Lassen Sie uns die Methode newWorkStealingPool herausfinden , die einen ExecutorService für uns vorbereitet.

Dieser Thread-Pool ist etwas Besonderes. Sein Verhalten basiert auf der Idee, Arbeit zu „stehlen“.
Aufgaben werden in die Warteschlange gestellt und auf die Prozessoren verteilt. Wenn jedoch ein Prozessor ausgelastet ist, kann ein anderer freier Prozessor ihm eine Aufgabe stehlen und ausführen. Dieses Format wurde in Java eingeführt, um Konflikte in Multithread-Anwendungen zu reduzieren. Es basiert auf dem Fork/Join- Framework.
forken/verbinden
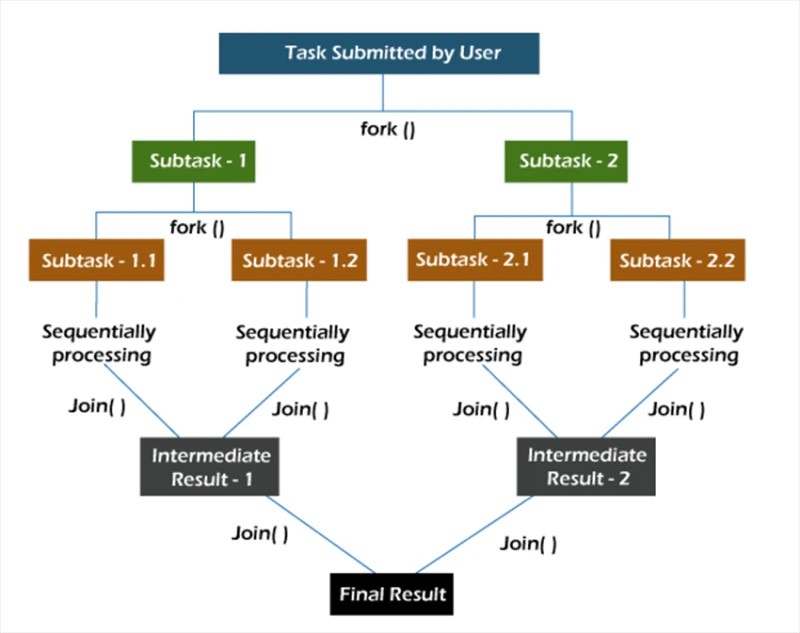
Im Fork/Join- Framework werden Aufgaben rekursiv zerlegt, also in Unteraufgaben zerlegt. Anschließend werden die Teilaufgaben einzeln ausgeführt und die Ergebnisse der Teilaufgaben zum Ergebnis der ursprünglichen Aufgabe zusammengefasst.
Die Fork- Methode startet eine Aufgabe asynchron in einem Thread und mit der Join- Methode können Sie warten, bis diese Aufgabe abgeschlossen ist.
newWorkStealingPool
Die newWorkStealingPool -Methode verfügt über zwei Implementierungen:
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
Von Anfang an stellen wir fest, dass wir unter der Haube nicht den ThreadPoolExecutor -Konstruktor aufrufen . Hier arbeiten wir mit der ForkJoinPool -Entität. Wie ThreadPoolExecutor ist es eine Implementierung von AbstractExecutorService .
Wir haben 2 Methoden zur Auswahl. Im ersten Schritt geben wir selbst an, welchen Grad an Parallelität wir sehen möchten. Wenn wir diesen Wert nicht angeben, entspricht die Parallelität unseres Pools der Anzahl der Prozessorkerne, die der Java Virtual Machine zur Verfügung stehen.

Es bleibt abzuwarten, wie es in der Praxis funktioniert:
Collection<Callable<Void>> tasks = new ArrayList<>();
ExecutorService executorService = Executors.newWorkStealingPool(10);
for (int i = 0; i < 10; i++) {
int taskNumber = i;
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
return null;
};
tasks.add(callable);
}
executorService.invokeAll(tasks);
Wir erstellen 10 Aufgaben, die ihren eigenen Erledigungsstatus anzeigen. Danach starten wir alle Aufgaben mit der Methode invokeAll .
Ergebnisse bei der Ausführung von 10 Aufgaben auf 10 Threads im Pool:
Verarbeitete Benutzeranfrage Nr. 4 im Thread „ForkJoinPool-1-worker-5“
Verarbeitete Benutzeranfrage Nr. 7 im Thread „ForkJoinPool-1-worker-8“
Verarbeitete Benutzeranfrage Nr. 1 im Thread „ForkJoinPool-“ 1-Worker-2-Thread
Verarbeitete Benutzeranforderung Nr. 2 im ForkJoinPool-1-worker-3-Thread
Verarbeitete Benutzeranforderung Nr. 3 im ForkJoinPool-1-worker-4-Thread
Verarbeitete Benutzeranforderung Nr. 6 im ForkJoinPool-1-worker-7-Thread
Verarbeiteter Benutzer Anfrage Nr. 0 im Thread „ForkJoinPool-1-worker-1“
Benutzeranfrage Nr. 5 im Thread „ForkJoinPool-1-worker-6“ verarbeitet
Benutzeranfrage Nr. 8 im Thread „ForkJoinPool-1-worker-9“ verarbeitet
Wir sehen, dass die Threads nach der Bildung der Warteschlange Aufgaben zur Ausführung übernehmen. Sie können auch überprüfen, wie 20 Aufgaben in einem Pool von 10 Threads verteilt werden.
Verarbeitete Benutzeranfrage Nr. 7 im Thread „ForkJoinPool-1-worker-8“
Verarbeitete Benutzeranfrage Nr. 2 im Thread „ForkJoinPool-1-worker-3“
Verarbeitete Benutzeranfrage Nr. 4 im Thread „ForkJoinPool-“ 1-worker-5 Thread
Verarbeitete Benutzeranfrage Nr. 1 im ForkJoinPool-1-worker-2-Thread
Verarbeitete Benutzeranforderung Nr. 5 im ForkJoinPool-1-worker-6-Thread
Verarbeitete Benutzeranforderung Nr. 8 im ForkJoinPool-1-worker-9-Thread
Verarbeiteter Benutzer Anfrage Nr. 9 im Thread „ForkJoinPool-1-worker-10“
Verarbeitete Benutzeranfrage Nr. 0 im Thread „
ForkJoinPool-1-worker-1“ Verarbeitete Benutzeranfrage Nr. 6 im Thread „ForkJoinPool-1-worker-7“
Verarbeitete Benutzeranfrage Nr. 10 im Thread „ForkJoinPool-1-“ Worker-9-Thread
Verarbeitete Benutzeranfrage Nr. 12 im Thread „ForkJoinPool-1-worker-1“
Verarbeitete Benutzeranfrage Nr. 13 im Thread „ForkJoinPool-1-worker-8“
Verarbeitete Benutzeranfrage Nr. 11 im Thread „ForkJoinPool-1-worker-6“
Verarbeitete Benutzeranfrage Nr. 15 im Thread „ForkJoinPool-“ 1-Worker-8-Thread
Verarbeitete Benutzeranfrage Nr. 14 im ForkJoinPool-1-worker-1-Thread
Verarbeitete Benutzeranfrage Nr. 17 im ForkJoinPool-1-worker-6-Thread
Verarbeitete Benutzeranfrage Nr. 16 im ForkJoinPool-1-worker-7-Thread
Verarbeiteter Benutzer Anfrage Nr. 19 im ForkJoinPool-1-worker-6-Thread
Benutzeranfrage Nr. 18 im ForkJoinPool-1-worker-1-Thread verarbeitet
Aus der Ausgabe können wir ersehen, dass es einigen Threads gelingt, mehrere Aufgaben abzuschließen ( ForkJoinPool-1-worker-6 hat 4 Aufgaben abgeschlossen), während andere nur eine erledigen ( ForkJoinPool-1-worker-2 ). Wenn der Implementierung der Aufrufmethode eine Verzögerung von 1 Sekunde hinzugefügt wird , ändert sich das Bild.
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
return null;
};
Lassen Sie uns aus Versuchsgründen denselben Code auf einem anderen Computer ausführen. Die resultierende Ausgabe:
Verarbeitete Benutzeranfrage Nr. 7 im Thread „ForkJoinPool-1-worker-31“
Verarbeitete Benutzeranfrage Nr. 4 im Thread „ForkJoinPool-1-worker-27“
Verarbeitete Benutzeranfrage Nr. 5 im Thread „ForkJoinPool-“ 1-worker-13 Thread
Verarbeitete Benutzeranforderung Nr. 0 im ForkJoinPool-1-worker-19 Thread
Verarbeitete Benutzeranforderung Nr. 8 im ForkJoinPool-1-worker-3 Thread
Verarbeitete Benutzeranforderung Nr. 9 im ForkJoinPool-1-worker-21 Thread
Verarbeiteter Benutzer Anfrage Nr. 6 im Thread „ForkJoinPool-1-worker-17“
Verarbeitete Benutzeranfrage Nr. 3 im Thread „ForkJoinPool-1-worker-9“
Verarbeitete Benutzeranfrage Nr. 1 im Thread „ForkJoinPool-1-worker-5“
Verarbeitete Benutzeranfrage Nr. 12 im Thread „ForkJoinPool-1-“ Worker-23-Thread
Verarbeitete Benutzeranfrage Nr. 15 im Thread „ForkJoinPool-1-worker-19“
Verarbeitete Benutzeranfrage Nr. 14 im Thread „ForkJoinPool-1-worker-27“
Verarbeitete Benutzeranfrage Nr. 11 im Thread „ForkJoinPool-1-worker-3“
Verarbeitete Benutzeranfrage Nr. 13 im Thread „ForkJoinPool-“ 1-worker-13 Thread
Verarbeitete Benutzeranforderung Nr. 10 im ForkJoinPool-1-worker-31-Thread
Verarbeitete Benutzeranforderung Nr. 18 im ForkJoinPool-1-worker-5-Thread
Verarbeitete Benutzeranforderung Nr. 16 im ForkJoinPool-1-worker-9-Thread
Verarbeiteter Benutzer Anfrage Nr. 17 im ForkJoinPool-1-worker-21-Thread
Benutzeranfrage Nr. 19 im ForkJoinPool-1-worker-17-Thread verarbeitet
In dieser Ausgabe fällt auf, dass wir nach den Threads im Pool „gefragt“ haben. Darüber hinaus gehen die Namen der Worker-Threads nicht von eins bis zehn, sondern liegen teilweise über zehn. Wenn wir uns die eindeutigen Namen ansehen, sehen wir, dass es tatsächlich zehn Arbeiter gibt (3, 5, 9, 13, 17, 19, 21, 23, 27 und 31). Hier ist es durchaus berechtigt zu fragen, warum das passiert ist? Wenn Sie nicht verstehen, was vor sich geht, verwenden Sie den Debugger.
Das werden wir tun. Lassen Sie uns das besetzenexecutorServiceObjekt zu einem ForkJoinPool :
final ForkJoinPool forkJoinPool = (ForkJoinPool) executorService;
Wir werden die Aktion „Ausdruck auswerten“ verwenden, um dieses Objekt nach dem Aufruf der Methode „invokeAll“ zu untersuchen . Fügen Sie dazu nach der invokeAll -Methode eine beliebige Anweisung hinzu, z. B. ein leeres Sout, und legen Sie einen Haltepunkt fest.

Wir können sehen, dass der Pool 10 Threads hat, aber die Größe des Arrays der Arbeitsthreads beträgt 32. Seltsam, aber okay. Lasst uns weiter graben. Versuchen wir beim Erstellen eines Pools, den Parallelitätsgrad auf mehr als 32, beispielsweise 40, festzulegen.
ExecutorService executorService = Executors.newWorkStealingPool(40);
Schauen wir uns im Debugger das anforkJoinPool-Objekt erneut.

Jetzt beträgt die Größe des Arrays der Arbeitsthreads 128. Wir können davon ausgehen, dass dies eine der internen Optimierungen der JVM ist. Versuchen wir es im Code des JDK (openjdk-14) zu finden:

Genau wie wir vermutet haben: Die Größe des Arrays der Arbeitsthreads wird durch bitweise Manipulationen am Parallelitätswert berechnet. Wir müssen nicht versuchen herauszufinden, was genau hier passiert. Es reicht aus, einfach zu wissen, dass eine solche Optimierung existiert.
Ein weiterer interessanter Aspekt unseres Beispiels ist die Verwendung der invokeAll- Methode. Es ist erwähnenswert, dass die invokeAll- Methode ein Ergebnis bzw. eine Ergebnisliste (in unserem Fall eine List<Future<Void>>) zurückgeben kann , in der wir das Ergebnis jeder Aufgabe finden können.
var results = executorService.invokeAll(tasks);
for (Future<Void> result : results) {
// Process the task's result
}
Diese besondere Art von Service und Thread-Pool kann in Aufgaben mit einem vorhersehbaren oder zumindest impliziten Grad an Parallelität verwendet werden.
GO TO FULL VERSION