1. Una guía detallada de Git para principiantes
Hoy vamos a hablar sobre un sistema de control de versiones, a saber, Git.
Realmente no puedes ser un programador completo sin conocer y comprender esta herramienta. Por supuesto, no es necesario que tenga todos los comandos y funciones de Git en su cabeza para poder utilizarlos continuamente. Necesita conocer un conjunto de comandos que lo ayudarán a comprender todo lo que está sucediendo.
Conceptos básicos de Git
Git es un sistema de control de versiones distribuido para nuestro código. ¿Por qué lo necesitamos? Los equipos necesitan algún tipo de sistema para gestionar su trabajo. Es necesario para realizar un seguimiento de los cambios que se producen a lo largo del tiempo.
Es decir, necesitamos poder ver paso a paso qué archivos han cambiado y cómo. Esto es especialmente importante cuando investiga qué cambió en el contexto de una sola tarea, lo que hace posible revertir los cambios.
Imaginemos la siguiente situación: tenemos un código que funciona, todo está bien, pero luego decidimos mejorar o modificar algo. No es gran cosa, pero nuestra "mejora" rompió la mitad de las funciones del programa e hizo que fuera imposible trabajar. ¿Y ahora que? Sin Git, tendrías que sentarte y pensar durante horas, tratando de recordar cómo era todo originalmente. Pero con Git, simplemente revertimos la confirmación, y eso es todo.
¿O qué sucede si hay dos desarrolladores que realizan sus propios cambios de código al mismo tiempo? Sin Git, copian los archivos de código originales y los modifican por separado. Llega un momento en que ambos quieren agregar sus cambios al directorio principal. ¿Qué haces en este caso?
No habrá tales problemas si usa Git.
Instalando Git
Instalemos Java en su computadora. Este proceso difiere ligeramente para diferentes sistemas operativos.
Instalación en Windows
Como de costumbre, debe descargar y ejecutar un archivo exe. Aquí todo es simple: haga clic en el primer enlace de Google , realice la instalación y listo. Para ello, utilizaremos la consola bash que nos proporciona Windows.
En Windows, debe ejecutar Git Bash. Así es como se ve en el menú Inicio:

Ahora bien, este es un símbolo del sistema con el que puede trabajar.
Para evitar tener que ir a la carpeta con el proyecto cada vez para poder abrir Git allí, puede abrir el símbolo del sistema en la carpeta del proyecto con el botón derecho del mouse con la ruta que necesitamos:

Instalación en Linux
Por lo general, Git es parte de las distribuciones de Linux y ya está instalado, ya que es una herramienta que se escribió originalmente para el desarrollo del kernel de Linux. Pero hay situaciones en las que no lo es. Para verificar, debe abrir una terminal y escribir: git --version. Si obtiene una respuesta inteligible, entonces no es necesario instalar nada.
Abra una terminal e instale. Para Ubuntu, debe escribir: sudo apt-get install git. Y eso es todo: ahora puedes usar Git en cualquier terminal.
Instalación en macOS
Aquí también, primero debe verificar si Git ya está allí (ver arriba, lo mismo que en Linux).
Si no lo tiene, la forma más fácil de obtenerlo es descargar la última versión . Si Xcode está instalado, Git definitivamente se instalará automáticamente.
Configuración de Git
Git tiene configuraciones de usuario para el usuario que enviará el trabajo. Esto tiene sentido y es necesario, porque Git toma esta información para el campo Autor cuando se crea una confirmación.
Configure un nombre de usuario y una contraseña para todos sus proyectos ejecutando los siguientes comandos:
Si necesita cambiar el autor de un proyecto específico (para un proyecto personal, por ejemplo), puede eliminar "--global". Esto nos dará lo siguiente:
un poco de teoria
Para profundizar en el tema, debemos presentarle algunas palabras y acciones nuevas... De lo contrario, no habrá nada de qué hablar. Por supuesto, esta es una jerga que nos llega del inglés, así que agregaré las traducciones entre paréntesis.
¿Qué palabras y acciones?
- repositorio git
- comprometerse
- rama
- unir
- conflictos
- jalar
- empujar
- cómo ignorar algunos archivos (.gitignore)
Etcétera.
Estados en Git
Git tiene varias estatuas que deben entenderse y recordarse:
- sin seguimiento
- modificado
- escenificado
- comprometido
¿Cómo debes entender esto?
Estos son estados que se aplican a los archivos que contienen nuestro código. En otras palabras, su ciclo de vida suele ser así:
- Un archivo que se crea pero aún no se agrega al repositorio tiene el estado "sin seguimiento".
- Cuando realizamos cambios en archivos que ya se han agregado al repositorio de Git, su estado es "modificado".
- Entre los archivos que hemos cambiado, seleccionamos los que necesitamos (por ejemplo, no necesitamos clases compiladas), y estas clases se cambian al estado "por etapas".
- Se crea una confirmación a partir de archivos preparados en el estado provisional y va al repositorio de Git. Después de eso, no hay archivos con el estado "preparado". Pero todavía puede haber archivos cuyo estado sea "modificado".
Así es como se ve:

¿Qué es un compromiso?
Una confirmación es el evento principal cuando se trata de control de versiones. Contiene todos los cambios realizados desde que comenzó la confirmación. Las confirmaciones están vinculadas entre sí como una lista vinculada individualmente.
Específicamente, hay un primer compromiso. Cuando se crea la segunda confirmación, (la segunda) sabe lo que viene después de la primera. Y de esta manera, la información puede ser rastreada.
Un compromiso también tiene su propia información, los llamados metadatos:
- el identificador único del compromiso, que se puede usar para encontrarlo
- el nombre del autor de la confirmación, quien la creó
- la fecha en que se creó la confirmación
- un comentario que describe lo que se hizo durante la confirmación
Así es como se ve:

¿Qué es una sucursal?

Una rama es un puntero a algún compromiso. Debido a que una confirmación sabe qué confirmación la precede, cuando una rama apunta a una confirmación, todas las confirmaciones anteriores también se aplican a ella.
En consecuencia, podríamos decir que puedes tener tantas ramas como quieras apuntando al mismo compromiso.
El trabajo ocurre en ramas, por lo que cuando se crea una nueva confirmación, la rama mueve su puntero a la confirmación más reciente.

Comenzando con Git
Puede trabajar solo con un repositorio local y también con uno remoto.
Para practicar los comandos requeridos, puede limitarse al repositorio local. Solo almacena toda la información del proyecto localmente en la carpeta .git.
Si estamos hablando del repositorio remoto, entonces toda la información se almacena en algún lugar del servidor remoto: solo una copia del proyecto se almacena localmente. Los cambios realizados en su copia local pueden enviarse (git push) al repositorio remoto.
En nuestra discusión aquí y más abajo, estamos hablando de trabajar con Git en la consola. Por supuesto, puede usar algún tipo de solución basada en GUI (por ejemplo, IntelliJ IDEA), pero primero debe averiguar qué comandos se están ejecutando y qué significan.
Trabajar con Git en un repositorio local
Para crear un repositorio local, debe escribir:

Esto creará una carpeta .git oculta en el directorio actual de la consola.
La carpeta .git almacena toda la información sobre el repositorio de Git. No lo borres ;)
A continuación, los archivos se agregan al proyecto y se les asigna el estado "Sin seguimiento". Para consultar el estado actual de tu trabajo, escribe esto:
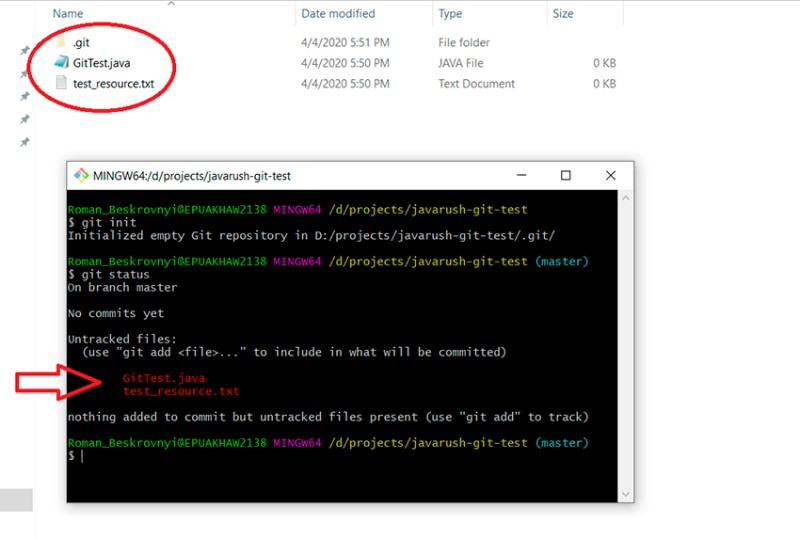
Estamos en la rama principal, y aquí permaneceremos hasta que cambiemos a otra rama.
Esto muestra qué archivos han cambiado pero aún no se han agregado al estado "preparado". Para agregarlos al estado "preparado", debe escribir "git add". Tenemos algunas opciones aquí, por ejemplo:
- git add -A: agrega todos los archivos al estado "preparado"
- agrega git — agregar todos los archivos de esta carpeta y todas las subcarpetas. Esencialmente lo mismo que el anterior;
- git add <Nombre del archivo> — agrega un archivo específico. Aquí puede usar expresiones regulares para agregar archivos de acuerdo con algún patrón. Por ejemplo, git add *.java: esto significa que solo desea agregar archivos con la extensión java.
Las dos primeras opciones son claramente simples. Las cosas se ponen más interesantes con la última incorporación, así que escribamos:
Para verificar el estado, usamos el comando que ya conocemos:

Aquí puede ver que la expresión regular ha funcionado correctamente: test_resource.txt ahora tiene el estado "preparado".
Y finalmente, la última etapa para trabajar con un repositorio local (hay una más cuando se trabaja con el repositorio remoto ;)) — crear una nueva confirmación:

El siguiente es un gran comando para ver el historial de confirmaciones en una rama. Hagámosle uso:

Aquí puede ver que hemos creado nuestro primer compromiso e incluye el texto que proporcionamos en la línea de comando. Es muy importante comprender que este texto debe explicar con la mayor precisión posible lo que se hizo durante este compromiso. Esto nos ayudará muchas veces en el futuro.
Un lector inquisitivo que aún no se ha quedado dormido puede preguntarse qué pasó con el archivo GitTest.java. Averigüémoslo ahora mismo. Para hacer esto, usamos:

Como puede ver, todavía está "sin seguimiento" y está esperando en las alas. Pero, ¿y si no queremos añadirlo al proyecto en absoluto? A veces eso sucede.
Para hacer las cosas más interesantes, intentemos ahora cambiar nuestro archivo test_resource.txt. Agreguemos algo de texto allí y verifiquemos el estado:

Aquí puede ver claramente la diferencia entre los estados "sin seguimiento" y "modificado".
GitTest.java está "sin seguimiento", mientras que test_resource.txt está "modificado".
Ahora que tenemos archivos en el estado modificado, podemos examinar los cambios realizados en ellos. Esto se puede hacer usando el siguiente comando:

Es decir, puedes ver claramente aquí lo que agregué a nuestro archivo de texto: ¡hola mundo!
Agreguemos nuestros cambios al archivo de texto y creemos una confirmación:
Para ver todas las confirmaciones, escribe:

Como puede ver, ahora tenemos dos confirmaciones.
Agregaremos GitTest.java de la misma manera. No hay comentarios aquí, solo comandos:

Trabajando con .gitignore
Claramente, solo queremos mantener el código fuente solo, y nada más, en el repositorio. Entonces, ¿qué más podría haber? Como mínimo, clases compiladas y/o archivos generados por entornos de desarrollo.
Para decirle a Git que los ignore, necesitamos crear un archivo especial. Haga esto: cree un archivo llamado .gitignore en la raíz del proyecto. Cada línea en este archivo representa un patrón para ignorar.
En este ejemplo, el archivo .gitignore se verá así:
objetivo/
*.iml
.idea/
Vamos a ver:
- La primera línea es ignorar todos los archivos con la extensión .class
- La segunda línea es ignorar la carpeta "objetivo" y todo lo que contiene
- La tercera línea es ignorar todos los archivos con la extensión .iml
- La cuarta línea es ignorar la carpeta .idea
Intentemos usar un ejemplo. Para ver cómo funciona, agreguemos el GitTest.class compilado al proyecto y verifiquemos el estado del proyecto:

Claramente, no queremos agregar accidentalmente la clase compilada al proyecto (usando git add -A). Para hacer esto, cree un archivo .gitignore y agregue todo lo que se describió anteriormente:

Ahora usemos una confirmación para agregar el archivo .gitignore al proyecto:
Y ahora el momento de la verdad: tenemos una clase compilada GitTest.class que está "sin seguimiento", que no queríamos agregar al repositorio de Git.
Ahora deberíamos ver los efectos del archivo .gitignore:

¡Perfecto! .gitignore +1 :)
Trabajando con ramas
Naturalmente, trabajar en una sola rama es un inconveniente para los desarrolladores solitarios y es imposible cuando hay más de una persona en un equipo. Por eso tenemos sucursales.
Una rama es solo un puntero móvil para confirmaciones.
En esta parte, exploraremos cómo trabajar en diferentes ramas: cómo fusionar cambios de una rama a otra, qué conflictos pueden surgir y mucho más.
Para ver una lista de todas las sucursales en el repositorio y comprender en cuál se encuentra, debe escribir:

Puede ver que solo tenemos una rama maestra. El asterisco delante de él indica que estamos en él. Por cierto, también puedes usar el comando "git status" para saber en qué rama estamos.
Luego, hay varias opciones para crear ramas (puede haber más, estas son las que uso):
- crear una nueva sucursal basada en la que estamos (99% de los casos)
- crear una rama basada en una confirmación específica (1% de los casos)
Vamos a crear una rama basada en una confirmación específica
Confiaremos en el identificador único de la confirmación. Para encontrarlo, escribimos:

Hemos resaltado la confirmación con el comentario "agregado hola mundo..." Su identificador único es 6c44e53d06228f888f2f454d3cb8c1c976dd73f8. Queremos crear una rama de "desarrollo" que comience desde este compromiso. Para ello, escribimos:
Se crea una rama con solo las dos primeras confirmaciones de la rama principal. Para verificar esto, primero nos aseguramos de cambiar a una rama diferente y observamos la cantidad de confirmaciones allí:

Y como era de esperar, tenemos dos confirmaciones. Por cierto, aquí hay un punto interesante: todavía no hay un archivo .gitignore en esta rama, por lo que nuestro archivo compilado (GitTest.class) ahora está resaltado con el estado "sin seguimiento".
Ahora podemos revisar nuestras sucursales nuevamente escribiendo esto:
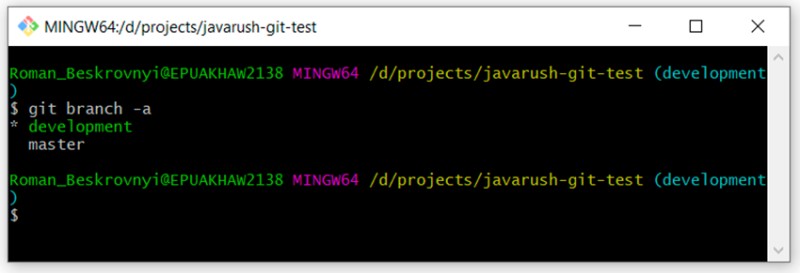
Puede ver que hay dos ramas: "maestro" y "desarrollo". Actualmente estamos en desarrollo.
Vamos a crear una rama basada en la actual
La segunda forma de crear una rama es crearla a partir de otra. Queremos crear una rama basada en la rama maestra. Primero, debemos cambiar a él, y el siguiente paso es crear uno nuevo. Vamos a ver:
- git checkout master: cambie a la rama maestra
- estado de git: verifica que realmente estamos en la rama principal

Aquí puede ver que cambiamos a la rama maestra, el archivo .gitignore está en vigor y la clase compilada ya no está resaltada como "sin seguimiento".
Ahora creamos una nueva rama basada en la rama maestra:

Si no está seguro de si esta rama es lo mismo que "maestro", puede verificarlo fácilmente ejecutando "git log" y observando todas las confirmaciones. Debería haber cuatro de ellos.
La resolución de conflictos
Antes de explorar qué es un conflicto, debemos hablar sobre fusionar una rama con otra.
Esta imagen muestra el proceso de fusionar una rama con otra:

Aquí, tenemos una sucursal principal. En algún momento, se crea una rama secundaria a partir de la rama principal y luego se modifica. Una vez que el trabajo está hecho, necesitamos fusionar una rama con la otra.
En nuestro ejemplo, creamos la rama función/actualizar-archivos-txt. Como lo indica el nombre de la sucursal, estamos actualizando el texto.

Ahora necesitamos crear una nueva confirmación para este trabajo:

Ahora, si queremos fusionar la rama función/actualizar-txt-archivos en maestro, debemos ir a maestro y escribir "git merge función/actualizar-txt-archivos":

Como resultado, la rama maestra ahora también incluye la confirmación que se agregó a los archivos de característica/actualización-txt.
Se agregó esta funcionalidad, por lo que puede eliminar una rama de funciones. Para ello, escribimos:
Compliquemos la situación: ahora digamos que necesita cambiar el archivo txt nuevamente. Pero ahora este archivo también se cambiará en la rama principal. En otras palabras, cambiará en paralelo. Git no podrá averiguar qué hacer cuando queramos fusionar nuestro nuevo código en la rama principal.
Crearemos una nueva rama basada en el maestro, haremos cambios en text_resource.txt y crearemos una confirmación para este trabajo:
... hacemos cambios en el archivo


Vaya a la rama maestra y también actualice este archivo de texto en la misma línea que en la rama de características:
… actualizamos test_resource.txt

Y ahora el punto más interesante: necesitamos fusionar los cambios de la rama característica/agregar encabezado a maestro. Estamos en la rama maestra, por lo que solo necesitamos escribir:
Pero el resultado será un conflicto en el archivo test_resource.txt:

Aquí podemos ver que Git no podía decidir por sí solo cómo fusionar este código. Nos dice que primero debemos resolver el conflicto y solo luego realizar el compromiso.
DE ACUERDO. Abrimos el archivo con el conflicto en un editor de texto y vemos:

Para comprender lo que hizo Git aquí, debemos recordar qué cambios hicimos y dónde, y luego comparar:
- Los cambios que estaban en esta línea en la rama maestra se encuentran entre "<<<<<<< HEAD" y "=======".
- Los cambios que estaban en la rama característica/agregar encabezado se encuentran entre "=======" y ">>>>>>> característica/agregar encabezado".
Así es como Git nos dice que no pudo averiguar cómo realizar la combinación en esta ubicación del archivo. Dividió esta sección en dos partes de las diferentes ramas y nos invita a resolver el conflicto de fusión nosotros mismos.
Me parece bien. Audazmente decido eliminar todo, dejando solo la palabra "encabezado":

Veamos el estado de los cambios. La descripción será ligeramente diferente. En lugar de un estado "modificado", tenemos "no fusionado". Entonces, ¿podríamos haber mencionado un quinto estado? No creo que esto sea necesario. Vamos a ver:

Podemos convencernos de que este es un caso especial, inusual. Continuemos:

Puede notar que la descripción sugiere escribir solo "git commit". Intentemos escribir eso:

Y así lo hicimos, resolvimos el conflicto en la consola.
Por supuesto, esto se puede hacer un poco más fácil en entornos de desarrollo integrado. Por ejemplo, en IntelliJ IDEA, todo está tan bien configurado que puede realizar todas las acciones necesarias dentro de él. Pero los IDE hacen muchas cosas "bajo el capó" y, a menudo, no entendemos qué está sucediendo exactamente allí. Y cuando no hay comprensión, pueden surgir problemas.
Trabajando con repositorios remotos
El último paso es descubrir algunos comandos más que se necesitan para trabajar con el repositorio remoto.
Como dije, un repositorio remoto es un lugar donde se almacena el repositorio y desde el cual puedes clonarlo.
¿Qué tipo de repositorios remotos existen? Ejemplos:
- GitHub es la mayor plataforma de almacenamiento para repositorios y desarrollo colaborativo.
- GitLab es una herramienta basada en web para el ciclo de vida de DevOps con código abierto. Es un sistema basado en Git para administrar repositorios de código con su propio wiki, sistema de seguimiento de errores, canalización de CI/CD y otras funciones.
- BitBucket es un servicio web para alojamiento de proyectos y desarrollo colaborativo basado en los sistemas de control de versiones Mercurial y Git. Hubo un tiempo en que tenía una gran ventaja sobre GitHub, ya que ofrecía repositorios privados gratuitos. El año pasado, GitHub también presentó esta capacidad para todos de forma gratuita.
- Etcétera…
Cuando trabaje con un repositorio remoto, lo primero que debe hacer es clonar el proyecto en su repositorio local.
Para esto, exportamos el proyecto que hicimos localmente. Ahora todos pueden clonarlo por sí mismos escribiendo:
Ahora hay una copia local completa del proyecto. Para asegurarse de que la copia local del proyecto sea la más reciente, debe extraer el proyecto escribiendo:

En nuestro caso, nada en el repositorio remoto ha cambiado en la actualidad, por lo que la respuesta es: Ya está actualizado.
Pero si hacemos algún cambio en el repositorio remoto, el local se actualiza después de extraerlos.
Y finalmente, el último comando es enviar los datos al repositorio remoto. Cuando hemos hecho algo localmente y queremos enviarlo al repositorio remoto, primero debemos crear un nuevo commit localmente. Para demostrar esto, agreguemos algo más a nuestro archivo de texto:

Ahora, algo bastante común para nosotros: creamos un compromiso para este trabajo:
El comando para enviar esto al repositorio remoto es:
¡Eso es todo por ahora!
| Enlaces útiles |
|---|
|
2. Cómo trabajar con Git en IntelliJ IDEA
En esta parte, aprenderá a trabajar con Git en IntelliJ IDEA.
Entradas requeridas:
- Lea, siga y comprenda la parte anterior. Esto ayudará a garantizar que todo esté configurado y listo para funcionar.
- Instale IntelliJ IDEA. Todo debería estar en orden aquí :)
- Asignar una hora para lograr el dominio completo.
Trabajemos con el proyecto de demostración que usé para el artículo sobre Git.
Clonar el proyecto localmente
Aquí hay dos opciones:
- Si ya tiene una cuenta de GitHub y desea impulsar algo más adelante, es mejor bifurcar el proyecto y clonar su propia copia. Puede leer acerca de cómo crear una bifurcación en otro artículo bajo el encabezado Un ejemplo del flujo de trabajo de bifurcación .
- Clone el repositorio y haga todo localmente sin la capacidad de enviar todo al servidor.
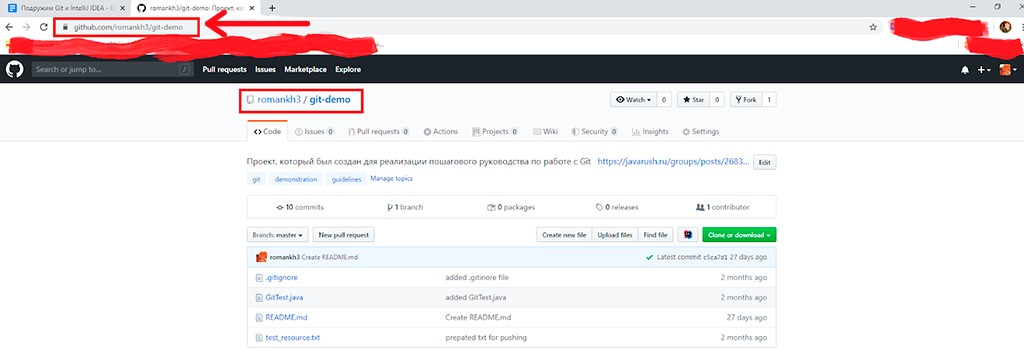
Para clonar un proyecto de GitHub, debe copiar el enlace del proyecto y pasarlo a IntelliJ IDEA:
-
Copie la dirección del proyecto:
![]()
-
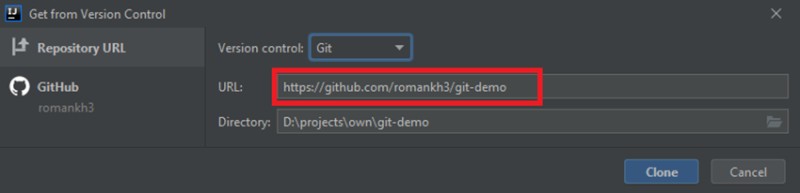
Abra IntelliJ IDEA y seleccione "Obtener del control de versiones":
![]()
-
Copie y pegue la dirección del proyecto:
![]()
-
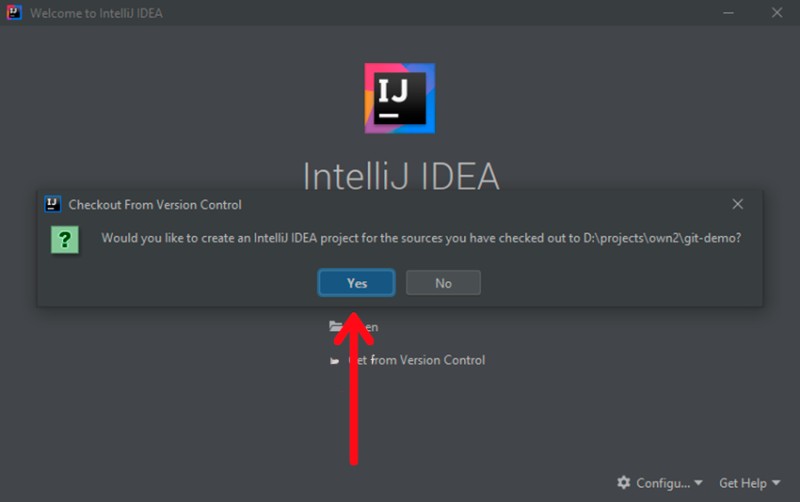
Se le pedirá que cree un proyecto IntelliJ IDEA. Acepto la oferta:
![]()
-
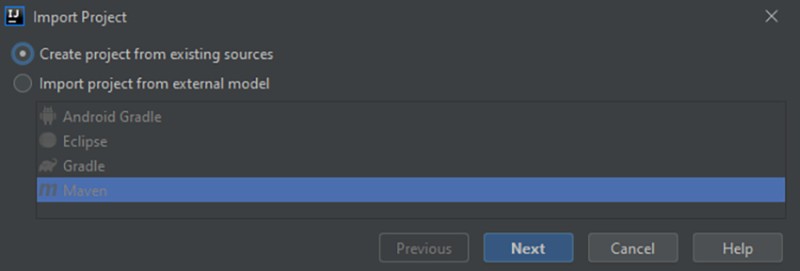
Como no hay un sistema de compilación, seleccionamos "Crear proyecto a partir de fuentes existentes":
![]()
-
A continuación verás esta hermosa pantalla:
![]()

Ahora que descubrimos la clonación, puedes echar un vistazo.
Primer vistazo a IntelliJ IDEA como una interfaz de usuario de Git
Eche un vistazo más de cerca al proyecto clonado: ya puede obtener mucha información sobre el sistema de control de versiones.
Primero, tenemos el panel Control de versiones en la esquina inferior izquierda. Aquí puede encontrar todos los cambios locales y obtener una lista de confirmaciones (análoga a "git log").
Pasemos a una discusión de Log. Hay una cierta visualización que nos ayuda a entender exactamente cómo ha procedido el desarrollo. Por ejemplo, puede ver que se creó una nueva rama con un encabezado agregado a la confirmación de txt, que luego se fusionó con la rama principal. Si hace clic en un compromiso, puede ver en la esquina derecha toda la información sobre el compromiso: todos sus cambios y metadatos.
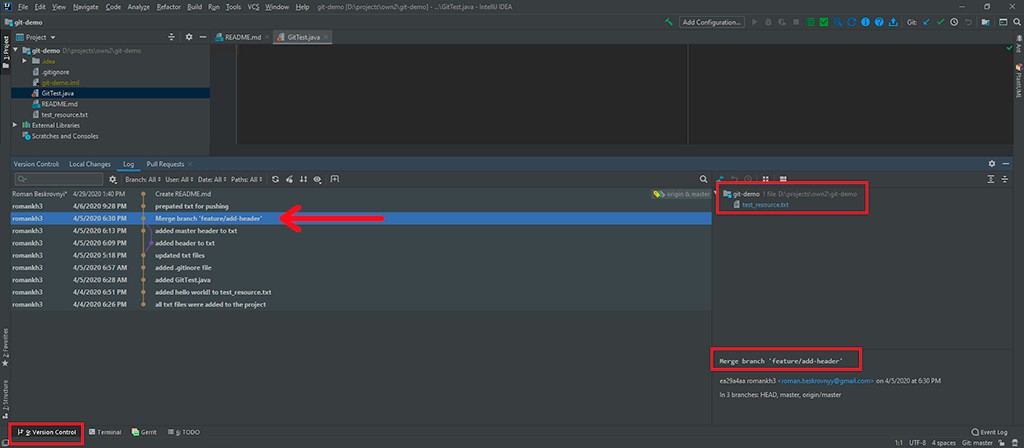
Además, puede ver los cambios reales. También vemos que allí se resolvió un conflicto. IDEA también presenta esto muy bien.
Si hace doble clic en el archivo que se modificó durante este compromiso, veremos cómo se resolvió el conflicto:

Notamos que a la izquierda ya la derecha tenemos las dos versiones del mismo archivo que necesitaban fusionarse en uno. Y en el medio, tenemos el resultado combinado final.
Cuando un proyecto tiene muchas ramas, confirmaciones y usuarios, debe buscar por separado por rama, usuario y fecha:

Antes de comenzar, también vale la pena explicar cómo entender en qué rama estamos.
En la esquina inferior derecha, hay un botón con la etiqueta "Git: maestro". Lo que sigue a "Git:" es la rama actual. Si hace clic en el botón, puede hacer muchas cosas útiles: cambiar a otra rama, crear una nueva, cambiar el nombre de una existente, etc.

Trabajando con un repositorio
Teclas de acceso rápido útiles
Para el trabajo futuro, debe recordar algunas teclas de acceso rápido muy útiles:
- CTRL+T : obtenga los últimos cambios del repositorio remoto (git pull).
- CTRL+K — Crear una confirmación/ver todos los cambios actuales. Esto incluye archivos sin seguimiento y modificados (git commit).
- CTRL+SHIFT+K : este es el comando para enviar cambios al repositorio remoto. Todas las confirmaciones creadas localmente y que aún no están en el repositorio remoto se enviarán (git push).
- ALT+CTRL+Z : revierte los cambios en un archivo específico al estado de la última confirmación creada en el repositorio local. Si selecciona todo el proyecto en la esquina superior izquierda, puede revertir los cambios en todos los archivos.
¿Qué queremos?
Para hacer el trabajo, necesitamos dominar un escenario básico que se usa en todas partes.
El objetivo es implementar una nueva funcionalidad en una rama separada y luego enviarla a un repositorio remoto (entonces también necesita crear una solicitud de extracción para la rama principal, pero eso está más allá del alcance de esta lección).
¿Qué se requiere para hacer esto?
-
Obtenga todos los cambios actuales en la rama principal (por ejemplo, "maestro").
-
Desde esta rama principal, cree una rama separada para su trabajo.
-
Implementar la nueva funcionalidad.
-
Vaya a la sucursal principal y verifique si ha habido algún cambio nuevo mientras estábamos trabajando. Si no, entonces todo está bien. Pero si hubo cambios, hacemos lo siguiente: vamos a la rama de trabajo y rebase los cambios de la rama principal a la nuestra. Si todo va bien, entonces genial. Pero es muy posible que haya conflictos. Da la casualidad de que solo se pueden resolver de antemano, sin perder tiempo en el repositorio remoto.
¿Te preguntas por qué deberías hacer esto? Es de buena educación y evita que ocurran conflictos después de enviar su rama al repositorio local (existe, por supuesto, la posibilidad de que aún ocurran conflictos, pero se vuelve mucho más pequeño ).
-
Empuje sus cambios al repositorio remoto.
¿Cómo obtener cambios desde el servidor remoto?
Agregamos una descripción al LÉAME con una nueva confirmación y queremos obtener estos cambios. Si se realizaron cambios tanto en el repositorio local como en el remoto, se nos invita a elegir entre una fusión y una reorganización. Elegimos fusionarnos.
Introduce CTRL+T :

Ahora puede ver cómo ha cambiado el archivo README, es decir, se extrajeron los cambios del repositorio remoto, y en la esquina inferior derecha puede ver todos los detalles de los cambios que provienen del servidor.

Crear una nueva rama basada en el maestro
Todo es simple aquí.
Vaya a la esquina inferior derecha y haga clic en Git: master . Seleccione + Nueva Sucursal .
 Deje seleccionada la casilla de verificación Sucursal de Checkout e ingrese el nombre de la nueva sucursal. En nuestro caso: será readme-improver .
Deje seleccionada la casilla de verificación Sucursal de Checkout e ingrese el nombre de la nueva sucursal. En nuestro caso: será readme-improver .
Git: master luego cambiará a Git: readme-improver .
Simulemos trabajo paralelo
Para que aparezcan los conflictos, alguien tiene que crearlos.
Editaremos el README con un nuevo commit a través del navegador, simulando así un trabajo paralelo. Es como si alguien hiciera cambios en el mismo archivo mientras trabajábamos en él. El resultado será un conflicto. Eliminaremos la palabra "completamente" de la línea 10.
Implementar nuestra funcionalidad
Nuestra tarea es cambiar el README y agregar una descripción al nuevo artículo. Es decir, el trabajo en Git pasa por IntelliJ IDEA. Agrega esto:

Los cambios están hechos. Ahora podemos crear un compromiso. Presione CTRL+K , lo que nos da:

Antes de crear un compromiso, debemos observar de cerca lo que ofrece esta ventana.
En la sección Mensaje de confirmación , escribimos el texto asociado con la confirmación. Luego, para crearlo, debemos hacer clic en Confirmar .
Escribimos que el README ha cambiado y creamos el commit. Aparece una alerta en la esquina inferior izquierda con el nombre de la confirmación:

Comprobar si la rama principal ha cambiado
Completamos nuestra tarea. Funciona. Escribimos pruebas. Todo esta bien. Pero antes de enviar al servidor, aún debemos verificar si hubo algún cambio en la rama principal mientras tanto. ¿Cómo pudo pasar eso? Bastante fácil: alguien recibe una tarea después de ti, y ese alguien la termina más rápido de lo que tú terminas tu tarea.
Así que tenemos que ir a la rama principal. Para hacer esto, debemos hacer lo que se muestra en la esquina inferior derecha de la siguiente captura de pantalla:

En la rama principal, presione CTRL+T para obtener los últimos cambios del servidor remoto. Al observar los cambios, puede ver fácilmente lo que sucedió:

Se eliminó la palabra "completamente". Tal vez alguien de marketing decidió que no debería escribirse así y le dio a los desarrolladores la tarea de actualizarlo.
Ahora tenemos una copia local de la última versión de la rama maestra. Regrese a readme-improver .
Ahora necesitamos reorganizar los cambios de la rama principal a la nuestra. Nosotros hacemos esto: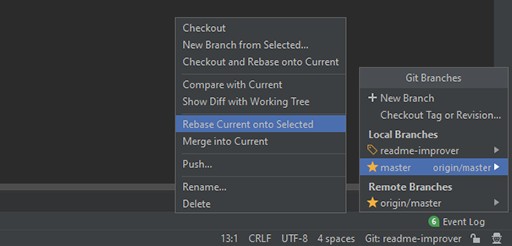
Si hiciste todo correctamente y me seguiste, el resultado debería mostrar un conflicto en el archivo README:

Aquí también tenemos mucha información para entender y empaparnos. Aquí se muestra una lista de archivos (en nuestro caso, un archivo) que tienen conflictos. Podemos elegir entre tres opciones:
- acepte el suyo: acepte solo los cambios de readme-improver.
- acepte los suyos: acepte solo los cambios del maestro.
- fusionar: elija usted mismo lo que desea conservar y lo que descarta.
No está claro qué cambió. Si hay cambios en la rama maestra, deben ser necesarios allí, por lo que no podemos simplemente aceptar nuestros cambios. En consecuencia, seleccionamos merge :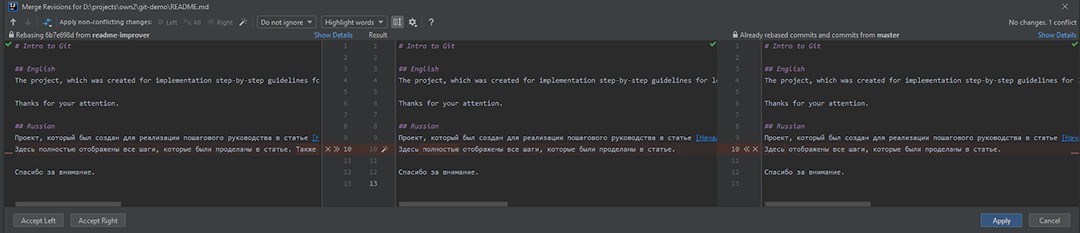
Aquí podemos ver que hay tres partes:
- Estos son los cambios de readme-improver.
- El resultado combinado. Por ahora, es lo que existía antes de los cambios.
- Los cambios de la rama maestra.
Necesitamos producir un resultado combinado que satisfaga a todos. Al revisar lo que se cambió ANTES de nuestros cambios, nos damos cuenta de que simplemente eliminaron la palabra "completamente". ¡Está bien, no hay problema! Eso significa que también lo eliminaremos en el resultado combinado y luego agregaremos nuestros cambios. Una vez que corrijamos el resultado combinado, podemos hacer clic en Aplicar .
Luego aparecerá una notificación, indicándonos que la reorganización fue exitosa:

¡Allá! Resolvimos nuestro primer conflicto a través de IntelliJ IDEA.
Empuje los cambios al servidor remoto
El siguiente paso es enviar los cambios al servidor remoto y crear una solicitud de extracción. Para hacer esto, simplemente presione CTRL+SHIFT+K . Entonces obtenemos:

A la izquierda, habrá una lista de confirmaciones que no se han enviado al repositorio remoto. A la derecha estarán todos los archivos que han cambiado. ¡Y eso es! Presiona Push y experimentarás la felicidad :)
Si la inserción tiene éxito, verá una notificación como esta en la esquina inferior derecha:

Bonificación: crear una solicitud de extracción
Vamos a un repositorio de GitHub y vemos que GitHub ya sabe lo que queremos:

Haga clic en Comparar y extraer solicitud . Luego haga clic en Crear solicitud de extracción . Debido a que resolvimos los conflictos de antemano, ahora, al crear una solicitud de extracción, podemos fusionarla de inmediato: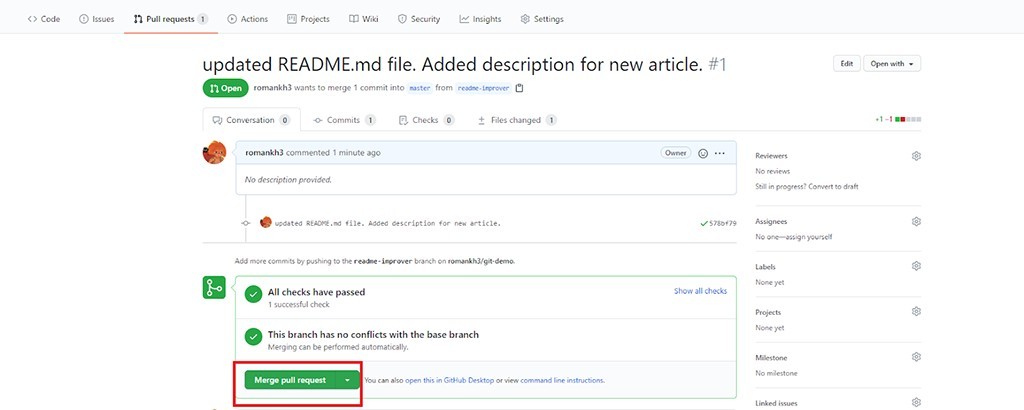
¡Eso es todo por ahora!
GO TO FULL VERSION