Să descoperim noua metodăWorkStealingPool, care ne pregătește un ExecutorService .

Acest grup de fire este special. Comportamentul său se bazează pe ideea de a „fura” munca.
Sarcinile sunt puse în coadă și distribuite între procesoare. Dar dacă un procesor este ocupat, atunci un alt procesor gratuit îi poate fura o sarcină și o poate executa. Acest format a fost introdus în Java pentru a reduce conflictele în aplicațiile multi-threaded. Este construit pe cadrul fork/join .
bifurca/ună
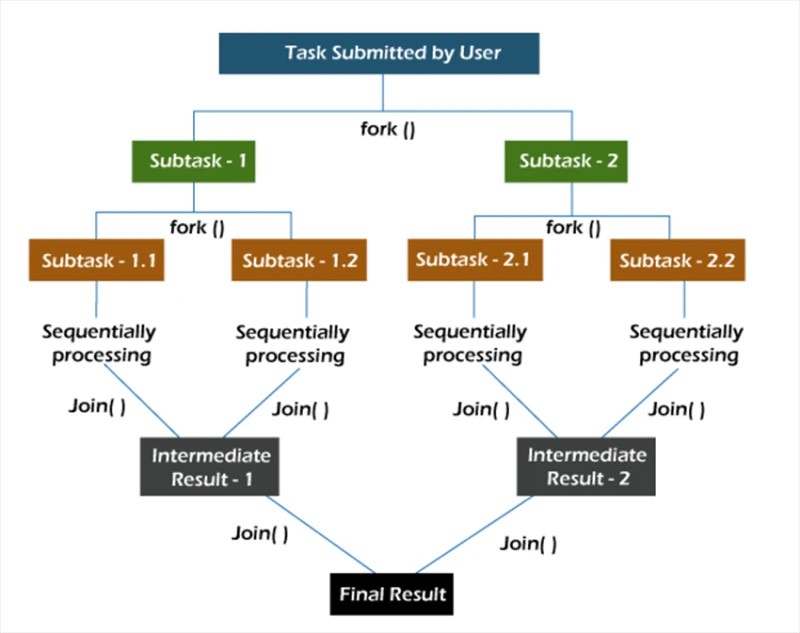
În cadrul fork/join , sarcinile sunt descompuse recursiv, adică sunt împărțite în subtask-uri. Apoi, subsarcinile sunt executate individual, iar rezultatele subsarcinilor sunt combinate pentru a forma rezultatul sarcinii inițiale.
Metoda fork pornește o sarcină asincron pe un fir, iar metoda join vă permite să așteptați ca această sarcină să se termine.
nouWorkStealingPool
Metoda newWorkStealingPool are două implementări:
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
De la început, observăm că sub capotă nu apelăm constructorul ThreadPoolExecutor . Aici lucrăm cu entitatea ForkJoinPool . La fel ca ThreadPoolExecutor , este o implementare a AbstractExecutorService .
Avem 2 metode din care să alegem. În primul, indicăm noi înșine ce nivel de paralelism vrem să vedem. Dacă nu specificăm această valoare, atunci paralelismul pool-ului nostru va fi egal cu numărul de nuclee de procesor disponibile pentru mașina virtuală Java.

Rămâne să ne dăm seama cum funcționează în practică:
Collection<Callable<Void>> tasks = new ArrayList<>();
ExecutorService executorService = Executors.newWorkStealingPool(10);
for (int i = 0; i < 10; i++) {
int taskNumber = i;
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
return null;
};
tasks.add(callable);
}
executorService.invokeAll(tasks);
Creăm 10 sarcini care își afișează propria stare de finalizare. După aceea, lansăm toate sarcinile folosind metoda invokeAll .
Rezultate la executarea a 10 sarcini pe 10 fire din pool:
Cererea utilizatorului #4 procesată pe firul ForkJoinPool-1-worker-5
Solicitarea utilizatorului #7 procesată pe firul ForkJoinPool-1-worker-8
Cererea utilizatorului #1 procesată pe ForkJoinPool- Firul 1-worker-2
Cererea utilizatorului #2 procesată pe firul ForkJoinPool-1-worker-3
Solicitarea utilizatorului #3 procesată pe firul ForkJoinPool-1-worker-4
Solicitarea utilizatorului #6 procesată pe firul ForkJoinPool-1-worker-7
Utilizator procesat cererea #0 pe firul ForkJoinPool-1-worker-1
Cererea utilizatorului procesată #5 pe firul ForkJoinPool-1-worker-6
Cererea utilizatorului #8 procesată pe firul ForkJoinPool-1-worker-9
Vedem că după ce coada este formată, firele de execuție preiau sarcini pentru execuție. De asemenea, puteți verifica cum vor fi distribuite 20 de sarcini într-un grup de 10 fire.
Solicitarea utilizatorului #7 procesată pe firul ForkJoinPool-1-worker-8
Solicitarea utilizatorului #2 procesată pe firul ForkJoinPool-1-worker-3
Cererea utilizatorului #4 procesată pe ForkJoinPool- Firul 1-worker-5
Cererea utilizatorului #1 procesată pe firul ForkJoinPool-1-worker-2
Solicitarea utilizatorului #5 procesată pe firul ForkJoinPool-1-worker-6
Solicitarea utilizatorului #8 procesată pe firul ForkJoinPool-1-worker-9
Utilizator procesat cererea #9 pe firul ForkJoinPool-1-worker-10
Cererea utilizatorului procesată #0 pe firul ForkJoinPool-1-worker-1
Cererea utilizatorului #6 procesată pe firul ForkJoinPool-1-worker-7
Cererea utilizatorului #10 procesată pe ForkJoinPool-1- firul muncitor-9
Solicitarea utilizatorului #12 procesată pe firul ForkJoinPool-1-worker-1
Solicitarea utilizatorului #13 procesată pe firul ForkJoinPool-1-worker-8
Solicitarea utilizatorului #11 procesată pe firul ForkJoinPool-1-worker-6
Cererea utilizatorului #15 procesată pe ForkJoinPool- Firul 1-worker-8
Cererea utilizatorului procesată #14 pe firul ForkJoinPool-1-worker-1
Solicitarea utilizatorului procesată #17 pe firul ForkJoinPool-1-worker-6
Cererea utilizatorului procesată #16 pe firul ForkJoinPool-1-worker-7
Utilizator procesat cererea #19 pe firul ForkJoinPool-1-worker-6
Cererea utilizatorului procesată #18 pe firul ForkJoinPool-1-worker-1
Din rezultat, putem vedea că unele fire reușesc să finalizeze mai multe sarcini ( ForkJoinPool-1-worker-6 a finalizat 4 sarcini), în timp ce unele completează doar una ( ForkJoinPool-1-worker-2 ). Dacă la implementarea metodei de apel se adaugă o întârziere de 1 secundă , imaginea se schimbă.
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
return null;
};
De dragul experimentului, să rulăm același cod pe o altă mașină. Rezultatul rezultat:
Cererea utilizatorului #7 procesată pe firul ForkJoinPool-1-worker-31
Cererea utilizatorului #4 procesată pe firul ForkJoinPool-1-worker-27
Cererea utilizatorului #5 procesată pe ForkJoinPool- Firul 1-worker-13
Cererea utilizatorului procesată #0 pe firul ForkJoinPool-1-worker-19
Solicitarea utilizatorului procesată #8 pe firul ForkJoinPool-1-worker-3
Cererea utilizatorului procesată #9 pe firul ForkJoinPool-1-worker-21
Utilizator procesat cererea #6 pe firul ForkJoinPool-1-worker-17
Cererea utilizatorului #3 procesată pe firul ForkJoinPool-1-worker-9
Solicitarea utilizatorului #1 procesată pe firul ForkJoinPool-1-worker-5
Cererea utilizatorului #12 procesată pe ForkJoinPool-1- firul muncitor-23
Solicitarea utilizatorului #15 procesată pe firul ForkJoinPool-1-worker-19
Solicitarea utilizatorului #14 procesată pe firul ForkJoinPool-1-worker-27
Cererea utilizatorului #11 procesată pe firul ForkJoinPool-1-worker-3
Cererea utilizatorului procesată #13 pe ForkJoinPool- Firul 1-worker-13
Cererea utilizatorului #10 procesată pe firul ForkJoinPool-1-worker-31
Solicitarea utilizatorului procesată #18 pe firul ForkJoinPool-1-worker-5
Cererea utilizatorului procesată #16 pe firul ForkJoinPool-1-worker-9
Utilizator procesat cererea #17 pe firul ForkJoinPool-1-worker-21
Cererea utilizatorului procesată #19 pe firul ForkJoinPool-1-worker-17
În această ieșire, este de remarcat că am „solicitat” firele din pool. În plus, numele firelor de lucru nu merg de la unu la zece, ci sunt uneori mai mari de zece. Privind numele unice, vedem că există într-adevăr zece lucrători (3, 5, 9, 13, 17, 19, 21, 23, 27 și 31). Aici este destul de rezonabil să ne întrebăm de ce s-a întâmplat asta? Ori de câte ori nu înțelegeți ce se întâmplă, utilizați depanatorul.
Asta vom face. Să aruncămexecutorServiceobiect la un ForkJoinPool :
final ForkJoinPool forkJoinPool = (ForkJoinPool) executorService;
Vom folosi acțiunea Evaluate Expression pentru a examina acest obiect după apelarea metodei invokeAll . Pentru a face acest lucru, după metoda invokeAll , adăugați orice instrucțiune, cum ar fi un sout gol și setați un punct de întrerupere pe ea.

Putem vedea că grupul are 10 fire, dar dimensiunea matricei de fire de lucru este de 32. Ciudat, dar în regulă. Să continuăm să săpăm. Când creați un pool, să încercăm să setăm nivelul de paralelism la mai mult de 32, să zicem 40.
ExecutorService executorService = Executors.newWorkStealingPool(40);
În depanator, să ne uităm laobiect forkJoinPool din nou.

Acum dimensiunea matricei de fire de lucru este de 128. Putem presupune că aceasta este una dintre optimizările interne ale JVM. Să încercăm să-l găsim în codul JDK-ului (openjdk-14):

Așa cum am bănuit: dimensiunea matricei de fire de lucru este calculată prin efectuarea de manipulări pe biți asupra valorii paralelismului. Nu trebuie să încercăm să ne dăm seama ce se întâmplă exact aici. Este suficient să știi pur și simplu că o astfel de optimizare există.
Un alt aspect interesant al exemplului nostru este utilizarea metodei invokeAll . Este de remarcat faptul că metoda invokeAll poate returna un rezultat, sau mai degrabă o listă de rezultate (în cazul nostru, o List<Future<Void>>) , unde putem găsi rezultatul fiecăreia dintre sarcini.
var results = executorService.invokeAll(tasks);
for (Future<Void> result : results) {
// Process the task's result
}
Acest tip special de serviciu și pool de fire de execuție poate fi utilizat în sarcini cu un nivel previzibil sau cel puțin implicit de concurență.
GO TO FULL VERSION