remotos
A última etapa é descobrir mais alguns comandos necessários para trabalhar com o repositório remoto.
Como eu disse, um repositório remoto é algum lugar onde o repositório é armazenado e de onde você pode cloná-lo.
Que tipo de repositórios remotos existem? Exemplos:
- O GitHub é a maior plataforma de armazenamento para repositórios e desenvolvimento colaborativo.
- O GitLab é uma ferramenta baseada na Web para o ciclo de vida do DevOps com código aberto. É um sistema baseado em Git para gerenciar repositórios de código com seu próprio wiki, sistema de rastreamento de bugs, pipeline de CI/CD e outras funções.
- BitBucket é um serviço web para hospedagem de projetos e desenvolvimento colaborativo baseado nos sistemas de controle de versão Mercurial e Git. Ao mesmo tempo, ele tinha uma grande vantagem sobre o GitHub, pois oferecia repositórios privados gratuitos. No ano passado, o GitHub também introduziu esse recurso gratuitamente para todos.
- E assim por diante…
Ao trabalhar com um repositório remoto, a primeira coisa a fazer é clonar o projeto em seu repositório local.
Para isso, exportamos o projeto que fizemos localmente Agora todos podem cloná-lo escrevendo:
Existe agora uma cópia local completa do projeto. Para ter certeza de que a cópia local do projeto é a mais recente, você precisa obter o projeto escrevendo:

No nosso caso, nada mudou no repositório remoto no momento, então a resposta é: Já atualizado.
Mas se fizermos qualquer alteração no repositório remoto, o local é atualizado depois que os extraímos.
E, finalmente, o último comando é enviar os dados para o repositório remoto. Quando tivermos feito algo localmente e quisermos enviá-lo para o repositório remoto, devemos primeiro criar um novo commit localmente. Para demonstrar isso, vamos adicionar algo mais ao nosso arquivo de texto:

Agora algo bastante comum para nós — criamos um commit para este trabalho:
O comando para enviar isso para o repositório remoto é:
Por enquanto é isso!
| Links Úteis |
|---|
|
2. Como trabalhar com Git no IntelliJ IDEA
Nesta parte, você aprenderá como trabalhar com o Git no IntelliJ IDEA.
Entradas necessárias:
- Leia, acompanhe e entenda a parte anterior. Isso ajudará a garantir que tudo esteja configurado e pronto para uso.
- Instale o IntelliJ IDEA. Tudo deve estar em ordem aqui :)
- Aloque uma hora para alcançar o domínio completo.
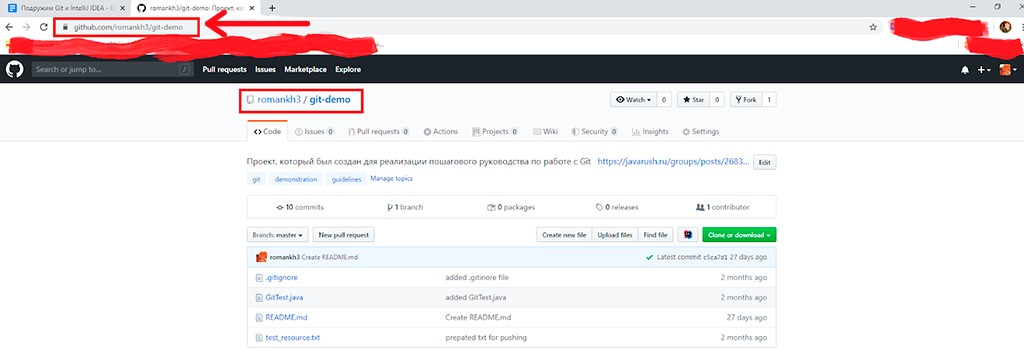
Vamos trabalhar com o projeto de demonstração que usei para o artigo sobre Git.
Clone o projeto localmente
Existem duas opções aqui:
- Se você já possui uma conta do GitHub e deseja enviar algo posteriormente, é melhor fazer um fork do projeto e clonar sua própria cópia. Você pode ler sobre como criar uma bifurcação em outro artigo sob o título Um exemplo do fluxo de trabalho de bifurcação .
- Clone o repositório e faça tudo localmente sem a capacidade de enviar tudo para o servidor.
Para clonar um projeto do GitHub, você precisa copiar o link do projeto e passá-lo para o IntelliJ IDEA:
-
Copie o endereço do projeto:
![]()
-
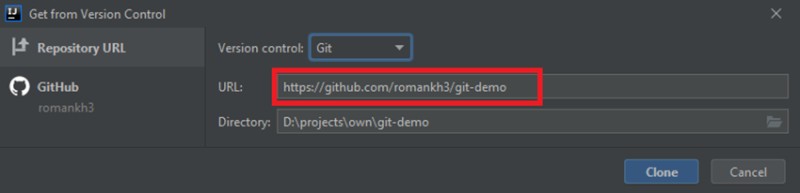
Abra o IntelliJ IDEA e selecione "Obter do controle de versão":
![]()
-
Copie e cole o endereço do projeto:
![]()
-
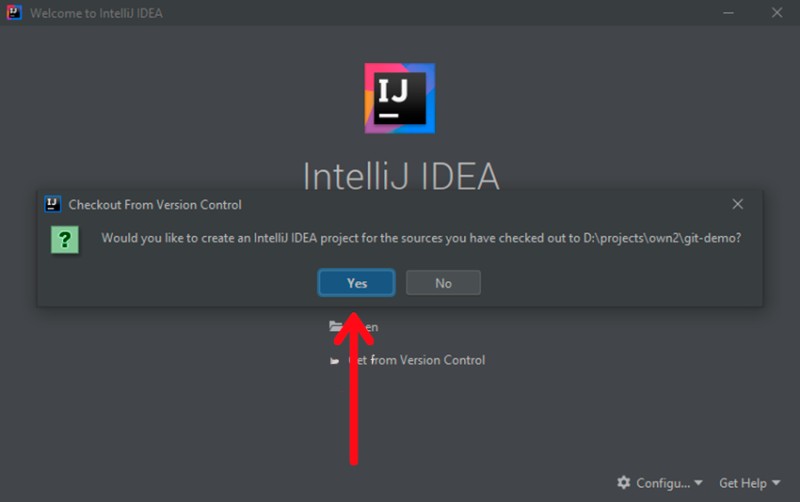
Você será solicitado a criar um projeto IntelliJ IDEA. Aceite a oferta:
![]()
-
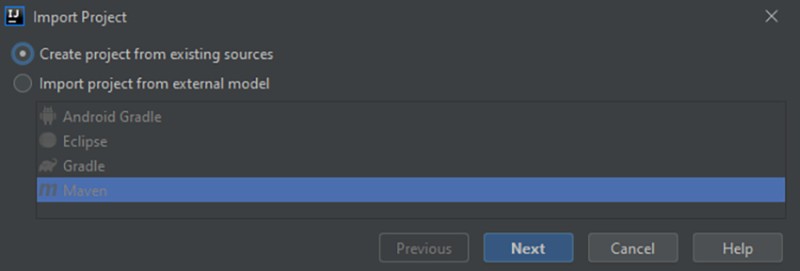
Como não há sistema de compilação, selecionamos "Criar projeto a partir de fontes existentes":
![]()
-
Em seguida, você verá esta bela tela:
![]()

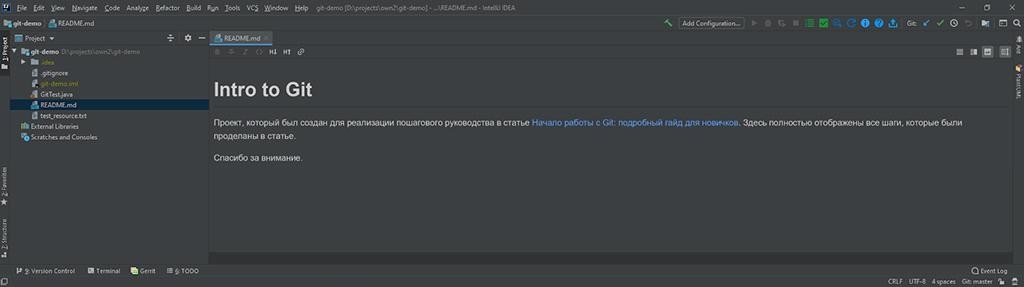
Agora que descobrimos a clonagem, você pode dar uma olhada.
Primeira olhada no IntelliJ IDEA como uma interface do Git
Dê uma olhada no projeto clonado: você já pode obter muitas informações sobre o sistema de controle de versão.
Primeiro, temos o painel Controle de versão no canto inferior esquerdo. Aqui você pode encontrar todas as alterações locais e obter uma lista de commits (análogo a "git log").
Vamos passar para uma discussão sobre Log. Existe uma certa visualização que nos ajuda a entender exatamente como o desenvolvimento ocorreu. Por exemplo, você pode ver que uma nova ramificação foi criada com um cabeçalho adicionado ao txt commit, que foi mesclado na ramificação principal. Se você clicar em um commit, poderá ver no canto direito todas as informações sobre o commit: todas as suas alterações e metadados.
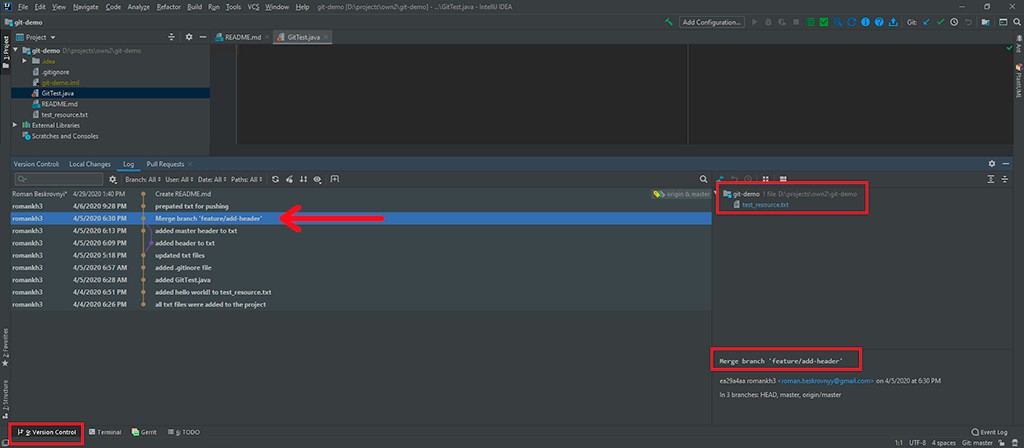
Além disso, você pode ver as mudanças reais. Também vemos que um conflito foi resolvido lá. IDEA também apresenta isso muito bem.
Se você clicar duas vezes no arquivo que foi alterado durante este commit, veremos como o conflito foi resolvido:

Notamos que à esquerda e à direita temos as duas versões do mesmo arquivo que precisavam ser mescladas em uma só. E no meio, temos o resultado final da mesclagem.
Quando um projeto tem muitos branches, commits e usuários, você precisa pesquisar separadamente por branch, usuário e data:

Antes de começar, também vale a pena explicar como entender em qual ramo estamos.
No canto inferior direito, há um botão chamado "Git: master". O que vem depois de "Git:" é o branch atual. Se você clicar no botão, poderá fazer muitas coisas úteis: alternar para outra ramificação, criar uma nova, renomear uma existente e assim por diante.

Trabalhando com um repositório
Teclas de atalho úteis
Para trabalhos futuros, você precisa se lembrar de algumas teclas de atalho muito úteis:
- CTRL+T — Obtenha as alterações mais recentes do repositório remoto (git pull).
- CTRL+K — Criar um commit/ver todas as alterações atuais. Isso inclui arquivos não rastreados e modificados (git commit).
- CTRL+SHIFT+K — Este é o comando para enviar alterações para o repositório remoto. Todos os commits criados localmente e ainda não no repositório remoto serão enviados (git push).
- ALT+CTRL+Z — Reverte alterações em um arquivo específico para o estado do último commit criado no repositório local. Se você selecionar todo o projeto no canto superior esquerdo, poderá reverter as alterações em todos os arquivos.
O que queremos?
Para fazer o trabalho, precisamos dominar um cenário básico que é usado em todos os lugares.
O objetivo é implementar uma nova funcionalidade em uma ramificação separada e, em seguida, enviá-la para um repositório remoto (você também precisa criar uma solicitação pull para a ramificação principal, mas isso está além do escopo desta lição).
O que é necessário para fazer isso?
-
Obtenha todas as alterações atuais na ramificação principal (por exemplo, "mestre").
-
A partir desta ramificação principal, crie uma ramificação separada para o seu trabalho.
-
Implemente a nova funcionalidade.
-
Vá para o ramo principal e verifique se houve novas alterações enquanto estávamos trabalhando. Se não, então está tudo bem. Mas se houve alterações, fazemos o seguinte: vamos para o ramo de trabalho e rebase as alterações do ramo principal para o nosso. Se tudo der certo, ótimo. Mas é perfeitamente possível que haja conflitos. Acontece que eles podem ser resolvidos antecipadamente, sem perder tempo no repositório remoto.
Você está se perguntando por que deveria fazer isso? É uma boa educação e evita que ocorram conflitos depois de enviar sua ramificação para o repositório local (há, é claro, a possibilidade de que ainda ocorram conflitos, mas eles se tornam muito menores ).
-
Envie suas alterações para o repositório remoto.
Como obter alterações do servidor remoto?
Adicionamos uma descrição ao README com um novo commit e queremos obter essas alterações. Se as alterações foram feitas tanto no repositório local quanto no remoto, somos convidados a escolher entre uma mesclagem e um rebase. Nós escolhemos nos fundir.
Digite CTRL+T :

Agora você pode ver como o README mudou, ou seja, as alterações do repositório remoto foram obtidas e, no canto inferior direito, você pode ver todos os detalhes das alterações que vieram do servidor.

Crie uma nova ramificação com base no mestre
Tudo é simples aqui.
Vá para o canto inferior direito e clique em Git: master . Selecione + Nova filial .
 Deixe a caixa de seleção Filial do caixa marcada e digite o nome da nova filial. No nosso caso: será readme-improver .
Deixe a caixa de seleção Filial do caixa marcada e digite o nome da nova filial. No nosso caso: será readme-improver .
Git: master mudará para Git: readme-improver .
Vamos simular um trabalho paralelo
Para que os conflitos apareçam, alguém tem que criá-los.
Vamos editar o README com um novo commit pelo navegador, simulando assim o trabalho paralelo. É como se alguém tivesse feito alterações no mesmo arquivo enquanto trabalhávamos nele. O resultado será um conflito. Vamos remover a palavra "fully" da linha 10.
Implemente nossa funcionalidade
Nossa tarefa é alterar o README e adicionar uma descrição ao novo artigo. Ou seja, o trabalho no Git passa pelo IntelliJ IDEA. Adicione isso:

As mudanças estão feitas. Agora podemos criar um commit. Pressione CTRL+K , o que nos dá:

Antes de criar um commit, precisamos dar uma olhada no que esta janela oferece.
Na seção Mensagem de confirmação , escrevemos o texto associado à confirmação. Então, para criá-lo, precisamos clicar em Commit .
Escrevemos que o README mudou e criamos o commit. Um alerta aparece no canto inferior esquerdo com o nome do commit:

Verifique se o ramo principal mudou
Concluímos nossa tarefa. Funciona. Nós escrevemos testes. Tudo está bem. Mas antes de enviar para o servidor, ainda precisamos verificar se houve alguma alteração no ramo principal nesse meio tempo. Como isso pode acontecer? Muito facilmente: alguém recebe uma tarefa depois de você e esse alguém a termina mais rápido do que você termina sua tarefa.
Então, precisamos ir para o branch master. Para fazer isso, precisamos fazer o que é mostrado no canto inferior direito na captura de tela abaixo:

Na ramificação master, pressione CTRL+T para obter as alterações mais recentes do servidor remoto. Olhando para o que mudou, você pode ver facilmente o que aconteceu:

A palavra "fully" foi removida. Talvez alguém do marketing tenha decidido que não deveria ser escrito assim e deu aos desenvolvedores a tarefa de atualizá-lo.
Agora temos uma cópia local da última versão do branch master. Volte para readme-improver .
Agora precisamos rebasear as alterações do branch master para o nosso. Nós fazemos isso: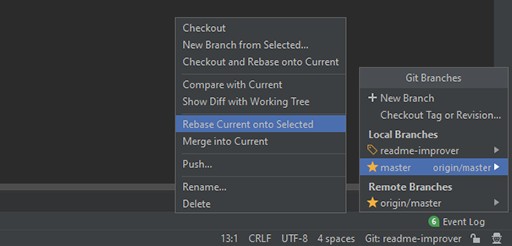
Se você fez tudo certo e me acompanhou, o resultado deve mostrar um conflito no arquivo README:

Aqui também temos muita informação para entender e absorver. Aqui é mostrada uma lista de arquivos (no nosso caso, um arquivo) que possuem conflitos. Podemos escolher entre três opções:
- aceite o seu — aceite apenas as alterações do readme-improver.
- aceite as deles — aceite apenas alterações do mestre.
- mesclar — escolha você mesmo o que deseja manter e o que descartar.
Não está claro o que mudou. Se houver alterações no branch master, elas devem ser necessárias lá, portanto, não podemos simplesmente aceitar nossas alterações. Assim, selecionamos merge :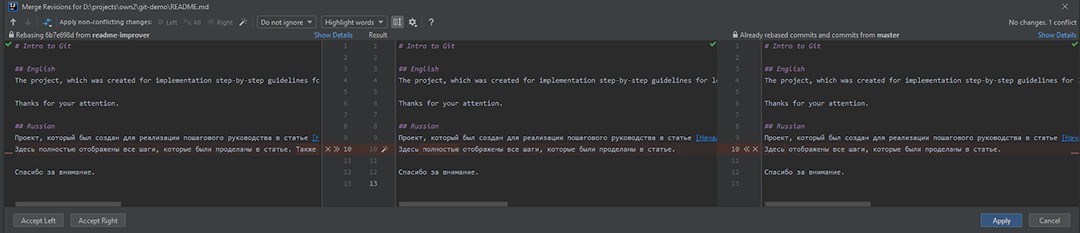
Aqui podemos ver que existem três partes:
- Estas são as alterações do readme-improver.
- O resultado mesclado. Por enquanto, é o que existia antes das mudanças.
- As alterações do branch master.
Precisamos produzir um resultado mesclado que satisfaça a todos. Revendo o que foi alterado ANTES de nossas alterações, percebemos que eles simplesmente removeram a palavra "fully". Ok sem problemas! Isso significa que também o removeremos no resultado mesclado e adicionaremos nossas alterações. Depois de corrigir o resultado mesclado, podemos clicar em Aplicar .
Em seguida, uma notificação será exibida, informando que o rebase foi bem-sucedido:

Lá! Resolvemos nosso primeiro conflito por meio do IntelliJ IDEA.
Enviar alterações para o servidor remoto
A próxima etapa é enviar as alterações para o servidor remoto e criar uma solicitação pull. Para fazer isso, basta pressionar CTRL+SHIFT+K . Então obtemos:

À esquerda, haverá uma lista de commits que não foram enviados para o repositório remoto. À direita estarão todos os arquivos que foram alterados. E é isso! Pressione Push e você experimentará a felicidade :)
Se o push for bem-sucedido, você verá uma notificação como esta no canto inferior direito:

Bônus: criando uma solicitação pull
Vamos a um repositório GitHub e vemos que o GitHub já sabe o que queremos:

Clique em Compare & pull request . Em seguida, clique em Criar solicitação pull . Como resolvemos os conflitos com antecedência, agora ao criar um pull request podemos imediatamente fazer um merge dele: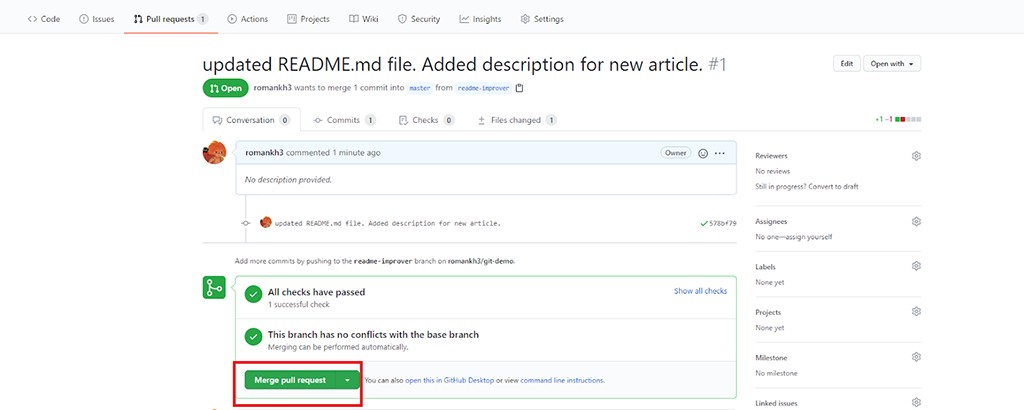
Por enquanto é isso!
GO TO FULL VERSION