Découvrons la méthode newWorkStealingPool , qui prépare un ExecutorService pour nous.

Ce pool de threads est spécial. Son comportement est basé sur l'idée de "voler" le travail.
Les tâches sont mises en file d'attente et réparties entre les processeurs. Mais si un processeur est occupé, alors un autre processeur libre peut lui voler une tâche et l'exécuter. Ce format a été introduit en Java afin de réduire les conflits dans les applications multithread. Il est construit sur le framework fork/join .
bifurquer/joindre
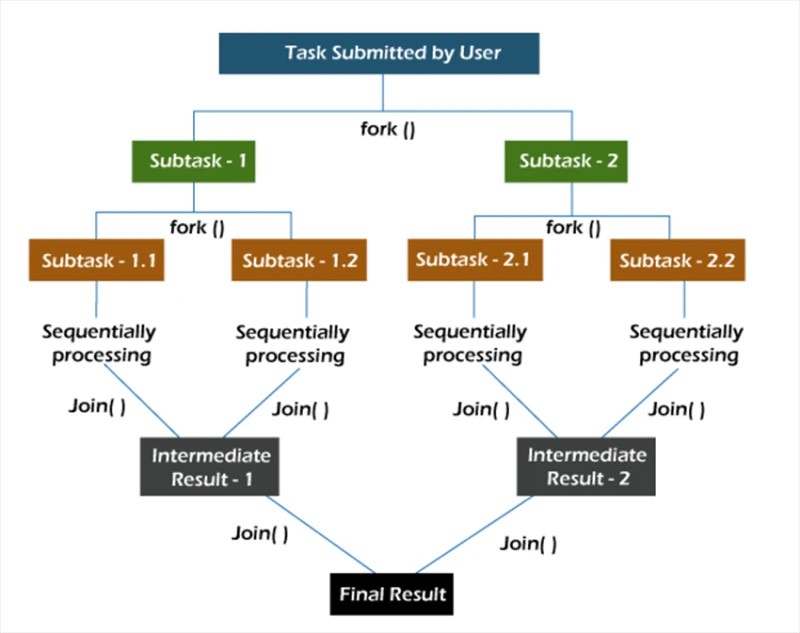
Dans le framework fork/join , les tâches sont décomposées de manière récursive, c'est-à-dire qu'elles sont décomposées en sous-tâches. Ensuite, les sous-tâches sont exécutées individuellement et les résultats des sous-tâches sont combinés pour former le résultat de la tâche d'origine.
La méthode fork démarre une tâche de manière asynchrone sur un thread, et la méthode join vous permet d'attendre la fin de cette tâche.
nouveauTravailVolerPiscine
La méthode newWorkStealingPool a deux implémentations :
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
D'emblée, notons que sous le capot nous n'appelons pas le constructeur ThreadPoolExecutor . Ici, nous travaillons avec l' entité ForkJoinPool . Comme ThreadPoolExecutor , il s'agit d'une implémentation de AbstractExecutorService .
Nous avons le choix entre 2 méthodes. Dans la première, nous indiquons nous-mêmes quel niveau de parallélisme nous voulons voir. Si nous ne spécifions pas cette valeur, alors le parallélisme de notre pool sera égal au nombre de cœurs de processeur disponibles pour la machine virtuelle Java.

Reste à savoir comment cela fonctionne en pratique :
Collection<Callable<Void>> tasks = new ArrayList<>();
ExecutorService executorService = Executors.newWorkStealingPool(10);
for (int i = 0; i < 10; i++) {
int taskNumber = i;
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
return null;
};
tasks.add(callable);
}
executorService.invokeAll(tasks);
Nous créons 10 tâches qui affichent leur propre état d'achèvement. Après cela, nous lançons toutes les tâches en utilisant la méthode invokeAll .
Résultats lors de l'exécution de 10 tâches sur 10 threads dans le pool :
Demande utilisateur traitée n° 4 sur le thread ForkJoinPool-1-worker-5
Demande utilisateur traitée n° 7 sur le thread ForkJoinPool-1-worker-8 Demande
utilisateur traitée n° 1 sur ForkJoinPool- 1-worker-2 thread
Requête d'utilisateur traitée n°2 sur le thread ForkJoinPool-1-worker-3
Requête d'utilisateur traitée n°3 sur le thread ForkJoinPool-1-worker-4
Requête d'utilisateur traitée n°6 sur le thread ForkJoinPool-1-worker-7
Utilisateur traité requête n° 0 sur le thread ForkJoinPool-1-worker-1
Requête de l'utilisateur n° 5 traitée sur le thread ForkJoinPool-1-worker-6
Requête de l'utilisateur n° 8 traitée sur le thread ForkJoinPool-1-worker-9
Nous voyons qu'une fois la file d'attente formée, les threads prennent des tâches à exécuter. Vous pouvez également vérifier comment 20 tâches seront réparties dans un pool de 10 threads.
Requête utilisateur n°7 traitée sur le thread ForkJoinPool-1-worker-8
Requête utilisateur n°2 traitée sur le thread ForkJoinPool-1-worker-3 Requête
utilisateur n°4 traitée sur ForkJoinPool- 1-worker-5 thread
Requête d'utilisateur traitée n°1 sur le thread ForkJoinPool-1-worker-2
Requête d'utilisateur traitée n°5 sur le thread ForkJoinPool-1-worker-6
Requête d'utilisateur traitée n°8 sur le thread ForkJoinPool-1-worker-9
Utilisateur traité requête n° 9 sur le thread ForkJoinPool-1-worker-10
Requête utilisateur traitée n° 0 sur le thread ForkJoinPool-1
-worker-1 Requête utilisateur traitée n° 6 sur le thread ForkJoinPool-1-worker-7 Requête
utilisateur traitée n° 10 sur ForkJoinPool-1- fil travailleur-9
Demande utilisateur traitée n° 12 sur le thread ForkJoinPool-1-worker-1
Demande utilisateur traitée n° 13 sur le thread ForkJoinPool-1-worker-8
Demande utilisateur traitée n° 11 sur le thread ForkJoinPool-1-worker-6 Demande
utilisateur traitée n° 15 sur ForkJoinPool- 1-worker-8 thread
Demande d'utilisateur traitée n°14 sur ForkJoinPool-1-worker-1 thread
Demande d'utilisateur traitée n°17 sur ForkJoinPool-1-worker-6 thread
Demande d'utilisateur traitée n°16 sur ForkJoinPool-1-worker-7 thread
Utilisateur traité requête n° 19 sur le thread ForkJoinPool-1-worker-6
Requête d'utilisateur traitée n° 18 sur le thread ForkJoinPool-1-worker-1
D'après la sortie, nous pouvons voir que certains threads parviennent à terminer plusieurs tâches ( ForkJoinPool-1-worker-6 a terminé 4 tâches), tandis que d'autres n'en terminent qu'une seule ( ForkJoinPool-1-worker-2 ). Si un délai d'une seconde est ajouté à la mise en œuvre de la méthode d'appel , l'image change.
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
return null;
};
Par souci d'expérimentation, exécutons le même code sur une autre machine. La sortie résultante :
Demande utilisateur traitée n° 7 sur le thread ForkJoinPool-1-worker-31
Demande utilisateur traitée n° 4 sur le thread ForkJoinPool-1-worker-27 Demande
utilisateur traitée n° 5 sur ForkJoinPool- 1-worker-13 thread
Requête utilisateur traitée n°0 sur le thread ForkJoinPool-1-worker-19 Requête
utilisateur traitée n°8 sur le thread ForkJoinPool-1-worker-3
Requête utilisateur traitée n°9 sur le thread ForkJoinPool-1-worker-21
Utilisateur traité Requête n°6 sur le thread ForkJoinPool-1-worker-17
Requête utilisateur n°3 traitée sur le thread ForkJoinPool- 1-worker-9
Requête utilisateur n°1 traitée sur le thread ForkJoinPool-1-worker-5
Requête utilisateur n°12 traitée sur ForkJoinPool-1- fil travailleur-23
Demande utilisateur traitée n°15 sur le thread ForkJoinPool-1-worker-19
Demande utilisateur traitée n°14 sur le thread
ForkJoinPool-1-worker-27 Demande utilisateur traitée n°11 sur le thread ForkJoinPool-1-worker-3 Demande
utilisateur traitée n°13 sur ForkJoinPool- 1-worker-13 thread
Demande d'utilisateur traitée n°10 sur ForkJoinPool-1-worker-31 thread
Demande d'utilisateur traitée n°18 sur ForkJoinPool-1-worker-5 thread
Demande d'utilisateur traitée n°16 sur ForkJoinPool-1-worker-9 thread
Utilisateur traité requête n° 17 sur le thread ForkJoinPool-1-worker-21
Demande d'utilisateur traitée n° 19 sur le thread ForkJoinPool-1-worker-17
Dans cette sortie, il est à noter que nous avons "demandé" les threads dans le pool. De plus, les noms des threads de travail ne vont pas de un à dix, mais sont parfois supérieurs à dix. En regardant les noms uniques, nous voyons qu'il y a vraiment dix ouvriers (3, 5, 9, 13, 17, 19, 21, 23, 27 et 31). Ici, il est tout à fait raisonnable de se demander pourquoi cela s'est produit? Chaque fois que vous ne comprenez pas ce qui se passe, utilisez le débogueur.
C'est ce que nous allons faire. Jetons leexecutorServiceobjet à un ForkJoinPool :
final ForkJoinPool forkJoinPool = (ForkJoinPool) executorService;
Nous utiliserons l'action Évaluer l'expression pour examiner cet objet après avoir appelé la méthode invokeAll . Pour ce faire, après la méthode invokeAll , ajoutez n'importe quelle instruction, telle qu'un sout vide, et définissez un point d'arrêt dessus.

Nous pouvons voir que le pool a 10 threads, mais la taille du tableau de threads de travail est de 32. Bizarre, mais bon. Continuons à creuser. Lors de la création d'un pool, essayons de définir le niveau de parallélisme à plus de 32, disons 40.
ExecutorService executorService = Executors.newWorkStealingPool(40);
Dans le débogueur, regardons leforkJoinPool à nouveau.

Maintenant, la taille du tableau de threads de travail est de 128. Nous pouvons supposer qu'il s'agit de l'une des optimisations internes de la JVM. Essayons de le trouver dans le code du JDK (openjdk-14) :

Tout comme nous le soupçonnions : la taille du tableau des threads de travail est calculée en effectuant des manipulations au niveau du bit sur la valeur de parallélisme. Nous n'avons pas besoin d'essayer de comprendre ce qui se passe exactement ici. Il suffit simplement de savoir qu'une telle optimisation existe.
Un autre aspect intéressant de notre exemple est l'utilisation de la méthode invokeAll . Il est à noter que la méthode invokeAll peut retourner un résultat, ou plutôt une liste de résultats (dans notre cas, un List<Future<Void>>) , où l'on peut trouver le résultat de chacune des tâches.
var results = executorService.invokeAll(tasks);
for (Future<Void> result : results) {
// Process the task's result
}
Ce type spécial de service et de pool de threads peut être utilisé dans des tâches avec un niveau prévisible, ou au moins implicite, de simultanéité.
GO TO FULL VERSION