1. Un guide détaillé de Git pour les débutants
Aujourd'hui, nous allons parler d'un système de contrôle de version, à savoir Git.
Vous ne pouvez vraiment pas être un programmeur à part entière sans connaître et comprendre cet outil. Bien sûr, vous n'avez pas besoin de garder toutes les commandes et fonctionnalités de Git dans votre tête pour être continuellement employé. Vous devez connaître un ensemble de commandes qui vous aideront à comprendre tout ce qui se passe.
Les bases de Git
Git est un système de contrôle de version distribué pour notre code. Pourquoi en avons-nous besoin? Les équipes ont besoin d'une sorte de système pour gérer leur travail. Il est nécessaire pour suivre les changements qui se produisent au fil du temps.
Autrement dit, nous devons être en mesure de voir étape par étape quels fichiers ont changé et comment. Ceci est particulièrement important lorsque vous recherchez ce qui a changé dans le contexte d'une seule tâche, ce qui permet d'annuler les modifications.
Imaginons la situation suivante : nous avons du code fonctionnel, tout est bon, mais nous décidons ensuite d'améliorer ou de modifier quelque chose. Ce n'est pas grave, mais notre "amélioration" a cassé la moitié des fonctionnalités du programme et l'a rendu impossible à travailler. Et maintenant? Sans Git, vous devriez vous asseoir et réfléchir pendant des heures, en essayant de vous rappeler comment tout était à l'origine. Mais avec Git, nous annulons simplement le commit - et c'est tout.
Ou que se passe-t-il si deux développeurs effectuent leurs propres modifications de code en même temps ? Sans Git, ils copient les fichiers de code d'origine et les modifient séparément. Il arrive un moment où les deux veulent ajouter leurs modifications au répertoire principal. Que faites-vous dans ce cas ?
Il n'y aura pas de tels problèmes si vous utilisez Git.
Installer Git
Installons Java sur votre ordinateur Ce processus diffère légèrement pour les différents systèmes d'exploitation.
Installation sous Windows
Comme d'habitude, vous devez télécharger et exécuter un fichier exe. Tout est simple ici : cliquez sur le premier lien Google , effectuez l'installation, et le tour est joué. Pour ce faire, nous allons utiliser la console bash fournie par Windows.
Sous Windows, vous devez exécuter Git Bash. Voici à quoi cela ressemble dans le menu Démarrer :

Maintenant, c'est une invite de commande avec laquelle vous pouvez travailler.
Pour éviter d'avoir à aller dans le dossier avec le projet à chaque fois afin d'y ouvrir Git, vous pouvez ouvrir l'invite de commande dans le dossier du projet avec le bouton droit de la souris avec le chemin dont nous avons besoin :

Installation sous Linux
Habituellement, Git fait partie des distributions Linux et est déjà installé, car il s'agit d'un outil initialement écrit pour le développement du noyau Linux. Mais il y a des situations où ce n'est pas le cas. Pour vérifier, vous devez ouvrir un terminal et écrire : git --version. Si vous obtenez une réponse intelligible, rien ne doit être installé.
Ouvrez un terminal et installez. Pour Ubuntu, vous devez écrire : sudo apt-get install git. Et c'est tout : vous pouvez désormais utiliser Git dans n'importe quel terminal.
Installation sur macOS
Ici aussi, vous devez d'abord vérifier si Git est déjà là (voir ci-dessus, le même que sur Linux).
Si vous ne l'avez pas, le moyen le plus simple de l'obtenir est de télécharger la dernière version . Si Xcode est installé, alors Git sera définitivement installé automatiquement.
Paramètres Git
Git a des paramètres utilisateur pour l'utilisateur qui soumettra le travail. Cela a du sens et est nécessaire, car Git prend ces informations pour le champ Auteur lorsqu'un commit est créé.
Configurez un nom d'utilisateur et un mot de passe pour tous vos projets en exécutant les commandes suivantes :
Si vous avez besoin de changer l'auteur pour un projet spécifique (pour un projet personnel, par exemple), vous pouvez supprimer "--global". Cela nous donnera ceci :
Un peu de théorie
Pour plonger dans le sujet, nous devrions vous présenter quelques nouveaux mots et actions... Sinon, il n'y aura rien à dire. Bien sûr, c'est du jargon qui nous vient de l'anglais, donc j'ajouterai les traductions entre parenthèses.
Quels mots et actions ?
- référentiel git
- commettre
- bifurquer
- fusionner
- conflits
- tirer
- pousser
- comment ignorer certains fichiers (.gitignore)
Et ainsi de suite.
Statuts dans Git
Git a plusieurs statues qui doivent être comprises et mémorisées :
- non suivi
- modifié
- mise en scène
- engagé
Comment devriez-vous comprendre cela?
Ce sont des statuts qui s'appliquent aux fichiers contenant notre code. En d'autres termes, leur cycle de vie ressemble généralement à ceci :
- Un fichier qui est créé mais pas encore ajouté au référentiel a le statut "non suivi".
- Lorsque nous apportons des modifications à des fichiers qui ont déjà été ajoutés au référentiel Git, leur statut est "modifié".
- Parmi les fichiers que nous avons modifiés, nous sélectionnons ceux dont nous avons besoin (par exemple, nous n'avons pas besoin de classes compilées), et ces classes passent au statut "staged".
- Un commit est créé à partir de fichiers préparés à l'état intermédiaire et est placé dans le référentiel Git. Après cela, il n'y a plus de fichiers avec le statut "stage". Mais il peut encore y avoir des fichiers dont le statut est "modifié".
Voici à quoi ça ressemble:

Qu'est-ce qu'un engagement ?
Un commit est l'événement principal en matière de contrôle de version. Il contient toutes les modifications apportées depuis le début de la validation. Les commits sont liés entre eux comme une liste à liens simples.
Plus précisément, il y a un premier commit. Lorsque le second commit est créé, il (le second) sait ce qui vient après le premier. Et de cette manière, les informations peuvent être suivies.
Un commit possède également ses propres informations, appelées métadonnées :
- l'identifiant unique du commit, qui peut être utilisé pour le trouver
- le nom de l'auteur du commit, qui l'a créé
- la date de création du commit
- un commentaire qui décrit ce qui a été fait pendant le commit
Voici à quoi ça ressemble :

Qu'est-ce qu'une succursale ?

Une branche est un pointeur vers un commit. Parce qu'un commit sait quel commit le précède, lorsqu'une branche pointe vers un commit, tous ces commits précédents s'appliquent également à lui.
En conséquence, nous pourrions dire que vous pouvez avoir autant de branches que vous le souhaitez pointant vers le même commit.
Le travail se passe dans les branches, donc lorsqu'un nouveau commit est créé, la branche déplace son pointeur vers le commit le plus récent.
Premiers pas avec Git
Vous pouvez travailler avec un référentiel local seul ou avec un référentiel distant.

Pour pratiquer les commandes requises, vous pouvez vous limiter au référentiel local. Il stocke uniquement toutes les informations du projet localement dans le dossier .git.
Si nous parlons du référentiel distant, alors toutes les informations sont stockées quelque part sur le serveur distant : seule une copie du projet est stockée localement. Les modifications apportées à votre copie locale peuvent être poussées (git push) vers le référentiel distant.
Dans notre discussion ici et ci-dessous, nous parlons de travailler avec Git dans la console. Bien sûr, vous pouvez utiliser une sorte de solution basée sur une interface graphique (par exemple, IntelliJ IDEA), mais vous devez d'abord déterminer quelles commandes sont exécutées et ce qu'elles signifient.
Travailler avec Git dans un référentiel local
Pour créer un dépôt local, vous devez écrire :

Cela créera un dossier .git caché dans le répertoire actuel de la console.
Le dossier .git stocke toutes les informations sur le référentiel Git. Ne le supprimez pas ;)
Ensuite, les fichiers sont ajoutés au projet et se voient attribuer le statut "Untracked". Pour vérifier l'état actuel de votre travail, écrivez ceci :
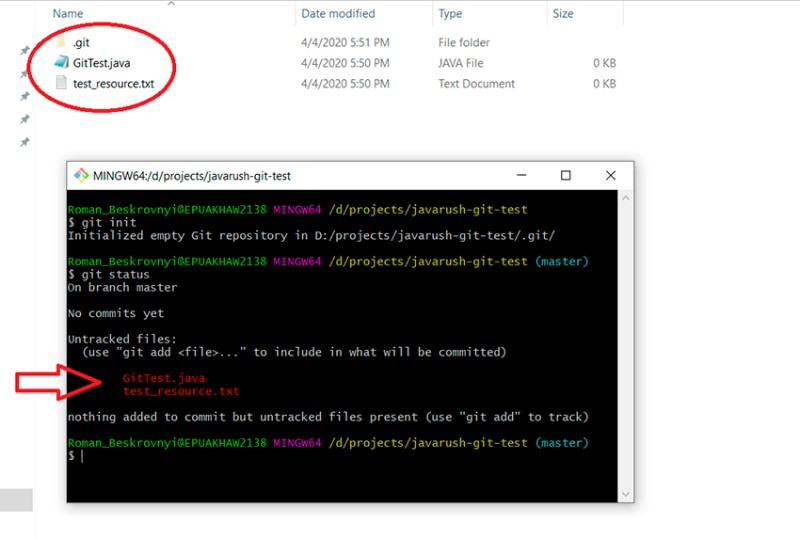
Nous sommes dans la branche master, et nous y resterons jusqu'à ce que nous passions à une autre branche.
Cela montre quels fichiers ont été modifiés mais n'ont pas encore été ajoutés au statut "mis en scène". Pour les ajouter au statut "staged", vous devez écrire "git add". Nous avons quelques options ici, par exemple :
- git add -A — ajoute tous les fichiers au statut "staged"
- git add . — ajouter tous les fichiers de ce dossier et de tous les sous-dossiers. Essentiellement le même que le précédent;
- git add <file name> — ajoute un fichier spécifique. Ici, vous pouvez utiliser des expressions régulières pour ajouter des fichiers selon un modèle. Par exemple, git add *.java : Cela signifie que vous souhaitez uniquement ajouter des fichiers avec l'extension java.
Les deux premières options sont clairement simples. Les choses deviennent plus intéressantes avec le dernier ajout, alors écrivons :
Pour vérifier l'état, nous utilisons la commande déjà connue de nous :

Ici, vous pouvez voir que l'expression régulière a fonctionné correctement : test_resource.txt a maintenant le statut "staged".
Et enfin, la dernière étape pour travailler avec un référentiel local (il y en a une de plus lorsque vous travaillez avec le référentiel distant ;)) — création d'un nouveau commit :

La prochaine étape est une excellente commande pour consulter l'historique des commits sur une branche. Profitons-en :

Ici, vous pouvez voir que nous avons créé notre premier commit et qu'il inclut le texte que nous avons fourni sur la ligne de commande. Il est très important de comprendre que ce texte doit expliquer le plus précisément possible ce qui a été fait lors de ce commit. Cela nous aidera plusieurs fois à l'avenir.
Un lecteur curieux qui ne s'est pas encore endormi peut se demander ce qui est arrivé au fichier GitTest.java. Découvrons dès maintenant. Pour ce faire, nous utilisons :

Comme vous pouvez le voir, il est toujours "non suivi" et attend dans les coulisses. Mais que se passe-t-il si nous ne voulons pas du tout l'ajouter au projet ? Cela arrive parfois.
Pour rendre les choses plus intéressantes, essayons maintenant de modifier notre fichier test_resource.txt. Ajoutons du texte ici et vérifions l'état :

Ici, vous pouvez clairement voir la différence entre les statuts "non suivi" et "modifié".
GitTest.java est "non suivi", tandis que test_resource.txt est "modifié".
Maintenant que nous avons des fichiers à l'état modifié, nous pouvons examiner les modifications qui leur ont été apportées. Cela peut être fait en utilisant la commande suivante :

C'est-à-dire que vous pouvez clairement voir ici ce que j'ai ajouté à notre fichier texte : hello world !
Ajoutons nos modifications au fichier texte et créons un commit :
Pour voir tous les commits, écrivez :

Comme vous pouvez le voir, nous avons maintenant deux commits.
Nous ajouterons GitTest.java de la même manière. Pas de commentaires ici, juste des commandes :

Travailler avec .gitignore
De toute évidence, nous ne voulons conserver que le code source, et rien d'autre, dans le référentiel. Alors que pourrait-il y avoir d'autre ? Au minimum, des classes compilées et/ou des fichiers générés par des environnements de développement.
Pour dire à Git de les ignorer, nous devons créer un fichier spécial. Faites ceci : créez un fichier appelé .gitignore à la racine du projet. Chaque ligne de ce fichier représente un modèle à ignorer.
Dans cet exemple, le fichier .gitignore ressemblera à ceci :
target/
*.iml
.idea/
Nous allons jeter un coup d'oeil:
- La première ligne consiste à ignorer tous les fichiers avec l'extension .class
- La deuxième ligne consiste à ignorer le dossier "target" et tout ce qu'il contient
- La troisième ligne consiste à ignorer tous les fichiers avec l'extension .iml
- La quatrième ligne consiste à ignorer le dossier .idea
Essayons d'utiliser un exemple. Pour voir comment cela fonctionne, ajoutons la classe GitTest.class compilée au projet et vérifions l'état du projet :

De toute évidence, nous ne voulons pas ajouter accidentellement la classe compilée au projet (en utilisant git add -A). Pour ce faire, créez un fichier .gitignore et ajoutez tout ce qui a été décrit précédemment :

Utilisons maintenant un commit pour ajouter le fichier .gitignore au projet :
Et maintenant le moment de vérité : nous avons une classe compilée GitTest.class qui est "untracked", que nous ne voulions pas ajouter au dépôt Git.
Nous devrions maintenant voir les effets du fichier .gitignore :

Parfait! .gitignore +1 :)
Travailler avec les succursales
Naturellement, travailler dans une seule branche n'est pas pratique pour les développeurs solitaires, et c'est impossible lorsqu'il y a plus d'une personne dans une équipe. C'est pourquoi nous avons des succursales.
Une branche n'est qu'un pointeur mobile vers les commits.
Dans cette partie, nous allons explorer le travail dans différentes branches : comment fusionner les modifications d'une branche à une autre, quels conflits peuvent survenir, et bien plus encore.
Pour voir une liste de toutes les branches du référentiel et comprendre dans laquelle vous vous trouvez, vous devez écrire :

Vous pouvez voir que nous n'avons qu'une seule branche master. L'astérisque devant indique que nous y sommes. Au fait, vous pouvez également utiliser la commande "git status" pour savoir dans quelle branche nous sommes.
Ensuite, il existe plusieurs options pour créer des branches (il peut y en avoir plus - ce sont celles que j'utilise):
- créer une nouvelle succursale basée sur celle dans laquelle nous nous trouvons (99% des cas)
- créer une branche basée sur un commit spécifique (1% des cas)
Créons une branche basée sur un commit spécifique
Nous nous baserons sur l'identifiant unique du commit. Pour le trouver, on écrit :

Nous avons mis en évidence le commit avec le commentaire « added hello world... » Son identifiant unique est 6c44e53d06228f888f2f454d3cb8c1c976dd73f8. Nous souhaitons créer une branche "development" qui démarre à partir de ce commit. Pour ce faire, nous écrivons :
Une branche est créée avec uniquement les deux premiers commits de la branche master. Pour vérifier cela, nous nous assurons d'abord de basculer vers une branche différente et de regarder le nombre de commits là-bas :

Et comme prévu, nous avons deux commits. Au fait, voici un point intéressant : il n'y a pas encore de fichier .gitignore dans cette branche, donc notre fichier compilé (GitTest.class) est maintenant mis en surbrillance avec le statut "non suivi".
Nous pouvons maintenant revoir nos branches en écrivant ceci :
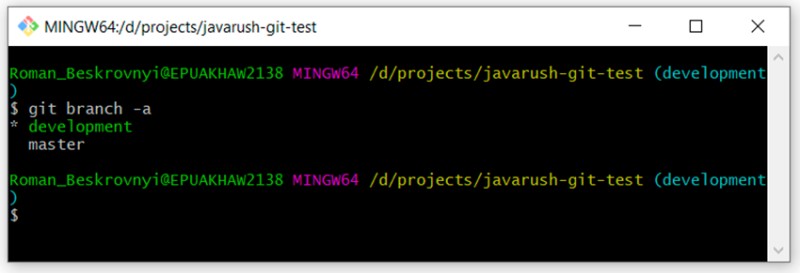
Vous pouvez voir qu'il y a deux branches : "master" et "development". Nous sommes actuellement en développement.
Créons une branche basée sur la branche actuelle
La deuxième façon de créer une branche est de la créer à partir d'une autre. Nous voulons créer une branche basée sur la branche master. Tout d'abord, nous devons y basculer, et l'étape suivante consiste à en créer un nouveau. Nous allons jeter un coup d'oeil:
- git checkout master — passer à la branche master
- git status — vérifie que nous sommes bien dans la branche master

Ici, vous pouvez voir que nous sommes passés à la branche master, le fichier .gitignore est en vigueur et la classe compilée n'est plus mise en surbrillance comme "non suivie".
Nous créons maintenant une nouvelle branche basée sur la branche master :

Si vous ne savez pas si cette branche est la même que "master", vous pouvez facilement vérifier en exécutant "git log" et en regardant tous les commits. Il devrait y en avoir quatre.
Résolution de conflit
Avant d'explorer ce qu'est un conflit, nous devons parler de la fusion d'une branche dans une autre.
Cette image illustre le processus de fusion d'une branche dans une autre :

Ici, nous avons une branche principale. À un moment donné, une branche secondaire est créée à partir de la branche principale, puis modifiée. Une fois le travail terminé, nous devons fusionner une branche dans l'autre.
Dans notre exemple, nous avons créé la branche feature/update-txt-files. Comme indiqué par le nom de la succursale, nous mettons à jour le texte.

Nous devons maintenant créer un nouveau commit pour ce travail :

Maintenant, si nous voulons fusionner la branche feature/update-txt-files dans master, nous devons aller dans master et écrire "git merge feature/update-txt-files":

Par conséquent, la branche master inclut désormais également le commit qui a été ajouté à feature/update-txt-files.
Cette fonctionnalité a été ajoutée, vous pouvez donc supprimer une branche de fonctionnalité. Pour ce faire, nous écrivons :
Compliquons la situation : disons maintenant que vous devez à nouveau modifier le fichier txt. Mais maintenant, ce fichier sera également modifié dans la branche master. En d'autres termes, il changera en parallèle. Git ne pourra pas savoir quoi faire lorsque nous voulons fusionner notre nouveau code dans la branche master.
Nous allons créer une nouvelle branche basée sur master, apporter des modifications à text_resource.txt et créer un commit pour ce travail :
... nous apportons des modifications au fichier


Allez dans la branche master et mettez également à jour ce fichier texte sur la même ligne que dans la branche feature :
… nous avons mis à jour test_resource.txt

Et maintenant, le point le plus intéressant : nous devons fusionner les modifications de la branche feature/add-header vers master. Nous sommes dans la branche master, il suffit donc d'écrire :
Mais le résultat sera un conflit dans le fichier test_resource.txt :

Ici, nous pouvons voir que Git n'a pas pu décider seul comment fusionner ce code. Cela nous indique que nous devons d'abord résoudre le conflit, puis effectuer la validation.
D'ACCORD. Nous ouvrons le fichier avec le conflit dans un éditeur de texte et voyons :

Pour comprendre ce que Git a fait ici, nous devons nous souvenir des modifications que nous avons apportées et où, puis comparer :
- Les modifications qui se trouvaient sur cette ligne dans la branche master se trouvent entre "<<<<<<< HEAD" et "=======".
- Les modifications qui se trouvaient dans la branche feature/add-header se trouvent entre "=======" et ">>>>>>> feature/add-header".
C'est ainsi que Git nous dit qu'il n'a pas pu comprendre comment effectuer la fusion à cet endroit du fichier. Il a divisé cette section en deux parties à partir des différentes branches et nous invite à résoudre nous-mêmes le conflit de fusion.
Assez juste. Je décide hardiment de tout supprimer, ne laissant que le mot "header":

Regardons l'état des changements. La description sera légèrement différente. Plutôt qu'un statut "modifié", nous avons "unmerged". Alors aurions-nous pu mentionner un cinquième statut ? Je ne pense pas que ce soit nécessaire. Voyons:

Nous pouvons nous convaincre qu'il s'agit d'un cas particulier et inhabituel. Nous allons continuer:

Vous remarquerez peut-être que la description suggère d'écrire uniquement "git commit". Essayons d'écrire ça :

Et juste comme ça, nous l'avons fait - nous avons résolu le conflit dans la console.
Bien sûr, cela peut être fait un peu plus facilement dans les environnements de développement intégrés. Par exemple, dans IntelliJ IDEA, tout est si bien configuré que vous pouvez effectuer toutes les actions nécessaires directement à l'intérieur. Mais les IDE font beaucoup de choses "sous le capot", et nous ne comprenons souvent pas exactement ce qui s'y passe. Et quand il n'y a pas de compréhension, des problèmes peuvent survenir.
Travailler avec des référentiels distants
La dernière étape consiste à déterminer quelques commandes supplémentaires nécessaires pour travailler avec le référentiel distant.
Comme je l'ai dit, un référentiel distant est un endroit où le référentiel est stocké et à partir duquel vous pouvez le cloner.
Quels types de référentiels distants existe-t-il ? Exemples:
- GitHub est la plus grande plate-forme de stockage pour les référentiels et le développement collaboratif.
- GitLab est un outil Web pour le cycle de vie DevOps avec open source. Il s'agit d'un système basé sur Git pour gérer les référentiels de code avec son propre wiki, son système de suivi des bogues, son pipeline CI/CD et d'autres fonctions.
- BitBucket est un service web d'hébergement de projets et de développement collaboratif basé sur les systèmes de contrôle de version Mercurial et Git. À une certaine époque, il avait un gros avantage sur GitHub en ce sens qu'il offrait des référentiels privés gratuits. L'année dernière, GitHub a également présenté cette fonctionnalité à tout le monde gratuitement.
- Et ainsi de suite…
Lorsque vous travaillez avec un référentiel distant, la première chose à faire est de cloner le projet dans votre référentiel local.
Pour cela, nous avons exporté le projet que nous avons réalisé localement Maintenant chacun peut le cloner pour lui-même en écrivant :
Il existe maintenant une copie locale complète du projet. Pour être sûr que la copie locale du projet est la plus récente, vous devez extraire le projet en écrivant :

Dans notre cas, rien n'a changé dans le référentiel distant pour le moment, la réponse est donc : déjà à jour.
Mais si nous apportons des modifications au référentiel distant, le référentiel local est mis à jour après leur extraction.
Et enfin, la dernière commande consiste à pousser les données vers le référentiel distant. Lorsque nous avons fait quelque chose localement et que nous voulons l'envoyer au référentiel distant, nous devons d'abord créer un nouveau commit localement. Pour le démontrer, ajoutons autre chose à notre fichier texte :

Maintenant quelque chose d'assez commun pour nous — nous créons un commit pour ce travail :
La commande pour pousser ceci vers le référentiel distant est :
C'est tout pour le moment!
| Liens utiles |
|---|
|
2. Comment travailler avec Git dans IntelliJ IDEA
Dans cette partie, vous apprendrez à travailler avec Git dans IntelliJ IDEA.
Entrées requises :
- Lisez, suivez et comprenez la partie précédente. Cela aidera à s'assurer que tout est configuré et prêt à fonctionner.
- Installez IntelliJ IDEA. Tout devrait être en ordre ici :)
- Allouer une heure pour atteindre une maîtrise complète.
Travaillons avec le projet de démonstration que j'ai utilisé pour l'article sur Git.
Cloner le projet localement
Il y a deux options ici:
- Si vous avez déjà un compte GitHub et que vous souhaitez pousser quelque chose plus tard, il est préférable de bifurquer le projet et de cloner votre propre copie. Vous pouvez en savoir plus sur la création d'un fork dans un autre article sous le titre Un exemple de workflow de fork .
- Clonez le référentiel et faites tout localement sans avoir la possibilité de tout transférer sur le serveur.
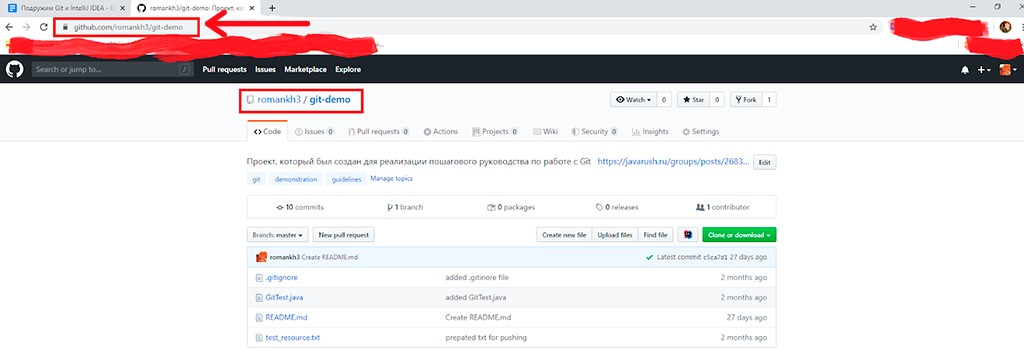
Pour cloner un projet depuis GitHub, vous devez copier le lien du projet et le transmettre à IntelliJ IDEA :
-
Copiez l'adresse du projet :
![]()
-
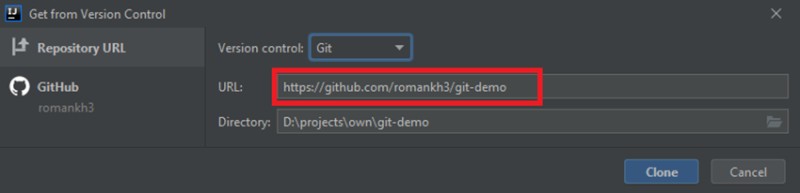
Ouvrez IntelliJ IDEA et sélectionnez "Get from Version Control":
![]()
-
Copiez et collez l'adresse du projet :
![]()
-
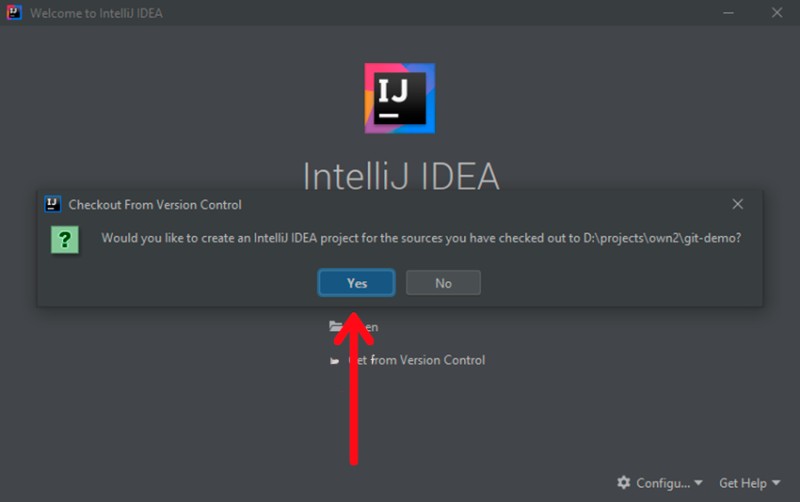
Vous serez invité à créer un projet IntelliJ IDEA. Acceptez l'offre :
![]()
-
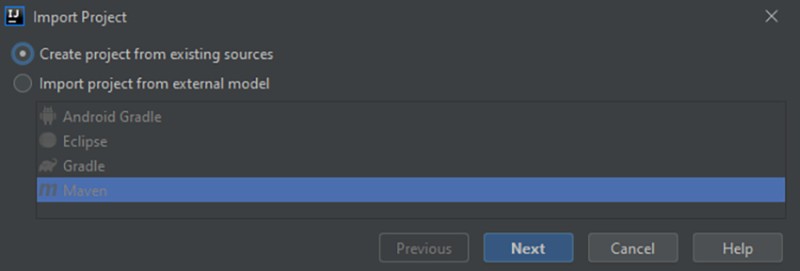
Puisqu'il n'y a pas de système de construction, nous sélectionnons "Créer un projet à partir de sources existantes":
![]()
-
Ensuite, vous verrez ce magnifique écran :
![]()

Maintenant que nous avons compris le clonage, vous pouvez jeter un coup d'œil.
Premier aperçu d'IntelliJ IDEA en tant qu'interface utilisateur Git
Examinez de plus près le projet cloné : vous pouvez déjà obtenir de nombreuses informations sur le système de contrôle de version.
Tout d'abord, nous avons le volet Version Control dans le coin inférieur gauche. Ici, vous pouvez trouver toutes les modifications locales et obtenir une liste des commits (analogue à "git log").
Passons à une discussion sur Log. Il existe une certaine visualisation qui nous aide à comprendre exactement comment le développement s'est déroulé. Par exemple, vous pouvez voir qu'une nouvelle branche a été créée avec un en-tête ajouté au commit txt, qui a ensuite été fusionné dans la branche principale. Si vous cliquez sur un commit, vous pouvez voir dans le coin droit toutes les informations sur le commit : toutes ses modifications et métadonnées.
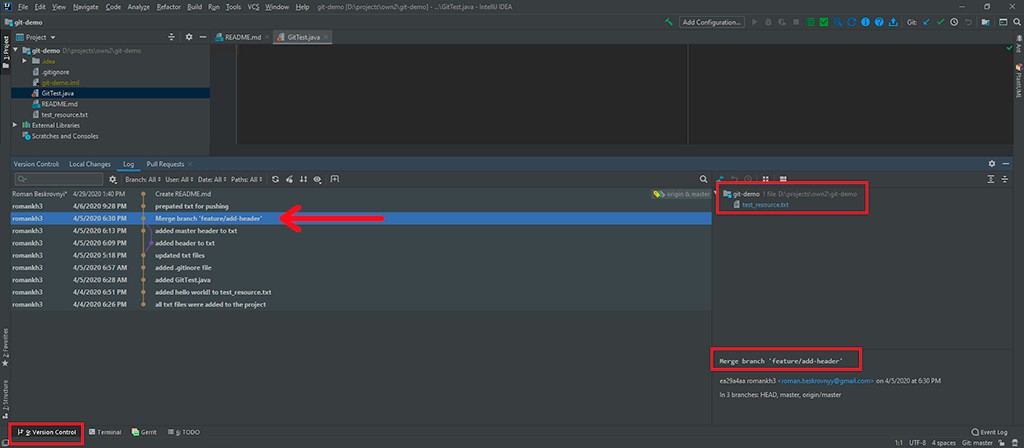
De plus, vous pouvez voir les changements réels. On voit aussi qu'un conflit s'y est résolu. IDEA le présente également très bien.
Si vous double-cliquez sur le fichier qui a été modifié lors de ce commit, nous verrons comment le conflit a été résolu :

Nous notons qu'à gauche et à droite, nous avons les deux versions du même fichier qui devaient être fusionnées en une seule. Et au milieu, nous avons le résultat final fusionné.
Lorsqu'un projet comporte de nombreuses branches, commits et utilisateurs, vous devez rechercher séparément par branche, utilisateur et date :

Avant de se lancer, il est également utile d'expliquer comment comprendre dans quelle branche on se situe.
Dans le coin inférieur droit, il y a un bouton intitulé "Git : master". Tout ce qui suit "Git :" est la branche actuelle. Si vous cliquez sur le bouton, vous pouvez faire beaucoup de choses utiles : basculer vers une autre branche, en créer une nouvelle, renommer une existante, etc.

Travailler avec un référentiel
Raccourcis clavier utiles
Pour les travaux futurs, vous devez vous souvenir de quelques raccourcis clavier très utiles :
- CTRL+T — Récupère les dernières modifications depuis le référentiel distant (git pull).
- CTRL+K — Créer un commit / voir toutes les modifications en cours. Cela inclut à la fois les fichiers non suivis et modifiés (git commit).
- CTRL+SHIFT+K — Il s'agit de la commande permettant de pousser les modifications vers le référentiel distant. Tous les commits créés localement et pas encore dans le dépôt distant seront poussés (git push).
- ALT+CTRL+Z — Restauration des modifications d'un fichier spécifique à l'état du dernier commit créé dans le référentiel local. Si vous sélectionnez l'intégralité du projet dans le coin supérieur gauche, vous pouvez annuler les modifications apportées à tous les fichiers.
Que voulons-nous?
Pour faire le travail, nous devons maîtriser un scénario de base qui est utilisé partout.
L'objectif est d'implémenter une nouvelle fonctionnalité dans une branche distincte, puis de la transférer vers un référentiel distant (vous devez également créer une demande d'extraction vers la branche principale, mais cela dépasse le cadre de cette leçon).
Que faut-il pour faire cela ?
-
Obtenez toutes les modifications actuelles dans la branche principale (par exemple, "master").
-
À partir de cette branche principale, créez une branche distincte pour votre travail.
-
Implémenter la nouvelle fonctionnalité.
-
Allez à la branche principale et vérifiez s'il y a eu de nouveaux changements pendant que nous travaillions. Si non, alors tout va bien. Mais s'il y a eu des modifications, nous procédons comme suit : accédez à la branche de travail et rebasez les modifications de la branche principale sur la nôtre. Si tout se passe bien, tant mieux. Mais il est tout à fait possible qu'il y ait des conflits. En l'occurrence, ils peuvent simplement être résolus à l'avance, sans perdre de temps dans le référentiel distant.
Vous vous demandez pourquoi vous devriez faire cela ? C'est une bonne manière et empêche les conflits de se produire après avoir poussé votre branche vers le référentiel local (il y a, bien sûr, une possibilité que des conflits se produisent encore, mais cela devient beaucoup plus petit ).
-
Poussez vos modifications vers le référentiel distant.
Comment obtenir les modifications du serveur distant ?
Nous avons ajouté une description au README avec un nouveau commit et souhaitons obtenir ces modifications. Si des modifications ont été apportées à la fois dans le dépôt local et dans le dépôt distant, alors nous sommes invités à choisir entre une fusion et un rebase. Nous choisissons de fusionner.
Entrez CTRL+T :

Vous pouvez maintenant voir comment le README a changé, c'est-à-dire que les modifications du référentiel distant ont été intégrées, et dans le coin inférieur droit, vous pouvez voir tous les détails des modifications provenant du serveur.

Créer une nouvelle branche basée sur master
Tout est simple ici.
Allez dans le coin inférieur droit et cliquez sur Git: master . Sélectionnez + Nouvelle branche .
 Laissez la case Checkout branch cochée et saisissez le nom de la nouvelle succursale. Dans notre cas : ce sera readme-improver .
Laissez la case Checkout branch cochée et saisissez le nom de la nouvelle succursale. Dans notre cas : ce sera readme-improver .
Git: master deviendra alors Git: readme-improver .
Simulons le travail en parallèle
Pour que des conflits apparaissent, quelqu'un doit les créer.
Nous allons éditer le README avec un nouveau commit via le navigateur, simulant ainsi un travail parallèle. C'est comme si quelqu'un apportait des modifications au même fichier pendant que nous travaillions dessus. Le résultat sera un conflit. Nous supprimerons le mot "fully" de la ligne 10.
Implémenter nos fonctionnalités
Notre tâche consiste à modifier le README et à ajouter une description au nouvel article. Autrement dit, le travail dans Git passe par IntelliJ IDEA. Ajoute ça:

Les modifications sont faites. Nous pouvons maintenant créer un commit. Appuyez sur CTRL+K , ce qui nous donne :

Avant de créer un commit, nous devons regarder de près ce que propose cette fenêtre.
Dans la section Commit Message , nous écrivons le texte associé au commit. Ensuite, pour le créer, nous devons cliquer sur Commit .
Nous écrivons que le README a changé et créons le commit. Une alerte apparaît dans le coin inférieur gauche avec le nom du commit :

Vérifier si la branche principale a changé
Nous avons terminé notre tâche. Ça marche. Nous avons écrit des tests. Tout va bien. Mais avant de pousser sur le serveur, nous devons encore vérifier s'il y a eu des changements dans la branche principale entre-temps. Comment cela a-t-il pu arriver ? Assez facilement : quelqu'un reçoit une tâche après vous, et que quelqu'un la termine plus rapidement que vous ne terminez votre tâche.
Nous devons donc nous rendre dans la branche master. Pour ce faire, nous devons faire ce qui est indiqué dans le coin inférieur droit de la capture d'écran ci-dessous :

Dans la branche master, appuyez sur CTRL+T pour obtenir ses dernières modifications depuis le serveur distant. En regardant les changements, vous pouvez facilement voir ce qui s'est passé :

Le mot "fully" a été supprimé. Peut-être que quelqu'un du marketing a décidé qu'il ne devrait pas être écrit comme ça et a donné aux développeurs la tâche de le mettre à jour.
Nous avons maintenant une copie locale de la dernière version de la branche master. Retournez au fichier readme-improver .
Nous devons maintenant rebaser les modifications de la branche master vers la nôtre. Nous faisons ceci :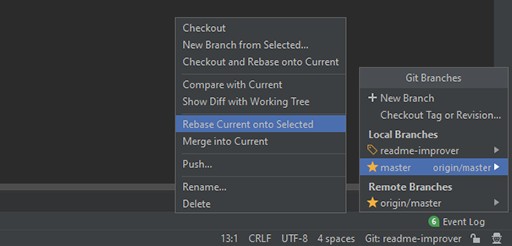
Si vous avez tout fait correctement et suivi avec moi, le résultat devrait montrer un conflit dans le fichier README :

Ici, nous avons également beaucoup d'informations à comprendre et à absorber. Voici une liste de fichiers (dans notre cas, un fichier) qui ont des conflits. Nous pouvons choisir parmi trois options :
- acceptez le vôtre - n'acceptez que les modifications du fichier readme-improver.
- accepter les leurs — n'accepter que les modifications du maître.
- fusionner - choisissez vous-même ce que vous voulez garder et ce que vous voulez jeter.
Ce qui a changé n'est pas clair. S'il y a des changements dans la branche master, ils doivent y être nécessaires, nous ne pouvons donc pas simplement accepter nos changements. En conséquence, nous sélectionnons merge :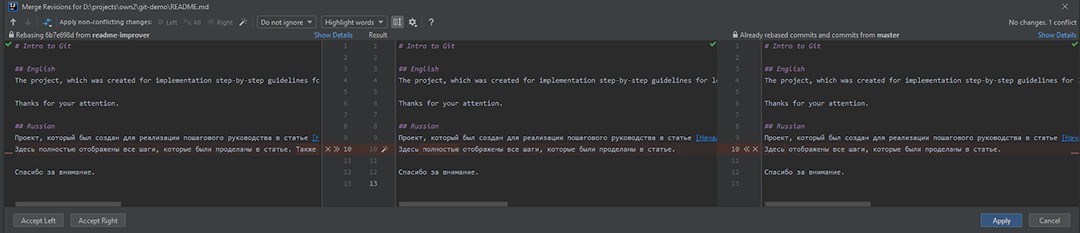
On voit ici qu'il y a trois parties :
- Ce sont les changements de readme-improver.
- Le résultat fusionné. Pour l'instant, c'est ce qui existait avant les changements.
- Les changements de la branche master.
Nous devons produire un résultat fusionné qui satisfera tout le monde. En examinant ce qui a été modifié AVANT nos modifications, nous nous rendons compte qu'ils ont simplement supprimé le mot "fully". D'accord pas de problème! Cela signifie que nous allons également le supprimer dans le résultat fusionné, puis ajouter nos modifications. Une fois que nous avons corrigé le résultat fusionné, nous pouvons cliquer sur Appliquer .
Ensuite, une notification apparaîtra, nous indiquant que le rebase a réussi :

Là! Nous avons résolu notre premier conflit grâce à IntelliJ IDEA.
Pousser les modifications vers le serveur distant
L'étape suivante consiste à envoyer les modifications au serveur distant et à créer une demande d'extraction. Pour ce faire, appuyez simplement sur CTRL+SHIFT+K . Alors on obtient :

Sur la gauche, il y aura une liste des commits qui n'ont pas été poussés vers le référentiel distant. Sur la droite seront tous les fichiers qui ont changé. Et c'est tout! Appuyez sur Push et vous ferez l'expérience du bonheur :)
Si le push réussit, vous verrez une notification comme celle-ci dans le coin inférieur droit :

Bonus : création d'une pull request
Allons dans un dépôt GitHub et nous voyons que GitHub sait déjà ce que nous voulons :

Cliquez sur Comparer et retirer la demande . Cliquez ensuite sur Créer une demande d'extraction . Parce que nous avons résolu les conflits à l'avance, maintenant lors de la création d'une pull request, nous pouvons immédiatement la fusionner :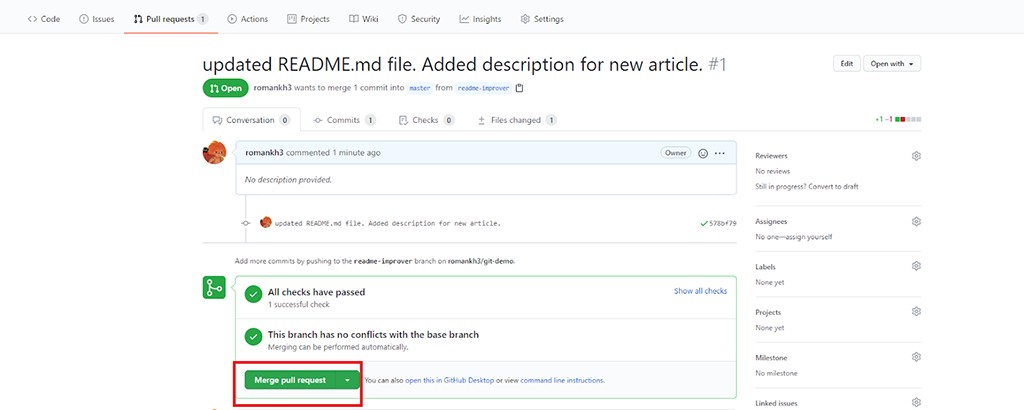
C'est tout pour le moment!
GO TO FULL VERSION