1. Eine ausführliche Anleitung zu Git für Anfänger
Heute sprechen wir über ein Versionskontrollsystem, nämlich Git.
Man kann wirklich kein vollwertiger Programmierer sein, ohne dieses Tool zu kennen und zu verstehen. Natürlich müssen Sie nicht alle Git-Befehle und -Funktionen im Kopf behalten, um kontinuierlich eingesetzt zu werden. Sie müssen eine Reihe von Befehlen kennen, die Ihnen helfen, alles zu verstehen, was passiert.
Git-Grundlagen
Git ist ein verteiltes Versionskontrollsystem für unseren Code. Warum brauchen wir es? Teams benötigen eine Art System zur Verwaltung ihrer Arbeit. Es ist erforderlich, Änderungen zu verfolgen, die im Laufe der Zeit auftreten.
Das heißt, wir müssen Schritt für Schritt sehen können, welche Dateien sich wie geändert haben. Dies ist besonders wichtig, wenn Sie untersuchen, was sich im Kontext einer einzelnen Aufgabe geändert hat, damit die Änderungen rückgängig gemacht werden können.
Stellen wir uns die folgende Situation vor: Wir haben funktionierenden Code, alles darin ist gut, aber dann entscheiden wir uns, etwas zu verbessern oder zu optimieren. Keine große Sache, aber unsere „Verbesserung“ hat die Hälfte der Funktionen des Programms kaputt gemacht und es unmöglich gemacht, zu arbeiten. Was nun? Ohne Git müssten Sie stundenlang herumsitzen und nachdenken und versuchen, sich daran zu erinnern, wie alles ursprünglich war. Aber mit Git setzen wir einfach den Commit zurück – und das war's.
Oder was ist, wenn zwei Entwickler gleichzeitig ihre eigenen Codeänderungen vornehmen? Ohne Git kopieren sie die ursprünglichen Codedateien und ändern sie separat. Es kommt der Zeitpunkt, an dem beide ihre Änderungen zum Hauptverzeichnis hinzufügen möchten. Was machen Sie in diesem Fall?
Wenn Sie Git verwenden, treten solche Probleme nicht auf.
Git installieren
Lassen Sie uns Java auf Ihrem Computer installieren. Dieser Vorgang unterscheidet sich geringfügig für verschiedene Betriebssysteme.
Installation unter Windows
Wie üblich müssen Sie eine exe-Datei herunterladen und ausführen. Hier ist alles ganz einfach: Klicken Sie auf den ersten Google-Link , führen Sie die Installation durch und fertig. Dazu verwenden wir die von Windows bereitgestellte Bash-Konsole.
Unter Windows müssen Sie Git Bash ausführen. So sieht es im Startmenü aus:

Dies ist nun eine Eingabeaufforderung, mit der Sie arbeiten können.
Um nicht jedes Mal in den Ordner mit dem Projekt gehen zu müssen, um dort Git zu öffnen, können Sie mit der rechten Maustaste die Eingabeaufforderung im Projektordner mit dem von uns benötigten Pfad öffnen:

Installation unter Linux
Normalerweise ist Git Teil von Linux-Distributionen und bereits installiert, da es sich um ein Tool handelt, das ursprünglich für die Linux-Kernel-Entwicklung geschrieben wurde. Aber es gibt Situationen, in denen das nicht der Fall ist. Um dies zu überprüfen, müssen Sie ein Terminal öffnen und Folgendes schreiben: git --version. Wenn Sie eine verständliche Antwort erhalten, muss nichts installiert werden.
Öffnen Sie ein Terminal und installieren Sie es. Für Ubuntu müssen Sie schreiben: sudo apt-get install git. Und das war's: Jetzt können Sie Git in jedem Terminal verwenden.
Installation unter macOS
Auch hier muss zunächst geprüft werden, ob Git bereits vorhanden ist (siehe oben, das gleiche wie unter Linux).
Wenn Sie es nicht haben, können Sie es am einfachsten herunterladen, indem Sie die neueste Version herunterladen . Wenn Xcode installiert ist, wird Git definitiv automatisch installiert.
Git-Einstellungen
Git verfügt über Benutzereinstellungen für den Benutzer, der Arbeiten einreichen wird. Dies ist sinnvoll und notwendig, da Git diese Informationen beim Erstellen eines Commits für das Feld „Autor“ übernimmt.
Richten Sie einen Benutzernamen und ein Passwort für alle Ihre Projekte ein, indem Sie die folgenden Befehle ausführen:
Wenn Sie den Autor für ein bestimmtes Projekt ändern müssen (z. B. für ein persönliches Projekt), können Sie „--global“ entfernen. Dadurch erhalten wir Folgendes:
Ein bisschen Theorie
Um tiefer in das Thema einzutauchen, sollten wir Ihnen ein paar neue Wörter und Taten vorstellen... Sonst gibt es nichts zu besprechen. Das ist natürlich eine Fachsprache, die wir aus dem Englischen kennen, daher füge ich die Übersetzungen in Klammern hinzu.
Welche Worte und Taten?
- Git-Repository
- begehen
- Zweig
- verschmelzen
- Konflikte
- ziehen
- drücken
- So ignorieren Sie einige Dateien (.gitignore)
Usw.
Status in Git
Git hat mehrere Statuen, die verstanden und erinnert werden müssen:
- nicht verfolgt
- geändert
- inszeniert
- engagiert
Wie soll man das verstehen?
Dies sind Status, die für die Dateien gelten, die unseren Code enthalten. Mit anderen Worten: Ihr Lebenszyklus sieht normalerweise so aus:
- Eine Datei, die erstellt, aber noch nicht zum Repository hinzugefügt wurde, hat den Status „nicht verfolgt“.
- Wenn wir Änderungen an Dateien vornehmen, die bereits zum Git-Repository hinzugefügt wurden, ist ihr Status „geändert“.
- Unter den Dateien, die wir geändert haben, wählen wir diejenigen aus, die wir benötigen (wir benötigen beispielsweise keine kompilierten Klassen) und diese Klassen werden in den Status „bereitgestellt“ geändert.
- Ein Commit wird aus vorbereiteten Dateien im bereitgestellten Zustand erstellt und in das Git-Repository verschoben. Danach gibt es keine Dateien mit dem Status „bereitgestellt“. Es können aber dennoch Dateien vorhanden sein, deren Status „geändert“ ist.
So sieht es aus:

Was ist ein Commit?
Ein Commit ist das Hauptereignis bei der Versionskontrolle. Es enthält alle Änderungen, die seit Beginn des Commits vorgenommen wurden. Commits sind wie eine einfach verknüpfte Liste miteinander verknüpft.
Konkret gibt es einen ersten Commit. Wenn der zweite Commit erstellt wird, weiß er (der zweite), was nach dem ersten kommt. Und auf diese Weise können Informationen nachverfolgt werden.
Ein Commit verfügt auch über eigene Informationen, sogenannte Metadaten:
- die eindeutige Kennung des Commits, die zum Auffinden des Commits verwendet werden kann
- der Name des Autors des Commits, der es erstellt hat
- das Datum, an dem der Commit erstellt wurde
- ein Kommentar, der beschreibt, was während des Commits getan wurde
So sieht es aus:

Was ist eine Filiale?

Ein Branch ist ein Zeiger auf einen Commit. Da ein Commit weiß, welcher Commit ihm vorangeht, gelten alle vorherigen Commits auch für ihn, wenn ein Zweig auf einen Commit verweist.
Dementsprechend könnten wir sagen, dass Sie beliebig viele Zweige haben können, die auf denselben Commit verweisen.
Die Arbeit erfolgt in Zweigen. Wenn also ein neuer Commit erstellt wird, verschiebt der Zweig seinen Zeiger auf den neueren Commit.
Erste Schritte mit Git
Sie können sowohl mit einem lokalen Repository allein als auch mit einem Remote-Repository arbeiten.
Um die erforderlichen Befehle zu üben, können Sie sich auf das lokale Repository beschränken. Es speichert lediglich alle Projektinformationen lokal im .git-Ordner.

Wenn wir über das Remote-Repository sprechen, werden alle Informationen irgendwo auf dem Remote-Server gespeichert: Nur eine Kopie des Projekts wird lokal gespeichert. An Ihrer lokalen Kopie vorgenommene Änderungen können per Push (Git Push) in das Remote-Repository übertragen werden.
In unserer Diskussion hier und unten sprechen wir über die Arbeit mit Git in der Konsole. Natürlich können Sie eine Art GUI-basierte Lösung verwenden (z. B. IntelliJ IDEA), aber zunächst sollten Sie herausfinden, welche Befehle ausgeführt werden und was sie bedeuten.
Arbeiten mit Git in einem lokalen Repository
Um ein lokales Repository zu erstellen, müssen Sie Folgendes schreiben:

Dadurch wird ein versteckter .git-Ordner im aktuellen Verzeichnis der Konsole erstellt.
Im .git-Ordner werden alle Informationen zum Git-Repository gespeichert. Nicht löschen ;)
Als nächstes werden Dateien zum Projekt hinzugefügt und ihnen wird der Status „Untracked“ zugewiesen. Um den aktuellen Status Ihrer Arbeit zu überprüfen, schreiben Sie Folgendes:
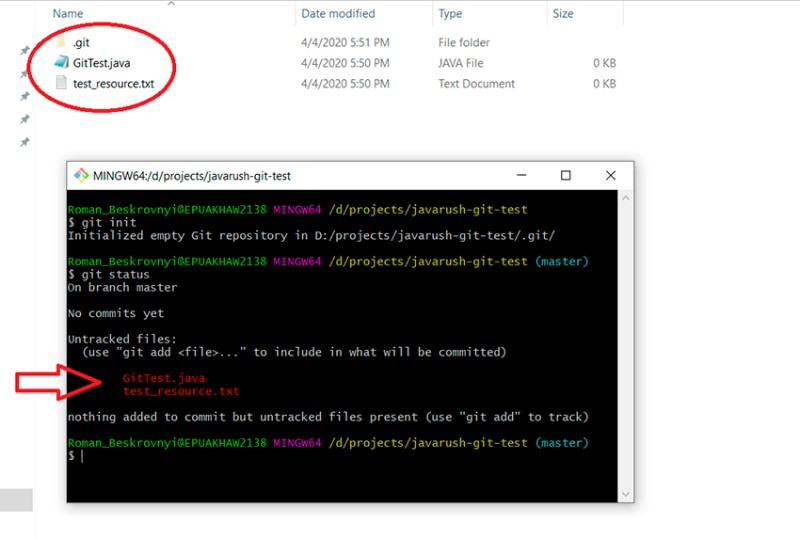
Wir befinden uns im Hauptzweig und bleiben hier, bis wir in einen anderen Zweig wechseln.
Hier wird angezeigt, welche Dateien geändert wurden, aber noch nicht in den Status „bereitgestellt“ aufgenommen wurden. Um ihnen den Status „staged“ hinzuzufügen, müssen Sie „git add“ schreiben. Hier haben wir einige Möglichkeiten, zum Beispiel:
- git add -A – fügt allen Dateien den Status „bereitgestellt“ hinzu
- git add . – Alle Dateien aus diesem Ordner und allen Unterordnern hinzufügen. Im Wesentlichen das Gleiche wie das vorherige;
- git add <Dateinamen> – fügt eine bestimmte Datei hinzu. Hier können Sie reguläre Ausdrücke verwenden, um Dateien nach einem bestimmten Muster hinzuzufügen. Beispiel: git add *.java: Dies bedeutet, dass Sie nur Dateien mit der Java-Erweiterung hinzufügen möchten.
Die ersten beiden Optionen sind eindeutig einfach. Mit der neuesten Ergänzung wird es noch interessanter, also schreiben wir:
Um den Status zu überprüfen, verwenden wir den uns bereits bekannten Befehl:

Hier sehen Sie, dass der reguläre Ausdruck korrekt funktioniert hat: test_resource.txt hat nun den Status „staged“.
Und schließlich der letzte Schritt für die Arbeit mit einem lokalen Repository (bei der Arbeit mit dem Remote-Repository gibt es noch einen weiteren ;)) – Erstellen eines neuen Commits:

Als nächstes folgt ein großartiger Befehl zum Betrachten des Commit-Verlaufs in einem Zweig. Nutzen wir es:

Hier können Sie sehen, dass wir unser erstes Commit erstellt haben und es den Text enthält, den wir in der Befehlszeile bereitgestellt haben. Es ist sehr wichtig zu verstehen, dass dieser Text so genau wie möglich erklären sollte, was während dieses Commits getan wurde. Das wird uns in Zukunft noch oft helfen.
Ein neugieriger Leser, der noch nicht eingeschlafen ist, fragt sich vielleicht, was mit der Datei GitTest.java passiert ist. Finden wir es gleich heraus. Dazu verwenden wir:

Wie Sie sehen können, ist es noch „unverfolgt“ und wartet in den Startlöchern. Aber was ist, wenn wir es überhaupt nicht zum Projekt hinzufügen möchten? Manchmal passiert das.
Um die Sache interessanter zu machen, versuchen wir nun, unsere Datei test_resource.txt zu ändern. Fügen wir dort etwas Text hinzu und überprüfen Sie den Status:

Hier erkennt man deutlich den Unterschied zwischen den Status „untracked“ und „modified“.
GitTest.java ist „untracked“, während test_resource.txt „modified“ ist.
Da sich die Dateien nun im geänderten Zustand befinden, können wir die daran vorgenommenen Änderungen untersuchen. Dies kann mit dem folgenden Befehl erfolgen:

Das heißt, Sie können hier deutlich sehen, was ich unserer Textdatei hinzugefügt habe: Hallo Welt!
Fügen wir unsere Änderungen zur Textdatei hinzu und erstellen einen Commit:
Um alle Commits anzuzeigen, schreiben Sie:

Wie Sie sehen, haben wir jetzt zwei Commits.
Wir werden GitTest.java auf die gleiche Weise hinzufügen. Keine Kommentare hier, nur Befehle:

Arbeiten mit .gitignore
Natürlich möchten wir nur den Quellcode und nichts anderes im Repository behalten. Was könnte es sonst noch sein? Zumindest kompilierte Klassen und/oder Dateien, die von Entwicklungsumgebungen generiert wurden.
Um Git anzuweisen, sie zu ignorieren, müssen wir eine spezielle Datei erstellen. Gehen Sie folgendermaßen vor: Erstellen Sie eine Datei mit dem Namen .gitignore im Stammverzeichnis des Projekts. Jede Zeile in dieser Datei stellt ein Muster dar, das ignoriert werden soll.
In diesem Beispiel sieht die .gitignore-Datei so aus:
target/
*.iml
.idea/
Lass uns einen Blick darauf werfen:
- Die erste Zeile besteht darin, alle Dateien mit der Erweiterung .class zu ignorieren
- Die zweite Zeile besteht darin, den Ordner „Ziel“ und alles, was er enthält, zu ignorieren
- Die dritte Zeile besteht darin, alle Dateien mit der Erweiterung .iml zu ignorieren
- Die vierte Zeile dient zum Ignorieren des .idea-Ordners
Versuchen wir es anhand eines Beispiels. Um zu sehen, wie es funktioniert, fügen wir die kompilierte GitTest.class zum Projekt hinzu und überprüfen den Projektstatus:

Natürlich möchten wir die kompilierte Klasse nicht versehentlich zum Projekt hinzufügen (mithilfe von git add -A). Erstellen Sie dazu eine .gitignore-Datei und fügen Sie alles hinzu, was zuvor beschrieben wurde:

Jetzt verwenden wir einen Commit, um die .gitignore-Datei zum Projekt hinzuzufügen:
Und jetzt der Moment der Wahrheit: Wir haben eine kompilierte Klasse GitTest.class, die „nicht verfolgt“ ist und die wir nicht zum Git-Repository hinzufügen wollten.
Jetzt sollten wir die Auswirkungen der .gitignore-Datei sehen:

Perfekt! .gitignore +1 :)
Arbeiten mit Zweigen
Natürlich ist die Arbeit in nur einer Branche für einzelne Entwickler unbequem und unmöglich, wenn mehr als eine Person in einem Team ist. Deshalb haben wir Niederlassungen.
Ein Zweig ist nur ein beweglicher Zeiger auf Commits.
In diesem Teil befassen wir uns mit der Arbeit in verschiedenen Zweigen: wie Änderungen von einem Zweig in einen anderen zusammengeführt werden, welche Konflikte auftreten können und vieles mehr.
Um eine Liste aller Zweige im Repository anzuzeigen und zu verstehen, in welchem Zweig Sie sich befinden, müssen Sie Folgendes schreiben:

Sie sehen, dass wir nur eine Hauptniederlassung haben. Das Sternchen davor zeigt an, dass wir uns darin befinden. Übrigens können Sie auch den Befehl „git status“ verwenden, um herauszufinden, in welchem Zweig wir uns befinden.
Dann gibt es mehrere Optionen zum Erstellen von Zweigen (möglicherweise gibt es noch mehr – diese verwende ich):
- Erstellen Sie einen neuen Zweig basierend auf dem, in dem wir uns befinden (99 % der Fälle).
- Erstellen Sie einen Zweig basierend auf einem bestimmten Commit (1 % der Fälle)
Lassen Sie uns einen Zweig basierend auf einem bestimmten Commit erstellen
Wir verlassen uns auf die eindeutige Kennung des Commits. Um es zu finden, schreiben wir:

Wir haben den Commit mit dem Kommentar „Hallo Welt hinzugefügt…“ hervorgehoben. Seine eindeutige Kennung ist 6c44e53d06228f888f2f454d3cb8c1c976dd73f8. Wir möchten einen „Entwicklungs“-Zweig erstellen, der mit diesem Commit beginnt. Dazu schreiben wir:
Ein Zweig wird nur mit den ersten beiden Commits des Hauptzweigs erstellt. Um dies zu überprüfen, wechseln wir zunächst zu einem anderen Zweig und schauen uns dort die Anzahl der Commits an:

Und wie erwartet haben wir zwei Commits. Hier ist übrigens ein interessanter Punkt: In diesem Zweig gibt es noch keine .gitignore-Datei, daher wird unsere kompilierte Datei (GitTest.class) jetzt mit dem Status „nicht verfolgt“ hervorgehoben.
Jetzt können wir unsere Filialen noch einmal überprüfen, indem wir Folgendes schreiben:
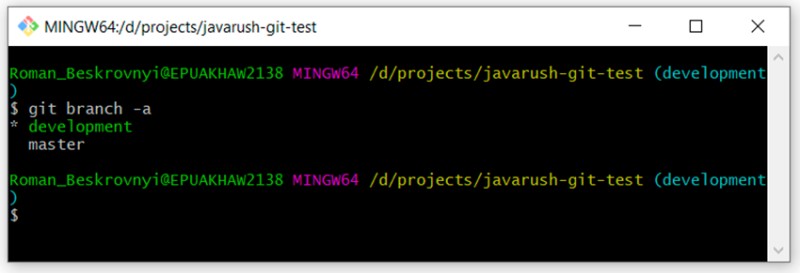
Sie können sehen, dass es zwei Zweige gibt: „Master“ und „Entwicklung“. Wir befinden uns derzeit in der Entwicklung.
Erstellen wir einen Zweig basierend auf dem aktuellen
Die zweite Möglichkeit, einen Zweig zu erstellen, besteht darin, ihn aus einem anderen zu erstellen. Wir möchten einen Zweig basierend auf dem Hauptzweig erstellen. Zuerst müssen wir darauf umsteigen, und der nächste Schritt besteht darin, ein neues zu erstellen. Lass uns einen Blick darauf werfen:
- git checkout master – Wechseln Sie zum Master-Zweig
- Git-Status – Überprüfen Sie, ob wir uns tatsächlich im Master-Zweig befinden

Hier können Sie sehen, dass wir zum Hauptzweig gewechselt sind, die .gitignore-Datei wirksam ist und die kompilierte Klasse nicht mehr als „nicht verfolgt“ hervorgehoben ist.
Jetzt erstellen wir einen neuen Branch basierend auf dem Master-Branch:

Wenn Sie sich nicht sicher sind, ob dieser Zweig mit „master“ identisch ist, können Sie dies ganz einfach überprüfen, indem Sie „git log“ ausführen und sich alle Commits ansehen. Es sollten vier davon sein.
Konfliktlösung
Bevor wir untersuchen, was ein Konflikt ist, müssen wir über die Zusammenführung eines Zweigs mit einem anderen sprechen.
Dieses Bild zeigt den Prozess der Zusammenführung eines Zweigs mit einem anderen:

Hier haben wir eine Hauptniederlassung. Irgendwann wird aus dem Hauptzweig ein sekundärer Zweig erstellt und dann geändert. Sobald die Arbeit erledigt ist, müssen wir einen Zweig mit dem anderen zusammenführen.
In unserem Beispiel haben wir den Zweig „feature/update-txt-files“ erstellt. Wie aus dem Namen des Zweigs hervorgeht, aktualisieren wir den Text.

Jetzt müssen wir ein neues Commit für diese Arbeit erstellen:

Wenn wir nun den Zweig „feature/update-txt-files“ im Master zusammenführen möchten, müssen wir zum Master gehen und „git merge feature/update-txt-files“ schreiben:

Daher enthält der Master-Zweig nun auch den Commit, der zu den Feature/Update-txt-Dateien hinzugefügt wurde.
Diese Funktionalität wurde hinzugefügt, sodass Sie einen Feature-Zweig löschen können. Dazu schreiben wir:
Machen wir die Situation noch komplizierter: Nehmen wir an, Sie müssen die TXT-Datei erneut ändern. Nun wird diese Datei aber auch im Master-Zweig geändert. Mit anderen Worten: Es wird sich parallel ändern. Git wird nicht herausfinden können, was zu tun ist, wenn wir unseren neuen Code in den Master-Zweig einbinden möchten.
Wir erstellen einen neuen Zweig basierend auf Master, nehmen Änderungen an text_resource.txt vor und erstellen einen Commit für diese Arbeit:
... wir nehmen Änderungen an der Datei vor


Gehen Sie zum Master-Zweig und aktualisieren Sie auch diese Textdatei in derselben Zeile wie im Feature-Zweig:
… wir haben test_resource.txt aktualisiert

Und nun der interessanteste Punkt: Wir müssen Änderungen vom Feature/Add-Header-Zweig zum Master zusammenführen. Wir befinden uns im Master-Zweig, also müssen wir nur schreiben:
Das Ergebnis wird jedoch ein Konflikt in der Datei test_resource.txt sein:

Hier sehen wir, dass Git nicht selbst entscheiden konnte, wie dieser Code zusammengeführt wird. Es sagt uns, dass wir zuerst den Konflikt lösen und erst dann den Commit durchführen müssen.
OK. Wir öffnen die Datei mit dem Konflikt in einem Texteditor und sehen:

Um zu verstehen, was Git hier gemacht hat, müssen wir uns merken, welche Änderungen wir wo vorgenommen haben, und dann vergleichen:
- Die Änderungen, die in dieser Zeile im Hauptzweig vorgenommen wurden, befinden sich zwischen „<<<<<<< HEAD“ und „=======".
- Die Änderungen, die im Zweig „feature/add-header“ vorgenommen wurden, befinden sich zwischen „=======" und „>>>>>>> feature/add-header".
So teilt uns Git mit, dass es nicht herausfinden konnte, wie die Zusammenführung an dieser Stelle in der Datei durchgeführt werden kann. Es unterteilt diesen Abschnitt in zwei Teile aus den verschiedenen Zweigen und lädt uns ein, den Zusammenführungskonflikt selbst zu lösen.
Fair genug. Ich entscheide mich mutig, alles zu entfernen und nur das Wort „Header“ übrig zu lassen:

Schauen wir uns den Status der Änderungen an. Die Beschreibung wird etwas anders sein. Anstelle eines „modifizierten“ Status haben wir einen „aufgelösten“ Status. Hätten wir also einen fünften Status erwähnen können? Ich glaube nicht, dass das notwendig ist. Mal sehen:

Wir können uns davon überzeugen, dass es sich hierbei um einen besonderen, ungewöhnlichen Fall handelt. Lass uns weitermachen:

Möglicherweise fällt Ihnen auf, dass in der Beschreibung nur „Git Commit“ vorgeschlagen wird. Versuchen wir, Folgendes zu schreiben:

Und einfach so haben wir es geschafft – wir haben den Konflikt in der Konsole gelöst.
In integrierten Entwicklungsumgebungen geht das natürlich etwas einfacher. In IntelliJ IDEA ist beispielsweise alles so gut eingerichtet, dass Sie alle notwendigen Aktionen direkt darin ausführen können. Aber IDEs erledigen viele Dinge „unter der Haube“, und wir verstehen oft nicht, was genau dort passiert. Und wenn es kein Verständnis gibt, können Probleme entstehen.
Arbeiten mit Remote-Repositorys
Der letzte Schritt besteht darin, einige weitere Befehle herauszufinden, die für die Arbeit mit dem Remote-Repository erforderlich sind.
Wie gesagt, ein Remote-Repository ist ein Ort, an dem das Repository gespeichert ist und von dem aus Sie es klonen können.
Welche Arten von Remote-Repositorys gibt es? Beispiele:
- GitHub ist die größte Speicherplattform für Repositories und kollaborative Entwicklung.
- GitLab ist ein webbasiertes Tool für den DevOps-Lebenszyklus mit Open Source. Es handelt sich um ein Git-basiertes System zur Verwaltung von Code-Repositorys mit eigenem Wiki, Bug-Tracking-System, CI/CD-Pipeline und anderen Funktionen.
- BitBucket ist ein Webdienst für Projekthosting und kollaborative Entwicklung, der auf den Versionskontrollsystemen Mercurial und Git basiert. Einst hatte es einen großen Vorteil gegenüber GitHub, da es kostenlose private Repositories anbot. Letztes Jahr hat GitHub diese Funktion auch allen kostenlos zur Verfügung gestellt.
- Usw…
Wenn Sie mit einem Remote-Repository arbeiten, müssen Sie zunächst das Projekt in Ihr lokales Repository klonen.
Dazu haben wir das Projekt, das wir lokal erstellt haben, exportiert. Jetzt kann es jeder für sich selbst klonen, indem er Folgendes schreibt:
Es gibt nun eine vollständige lokale Kopie des Projekts. Um sicherzustellen, dass die lokale Kopie des Projekts die neueste ist, müssen Sie das Projekt abrufen, indem Sie Folgendes schreiben:

In unserem Fall hat sich im Remote-Repository derzeit nichts geändert, daher lautet die Antwort: Bereits auf dem neuesten Stand.
Wenn wir jedoch Änderungen am Remote-Repository vornehmen, wird das lokale Repository aktualisiert, nachdem wir sie abgerufen haben.
Und schließlich besteht der letzte Befehl darin, die Daten in das Remote-Repository zu übertragen. Wenn wir etwas lokal erledigt haben und es an das Remote-Repository senden möchten, müssen wir zunächst lokal einen neuen Commit erstellen. Um dies zu demonstrieren, fügen wir unserer Textdatei noch etwas hinzu:

Nun etwas ganz Gemeinsames für uns – wir erstellen ein Commit für diese Arbeit:
Der Befehl, um dies in das Remote-Repository zu übertragen, lautet:
Das war es fürs Erste!
| Nützliche Links |
|---|
|
2. So arbeiten Sie mit Git in IntelliJ IDEA
In diesem Teil erfahren Sie, wie Sie mit Git in IntelliJ IDEA arbeiten.
Erforderliche Eingaben:
- Lesen Sie den vorherigen Teil, folgen Sie ihm und verstehen Sie ihn. Dadurch wird sichergestellt, dass alles eingerichtet und betriebsbereit ist.
- Installieren Sie IntelliJ IDEA. Hier sollte alles in Ordnung sein :)
- Planen Sie eine Stunde ein, um die vollständige Meisterschaft zu erlangen.
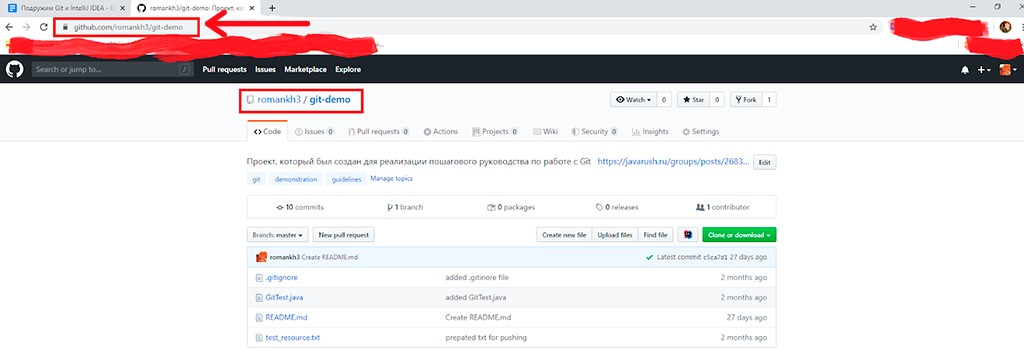
Lassen Sie uns mit dem Demoprojekt arbeiten , das ich für den Artikel über Git verwendet habe.
Klonen Sie das Projekt lokal
Hier gibt es zwei Möglichkeiten:
- Wenn Sie bereits über ein GitHub-Konto verfügen und später etwas pushen möchten, ist es besser, das Projekt zu forken und Ihre eigene Kopie zu klonen. Wie Sie einen Fork erstellen, können Sie in einem anderen Artikel unter der Überschrift Ein Beispiel für den Forking-Workflow nachlesen .
- Klonen Sie das Repository und erledigen Sie alles lokal, ohne die Möglichkeit zu haben, das Ganze auf den Server zu übertragen.
Um ein Projekt von GitHub zu klonen, müssen Sie den Projektlink kopieren und an IntelliJ IDEA übergeben:
-
Kopieren Sie die Projektadresse:
![]()
-
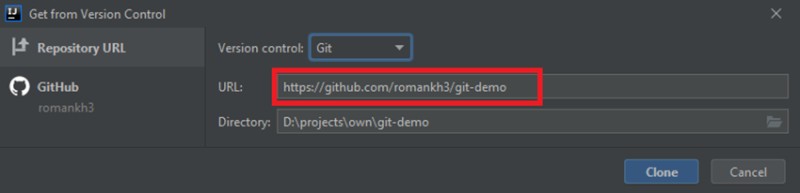
Öffnen Sie IntelliJ IDEA und wählen Sie „Von Versionskontrolle abrufen“:
![]()
-
Kopieren Sie die Projektadresse und fügen Sie sie ein:
![]()
-
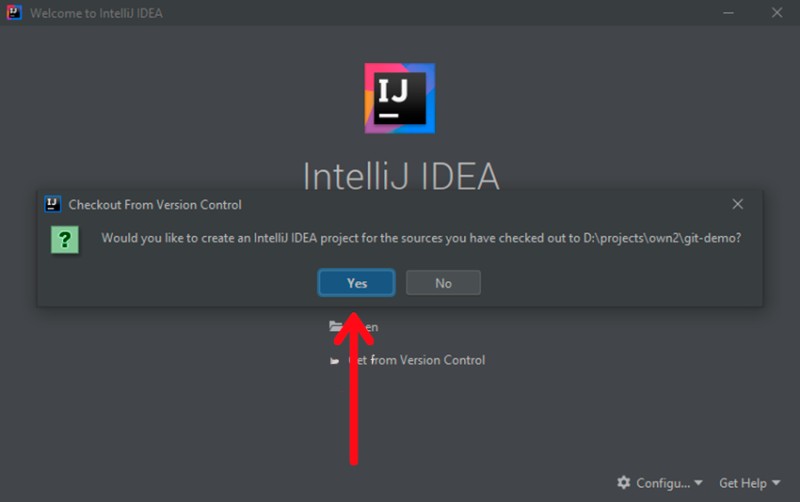
Sie werden aufgefordert, ein IntelliJ IDEA-Projekt zu erstellen. Angebot annehmen:
![]()
-
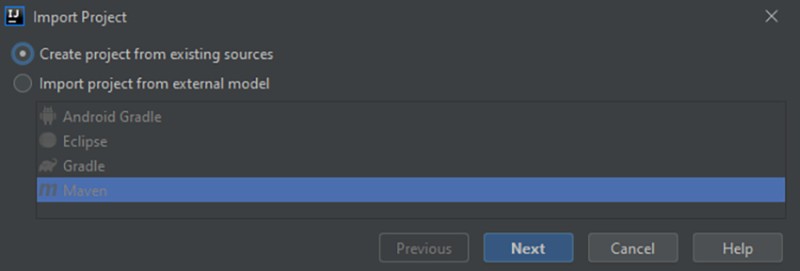
Da es kein Build-System gibt, wählen wir „Projekt aus vorhandenen Quellen erstellen“:
![]()
-
Als nächstes sehen Sie diesen schönen Bildschirm:
![]()

Nachdem wir nun das Klonen herausgefunden haben, können Sie sich umschauen.
Erster Blick auf IntelliJ IDEA als Git-Benutzeroberfläche
Schauen Sie sich das geklonte Projekt genauer an: Sie können bereits viele Informationen über das Versionskontrollsystem erhalten.
Zuerst haben wir den Versionskontrollbereich in der unteren linken Ecke. Hier finden Sie alle lokalen Änderungen und erhalten eine Liste der Commits (analog zu „git log“).
Kommen wir zur Diskussion von Log. Es gibt eine gewisse Visualisierung, die uns hilft, genau zu verstehen, wie die Entwicklung verlaufen ist. Sie können beispielsweise sehen, dass ein neuer Zweig mit einem hinzugefügten Header zum TXT-Commit erstellt wurde, der dann mit dem Hauptzweig zusammengeführt wurde. Wenn Sie auf einen Commit klicken, sehen Sie in der rechten Ecke alle Informationen zum Commit: alle seine Änderungen und Metadaten.
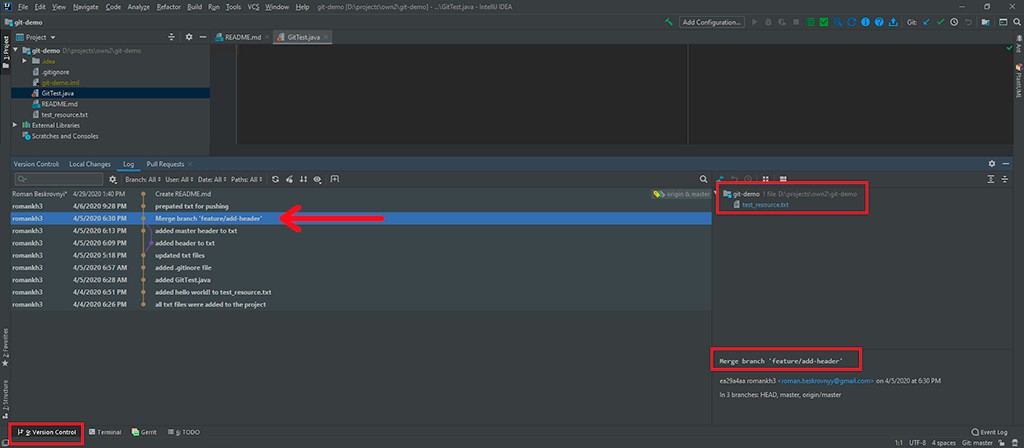
Darüber hinaus können Sie die tatsächlichen Änderungen sehen. Wir sehen auch, dass dort ein Konflikt gelöst wurde. IDEA stellt dies auch sehr gut dar.
Wenn Sie auf die Datei doppelklicken, die während dieses Commits geändert wurde, sehen wir, wie der Konflikt gelöst wurde:

Wir stellen fest, dass wir links und rechts die beiden Versionen derselben Datei haben, die zu einer zusammengeführt werden mussten. Und in der Mitte haben wir das endgültige zusammengeführte Ergebnis.
Wenn ein Projekt viele Zweige, Commits und Benutzer hat, müssen Sie separat nach Zweig, Benutzer und Datum suchen:

Bevor es losgeht, lohnt es sich auch zu erklären, wie man versteht, in welcher Branche wir uns befinden.
In der unteren rechten Ecke befindet sich eine Schaltfläche mit der Bezeichnung „Git:master“. Was auch immer auf „Git:“ folgt, ist der aktuelle Zweig. Wenn Sie auf die Schaltfläche klicken, können Sie viele nützliche Dinge tun: zu einem anderen Zweig wechseln, einen neuen erstellen, einen vorhandenen umbenennen und so weiter.

Arbeiten mit einem Repository
Nützliche Hotkeys
Für die zukünftige Arbeit müssen Sie sich einige sehr nützliche Hotkeys merken:
- STRG+T – Holen Sie sich die neuesten Änderungen aus dem Remote-Repository (git pull).
- STRG+K – Commit erstellen / alle aktuellen Änderungen anzeigen. Dies umfasst sowohl nicht verfolgte als auch geänderte Dateien (Git Commit).
- STRG+UMSCHALT+K – Dies ist der Befehl zum Übertragen von Änderungen an das Remote-Repository. Alle Commits, die lokal erstellt wurden und sich noch nicht im Remote-Repository befinden, werden gepusht (git push).
- ALT+STRG+Z – Rollback von Änderungen in einer bestimmten Datei auf den Status des letzten im lokalen Repository erstellten Commits. Wenn Sie in der oberen linken Ecke das gesamte Projekt auswählen, können Sie Änderungen in allen Dateien rückgängig machen.
Was wollen wir?
Um unsere Arbeit zu erledigen, müssen wir ein grundlegendes Szenario beherrschen, das überall verwendet wird.
Das Ziel besteht darin, neue Funktionen in einem separaten Zweig zu implementieren und sie dann in ein Remote-Repository zu übertragen (dann müssen Sie auch eine Pull-Anfrage an den Hauptzweig erstellen, aber das würde den Rahmen dieser Lektion sprengen).
Was ist dazu erforderlich?
-
Rufen Sie alle aktuellen Änderungen im Hauptzweig ab (z. B. „master“).
-
Erstellen Sie von diesem Hauptzweig aus einen separaten Zweig für Ihre Arbeit.
-
Implementieren Sie die neue Funktionalität.
-
Gehen Sie zum Hauptzweig und prüfen Sie, ob während unserer Arbeit neue Änderungen vorgenommen wurden. Wenn nicht, dann ist alles in Ordnung. Wenn es jedoch Änderungen gab, gehen wir wie folgt vor: Gehen Sie zum Arbeitszweig und übertragen Sie die Änderungen vom Hauptzweig auf unseren. Wenn alles gut geht, dann großartig. Aber es ist durchaus möglich, dass es zu Konflikten kommt. Tatsächlich können sie einfach im Voraus gelöst werden, ohne Zeit im Remote-Repository zu verschwenden.
Sie fragen sich, warum Sie das tun sollten? Das ist ein gutes Benehmen und verhindert, dass Konflikte auftreten, nachdem Sie Ihren Zweig in das lokale Repository verschoben haben (es besteht natürlich die Möglichkeit, dass Konflikte immer noch auftreten, aber die Wahrscheinlichkeit wird viel geringer ).
-
Übertragen Sie Ihre Änderungen per Push an das Remote-Repository.
Wie erhalte ich Änderungen vom Remote-Server?
Wir haben der README-Datei mit einem neuen Commit eine Beschreibung hinzugefügt und möchten diese Änderungen erhalten. Wenn Änderungen sowohl im lokalen Repository als auch im Remote-Repository vorgenommen wurden, können wir zwischen einer Zusammenführung und einem Rebase wählen. Wir entscheiden uns für die Fusion.
Geben Sie STRG+T ein :

Sie können nun sehen, wie sich die README-Datei geändert hat, d. h. die Änderungen wurden aus dem Remote-Repository übernommen, und in der unteren rechten Ecke sehen Sie alle Details zu den Änderungen, die vom Server kamen.

Erstellen Sie einen neuen Zweig basierend auf dem Master
Hier ist alles einfach.
Gehen Sie in die untere rechte Ecke und klicken Sie auf Git:master . Wählen Sie + Neuer Zweig aus .
 Lassen Sie das Kontrollkästchen „Checkout-Filiale“ aktiviert und geben Sie den Namen der neuen Filiale ein. In unserem Fall: Dies wird readme-improver sein .
Lassen Sie das Kontrollkästchen „Checkout-Filiale“ aktiviert und geben Sie den Namen der neuen Filiale ein. In unserem Fall: Dies wird readme-improver sein .
Git:master ändert sich dann zu Git:readme-improver .
Lassen Sie uns paralleles Arbeiten simulieren
Damit Konflikte entstehen, muss jemand sie schaffen.
Wir werden die README-Datei mit einem neuen Commit über den Browser bearbeiten und so paralleles Arbeiten simulieren. Es ist, als hätte jemand Änderungen an derselben Datei vorgenommen, während wir daran gearbeitet haben. Das Ergebnis wird ein Konflikt sein. Wir werden das Wort „völlig“ aus Zeile 10 entfernen.
Implementieren Sie unsere Funktionalität
Unsere Aufgabe besteht darin, die README-Datei zu ändern und dem neuen Artikel eine Beschreibung hinzuzufügen. Das heißt, die Arbeit in Git läuft über IntelliJ IDEA. Füge das hinzu:

Die Änderungen sind abgeschlossen. Jetzt können wir einen Commit erstellen. Drücken Sie STRG+K , was uns Folgendes ergibt:

Bevor wir einen Commit erstellen, müssen wir uns genau ansehen, was dieses Fenster bietet.
Im Abschnitt „Commit-Nachricht“ schreiben wir Text, der mit dem Commit verknüpft ist. Um es dann zu erstellen, müssen wir auf „Commit“ klicken .
Wir schreiben, dass sich die README geändert hat und erstellen den Commit. In der unteren linken Ecke wird eine Warnung mit dem Namen des Commits angezeigt:

Überprüfen Sie, ob sich der Hauptzweig geändert hat
Wir haben unsere Aufgabe erledigt. Es klappt. Wir haben Tests geschrieben. Alles ist gut. Doch bevor wir auf den Server pushen, müssen wir noch prüfen, ob es zwischenzeitlich Änderungen im Hauptzweig gegeben hat. Wie konnte das passieren? Ganz einfach: Jemand erhält eine Aufgabe nach Ihnen, und dieser Jemand erledigt sie schneller, als Sie Ihre Aufgabe erledigen.
Also müssen wir zur Hauptniederlassung gehen. Dazu müssen wir das tun, was in der unteren rechten Ecke im Screenshot unten gezeigt wird:

Drücken Sie im Hauptzweig STRG+T , um die neuesten Änderungen vom Remote-Server abzurufen. Wenn Sie sich die Änderungen ansehen, können Sie leicht erkennen, was passiert ist:

Das Wort „völlig“ wurde entfernt. Vielleicht hat jemand aus dem Marketing entschieden, dass es nicht so geschrieben werden sollte, und den Entwicklern die Aufgabe gegeben, es zu aktualisieren.
Wir haben jetzt eine lokale Kopie der neuesten Version des Master-Zweigs. Gehen Sie zurück zu readme-improver .
Jetzt müssen wir die Änderungen vom Hauptzweig auf unseren umbasieren. Wir machen das: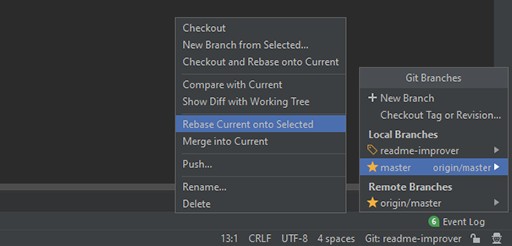
Wenn Sie alles richtig gemacht und mir gefolgt sind, sollte das Ergebnis einen Konflikt in der README-Datei anzeigen:

Auch hier haben wir viele Informationen zum Verstehen und Aufsaugen. Hier wird eine Liste von Dateien (in unserem Fall eine Datei) angezeigt, die Konflikte aufweisen. Wir können aus drei Optionen wählen:
- Akzeptieren Sie Ihre – akzeptieren Sie nur Änderungen aus dem Readme-Improver.
- Akzeptieren Sie ihre – akzeptieren Sie nur Änderungen vom Master.
- Zusammenführen – entscheiden Sie selbst, was Sie behalten und was Sie verwerfen möchten.
Es ist nicht klar, was sich geändert hat. Wenn es Änderungen im Hauptzweig gibt, müssen diese dort benötigt werden, sodass wir unsere Änderungen nicht einfach akzeptieren können. Dementsprechend wählen wir merge aus :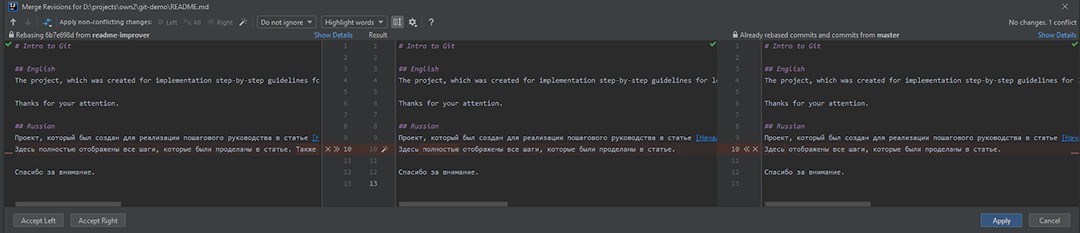
Hier sehen wir, dass es drei Teile gibt:
- Dies sind die Änderungen aus dem Readme-Improver.
- Das zusammengeführte Ergebnis. Im Moment ist es das, was vor den Änderungen existierte.
- Die Änderungen aus dem Hauptzweig.
Wir müssen ein zusammengeführtes Ergebnis erzielen, das alle zufriedenstellt. Wenn wir uns ansehen, was VOR unseren Änderungen geändert wurde, stellen wir fest, dass einfach das Wort „völlig“ entfernt wurde. Okay, kein Problem! Das bedeutet, dass wir es auch im zusammengeführten Ergebnis entfernen und dann unsere Änderungen hinzufügen. Sobald wir das zusammengeführte Ergebnis korrigiert haben, können wir auf Übernehmen klicken .
Dann erscheint eine Benachrichtigung, die uns mitteilt, dass die Rebase erfolgreich war:

Dort! Wir haben unseren ersten Konflikt durch IntelliJ IDEA gelöst.
Übertragen Sie Änderungen an den Remote-Server
Der nächste Schritt besteht darin, die Änderungen an den Remote-Server zu übertragen und eine Pull-Anfrage zu erstellen. Drücken Sie dazu einfach STRG+UMSCHALT+K . Dann erhalten wir:

Auf der linken Seite wird eine Liste der Commits angezeigt, die nicht in das Remote-Repository übertragen wurden. Auf der rechten Seite werden alle Dateien angezeigt, die geändert wurden. Und das ist es! Drücken Sie Push und Sie werden Glück erleben :)
Wenn der Push erfolgreich war, sehen Sie unten rechts eine Benachrichtigung wie diese:

Bonus: Erstellen einer Pull-Anfrage
Gehen wir zu einem GitHub-Repository und sehen, dass GitHub bereits weiß, was wir wollen:

Klicken Sie auf „Vergleichen und Anforderung abrufen“ . Klicken Sie dann auf Pull-Anfrage erstellen . Da wir die Konflikte im Voraus gelöst haben, können wir jetzt beim Erstellen einer Pull-Anfrage diese sofort zusammenführen: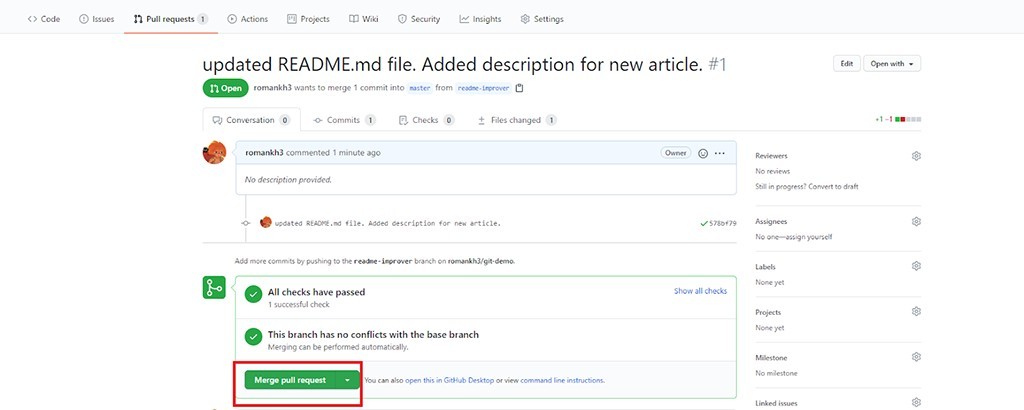
Das war es fürs Erste!
GO TO FULL VERSION