Нека разберем метода newWorkStealingPool , който подготвя ExecutorService за нас.

Този пул от теми е специален. Поведението му се основава на идеята за „кражба“ на работа.
Задачите се поставят на опашка и се разпределят между процесорите. Но ако един процесор е зает, тогава друг свободен процесор може да открадне задача от него и да я изпълни. Този формат е въведен в Java, за да се намалят конфликтите в многонишкови applications. Той е изграден върху рамката fork/join .
разклонение/съединяване
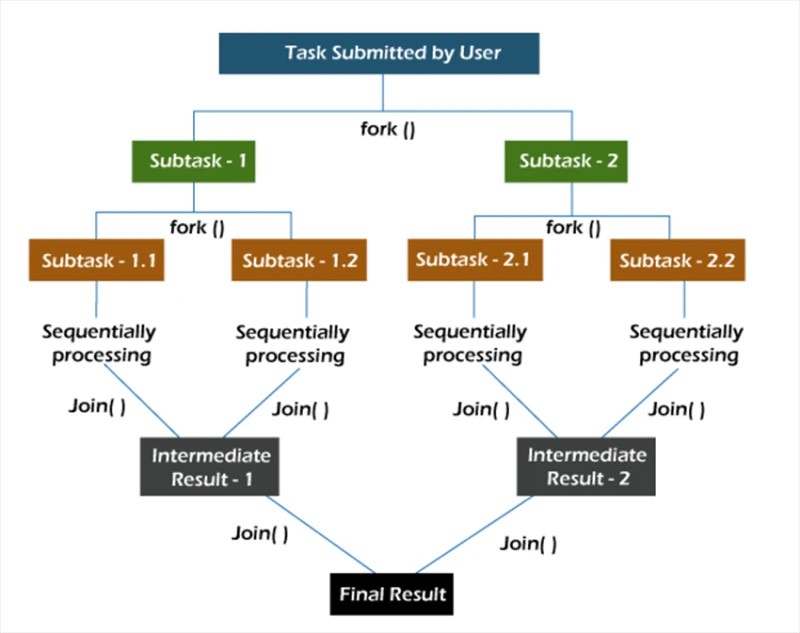
В рамката fork/join задачите се декомпозират рекурсивно, т.е. те се разбиват на подзадачи. След това подзадачите се изпълняват поотделно и резултатите от подзадачите се комбинират, за да формират резултата от първоначалната задача.
Методът fork стартира задача асинхронно в няHowва нишка, а методът join ви позволява да изчакате тази задача да приключи.
newWorkStealingPool
Методът newWorkStealingPool има две реализации:
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
От самото начало отбелязваме, че под капака не извикваме конструктора ThreadPoolExecutor . Тук работим с обекта ForkJoinPool . Подобно на ThreadPoolExecutor , това е имплементация на AbstractExecutorService .
Имаме 2 метода за избор. В първия ние сами посочваме Howво ниво на паралелизъм искаме да видим. Ако не посочим тази стойност, тогава паралелността на нашия пул ще бъде равна на броя на процесорните ядра, налични за виртуалната машина на Java.

Остава да разберем How работи на практика:
Collection<Callable<Void>> tasks = new ArrayList<>();
ExecutorService executorService = Executors.newWorkStealingPool(10);
for (int i = 0; i < 10; i++) {
int taskNumber = i;
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
return null;
};
tasks.add(callable);
}
executorService.invokeAll(tasks);
Ние създаваме 10 задачи, които показват собствения си статус на изпълнение. След това стартираме всички задачи с помощта на метода invokeAll .
Резултати при изпълнение на 10 задачи на 10 нишки в пула:
Обработена потребителска заявка #4 на ForkJoinPool-1-worker-5 нишка
Обработена потребителска заявка #7 на ForkJoinPool-1-worker-8 нишка
Обработена потребителска заявка #1 на ForkJoinPool- 1-worker-2 нишка
Обработена потребителска заявка #2 на ForkJoinPool-1-worker-3 нишка
Обработена потребителска заявка #3 на ForkJoinPool-1-worker-4 нишка
Обработена потребителска заявка #6 на ForkJoinPool-1-worker-7 нишка
Обработен потребител заявка #0 в нишка ForkJoinPool-1-worker-1
Обработена заявка на потребител #5 в нишка ForkJoinPool-1-worker-6
Обработена заявка на потребител #8 в нишка ForkJoinPool-1-worker-9
Виждаме, че след формирането на опашката нишките приемат задачи за изпълнение. Можете също така да проверите How 20 задачи ще бъдат разпределени в група от 10 нишки.
Обработена потребителска заявка #7 на ForkJoinPool-1-worker-8 нишка
Обработена потребителска заявка #2 на ForkJoinPool-1-worker-3 нишка
Обработена потребителска заявка #4 на ForkJoinPool- 1-worker-5 нишка
Обработена потребителска заявка #1 на ForkJoinPool-1-worker-2 нишка
Обработена потребителска заявка #5 на ForkJoinPool-1-worker-6 нишка
Обработена потребителска заявка #8 на ForkJoinPool-1-worker-9 нишка
Обработен потребител заявка #9 в нишка ForkJoinPool-1-worker-10
Обработена потребителска заявка #0 в нишка ForkJoinPool-1-worker-1
Обработена потребителска заявка #6 в нишка ForkJoinPool-1-worker-7
Обработена потребителска заявка #10 във ForkJoinPool-1- работник-9 нишка
Обработена потребителска заявка #12 на ForkJoinPool-1-worker-1 нишка
Обработена потребителска заявка #13 на ForkJoinPool-1-worker-8 нишка
Обработена потребителска заявка #11 на ForkJoinPool-1-worker-6 нишка
Обработена потребителска заявка #15 на ForkJoinPool- 1-worker-8 нишка
Обработена потребителска заявка #14 на ForkJoinPool-1-worker-1 нишка
Обработена потребителска заявка #17 на ForkJoinPool-1-worker-6 нишка
Обработена потребителска заявка #16 на ForkJoinPool-1-worker-7 нишка
Обработен потребител заявка #19 в нишка ForkJoinPool-1-worker-6
Обработена потребителска заявка #18 в нишка ForkJoinPool-1-worker-1
От изхода можем да видим, че някои нишки успяват да изпълнят няколко задачи ( ForkJoinPool-1-worker-6 изпълни 4 задачи), докато някои изпълняват само една ( ForkJoinPool-1-worker-2 ). Ако се добави забавяне от 1 секунда към изпълнението на метода за повикване , картината се променя.
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
return null;
};
В името на експеримента, нека изпълним същия code на друга машина. Полученият резултат:
Обработена потребителска заявка #7 на ForkJoinPool-1-worker-31 нишка
Обработена потребителска заявка #4 на ForkJoinPool-1-worker-27 нишка
Обработена потребителска заявка #5 на ForkJoinPool- 1-worker-13 нишка
Обработена потребителска заявка #0 на ForkJoinPool-1-worker-19 нишка
Обработена потребителска заявка #8 на ForkJoinPool-1-worker-3 нишка
Обработена потребителска заявка #9 на ForkJoinPool-1-worker-21 нишка
Обработен потребител заявка #6 на ForkJoinPool-1-worker-17 нишка
Обработена потребителска заявка #3 на ForkJoinPool-1-worker-9 нишка
Обработена потребителска заявка #1 на ForkJoinPool-1-worker-5 нишка
Обработена потребителска заявка #12 на ForkJoinPool-1- работник-23 нишка
Обработена потребителска заявка #15 на ForkJoinPool-1-worker-19 нишка
Обработена потребителска заявка #14 на ForkJoinPool-1-worker-27 нишка
Обработена потребителска заявка #11 на ForkJoinPool-1-worker-3 нишка
Обработена потребителска заявка #13 на ForkJoinPool- 1-worker-13 нишка
Обработена потребителска заявка #10 на ForkJoinPool-1-worker-31 нишка
Обработена потребителска заявка #18 на ForkJoinPool-1-worker-5 нишка
Обработена потребителска заявка #16 на ForkJoinPool-1-worker-9 нишка
Обработен потребител заявка #17 в нишка ForkJoinPool-1-worker-21
Обработена потребителска заявка #19 в нишка ForkJoinPool-1-worker-17
В този резултат е забележимо, че „поискахме“ нишките в пула. Нещо повече, имената на работните нишки не преминават от едно до десет, а instead of това понякога са по-високи от десет. Разглеждайки уникалните имена, виждаме, че наистина има десет работници (3, 5, 9, 13, 17, 19, 21, 23, 27 и 31). Тук съвсем резонно е да се запитаме защо се случи това? Винаги, когато не разбирате Howво се случва, използвайте дебъгера.
Това ще направим. Нека хвърлимexecutorServiceобект към ForkJoinPool :
final ForkJoinPool forkJoinPool = (ForkJoinPool) executorService;
Ще използваме действието Evaluate Expression, за да изследваме този обект след извикване на метода invokeAll . За да направите това, след метода invokeAll добавете произволен оператор, като например празен sout, и задайте точка на прекъсване върху него.

Виждаме, че пулът има 10 нишки, но размерът на масива от работни нишки е 32. Странно, но добре. Нека продължим да копаем. Когато създаваме пул, нека се опитаме да зададем нивото на паралелизъм на повече от 32, да кажем 40.
ExecutorService executorService = Executors.newWorkStealingPool(40);
В програмата за отстраняване на грешки нека да разгледамеforkJoinPool обект отново.

Сега размерът на масива от работни нишки е 128. Можем да предположим, че това е една от вътрешните оптимизации на JVM. Нека се опитаме да го намерим в codeа на JDK (openjdk-14):

Точно Howто подозирахме: размерът на масива от работни нишки се изчислява чрез извършване на побитови манипулации върху стойността на паралелизма. Не е нужно да се опитваме да разберем Howво точно се случва тук. Достатъчно е просто да знаете, че такава оптимизация съществува.
Друг интересен аспект на нашия пример е използването на метода invokeAll . Струва си да се отбележи, че методът invokeAll може да върне резултат or по-скоро списък с резултати (в нашия случай List <Future<Void>>) , където можем да намерим резултата от всяка от задачите.
var results = executorService.invokeAll(tasks);
for (Future<Void> result : results) {
// Process the task's result
}
Този специален вид услуга и набор от нишки могат да се използват в задачи с предвидимо or поне имплицитно ниво на едновременност.
GO TO FULL VERSION