Mari cari tahu metode baruWorkStealingPool , yang menyiapkan ExecutorService untuk kita.

Kumpulan utas ini istimewa. Tingkah lakunya didasarkan pada ide “mencuri” pekerjaan.
Tugas diantrekan dan didistribusikan di antara prosesor. Tetapi jika sebuah prosesor sedang sibuk, prosesor lain yang bebas dapat mencuri tugas darinya dan menjalankannya. Format ini diperkenalkan di Java untuk mengurangi konflik dalam aplikasi multi-utas. Itu dibangun di atas kerangka fork/join .
garpu / bergabung
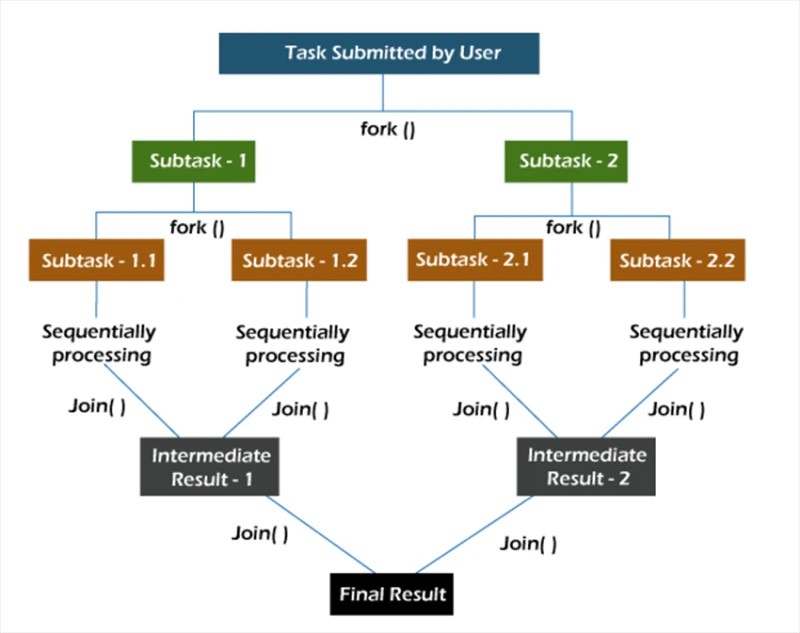
Dalam kerangka kerja fork/join , tugas didekomposisi secara rekursif, yaitu dipecah menjadi subtugas. Kemudian subtugas dijalankan secara individual, dan hasil subtugas digabungkan untuk membentuk hasil tugas asli.
Metode fork memulai tugas secara asinkron pada beberapa utas, dan metode bergabung memungkinkan Anda menunggu hingga tugas ini selesai.
newWorkStealingPool
Metode newWorkStealingPool memiliki dua implementasi:
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
Sejak awal, kami perhatikan bahwa di bawah tenda kami tidak memanggil konstruktor ThreadPoolExecutor . Di sini kami bekerja dengan entitas ForkJoinPool . Seperti ThreadPoolExecutor , ini merupakan implementasi dari AbstractExecutorService .
Kami memiliki 2 metode untuk dipilih. Yang pertama, kami sendiri menunjukkan tingkat paralelisme apa yang ingin kami lihat. Jika kami tidak menentukan nilai ini, paralelisme kumpulan kami akan sama dengan jumlah inti prosesor yang tersedia untuk mesin virtual Java.

Masih mencari tahu cara kerjanya dalam praktik:
Collection<Callable<Void>> tasks = new ArrayList<>();
ExecutorService executorService = Executors.newWorkStealingPool(10);
for (int i = 0; i < 10; i++) {
int taskNumber = i;
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
return null;
};
tasks.add(callable);
}
executorService.invokeAll(tasks);
Kami membuat 10 tugas yang menampilkan status penyelesaiannya sendiri. Setelah itu, kami meluncurkan semua tugas menggunakan metode invokeAll .
Hasil saat menjalankan 10 tugas pada 10 utas di kumpulan:
Permintaan pengguna yang diproses #4 di utas ForkJoinPool-1-pekerja-5 Permintaan
pengguna yang diproses #7 di utas ForkJoinPool-1-pekerja-8 Permintaan
pengguna yang diproses #1 di ForkJoinPool- utas 1-pekerja-2
Permintaan pengguna yang diproses #2 di utas ForkJoinPool-1-pekerja-3
Permintaan pengguna yang diproses #3 di utas ForkJoinPool-1-pekerja-4 Permintaan
pengguna yang diproses #6 di utas ForkJoinPool-1-pekerja-7 Pengguna
yang diproses permintaan #0 di utas ForkJoinPool-1-pekerja-1
Permintaan pengguna yang diproses #5 di utas ForkJoinPool-1-pekerja-6
Permintaan pengguna yang diproses #8 di utas ForkJoinPool-1-pekerja-9
Kami melihat bahwa setelah antrian terbentuk, utas mengambil tugas untuk dieksekusi. Anda juga dapat memeriksa bagaimana 20 tugas akan didistribusikan dalam kumpulan 10 utas.
Permintaan pengguna yang diproses #7 di utas ForkJoinPool-1-pekerja-8 Permintaan
pengguna yang diproses #2 di utas ForkJoinPool-1-pekerja-3 Permintaan
pengguna yang diproses #4 di ForkJoinPool- 1-pekerja-5 utas
Permintaan pengguna yang diproses #1 di utas ForkJoinPool-1-pekerja-2
Permintaan pengguna yang diproses #5 di utas ForkJoinPool-1-pekerja-6 Permintaan
pengguna yang diproses #8 di utas ForkJoinPool-1-pekerja-9 Pengguna
yang diproses permintaan #9 di utas ForkJoinPool-1-pekerja-10
Permintaan pengguna yang diproses #0 di utas ForkJoinPool-1-pekerja-1
Permintaan pengguna yang diproses #6 di utas ForkJoinPool-1-pekerja-7 Permintaan
pengguna yang diproses #10 di ForkJoinPool-1- utas pekerja-9
Permintaan pengguna yang diproses #12 di utas ForkJoinPool-1-pekerja-1
Permintaan pengguna yang diproses #13 di utas ForkJoinPool-1-pekerja-8 Permintaan
pengguna yang diproses #11 di utas ForkJoinPool-1-pekerja-6 Permintaan
pengguna yang diproses #15 di ForkJoinPool- 1-pekerja-8 utas
Permintaan pengguna yang diproses #14 di utas ForkJoinPool-1-pekerja-1
Permintaan pengguna yang diproses #17 di utas ForkJoinPool-1-pekerja-6 Permintaan
pengguna yang diproses #16 di utas ForkJoinPool-1-pekerja-7 Pengguna yang
diproses permintaan #19 di utas ForkJoinPool-1-worker-6
Permintaan pengguna yang diproses #18 di utas ForkJoinPool-1-worker-1
Dari output, kita dapat melihat bahwa beberapa utas berhasil menyelesaikan beberapa tugas ( ForkJoinPool-1-worker-6 menyelesaikan 4 tugas), sementara beberapa hanya menyelesaikan satu tugas ( ForkJoinPool-1-worker-2 ). Jika penundaan 1 detik ditambahkan ke penerapan metode panggilan , gambar akan berubah.
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
return null;
};
Demi percobaan, mari jalankan kode yang sama di komputer lain. Keluaran yang dihasilkan:
Permintaan pengguna yang diproses #7 pada utas ForkJoinPool-1-pekerja-31 Permintaan
pengguna yang diproses #4 pada utas ForkJoinPool-1-pekerja-27 Permintaan
pengguna yang diproses #5 pada ForkJoinPool- 1-pekerja-13 utas
Permintaan pengguna yang diproses #0 di utas ForkJoinPool-1-pekerja-19 Permintaan
pengguna yang diproses #8 di utas ForkJoinPool-1-pekerja-3 Permintaan
pengguna yang diproses #9 di utas ForkJoinPool-1-pekerja-21 Pengguna
yang diproses permintaan #6 di utas ForkJoinPool-1-pekerja-17
Permintaan pengguna yang diproses #3 di utas ForkJoinPool-1-pekerja-9
Permintaan pengguna yang diproses #1 di utas ForkJoinPool-1-pekerja-5
Permintaan pengguna yang diproses #12 di ForkJoinPool-1- utas pekerja-23
Permintaan pengguna yang diproses #15 di utas ForkJoinPool-1-pekerja-19
Permintaan pengguna yang diproses #14 di utas ForkJoinPool-1-pekerja-27 Permintaan
pengguna yang diproses #11 di utas ForkJoinPool-1-pekerja-3 Permintaan
pengguna yang diproses #13 di ForkJoinPool- utas 1-pekerja-13
Permintaan pengguna yang diproses #10 di utas ForkJoinPool-1-pekerja-31 Permintaan
pengguna yang diproses #18 di utas ForkJoinPool-1-pekerja-5
Permintaan pengguna yang diproses #16 di utas ForkJoinPool-1-pekerja-9
Pengguna yang diproses permintaan #17 di utas ForkJoinPool-1-worker-21
Permintaan pengguna yang diproses #19 di utas ForkJoinPool-1-worker-17
Dalam keluaran ini, perlu dicatat bahwa kami "meminta" utas di kumpulan. Terlebih lagi, nama thread pekerja tidak berubah dari satu menjadi sepuluh, tetapi terkadang lebih tinggi dari sepuluh. Melihat nama uniknya, kita melihat bahwa sebenarnya ada sepuluh pekerja (3, 5, 9, 13, 17, 19, 21, 23, 27 dan 31). Di sini cukup masuk akal untuk bertanya mengapa ini terjadi? Setiap kali Anda tidak mengerti apa yang sedang terjadi, gunakan debugger.
Inilah yang akan kami lakukan. Mari kita corExecutorServicekeberatan dengan ForkJoinPool :
final ForkJoinPool forkJoinPool = (ForkJoinPool) executorService;
Kami akan menggunakan tindakan Evaluasi Ekspresi untuk memeriksa objek ini setelah memanggil metode invokeAll . Untuk melakukannya, setelah metode invokeAll , tambahkan pernyataan apa pun, seperti sout kosong, dan atur breakpoint di atasnya.

Kita dapat melihat bahwa kumpulan tersebut memiliki 10 utas, tetapi ukuran susunan utas pekerja adalah 32. Aneh, tapi oke. Ayo terus menggali. Saat membuat kumpulan, mari kita coba atur level paralelisme menjadi lebih dari 32, katakanlah 40.
ExecutorService executorService = Executors.newWorkStealingPool(40);
Di debugger, mari kita lihatobjek forkJoinPool lagi.

Sekarang ukuran larik utas pekerja adalah 128. Kita dapat berasumsi bahwa ini adalah salah satu pengoptimalan internal JVM. Mari kita coba temukan di kode JDK (openjdk-14):

Seperti yang kita duga: ukuran larik thread pekerja dihitung dengan melakukan manipulasi bitwise pada nilai paralelisme. Kami tidak perlu mencoba mencari tahu apa yang sebenarnya terjadi di sini. Cukup mengetahui bahwa pengoptimalan semacam itu ada.
Aspek lain yang menarik dari contoh kita adalah penggunaan metode invokeAll . Perlu dicatat bahwa metode invokeAll dapat mengembalikan hasil, atau lebih tepatnya daftar hasil (dalam kasus kami, List <Future<Void>>) , di mana kami dapat menemukan hasil dari setiap tugas.
var results = executorService.invokeAll(tasks);
for (Future<Void> result : results) {
// Process the task's result
}
Jenis layanan dan kumpulan utas khusus ini dapat digunakan dalam tugas dengan tingkat konkurensi yang dapat diprediksi, atau setidaknya implisit.
GO TO FULL VERSION